





基于用户兴趣偏好的画像方法
Consumers face a huge challenge today in choosing from numerous alternatives available in any product category. I developed and tested a system that matches a shopper’s preferences regarding the features of a product to recommendations using online reviews. I also performed feature-level sentiment analysis to make sure that the recommended products have high customer satisfaction with preferred features. This recommender system is quite different from the most common approach, which takes a product such as a movie as input, and finds similar products as recommendations. It doesn’t use a shopper’s history either, and therefore avoids the cold start problem, and is also well suited for one-time purchases.
如今 , 消费者在从任何产品类别中选择众多替代产品时面临着巨大的挑战 。 我开发并测试了一个系统,该系统使用在线评论将购物者对产品功能的偏好与推荐相匹配。 我还进行了功能级别的情感分析,以确保推荐产品对首选功能的客户满意度很高。 此推荐器系统与最常见的方法有很大的不同,后者将电影等产品作为输入,并找到相似的产品作为推荐。 它也没有使用购物者的历史记录,因此避免了冷启动问题,也非常适合一次性购买。
Being a cross country runner, I wanted to build a recommender system for running shoes. With 100k reviews of 505 running shoes from 18 manufacturers, my recommender system (runningshoe4you.com) finds shoes that are a closer match with a consumer’s ideal preferences compared to those with the highest overall rating, without the need to read a large number of product reviews. The Python code I wrote for this recommender system is available from one of my GitHub repositories: https://github.com/JoshB02/recommender-system-tools
作为越野跑步者,我想为跑鞋建立一个推荐系统。 我的推荐系统( runningshoe4you.com )对来自18个制造商的505跑鞋进行了10万条评论,发现与总评分最高的鞋相比,它更符合消费者的理想偏好,而无需阅读大量产品评论。 我为此推荐系统编写的Python代码可从我的GitHub存储库之一获得: https : //github.com/JoshB02/recommender-system-tools
It is difficult for a consumer to discover the right product that matches her preferences without spending a lot of time and effort in evaluating numerous alternatives. Curiously, the Amazon.com website puts a major burden on users to read reviews, one product at a time. For example, searching by the keywords “running shoes” generated many pages of results, with 68 products being displayed on the first page itself. A user has to click on a product, and read the reviews for that product; for reviews of another product, the user has to click on the second product, and repeat the tedious process. I am sure Amazon has figured out that this way of displaying product information maximizes its profits, but I feel it places an undue demand on our time.
消费者很难在不花费大量时间和精力来评估众多替代产品的情况下,找到符合其偏好的合适产品。 奇怪的是,Amazon.com网站给用户带来了很大的负担,使他们一次只能阅读一种产品。 例如,通过关键字“跑鞋”进行搜索可生成许多结果页面,第一页本身显示68种产品。 用户必须单击产品,然后阅读该产品的评论; 要评论其他产品,用户必须单击第二个产品,然后重复乏味的过程。 我敢肯定,亚马逊已经弄清楚了这种显示产品信息的方式可以最大程度地提高其利润,但是我觉得这对我们的时间提出了过高的要求。
To make it a little easier, Amazon does present a set of buttons representing review keywords or phrases it finds from a word frequency analysis. Figure 1 shows the keyword or topic buttons for a certain pair of running shoes. If we click a button, say, perfect fit, Amazon displays all reviews that contain the keywords. While this approach is useful in that it allows a shopper to focus on reviews based on what she is looking for in a product, it still requires her to read many reviews, one feature at a time for each product. The process can be frustrating.
为了使操作更简单,Amazon确实提供了一组按钮,这些按钮代表从单词频率分析中找到的评论关键字或短语。 图1显示了某双跑步鞋的关键字或主题按钮。 如果我们单击一个按钮,例如说完美匹配 ,亚马逊将显示所有包含关键字的评论。 尽管这种方法很有用,因为它允许购物者根据她在产品中寻找的内容专注于评论,但仍然需要她阅读许多评论,每个产品一次具有一项功能。 这个过程可能令人沮丧。

提取用户评论中提到的产品功能 (Extracting product features mentioned in user reviews)
I used nouns (e.g., comfort), verbs (e.g., comforted), adjectives (e.g., comfortable) and adverbs (e.g., comfortably) to extract product features from reviews.
我使用名词(例如舒适),动词(例如舒适),形容词(例如舒适)和副词(例如舒适)来从评论中提取产品功能。
I transformed the set of product reviews into a matrix of binary values (0 or 1) based on whether they contain mentions of these features or related words, as shown in Table 1.
我根据产品评论中是否包含这些功能或相关字词,将产品评论集转换为二进制值矩阵(0或1),如表1所示。

From the above table, each review can be expressed as a vector of features, where 1 (0) means that the feature or a related word was (not) mentioned in that review. The original review data will still be valuable for conducting sentiment analysis, since all sentiment related information will be lost in the above step. As an alternative to binary representation, we can also use term frequency-inverse document frequency (tf-idf) to represent the review vectors.
从上表中,每个评论都可以表示为特征的向量,其中1(0)表示该评论中未提及特征或相关词。 由于在上述步骤中所有与情感相关的信息都将丢失,因此原始评论数据对于进行情感分析仍然将是有价值的。 作为二进制表示的替代方法,我们还可以使用术语频率反文档频率( tf - idf )来表示评论向量。
获取有关所需功能的用户输入 (Obtaining user inputs regarding desired features)
There are two possible ways to obtain inputs from a user without intruding upon her privacy. First, we can ask the user to choose her preferred product features from a list. This will provide the desired feature vector.
有两种可能的方式可在不侵犯用户隐私的情况下从用户那里获取输入。 首先,我们可以要求用户从列表中选择她喜欢的产品功能。 这将提供所需的特征向量。
However, our recommendations will be more relevant if we only consider the features that have been explicitly specified by the user.
但是,如果我们仅考虑用户已明确指定的功能,那么我们的建议将更加相关。


Sometimes a shopper may be unsure of the features she wants, but can indicate a product that she may have heard about or is interested in. In such a case, we can determine which features are strongly associated with this product in customer reviews using the following formula:
有时,购物者可能不确定她想要的功能,但是可以指示她可能听说过或感兴趣的产品。在这种情况下,我们可以使用以下方法在客户评论中确定与该产品强烈相关的功能式:

If the association value is greater than 1, the relationship is significant, and we can infer that when people write about product A, they associate it with feature f (and vice versa). The greater the association value above 1, the stronger the relationship. Thus, when a shopper expresses interest in a product, it is reasonable to take features with high association values as the feature set that may be of interest to her.
如果关联值大于1,则该关系很重要,我们可以推断出,当人们写产品A时 ,他们将其与特征f关联(反之亦然)。 高于1的关联值越大,关联越强。 因此,当购物者表达对产品的兴趣时,将具有高关联值的特征作为她可能感兴趣的特征集是合理的。
获得偏好和评论之间的匹配分数 (Obtaining matching scores between preferences and reviews)
There are multiple ways to obtain a matching score between a review and the desired feature vector. Cosine similarity is the most common approach, which, in our case, is the cosine of the angle between the desired feature vector and a review vector in the same space. Let D be the set of features either chosen by the user, or inferred from high association values with a selected product.
有多种方法可获取评论与所需特征向量之间的匹配分数。 余弦相似度是最常见的方法,在我们的情况下,它是相同空间中所需特征向量和查看向量之间角度的余弦值。 令D为用户选择的特征集,或者由与选定产品的高关联值推论得出的特征集。


The average cosine value for a product and a desired set of features shows us the match between what a shopper is looking for in a product and the features mentioned in the reviews. If the score is closer to 0, then the match is low, while a score closer to 1 indicates a strong match. If there are a total of N reviews, N cosine scores are obtained for a given set of features, and the average for each product is calculated.
产品的平均余弦值和所需的功能集向我们显示了购物者在产品中寻找的内容与评论中提到的功能之间的匹配。 如果分数接近0,则表示匹配程度较低,而分数接近1则表示匹配程度较高。 如果总共有N条评论,则针对给定的一组特征获得N个余弦分数,并计算每个产品的平均值。
An alternative to requiring an exact word match as in cosine similarity is word embeddings. While superior in principle, with word embeddings, I faced the problem of the recommender system not distinguishing well between different features. For instance, while cushion and comfort are two distinct features of running shoes, standard word embeddings are based on news items and other topics, where cushion and comfort are likely to appear in close proximity of each other. Thus, in the word embeddings approach, cushion and comfort get treated as similar words, which leads to poor recommendations. I wrote an article on this topic in The Startup: https://medium.com/swlh/word-embeddings-versus-bag-of-words-the-curious-case-of-recommender-systems-6ac1604d4424
如在余弦相似度中那样,要求精确的单词匹配的另一种方法是单词嵌入 。 尽管在原则上具有词嵌入功能,但我遇到了推荐系统无法在不同功能之间区分开的问题。 例如,缓冲性和舒适性是跑鞋的两个显着特征,而标准的词嵌入则基于新闻和其他主题,其中缓冲性和舒适性很可能彼此接近。 因此,在词嵌入方法中,缓冲性和舒适性被视为相似的词,从而导致建议不佳。 我在《创业公司》中写了一篇关于该主题的文章: https : //medium.com/swlh/word-embeddings-versus-bag-of-words-the-curious-case-of-recommender-systems-6ac1604d4424
特征级情感分析 (Feature-level sentiment analysis)
While similarity analysis shows reviews that have focused on the same features that the user of the recommender system considers important, it cannot distinguish between positive and negative sentiments. Consider two short reviews:
尽管相似性分析显示评论的重点是推荐系统用户认为重要的相同功能,但它无法区分正面情绪和负面情绪。 考虑两个简短的评论:
Review (i): “These shoes are not comfortable at all, but are very durable”.
评论(i):“这些鞋子根本不舒适,但非常耐用”。
Review (ii): “Such amazingly comfortable shoes, plus I also like the support.”
评论(ii):“这双鞋非常舒适,我也喜欢这种支撑。”
Both reviews will have a higher similarity score if a shopper specifies comfort as an important feature; however, the product associated with the first review should not be recommended, assuming that a similar sentiment is echoed in other reviews of the product. Thus, sentiment analysis needs to be conducted in addition to calculating similarity scores.
如果购物者将舒适性指定为重要特征,则两个评论的相似性得分都将更高。 但是,不建议与第一次审核相关的产品,前提是该产品的其他审核中也有类似的想法。 因此,除了计算相似度得分外,还需要进行情感分析。
While an overall sentiment score for a product may be useful, we need to know how users feel about a particular feature of a product. A simple assumption we can use is that a customer will express her emotion regarding a feature within a window of words around the feature word. For example, in the short review “these shoes have excellent durability”, the word excellent captures the sentiment about the feature durability. Thus, from a review, if we extract a window of, say, three words to both the right and left of the feature word (when available), we can pass this window of words through a sentiment analyzer. For example, with a window size of 3, and excluding stop words like a, the or be, we will obtain the following from the two short reviews above:
虽然产品的整体情感评分可能有用,但我们需要了解用户对产品的特定功能的感觉。 我们可以使用的简单假设是,客户将在特征词周围的词窗口内表达其对特征的情感。 例如,在简短评论:“这些鞋有良好的耐久性”,这个词优秀捕获关于功能耐久性情绪。 因此,从评论中,如果我们提取特征词左右两个词的窗口(如果有的话),则可以使这个词窗口通过情感分析器。 例如,为3的窗口尺寸,以及不包括停止词喜欢 的或是 ,我们将获得从上面的两个短的评论如下:
From review (i): Shoes not comfortable at all
来自评论(i):鞋子根本不舒服
From review (ii): Such amazingly comfortable shoes, plus also
点评(ii):如此舒适的鞋子,加上
These extracted parts of a review can now be sent through a sentiment analyzer, and the resulting sentiment scores may be attributed to the feature comfort.
现在可以通过情感分析器发送评论的这些提取的部分,并且所得到的情感分数可以归因于特征舒适度 。
While all sentiment analyzer scales include negative values, users are more familiar with Amazon’s 1–5 ratings scale. I use the VADER sentiment analyzer in Python, which has a [-1, +1] scale. To present sentiment scores on the Amazon scale, I run a linear regression: Amazon rating = C + a*VADER + error, where C is a constant, and a the coefficient for the VADER score. With the data I collected, I obtain C = 3.66 and a = 1.36, with an adjusted R-squared of 42.2%. The root mean squared error (RMSE) is .228, which is reasonably good. Therefore, instead of showing VADER sentiment scores, my recommender system displays predicted Amazon ratings for each product feature on a [1, 5] scale.
尽管所有情绪分析器量表均包含负值,但用户对亚马逊的1–5量表更为熟悉。 我在Python中使用VADER情感分析器,其比例为[-1,+1]。 到在亚马逊规模本情绪评分,我跑的线性回归:亚马逊评级= C + A * VADER +误差,其中C是常数, 和系数为VADER得分。 通过收集的数据,我得到C = 3.66和a = 1.36,调整后的R平方为42.2%。 均方根误差(RMSE)为.228,这是相当不错的。 因此,我的推荐系统没有显示VADER情绪评分,而是以[1、5]比例显示了每个产品功能的预测亚马逊评分。
提出建议 (Making recommendations)
For each product, we calculate a weighted sum of the similarity score and the sentiment score averaged over the features chosen by the shopper. Since VADER’s scale is [-1, +1], this addition of similarity and sentiment scores does not pose a problem with scales. The recommended products are the ones with the highest weighted scores.
对于每种产品,我们计算相似分数和情感分数在购物者选择的特征上的加权平均值。 由于VADER的标度为[-1,+1],因此相似度和情感分数的这种增加不会对标度造成任何问题。 推荐的产品是加权分数最高的产品。
数据收集和预处理 (Data collection and pre-processing)
I wrote a scraper in Python using Selenium, and scraped over 100k reviews of running shoes from Amazon product review pages and other websites. A common issue with large amounts of text is that the corpus contains a large number of words. To reduce this vocabulary, I removed stopwords selectively, while retaining negation stopwords, since they flip the polarity of sentiments. To further reduce the total number of words, I used lemmatization. Further, I converted all parts of speech (e.g., comfortably, comfortable, etc.) and synonyms of a feature into the corresponding noun (comfort). However, I retained the original set of reviews for the purpose of sentiment analysis.
我使用Selenium在Python中编写了一个刮板,并从亚马逊产品评论页面和其他网站上刮了超过10万条关于跑鞋的评论。 大量文本的一个常见问题是,语料库包含大量单词。 为了减少词汇量,我选择性地删除了停用词,同时保留了否定停用词,因为它们颠倒了情感的极性。 为了进一步减少单词总数,我使用了词形化。 此外,我将语音的所有部分(例如,舒适,舒适等)和特征的同义词转换为相应的名词(舒适)。 但是,出于情感分析的目的,我保留了原始的一组评论。
For every combination specified by a shopper, my recommender system calculates (i) the cosine similarity of the feature vector with each review vector rid, (ii) the average cosine similarity for each shoe, calculated as the average over all reviews of a shoe, and (iii) the average Amazon adjusted sentiment score for each shoe for each chosen feature.
对于购物者指定的每种组合,我的推荐系统都会计算(i)特征向量与每个评论向量rid的余弦相似度,(ii)每只鞋的平均余弦相似度,计算为鞋子所有评论的平均值, (iii)每个鞋款针对每个所选功能的平均亚马逊调整后情感指数。
As an illustration, consider a user telling the system that three features — comfort, support and durability — are important to her in a pair of running shoes. For these three features, the three recommendations from my system are shown in Table 2, including matching scores (between 0 and 1), Amazon adjusted sentiments for each feature, and the average feature sentiment. To evaluate my recommendations, I consider the three highest rated running shoes on Amazon.com. As shown in Table 3, these shoes show a significantly lower matching score (average = 0.20) than those recommended by my system (average = 0.52). Similarly, the sentiment scores for each feature in the top-rated shoes are lower than those from my recommendations. More importantly, the percentages of reviews discussing the three preferred features are significantly higher for my recommendations (average = 50.1% for our recommendations versus 14.5% for the top-rated shoes). Different customers may like a product for various reasons. Thus, a product with a very high overall rating simply means that a lot of customers have found something or the other to like in the product. However, it does not necessarily mean that the product is well-suited to the specific preferences of a shopper.
作为说明,考虑一下用户告诉系统,一双跑鞋对她来说, 舒适性 , 支撑性和耐用性这三个特征很重要。 对于这三个功能,表2中显示了我系统中的三个建议,包括匹配分数(0到1之间),每个功能的Amazon调整后的情绪以及平均功能下的情绪。 为了评估我的建议,我考虑了Amazon.com上评分最高的三双跑鞋。 如表3所示,这些鞋子的匹配得分(平均= 0.20)明显低于我的系统推荐的得分(平均= 0.52)。 同样,评价最高的鞋子中每个功能的情绪得分也低于我的建议。 更重要的是,对我的建议来说,讨论这三种首选功能的评论百分比要高得多(平均=我们建议的50.1%,顶级鞋的14.5%)。 由于各种原因,不同的顾客可能喜欢产品。 因此,具有很高总体评价的产品只是意味着许多客户在产品中找到了喜欢的东西。 但是,这不一定意味着该产品非常适合购物者的特定喜好。

类似功能,价格更低? (Similar features for a lower price?)
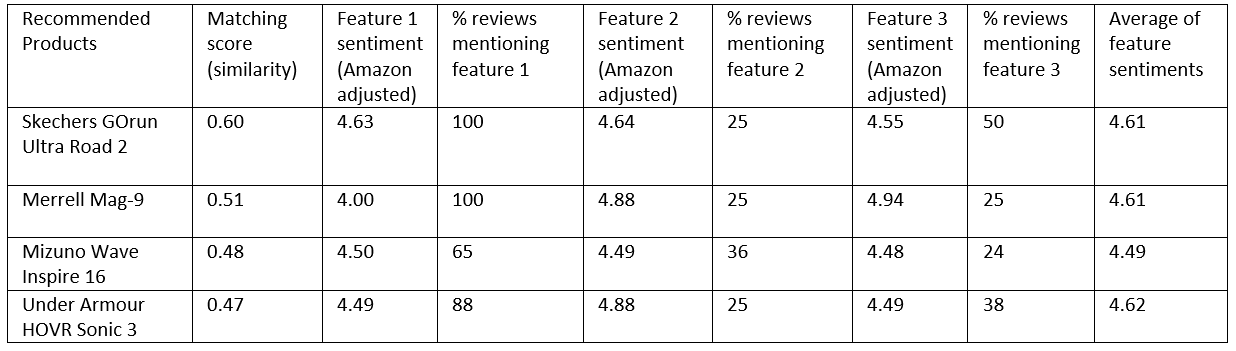
Notwithstanding the obvious attraction of big-name brands, my recommender system can find products that are priced lower than those of a top brand, but which share similar features, and possibly more positive sentiments on those features. For example, if the user specifies a product, the system calculates the association values between the product and each of the twelve features. It then selects three features with the highest association, and recommends, say, three products which are priced lower, but which have been praised by reviewers for the same features as the more expensive product. The results are shown below for the case where a user has specified Mizuno Wave Prophecy 8 with a retail price tag of $240 (Table 4).
尽管知名品牌具有明显的吸引力,但我的推荐系统仍可以找到价格低于顶级品牌但具有相似特征的产品,并且在这些特征上可能会有更多积极的情绪。 例如,如果用户指定了产品,则系统将计算产品与十二个特征中的每个特征之间的关联值。 然后,它选择具有最高关联性的三个功能,并推荐三种价格较低的产品,但与昂贵的产品相同的功能却受到评论家的好评。 用户指定Mizuno Wave Prophecy 8零售价为$ 240(表4)时,结果如下所示。

My system finds that the three features most associated with this product are cushion, stability and looks. Based on these features, the three alternative products suggested by the system are priced significantly lower ($120 to $150), while the matching scores are much higher, as are the feature sentiment scores (Table 5).
我的系统发现与该产品最相关的三个功能是缓冲 , 稳定性和外观 。 基于这些功能,系统建议的三种替代产品的价格明显较低(120美元至150美元),而匹配评分则高得多,功能情感评分也较高(表5)。

外卖 (Takeaways)
While electronic commerce has made it possible to offer an unlimited variety of products, the biggest obstacle to their success is the high burden of time and effort placed on the shopper to search, discover and evaluate a large set of unfamiliar choices. My approach recommends products by matching what a shopper wants in a product and what prior customers have written about their purchases. As a result, a consumer is presented with just a few choices with features she actually values in a product.
尽管电子商务使提供无限多种产品成为可能,但其成功的最大障碍是购物者在搜索,发现和评估大量不熟悉的选择上花费了大量的时间和精力。 我的方法通过匹配购物者对产品的需求以及以前的顾客写的关于购买的内容来推荐产品。 结果,向消费者提供了一些选择,这些选择具有她在产品中实际重视的功能。
Once again, the Python code I wrote for this project is available at: https://github.com/JoshB02/recommender-system-tools
再次提供我为该项目编写的Python代码, 网址为: https : //github.com/JoshB02/recommender-system-tools
基于用户兴趣偏好的画像方法















 5322
5322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









