





Everything changes. Time is a measure of change. I’d go so far to say that change is the most powerful force in the universe. Even truth is subject to change. What is true today is not necessarily true tomorrow. Throughout recorded history, we can see the power of change.
一切都变了。 时间是变化的量度。 我要说的是,变化是宇宙中最强大的力量。 甚至真理也会改变。 今天的真实并不一定明天的真实。 在整个记录的历史中,我们可以看到变化的力量。
Technological innovations brought about by changes in thinking often create their own empires. I understand the power of change and when I look at history, I realize I can’t fight changes that bring technological advancements, I have to embrace the change. Yet, oddly enough, it is part of human nature to like things just the way they are. Sometimes I fight the changes even though I know it is folly.
思维变化带来的技术创新通常会建立自己的帝国。 我了解变化的力量,当我回顾历史时,我意识到我无法与带来技术进步的变化抗衡, 我必须接受变化 。 然而,奇怪的是,以某种方式喜欢事物是人类的一部分。 有时,即使我知道这很愚蠢,我还是会与之抗争。
The technology industry is constantly changing, reinventing itself to enable new capabilities. Compare technology to another industry like health care and feels like it's like comparing dog years to a human life span. I work in the tech industry, I must constantly learn new technologies just to keep up with all the changes.
技术行业在不断变化,不断创新以实现新功能。 将技术与医疗保健等其他行业进行比较,就好像将狗年与人类的寿命进行比较一样。 我从事科技行业,我必须不断学习新技术,以跟上所有变化。
Three years ago, I was happily employed as a Principal Sales Consultant at Oracle Corporation. I had several years of experience with Java and Oracle and was happy and content in my role. In my humble opinion, Oracle was, (and still is) probably the greatest relational database in the world.
三年前,我很高兴被聘为Oracle Corporation的首席销售顾问。 我在Java和Oracle方面有几年的经验,很高兴并且对自己的角色感到满意。 以我的拙见,Oracle曾经是(现在仍然是)世界上最大的关系数据库。
Today I am employed as a Senior Solutions Architect at MongoDB. This article explains why I made the switch from Oracle to MongoDB. More importantly, I hope to give you some insight as to the changes going on right now inside the tech industry when it comes to databases.
今天,我受聘为MongoDB的高级解决方案架构师。 本文说明了为什么我从Oracle切换到MongoDB。 更重要的是,我希望给您一些有关数据库中技术行业目前正在发生的变化的见解。
Over the past couple of decades, I have seen many iterations of various programing platforms rise and fall in popularity based on major technological paradigm shifts.
在过去的几十年中,我看到各种编程平台的许多迭代都基于主要的技术范式变化而流行起来。
尽管发生了所有这些变化,但仍有一个核心真理:数据具有价值。 (In spite of all this change, there is one central truth: data has value.)
Many technologies developed to access and display the data in a database have come and gone. Yet the paradigm of the database, a place to store and retrieve data, has changed relatively little, until recently.
为访问和显示数据库中的数据而开发的许多技术已经消失。 然而,直到最近,数据库的范式(用于存储和检索数据的地方)的变化相对较小。
Over the past 40 years we witnessed the migration from mainframe to client-server technologies, then to distributed processing on the web, and in the process saw all the programing paradigms shift. Then the concept of the web began to evolve to the concept of cloud.
在过去的40年中,我们目睹了从大型机到客户端-服务器技术的迁移,然后到Web上的分布式处理的迁移,并且在此过程中看到了所有编程范例的转变。 然后,网络的概念开始演变为云的概念。
Communication between systems is not only critical, today it's central to the success of running any sort of business. Moving data from one system to another requires having a way to describe the data in a commonly understood format between the systems.
系统之间的通信不仅至关重要,而且今天对于成功运行各种业务至关重要。 将数据从一个系统移动到另一个系统需要有一种方法来描述系统之间通常理解的格式的数据。
Extensible markup language (XML)and JavaScript Object Notation (JSON) are different ways of representing data as it is transferred from one system to another. Originally the favored method of communicating between systems was Web Services and something like SOAP (Simple Object Acess Protocol). Together with a Web Service Definition Language (WSDL) file and an XML message I could do just about anything.
当数据从一个系统传输到另一个系统时,可扩展标记语言(XML)和JavaScript对象表示法(JSON)是表示数据的不同方式。 最初,系统之间进行通信的首选方法是Web服务和诸如SOAP(简单对象访问协议)之类的东西。 连同Web服务定义语言(WSDL)文件和XML消息,我几乎可以做任何事情。
Today, Representational State Transfer (REST) and JSON are pretty much the favored standard. JSON is a bit easier on the eyes and considered more human-readable.
如今,代表性状态传输(REST)和JSON几乎成为了最受欢迎的标准。 JSON在您看来更容易一些,并且被认为更容易理解。
A Sample Customer Record in XML format:
XML格式的客户记录样本:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<address>
<city>New York</city>
<postalCode>10021</postalCode>
<state>NY</state>
<streetAddress>21 2nd Street</streetAddress>
</address>
<age>25</age>
<gender>Male</gender>
<customerId>100123</customerId>
<firstName>John</firstName>
<lastName>Smith</lastName>
<phoneNumber>
<element>
<number>212 555-1234</number>
<type>home</type>
</element>
<element>
<number>646 555-4567</number>
<type>fax</type>
</element>
</phoneNumber>
</root>A Sample Customer Record in JSON Format:
JSON格式的客户记录样本:
{
"customerId":"100123",
"firstName": "John",
"lastName": "Smith",
"age": 25,
"gender": "Male",
"address":
{
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"phoneNumber":
[
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "fax",
"number": "646 555-4567"
}
]
}In 2006 Amazon Web Services was officially launched offering Simple Storage Service (S3) and Elastic Compute Cloud (EC2).
2006年,Amazon Web Services正式启动,提供简单存储服务(S3)和弹性计算云(EC2)。
Fourteen years later, the infrastructure, platforms, and software hosting just about all the applications we interact with are either running in the cloud, or they are communicating with systems running in the cloud. In the tech industry, we are embracing the cloud because we have to, the speed and scale cloud offers for application development cannot be ignored.
十四年后,托管几乎所有与我们交互的应用程序的基础结构,平台和软件要么在云中运行,要么与在云中运行的系统通信。 在技术行业中,我们正在拥抱云,因为我们必须忽略云为应用程序开发提供的速度和规模。
REST itself is now facing a new challenger. GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data. GraphQL was developed internally by Facebook in 2012 before being publicly released in 2015. It is gaining serious traction in 2020.
REST本身现在面临着新的挑战者。 GraphQL是一种用于API的开源数据查询和操作语言,并且是用于使用现有数据执行查询的运行时。 GraphQL由Facebook内部于2012年开发,然后于2015年公开发布。它在2020年将受到严重关注。

GraphQL has an advantage over REST. The REST API has a rigid framework and the result returned is predefined when the program is written. GraphQL allows the developer to shape the response and only return the fields the developer needs. Additionally, GraphQL provides a framework for “Mutation” or changing data through inserts, updates, and deletes. It saves all the time necessary to develop a rest API for every possibility. I can easily predict that GraphQL will be the dominant standard in the future. It is important to note that GraphQL still uses JSON as the default response.
GraphQL优于REST。 REST API具有严格的框架,并且在编写程序时预定义了返回的结果。 GraphQL允许开发人员调整响应并仅返回开发人员需要的字段。 此外,GraphQL提供了一个“突变”或通过插入,更新和删除来更改数据的框架。 它节省了开发每种可能性的Rest API所需的所有时间。 我可以轻松地预测GraphQL将成为未来的主导标准。 重要的是要注意,GraphQL仍使用JSON作为默认响应。

Up until the year 2017 the one constant through all this change was the database itself. Of all the technical knowledge that I learned, what served me well, and became the one thing that stood out with little need for change was my knowledge of Relational Database Design.
直到2017年,所有这些更改中唯一不变的是数据库本身。 在我学到的所有技术知识中,什么对我很有用,并且成为一件几乎不需要更改的事情就是我对关系数据库设计的了解。
My knowledge of Oracle and Structured Query Language (SQL) kept me employed with a healthy salary through all of the technical paradigm changes. While the rest of technology evolved and changed, the relational paradigm remained relatively static since its inception by Larry Ellison on June 16, 1977.
我对Oracle和结构化查询语言(SQL)的了解,使我在所有技术范式变更中都能获得稳定的薪水。 在其他技术不断发展和变化的同时,关系范式自1977年6月16日由拉里·埃里森(Larry Ellison)创立以来一直相对静止。
Over the last 43 years, the relational database did not change much. Data is sticky. It has value. Knowing how to get data, store it, and manipulate it is a way to guarantee stable well-paid employment in the tech industry.
在过去的43年中,关系数据库变化不大。 数据是粘性的。 它具有价值。 知道如何获取,存储和操作数据是保证技术行业稳定高薪工作的一种方式。

Oracle and the relational database concept has remained relatively unchanged for a very very very long time in technology.
Oracle和关系数据库的概念在技术上非常非常长时间以来一直保持相对不变。
Today when I use a modern Web Services or REST, I literally have to travel back in time 40 years, conceptually speaking, to store it in a relational database. When I store data sent in an XML or JSON message I have to break the message down into separate tables every time I put the data from the message into a relational database.
今天,当我使用现代Web服务或REST时,从概念上讲,我实际上必须回溯40年才能将其存储在关系数据库中。 当我存储以XML或JSON消息形式发送的数据时,每次将消息中的数据放入关系数据库时,都必须将消息分解为单独的表。
Then I have to reassemble the object from different tables every time I want to send data to another system. The mismatch between the JSON document and the relational database is called “Impedance Mismatch.” Its a war fought every day by developers that have to break the JSON document into pieces that go into different tables. That is a lot of work, and I made a good living doing exactly that kind of work.
然后,每次要将数据发送到另一个系统时,都必须从不同的表重新组合对象。 JSON文档和关系数据库之间的不匹配称为“阻抗不匹配”。 开发人员每天都在打仗,他们不得不将JSON文档分解成不同的表,并将它们分成不同的表。 那是很多工作,而我正是通过这种工作过得很好。
Our Sample Customer JSON Document in a Relational Database:
我们在关系数据库中的样本客户JSON文档:

Relational databases have always had a central weakness. They break the world down into separate tables based on an idea of normalization. This is done to eliminate repeating values in the rows of a table. I stop repeating values by splitting the attributes that cause repetition off into its own table and create a primary key in one table and a foreign key in the other to join the two together. For example, if we put all the data in one table the customer_id value 100123, age 25, gender “Male,” and the name “John Smith” have to be repeated for every phone number and address combination.
关系数据库一直有一个中心弱点。 他们根据规范化的想法将世界分解为单独的表。 这样做是为了消除表行中的重复值。 我通过将导致重复的属性拆分到自己的表中并在一个表中创建一个主键,在另一个表中创建一个外键以将两个表连接在一起,来停止重复值。 例如,如果我们将所有数据放在一个表中,则必须对每个电话号码和地址组合重复使用customer_id值100123,年龄25,性别“男”和名称“约翰·史密斯”。
To keep from repeating these values I break the data down into three tables, a customer table, a phone table, and an address table. Then I link the tables off of only one repeating value, the Customer_ID. It is all well and good for storage. But no so well and good for the poor developer who has to write all the code to take the JSON document apart and stick it in the right tables.
为了避免重复这些值,我将数据分为三个表,一个客户表,一个电话表和一个地址表。 然后,我仅将一个重复值Customer_ID与表链接起来。 一切都很好,适合存放。 但是对于那些必须编写所有代码以将JSON文档拆开并粘贴在正确表中的可怜的开发人员来说,情况并没有那么好。

The biggest computational problem comes when I want to report against large volumes of that data. I need to join the tables back together. Those joins work fine on a relatively small data set. When I have millions of rows of data it works great. Perhaps hundreds of millions of rows of data, relational will still work if I tune the database and optimize my SQL query.
当我想针对大量数据进行报告时,最大的计算问题就来了。 我需要将表重新连接在一起。 这些连接在相对较小的数据集上工作良好。 当我有数百万行的数据时,它的效果很好。 如果我调整数据库并优化我SQL查询,也许数亿行的数据关系仍将起作用。
Think of customers and orders… or call data records (CDRs) at a telecom provider. Each order or call data record is a row in a table. I can easily reach billions of rows in a short time period. Think about what the size of Amazon's orders must look like on a daily basis. Now think of what that looks like for a week, a month… a year. Imagine billions, even trillions of rows of data that have to be joined across many tables. Relational database systems really struggle with this volume of data.
考虑一下客户和订单…或电信提供商的呼叫数据记录(CDR)。 每个订单或呼叫数据记录都是表中的一行。 我可以在短时间内轻松达到数十亿行。 考虑一下亚马逊每天的订单量。 现在想想一周,一个月……一年的情况。 想象一下数十亿甚至数万亿行的数据必须跨多个表进行联接。 关系数据库系统确实难以处理如此大量的数据 。
关系数据库从来没有很好地扩展 (Relational databases never did scale very well)
Here is a somewhat hidden secret in the tech industry… Relational databases never did scale very well. The reason is simple, relational joins are extremely expensive when it comes to computational resources. Try running a Structured Query Language (SQL) statement that joins several tables against tens of terabytes of data. It doesn't work on a single server in 3rd normal form. It never did.
这是技术行业中一个隐藏的秘密 ……关系数据库从来没有很好地扩展。 原因很简单,关系连接在计算资源方面非常昂贵。 尝试运行结构化查询语言(SQL)语句,该语句将针对数十兆字节数据的多个表联接在一起。 它不能以第三普通形式在单个服务器上运行。 从来没有。

To handle reporting against extremely large volumes of relational data, a concept was formed called “data warehousing.” To get data of that scale (hundreds of billions of rows of data) to work I have to “denormalize” the data. A “star schema” is a very flat denormalized schema to join from a dimension like time or region to a “fact” table that has everything in it. The fact table is all nice and flat, it is one huge table.
为了处理针对大量关系数据的报告,形成了一个称为“ 数据仓库 ”的概念。 为了使这种规模的数据(数千亿行数据)正常工作,我必须对数据进行“ 非规范化 ”。 “ 星型模式 ”是一种非常扁平的非规范化模式,可以从诸如时间或区域之类的维度连接到包含所有内容的“事实”表。 事实表非常漂亮而且平坦,它是一个巨大的表。
Data warehousing works because it denormalizes the data, and eliminates joins. The only downside to data warehousing is, I have to write complex Extract Transform and Load (ETL) processes to move data from the Online Transactional Processing (OLTP) database to the Data Warehouse database. The ETL is responsible for denormalizing the data from 3rd normal form in the OLTP database and getting rid of the need to join multiple tables together. It will take the customer data in the three tables and add it to the order data and product data in one giant fact table, repeating values if necessary. The key here is I only have to join from one or two dimensions to the fact table. The data warehouse works because I eliminated the majority of joins between tables.
数据仓库之所以起作用,是因为它可以规范化数据并消除联接。 数据仓库的唯一缺点是,我必须编写复杂的提取转换和加载(ETL)流程,才能将数据从在线事务处理(OLTP)数据库移至数据仓库数据库。 ETL负责使OLTP数据库中的第三范式的数据标准化,并消除将多个表连接在一起的需要。 它将把三个表中的客户数据收集到一个巨型事实表中的订单数据和产品数据中,并在必要时重复这些值。 这里的关键是我只需要从一个或两个维度连接到事实表。 数据仓库之所以有效,是因为我消除了表之间的大多数联接。
The Data Warehouse paradigm works, I keep the OLTP database small and nimble and archive data through ETL to the data warehouse. It is expensive and time-consuming, but up until now, it has worked.
数据仓库范例可以正常工作,我使OLTP数据库小而灵活,并通过ETL将数据存档到数据仓库。 它既昂贵又费时,但是直到现在,它仍然有效。
But, it's not just the increase in the volume of data that has changed over time, its the nature of the data we need to process. Now we have unstructured log data, sentiment analytics, thumbs up, thumbs down, emojis, memes, and graphical representations of data.
但是,随着时间的推移,变化的不仅仅是数据量的增加,还有我们需要处理的数据的性质。 现在,我们有了非结构化的日志数据,情绪分析,支持,反对,表情符号,模因和数据的图形表示。
The problem goes beyond the impedance mismatch or the unstructured nature of the new data, it is the velocity of data change we need to process. New fields are added frequently by agile development shops. IoT devices will be sending new data streams. All of this has to be modeled in 3rd normal form before I can insert a single piece of data in a relational system. Now the database itself meets the most powerful force in the universe, change. The underlying technology of the relational database has to change to meet the demands of new technology.
问题超出了阻抗失配或新数据的非结构化性质的范围,这是我们需要处理的数据更改速度。 敏捷开发商店经常添加新字段。 物联网设备将发送新的数据流。 在我可以在关系系统中插入单个数据之前,所有这些都必须以第三范式建模。 现在,数据库本身遇到了宇宙中最强大的力量,即变化。 关系数据库的基础技术必须进行更改以满足新技术的需求。
For now, let's just go back to the change in data volume over time. Look at the sheer size of the data growth. What are we up against? Why is the relational database paradigm reaching its end?
现在,让我们回到数据量随时间的变化。 看一下数据增长的巨大规模。 我们要面对什么? 为什么关系数据库范式达到终点?
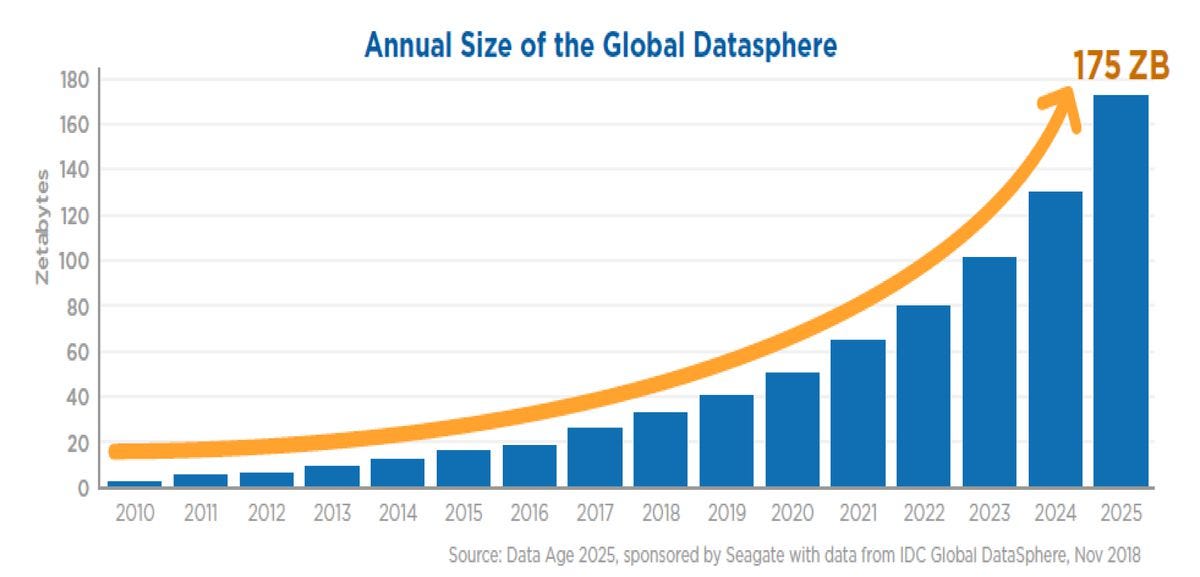
The IDC estimates will 175 ZettaBytes will be generated annually by 2025. The information is shared in the report, Data Age 2025, sponsored by Seagate Technology. The growth of this data will be the result of the incorporation of intelligent agents that use machine learning and other forms of artificial intelligence to analyze the growing amount of data generated by the digital things in our lives.
IDC估计,到2025年,每年将产生175 ZettaBytes。该信息在希捷科技公司赞助的数据时代2025报告中共享。 这些数据的增长将是整合了智能代理的结果,这些智能代理使用机器学习和其他形式的人工智能来分析我们生活中数字事物所生成的不断增长的数据量。
Whats a ZettaByte? Its 10²¹ Bytes or a trillion gigabytes. It's worth seeing the number of bytes in a ZettaByte, a 1 followed by 21 zeros.
什么是ZettaByte? 它的10²¹字节或一兆兆字节。 值得一看的是ZettaByte中的字节数,一个1后跟21个零。
1 ZettaByte = 1,000,000,000,000,000,000,000字节 (1 ZettaByte = 1,000,000,000,000,000,000,000 bytes.)
Today in 2020, we produce about 50 ZettaBytes annually. That number will more than triple in the next 5 years. The pain that relational systems feel today will be much worse in the near future. Just look at the graph and see that 10 years ago we produced less than 5 ZettaBytes. The pain was recognizable then, and relational systems had to introduce clustering technology and sharding just to stay relevant.
2020年的今天,我们每年生产约50 ZettaBytes。 在接下来的五年中,这个数字将增长三倍以上。 关系系统今天所感受到的痛苦在不久的将来会更加严重。 只要看一下图表,就会发现10年前我们生产了不到5个ZettaBytes。 当时的痛苦是可以识别的,关系系统必须引入集群技术和分片才能保持关联性。
Something has to change to eliminate all the joins that a relational database has to do just to function. Something that can support JSON natively so we don't have to take it apart and reassemble it every time we need to communicate with a different system. Something that can handle trillions of data points that constantly have new data fields added.
必须进行某些更改以消除关系数据库仅需执行的所有联接即可。 可以原生支持JSON的东西,因此我们不必在每次需要与其他系统进行通信时拆开它并重新组装它。 可以处理数万亿个数据点的事物,不断添加新的数据字段。
输入MongoDB…。 (Enter MongoDB….)

The year was 2008 and the winds of change for the database began to blow. A young developer working with JSON was frustrated by relational design. His name was Eliot Horowitz. Every project he worked on was stymied by the upfront data modeling requirements and lack of scalability inherent in relational databases. So in 2008, he decided to fix the problem. He wanted to create a highly available “Humongous” database that could scale on commodity hardware and would store JSON documents directly. Mongo is short for humongous.
那一年是2008年,数据库的变化之风开始刮起。 一个使用JSON的年轻开发人员对关系设计感到沮丧。 他的名字叫艾略特·霍洛维茨(Eliot Horowitz)。 他从事的每个项目都受到前期数据建模要求和关系数据库固有的可伸缩性的限制。 因此,在2008年,他决定解决此问题。 他想创建一个高度可用的“大型”数据库,该数据库可以在商品硬件上扩展并直接存储JSON文档。 蒙哥(Mongo)是巨大的简称。
I will let you hear him speak in his own words about MongoDB. Take 5 minutes, if you have it, and watch the video below. It is well worth your time.
我会让您听到他用他自己的话语谈论MongoDB。 如果有的话,请花费5分钟,然后观看下面的视频。 非常值得您花时间。
From day one MongoDB was scalable. It is built on the principle of horizontal sharding. I can scale the database by partitioning data across shards that run on separate commodity servers. It is also highly available each shard replicates its data two a minimum of two secondary nodes. So MongoDB, by default is both highly available, and scalable.
从第一天开始,MongoDB就具有可伸缩性 。 它基于水平分片的原理。 我可以通过在单独的商品服务器上运行的分片上对数据进行分区来扩展数据库。 每个分片(至少两个辅助节点)复制其数据的可用性也很高 。 因此,默认情况下,MongoDB既具有高可用性,又具有可伸缩性。
MongoDB is a document database. I simply store the JSON document I receive through REST directly in the database. Every field in the document can be indexed so it's super fast. It also eliminates the need for joins within a JSON object. It overcomes the impedance mismatch between relational and a JSON object because it stores the JSON object as it is.
MongoDB是一个文档数据库。 我只是将通过REST收到的JSON文档直接存储在数据库中。 文档中的每个字段都可以被索引,因此它非常快。 它还消除了在JSON对象内进行联接的需要。 它克服了关系对象和JSON对象之间的阻抗不匹配的问题,因为它按原样存储JSON对象。
Developers love it because it speeds up development. They don’t have to model everything in 3rd normal form anymore. I can do joins across documents if I so desire, but the JSON object itself is stored intact in contiguous blocks on disk. So again it's super fast. I can read and write a multiple of JSON documents for each input-output operation per second.
开发人员喜欢它,因为它可以加快开发速度。 他们不再需要以第三范式来建模所有内容。 如果需要,我可以跨文档进行联接,但是JSON对象本身完整存储在磁盘上的连续块中。 因此,它又超级快。 我每秒可以为每个输入输出操作读写多个JSON文档。
MongoDB writes documents to disk in contiguous blocks, unlike a relational database that has to write data in different sectors on the disk depending on where the relational tables are stored. This is a HUGE deal, it leads to an incredible leap forward in performance.
MongoDB以连续块的形式将文档写入磁盘,这与关系数据库不同,后者必须根据关系表的存储位置在磁盘的不同扇区中写入数据。 这是一笔巨大的交易,它带来了令人难以置信的性能飞跃。
The ingest rate exceeds the input-output operation per second (IOPS). A couple of years ago, I was doing a test with an online testing service that wanted to insert at least 100,000 documents per second. They built the MongoDB cluster to handle 100,000 IOPS. During the test, they only saw the MongoDB cluster go to 20,000 IOPS. Yet they were inserting 100,000 documents every second. Confused, we looked at the logs and confirmed they were inserting about 5 times the number of documents we expected. MongoDB was inserting 5 documents for every input operation available. The test harness generated 100,000 documents per second, but only utilized 20% of the capacity available. Because they built the MongoDB cluster for 100,000 IOPS, they could easily get 500,000 documents per second without having to scale any further.
摄取速率超过了每秒的输入输出操作(IOPS)。 几年前,我正在使用在线测试服务进行测试,该服务希望每秒至少插入100,000个文档。 他们构建了MongoDB集群来处理100,000 IOPS。 在测试期间,他们只看到MongoDB集群达到20,000 IOPS。 但是他们每秒插入100,000个文档。 感到困惑的是,我们查看了日志,并确认它们插入的文件数量约为我们预期的5倍。 MongoDB为每个可用的输入操作插入5个文档。 测试工具每秒生成100,000个文档,但仅利用了可用容量的20%。 由于他们以100,000 IOPS的价格构建了MongoDB集群,因此他们可以轻松地每秒获得500,000个文档,而无需进一步扩展。
2016年6月28日,发布了Atlas:MongoDB的数据库即服务 (On June 28, 2016, Announced Atlas: Database as a Service for MongoDB)
Having a humongous highly available, scalable, JSON document database is awesome on its own. But having it run on all three of the major cloud providers is something else entirely. Within minutes I can deploy a MongoDB cluster in any cloud provider (AWS, GCP or Azure) in just about any region in the world. Wow!
拥有庞大的高可用性,可扩展的JSON文档数据库本身就很棒。 但是让它在所有三个主要的云提供商上运行完全是另外一回事。 几分钟之内,我就可以在全球几乎任何地区的任何云提供商(AWS,GCP或Azure)中部署MongoDB集群。 哇!
当我在Oracle工作时,对MongoDB的感觉可以用一个词来定义,而这个词就是“恐惧” (When I worked at Oracle, the feeling about MongoDB could be defined in one word, and that word was “fear”)

MongoDB was a document database that ran on commodity hardware. It had a GPL opensource offering and it was powerful. At Oracle, MongoDB was alien to us, and yet we could not deny that it was a force to be reckoned with because so many of our customers were adopting it and using it on new projects with great success. Now the paid version was offered in the cloud.
MongoDB是在商品硬件上运行的文档数据库。 它具有GPL开源产品,功能强大。 在Oracle,MongoDB对我们而言是陌生的,但是我们不能否认它是一支不可忽视的力量,因为我们的许多客户正在采用它并将其用于新项目中,并取得了巨大的成功。 现在,付费版本已在云中提供。
In March of 2017, Oracle released 12c R2 (after launching it first in the Oracle cloud) to be used on-premises. To my knowledge, it was the first R2 release that contained a new feature. Normally the R2 release at Oracle is just bug fixing of the R1 release. What new feature had to be released in R2? It was sharding. The reason sharding was released in R2 was that the Oracle customer base was begging for it.
2017年3月,Oracle发布了12c R2(在Oracle云中首次启动它之后),以供本地使用。 据我所知,这是第一个包含新功能的R2版本。 通常,Oracle的R2版本只是R1版本的错误修复。 R2中必须发布什么新功能? 它正在分片 。 在R2中发布分片的原因是Oracle客户群在乞求它。
The latest example of Oracle reacting to MongoDB was made on August 13th, 2020 with the announcement of “Oracle Autonomous JSON Database.” Touted as a full-featured database for developers working with JSON data, it is advertised to have “The JSON Features of MongoDB and More…” I will write another article addressing the limitations of Oracle’s attempt at JSON, but suffice it to say it does reinforce my arguments. In my opinion, Oracle is scared of MongoDB. At a minimum, the release of the Oracle JSON database is a nod to the fact that developers want to store their data in JSON format.
Oracle对MongoDB做出React的最新示例是在2020年8月13日发布的“ Oracle自主JSON数据库”。 它被吹捧为使用JSON数据的开发人员的全功能数据库,被宣传为具有“ MongoDB的JSON功能及更多功能……”。我将写另一篇文章,探讨Oracle尝试JSON的局限性,但足以说明加强我的论点。 我认为,Oracle害怕MongoDB。 至少,Oracle JSON数据库的发布是对开发人员希望以JSON格式存储其数据的一种认可。
Back in 2016 at Oracle, we were struggling with our own cloud offering as we made great attempts to pivot to the cloud. I remember an all-hands meeting for sales with Oracle’s then-president Thomas Kurian. “You cannot win the cloud war without infrastructure. You simply cannot,” Thomas said with conviction.
早在2016年在Oracle公司时,我们就努力转向云服务而苦苦挣扎。 我记得与Oracle当时的总裁Thomas Kurian举行的全体销售会议。 如果没有基础架构,您将无法赢得云战争。 你根本做不到,”托马斯坚定地说道。
If you want to run the Oracle Autonomous database or Exadata in the cloud you have a couple of options, your datacenter or Oracle’s. The highest level of executive leadership at Oracle does not want to run Oracle software in someone else's cloud.
如果要在云中运行Oracle自治数据库或Exadata,则有两种选择,即数据中心或Oracle。 Oracle的最高管理领导层不想在其他人的云中运行Oracle软件。
This is worth repeating. MongoDB runs as Database as a Service (DBaaS) on AWS, GCP, and Azure. If you have an application running on these cloud providers, the traffic between the app and the database is routed within the cloud provider’s datacenter.
这是值得重复的。 MongoDB在AWS,GCP和Azure上作为数据库即服务(DBaaS)运行。 如果您在这些云提供程序上运行了应用程序,则该应用程序与数据库之间的流量将在云提供程序的数据中心内进行路由。
Oracle does not have a DBaaS offering on any of the major cloud providers. If you want to run applications on any of the major cloud providers and you want to use Oracle Database as a Service, the traffic will have to go from your application in AWS, Azure or GCP to the Oracle cloud. In most cases, this means routing traffic over the public internet. Who wants the additional latency, or to route traffic over the public internet, or create and pay for a direct connection between Oracle’s datacenter and another cloud provider if you don’t have to?
Oracle在任何主要的云提供商上都没有提供DBaaS产品。 如果要在任何主要的云提供商上运行应用程序,并且要使用Oracle数据库即服务,则流量必须从AWS,Azure或GCP中的应用程序流到Oracle云。 在大多数情况下,这意味着通过公共Internet路由流量。 谁会想要额外的延迟,或者通过公共Internet路由流量,或者在不需要时创建Oracle数据中心与另一个云提供商之间的直接连接并为之付费?
In September of 2018, Thomas Kurian left Oracle. In November he joined Google as CEO of Google Cloud. No one knows for sure why. My guess is it was frustration over Oracle not investing in infrastructure as the other cloud providers did. That was one problem, the other was not running Oracle DBaaS in the other major cloud providers. Ultimately, I believe, this is not a competitive situation Oracle can win.
2018年9月,托马斯·库里安(Thomas Kurian)离开了Oracle。 11月,他加入Google,担任Google Cloud的首席执行官。 没有人知道为什么。 我的猜测是,Oracle没有像其他云提供商那样对基础设施进行投资而感到沮丧。 那是一个问题,另一个问题是在其他主要云提供商中未运行Oracle DBaaS。 最终,我相信,这不是Oracle可以赢得的竞争情况。
I’ll have more articles on the things MongoDB has accomplished since 2017, but in the summer of 2017, I could see the writing on the wall. I’d like to point out one more thing that happened in 2016. The Man AHL use case is linked below.
自2017年以来,我将有更多文章介绍MongoDB已完成的工作,但在2017年夏天,我可以看到墙上的文字。 我想指出2016年发生的另一件事。下面是Man AHL用例的链接。
最后一根稻草:MongoDB可以胜过Oracle Exadata (The last straw: MongoDB can outperform Oracle Exadata)
The test case I reviewed showed that MongoDB was able to run 250 million “ticks” per second for Man AHL. Imagine all the global stock trades that occur and all the related data that goes with it. Man AHL was wrestling with all this data. Let us just flip these ticks to IOPS.
我审查的测试案例表明,MongoDB能够为Man AHL每秒运行2.5亿次“ ticks”。 想象一下发生的所有全球股票交易以及随之而来的所有相关数据。 Man AHL正在努力处理所有这些数据。 让我们将这些滴答声翻转到IOPS。
MongoDB can insert multiple documents per input operation and actually exceed the IOPS, but relational databases cannot. The relational database has to break down the JSON document message and store it in different locations on disk. As far as I know, the best you can get is a one to one mapping. The test results I saw back in 2016 would translate to a minimum of 250 million IOPS per second for a relational database. I wanted to see what it would take for Oracle to compete.
MongoDB可以为每个输入操作插入多个文档,并且实际上超出了IOPS,但是关系数据库不能。 关系数据库必须分解JSON文档消息并将其存储在磁盘上的不同位置。 据我所知,最好的是一对一映射。 我在2016年看到的测试结果将转换为关系数据库至少每秒2.5亿IOPS。 我想看看Oracle竞争需要什么。
Oracle’s premier database offering is an engineered system called Exadata. It uses Oracle’s real application clustering technology (RAC) with Intelligent Database Protocol (iDB) to communicate with storage cells. Each storage cell is its own server. The storage cell has flash cache storage indexes that have the high and low value of every megabyte of data on disk. The Exadata X8 was released in April 2019. A single full-rack Exadata Database Machine X8–2, with 8 database servers and 14 High Capacity storage servers can achieve up to 350 GB per second of analytic scan bandwidth from SQL, and up to 4.8 Million random 8K read I/O operations per second (IOPS) from SQL. Its a killer, and has some of the best performance benchmarks I have ever seen for a relational database. In fact, although it's not advertised, I have heard that a well-tuned Exadata can hit the 12 Million IOPS mark.
Oracle首要的数据库产品是一个称为Exadata的工程系统。 它使用带有智能数据库协议(iDB)的Oracle实际应用程序集群技术(RAC)与存储单元进行通信。 每个存储单元都是其自己的服务器。 该存储单元具有闪存缓存存储索引,这些索引具有磁盘上每兆字节数据的高值和低值。 Exadata X8于2019年4月发布。一台具有8个数据库服务器和14个高容量存储服务器的全机架Exadata数据库云服务器 X8–2可以从SQL每秒获得高达350 GB的分析扫描带宽,并达到4.8每秒来自SQL的百万随机8K读取I / O操作( IOPS )。 它是杀手kill,并具有我见过的有关关系数据库的一些最佳性能基准。 实际上,尽管它没有进行广告宣传,但我听说精心调整的Exadata可以达到1200万IOPS。
Let's go with 12 million IOPS on the Man AHL use case. We need 250 million IOPS. How many Exadata machines do we need to match the MongoDB cluster running on commodity hardware? Well, it looks like we need about 20 of them. But if we want disaster recovery outside of a single datacenter we need another 20 standby Exadata machines in another datacenter so we can failover. The cost of a fully-loaded Exadata machine is millions of dollars. So we need 40 multi-million dollar Exadata machines to compete with one single MongoDB cluster. The Man AHL use case blew my mind.
让我们在Man AHL用例上获得1200万的IOPS。 我们需要2.5亿IOPS。 我们需要多少台Exadata计算机才能与在商品硬件上运行的MongoDB集群相匹配? 好吧,看来我们大约需要20个。 但是,如果我们想在单个数据中心之外进行灾难恢复,则需要在另一个数据中心中再安装20台备用Exadata计算机,以便进行故障转移。 满载的Exadata计算机的成本为数百万美元。 因此,我们需要40台价值数百万美元的Exadata计算机,才能与一个MongoDB集群竞争。 Man AHL用例令人震惊。
在2017年夏天,我正在MongoDB上积极面试。 (In the summer of 2017, I was actively interviewing at MongoDB.)
When an old technology dies, it doesn't go out in a bang, it slowly fades away. Today we still have mainframes and COBOL. We will have relational databases for a long time to come. But in my humble opinion, the era of the relational database as the first and best option to solve a data problem has come to an end. It has come to an end because of the flexibility, sheer volume, incredible ingest rate, and query velocity a modern database requires.
当一项旧技术消亡时,它不会爆炸,而是慢慢消失。 今天,我们仍然有大型机和COBOL。 我们将在很长一段时间内拥有关系数据库。 但以我的拙见,关系数据库作为解决数据问题的第一个也是最好的选择的时代已经结束。 由于现代数据库所需的灵活性,庞大的容量,令人难以置信的接收速率以及查询速度,它已告一段落。
When I recognized the relational gig was up at Oracle, I made the change and joined MongoDB at the end of July 2017. MongoDB went public on October 19, 2017. I am currently vesting the stock options I received before the IPO. Today less than three years later, the stock has gone up in value about 10 times its IPO price. Can I call it or what?
当我意识到与Oracle的关系工作即将结束时,我进行了更改,并于2017年7月底加入了MongoDB。MongoDB于2017年10月19日上市。我目前拥有在IPO之前获得的股票期权。 不到三年后的今天,该股的价值已经上涨了约10倍于IPO价格。 我可以叫它还是什么?
I don’t regret leaving Oracle to join MongoDB at all. Being in the industry gave me great insight into what is going on and why. I was able to get stock before anyone else investing in the market. I joined MongoDB because it was obvious to me that MongoDB was going to succeed greatly.
我完全不后悔离开Oracle加入MongoDB。 从事这个行业使我对正在发生的事情和原因有了很好的了解。 我能够在其他任何人投资市场之前先获得股票。 我加入MongoDB是因为对我而言,MongoDB显然将取得巨大成功。
It is good to be able to see why change happens, to embrace it, and to ride the wave. I hope that this article gives some clarity to see the changes that are underway. If you have massive amounts of data to deal with and need to modernize your tech stack, take a serious look at MongoDB.
能够了解为什么会发生变化,拥抱变化并驾驭潮流是一件好事。 我希望本文能使您清楚地看到正在进行的更改。 如果您要处理大量数据,并且需要更新技术堆栈,请认真看一下MongoDB。
翻译自: https://medium.com/@britton.laroche/why-i-left-oracle-and-joined-mongodb-45529bd04c6e















 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}