





网络变压器
This is a technical tutorial on how to set up and add semantic search via transformers as an Elasticsearch index. We go through all steps needed and will introduce the utility class ElasticTransformers. Finally we will consider some speed comparisons.
这是一本技术教程,介绍如何通过转换器将语义搜索设置和添加为Elasticsearch索引。 我们将完成所有必要的步骤,并将介绍实用程序类ElasticTransformers。 最后,我们将考虑一些速度比较。
This is the last part of a three part series about Search. For the non-technical discussions of how this fits into the wider topic of search consider the previous two parts.
这是关于搜索的三部分系列的最后一部分。 对于非技术性的讨论如何使其适合更广泛的搜索主题,请考虑前面的两个部分。
Pt 1 was a gentle introduction to the typical building blocks of search engines
Pt 1是对搜索引擎典型构建模块的简要介绍
In Pt 2 we performed a side-by-side comparison of key words and contextual embeddings for search
在Pt 2中,我们对关键字和上下文嵌入进行了搜索的并排比较
Already in part 1 we saw how Elasticsearch provides a wide range of search capabilities out of the box. In this article we will show how to add one more — contextual semantic search
在第1部分中,我们已经看到Elasticsearch如何提供开箱即用的广泛搜索功能。 在本文中,我们将展示如何再添加一个-上下文语义搜索
“如何”(The “How to”)
I will briefly outline the approach here. You can also follow on github.
我将在这里简要概述该方法。 您也可以在github上关注。
建筑 (Architecture)
We will deploy locally Elasticsearch as a docker container. Data will be stored locally. Using Jupyter notebook, we will chunk the data and iteratively embed batches of records using the sentence-transformers library and commit to the index. Finally, we will also perform search out of the notebook. To enable, all of this, I prepared a utility class ElasticTransformers
我们将在本地将Elasticsearch部署为docker容器。 数据将存储在本地。 使用Jupyter笔记本,我们将对数据进行分块,并使用句子转换器库迭代地嵌入一批记录,然后提交给索引。 最后,我们还将在笔记本外执行搜索。 为此,我准备了一个实用程序类ElasticTransformers
积木 (The building blocks)
All of these steps are also documented in the github repo and performed as part of the notebooks included.
所有这些步骤也记录在github repo中,并作为所包含笔记本的一部分执行。
Data I am using A Million News Headlines by Rohk. The data represents about 18 years of headlines from ABC news. The long time span as well as the size of the dataset provides a good foundation for experimentation.
数据我正在使用Rohk的《百万新闻头条》 。 该数据代表了ABC新闻大约18年的头条新闻。 较长的时间跨度以及数据集的大小为实验提供了良好的基础。
Elasticsearch Docker container. A very quick and easy way to get started with Elasticsearch locally is by deploying it as a Docker container. Follow the steps here For this tutorial, you only need to run the two steps:
Elasticsearch Docker容器。 在本地开始使用Elasticsearch的一种非常快速简便的方法是将其部署为Docker容器。 请按照此处的步骤进行操作。对于本教程,您只需要运行两个步骤:
For vector search on elastic we use the dense vector search capability, thanks to these excellent resources
有关弹性矢量的搜索,我们用密集的矢量搜索功能,得益于这些优秀的资源
As mentioned, we use (SBERT) sentence-transformers for embedding as both a highly performant and very accessible way of accessing semantic similarity
如前所述,我们使用(SBERT)句子转换器进行嵌入,这是访问语义相似性的一种高性能且非常易于访问的方式
Using those utilities, we sequentially: create an index, write several different sizes of the dataset to index with embeddings and perform some experiments
使用这些实用程序,我们可以依次进行以下操作:创建索引,编写几种不同大小的数据集以使用嵌入进行索引并进行一些实验
对于懒惰的人,嗯,忙碌的人。(For the lazy… uhm, busy ones….)
Finally, all of these steps used to be complicated to perform. Thankfully, it’s 2020 and a lot of this is simpler: we can deploy a Elasticsearch on Docker (since 2016 actually) with 2 lines of code, transformers come pre-trained with some cutting edge libraries and we can accomplish all of the above out of the comfort of our Jupyter notebook…
最后,所有这些步骤过去执行起来都很复杂。 幸运的是,现在是2020年,而且很多事情都变得更简单了:我们可以在Docker上部署Elasticsearch(实际上是自2016年以来),只需两行代码,转换器就已经过一些尖端库的预培训,我们可以完成以上所有工作Jupyter笔记本的舒适性……
All of these steps are also documented in the github repo and performed as part of the notebooks included.
所有这些步骤也记录在github repo中,并作为所包含笔记本的一部分执行。
使用弹性变压器 (Working with Elastic Transformers)
ElasticTrasnformers builds on the elasticsearch library by simply wrapping some of the instantiation steps, adding simple utilities for index creation & mapping (something I personally always struggled with) and importantly an easy to use chunking tool for large documents that can write embeddings to the search index
ElasticTrasnformers建立在elasticsearch库通过简单地包装了一些实例化步骤,增加了对索引创建和映射(这是我个人一直挣扎)简单公用事业和重要的一个易于使用的,可写的嵌入到搜索索引大量的文档分块工具
Initialize class as well as (optionally) the name of the index to work with
初始化类以及(可选)要使用的索引的名称
et = ElasticTransformers(url = ’http://localhost:9300', index_name = 'et-tiny')Create specification for the index. Lists of relevant fields can be provided based on whether those would be needed for keyword search or semantic (dense vector) search. It also has parameters for the size of the dense vector as those can vary
创建索引规范。 可以基于是否需要关键词搜索或语义(密集向量)搜索来提供相关字段的列表。 它还具有稠密向量大小的参数,因为这些参数可能会有所不同
et.create_index_spec(
text_fields=[‘publish_date’,’headline_text’],
dense_fields=[‘headline_text_embedding’],
dense_fields_dim=768
)Create index — uses the spec created earlier to create an index ready for search
创建索引-使用之前创建的规范来创建可供搜索的索引
et.create_index()Write to large files — breaks up a large csv file into chunks and iteratively uses a predefined embedding utility to create the embeddings list for each chunk and subsequently feed results to the index. In the notebooks, we show an example of how to create the embed_wrapper, notice that the actual embedder can therefore be any function. We use sentence-transformers with distilbert because it provides a nice balance between speed and performance. However, this can vary for the use case you are interested in.
写入大型文件-将大型csv文件分解为多个块,并迭代使用预定义的嵌入实用程序为每个块创建嵌入列表,然后将结果馈入索引。 在笔记本中,我们显示了如何创建embed_wrapper的示例,请注意,实际的嵌入器因此可以是任何函数。 我们将句子转换程序与distilbert一起使用,因为它在速度和性能之间实现了很好的平衡。 但是,这可能会因您感兴趣的用例而异。
et.write_large_csv(‘data/tiny_sample.csv’,chunksize=1000,embedder=embed_wrapper,field_to_embed=’headline_text’)Search — can select either keyword (‘match’ in Elastic) or contextual (‘dense’ in Elastic) search. Note, it requires the same embedding function used in write_large_csv. This only checks if type = ‘dense’ to treat is as embedding search otherwise can take the common: ‘match’, ‘wildcard’, ‘fuzzy’, etc.
搜索-可以选择关键字(在Elastic中为“ match”)或上下文(在Elastic中为“ dense”)搜索。 注意,它需要与write_large_csv中使用的嵌入功能相同。 这只会检查是否将type ='dense'视为嵌入搜索,否则可以采用常见的值:'match','wildcard','fuzzy'等。
et.search(query = ’search these terms’, field = ’headline_text’, type = ’match’, embedder = embed_wrapper, size = 1000)We will index data from A Million News Headlines in several different index sizes (tiny: 1k, medium: 100k and large: 1.1million (all) headlines). Finally, we will use those to perform some speed comparisons.
我们将以数种不同的索引大小(一小:1000万,中:10万和大:110万(所有)标题)为“百万新闻头条”的数据编制索引。 最后,我们将使用它们来执行一些速度比较。
速度… (Speed…)
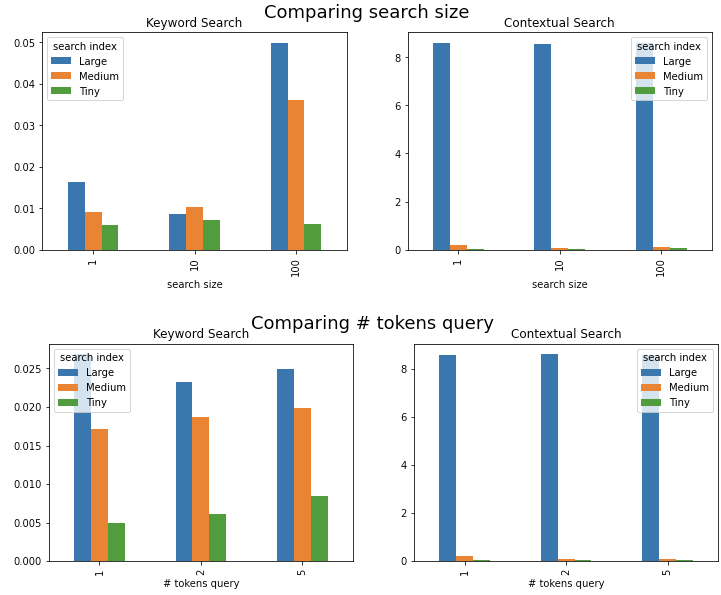
We just indexed about 1.1 million sentences, but does all this actually scale? Naturally, there will always be a slowdown when scanning a massive index, but how much?
我们刚刚索引了约110万个句子,但这是否真的可以扩展? 自然地,在扫描大量索引时总会放慢速度,但是要多少呢?
I performed several tests (each with 10 repetitions):
我进行了几项测试(每项测试均重复10次):
- Queries of different length: 1, 2, & 5 tokens 不同长度的查询:1、2和5个令牌
- Queries with different size of results 1, 10 and 100 results具有不同结果大小,1、10和100个结果的查询
Results are in the below charts:
结果在以下图表中:
- Keyword search — about 8x slowdown for a 1000x increase in index size, 4x slowdown for a 100x increase in result size. All of this under 10ms 关键字搜索-索引大小增加1000倍,速度降低约8倍,结果大小增加100倍,速度降低4倍。 所有这些都在10ms以内
- However, on the contextual search side, performance slows down significantly with an individual search from a Large (1mn) index taking up to 8sec. This seems definitely a significant slowdown compared to say the midsized index of 100k taking up still significantly less than 1sec 但是,在上下文搜索方面,从大型(1mn)索引进行单个搜索最多需要8秒钟,因此性能会显着降低。 与说100k的中型索引占用时间还不到1秒相比,这无疑是一个显着的放缓
Notably, the common requirement on interactive search applications is for results to be retrieved in under 1sec, in some cases under 300ms, hence this is a significant slowdown. Some solutions are explored below
值得注意的是,对交互式搜索应用程序的普遍要求是要在1秒以内检索结果,在某些情况下是在300ms以内,因此这是一个显着的减慢。 下面探讨了一些解决方案
提高速度(Improving speed)
Speed of search is a crucial aspect as search often needs to be interactive and document size will often be significant. In this case, we can see that there is an exponential slow down with size of the dataset. This is due to the fact that we are comparing all documents against the query, vs using an inverted index in the keyword search approach. A number of ways exist to fix this but unfortunately they come with trade-offs with respect to accuracy.
搜索速度是至关重要的方面,因为搜索通常需要是交互式的,并且文档的大小通常很重要。 在这种情况下,我们可以看到数据集的大小呈指数下降。 这是由于以下事实:我们将所有文档与查询进行比较,而不是在关键字搜索方法中使用反向索引。 有多种方法可以解决此问题,但不幸的是,它们在准确性方面需要进行权衡。
For instance, Approximate nearest neighbour (ANN) approaches would use less space and perform faster at the cost of sometimes returning results which are not exactly the most relevant — for implementations check out Faiss or Annoy as well as this great example on mixing embeddings, keyword search and using Faiss. A great talk about different trade off of ANN at scale and how to choose one — Billion-scale Approximate Nearest Neighbor Search. Another approach might be to perform agglomerative clustering and collect the relevant number of results at retrieval time only. Check out fastcluster for an implementation.
例如,近似最近邻(ANN)方法将使用较少的空间并以更快的速度执行,但有时返回的结果并不完全相关,这可能与Faiss或Annoy以及有关混合嵌入,关键字的出色示例有关搜索并使用Faiss。 关于规模化ANN的不同权衡以及如何选择一个问题的精彩演讲-十亿规模的“近似最近邻居搜索”。 另一种方法可能是执行聚集聚类,并仅在检索时收集相关数量的结果。 查看fastcluster的实现。
Haystack provides an extensive framework for combining transformers with search. However, queries are considered as natural language questions and a QA answering framework is employed. The difference is that, in QA framework the quality of the match between a query and each individual candidate document is evaluated as a pair. This is in itself a significantly more computationally expensive problem, as opposed to what we are doing here where each document is represented by an embedding which is compared to the query at runtime. The bigger computational load is dealt with initially reducing the search space to a smaller number of relevant candidates.
Haystack提供了一个广泛的框架,可将变压器与搜索结合在一起。 但是,查询被视为自然语言问题,并且使用了QA回答框架。 区别在于,在QA框架中,查询和每个单独的候选文档之间的匹配质量是成对评估的。 与我们在这里所做的相反,在这里,每个文档都由嵌入表示,而在运行时将其与查询进行比较,这本身就是一个在计算上更加昂贵的问题。 最初需要将搜索空间减少到较少数量的相关候选对象,以应对更大的计算量。
冗长的文件 (Lengthy documents)
The contextual solution we have seen is limited by the document size too - constrained by the token limitations of the transformers models. In this case, we can fit up to 512 tokens (word-like chunks, e.g. the word look is one token, looking is two tokens — look & ing, etc.). Such a constraint works well with a headline or even a paragraph but not full sized documents, e.g. news article body, research papers, etc.
我们所看到的上下文解决方案也受文档大小的限制-受转换器模型的令牌限制的约束。 在这种情况下,我们最多可以容纳512个令牌(类似单词的块,例如单词look是一个令牌, look是两个令牌-look&ing等)。 这样的约束条件适用于标题甚至段落,但不适用于完整的文档,例如新闻正文,研究论文等。
These models can be extended to take in longer sequences however they grow quadratically in memory usage with the increase of length. Common solutions tend to keep the standard length, but use workarounds, e.g. some averaging of embeddings where relevant. This is still an active area of research with one notable recent addition being BigBird — a Google Research transformer based model which can handle longer sequences while keeping memory usage growth linear to the size of the document
这些模型可以扩展为采用更长的序列,但是随着内存长度的增加,它们在内存使用量中的增长也呈二次方增长。 常见的解决方案倾向于保持标准长度,但是使用变通方法,例如在相关时对嵌入进行一些平均。 这仍然是一个活跃的研究领域,最近还有一个引人注目的新功能是BigBird,这是一种基于Google Research转换器的模型,可以处理更长的序列,同时使内存使用量的增长与文档的大小保持线性关系。
结论 (Conclusion)
We have seen how to easily deploy an Elasticsearch container and index it with some of the most powerful contextual embeddings available to us. Evaluation showed that semantic search might slow down for large indices and, however, we have also considered some alternative solutions to this.
我们已经看到了如何轻松部署Elasticsearch容器并使用一些可用的最强大的上下文嵌入对其进行索引。 评估表明,对于大索引,语义搜索可能会变慢,但是,我们还考虑了一些替代方法。
The future of this field remains very hopeful and increasingly accessible.
这个领域的未来仍然充满希望,并且越来越容易获得。
Hopefully, this was useful. Thank you for reading. If you feel like saying Hi or just like to tell me I am wrong, feel free to reach out via LinkedIn
希望这是有用的。 感谢您的阅读。 如果您想打招呼或只是想告诉我我错了,请随时通过LinkedIn与我们联系
翻译自: https://towardsdatascience.com/elastic-transformers-ae011e8f5b88
网络变压器















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









