





bigquery使用教程
Propensity to purchase use case is widely applicable across many industry verticals such as Retail, Finance and more. In this article, we will show you how to build an end to end solution using BigQuery ML and Kubeflow Pipelines (KFP, an Machine Learning Operations (MLOps) workflow tool) using a Google Analytics dataset to determine which customers have the propensity to purchase. You could use the solution to reach out to your targeted customers in an offline campaign via email or postal channels. You could also use it in an online campaign via on the spot decision, when the customer is browsing your products in your website, to recommend some products or trigger a personalized email for the customer.
购买用例的倾向性可广泛应用于许多垂直行业,例如零售,金融等。 在本文中,我们将向您展示如何使用Google Analytics(分析)数据集使用BigQuery ML和Kubeflow管道 (KFP,机器学习操作(MLOps)工作流工具)构建端到端解决方案,以确定哪些客户有购买意愿。 您可以使用该解决方案通过电子邮件或邮政渠道在离线广告系列中吸引目标客户。 当客户浏览您网站上的产品时,您也可以通过现场决策在在线广告系列中使用它,为客户推荐某些产品或触发个性化电子邮件。
Propensity to purchase use case is a subset of personalization use case. It is a key driver of how many organizations do marketing today. In today’s changing times, you need to ensure that you are targeting the right messages to the right customers at the right time. “Personalization at scale has the potential to create $1.7 trillion to $3 trillion in new value” (McKinsey study). Propensity modeling helps companies to identify these “right” customers and prospects that have a high likelihood to purchase a particular product or service.
购买倾向用例是个性化用例的子集。 它是当今有多少组织进行营销的关键驱动力。 在当今瞬息万变的时代,您需要确保在正确的时间将正确的消息定向到正确的客户。 “大规模的个性化有可能创造1.7万亿至3万亿美元的新价值”( 麦肯锡研究 )。 倾向模型可帮助公司识别这些“正确”的客户和潜在客户,这些客户和潜在客户极有可能购买特定的产品或服务。
Propensity models are important as it is a mechanism for targeting sales outreach with personalized messages as they are keys to the success of getting attention of the customers. By using a propensity to purchase model, you can more effectively target customers who are most likely to purchase certain products.
倾向模型很重要,因为它是一种以个性化消息为目标的销售范围的机制,因为它们是成功吸引客户注意力的关键。 通过使用购买倾向模型,您可以更有效地定位最有可能购买某些产品的客户。
目录 (Table of Contents)
A typical end-to-end solution architecture and implementation steps
Identify the data source with past customers purchase history and load it to BigQuery
Build an ML model to determine which determines propensity of a customer to purchase
Join the customer data with a CRM system to gather customer details
典型的端到端解决方案体系结构和实施步骤 (A typical end-to-end solution architecture and implementation steps)
You will select features, create a label (which tells you if a customer has the propensity to purchase), build a model, predict batch/online in BigQuery using BigQuery ML. BigQuery ML enables you to create and execute machine learning models in BigQuery by using standard SQL queries. This means, you don’t need to export your data to train and deploy machine learning models — by training, you’re also deploying in the same step. Combined with BigQuery’s auto-scaling of compute resources, you won’t have to worry about spinning up a cluster or building a model training and deployment pipeline. This means you’ll be saving time building your machine learning pipeline, enabling your business to focus more on the value of machine learning instead of spending time setting up the infrastructure.
您将选择功能,创建标签(告诉您客户是否有购买倾向),构建模型,使用BigQuery ML预测BigQuery中的批次/在线。 BigQuery ML使您可以使用标准SQL查询在BigQuery中创建和执行机器学习模型。 这意味着,您无需导出数据即可训练和部署机器学习模型-通过训练,您也可以在同一步骤中进行部署。 结合BigQuery的计算资源自动缩放功能,您不必担心分散集群或构建模型训练和部署管道。 这意味着您将节省建立机器学习管道的时间,使您的企业可以将更多的精力放在机器学习的价值上,而不必花费时间来建立基础架构。
To automate this model-building process, you will orchestrate the pipeline using Kubeflow Pipelines, ‘a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers.’
为了使该模型构建过程自动化,您将使用Kubeflow Pipelines (一种用于基于Docker容器构建和部署可移植,可扩展的机器学习(ML)工作流的平台)来协调管道 。
Below is a picture of how the entire solution works:
下面是整个解决方案的工作原理图:
The solution involves the following steps:
该解决方案涉及以下步骤:
- Identify the data source with past customers purchase history and load the data to BigQuery 确定数据源和过去的客户购买历史,并将数据加载到BigQuery
- Prepare the data for Machine Learning (ML) tasks. 准备用于机器学习(ML)任务的数据。
- Build an ML model which determines the propensity of a customer to purchase 建立确定客户购买倾向的ML模型
- Join the customer data with a CRM system to gather customer details (e.g. email id, etc.) 将客户数据与CRM系统结合在一起以收集客户详细信息(例如,电子邮件ID等)
- Determine which product(s) we should recommend the customer 确定我们应该推荐客户的产品
- Launch a channel campaign with the above data 使用以上数据启动渠道活动
- Manage the lifecycle of the customer communication (e.g. email) in the CRM or equivalent 在CRM或类似版本中管理客户交流(例如电子邮件)的生命周期
- Refine the Customer Lifetime Value from the result of the campaign 根据活动结果优化客户生命周期价值
- Monitor the models to ensure that they are meeting the expectations 监视模型以确保它们满足期望
- Retrain the model, if necessary, based on either new dataset or rectified dataset 根据需要,根据新数据集或校正后的数据集重新训练模型
We are now going to discuss the steps in detail below. There is also an accompanying notebook which implements the first 3 steps of the solution.
现在,我们将在下面详细讨论这些步骤。 还有一个随附的笔记本 ,可实现解决方案的前三个步骤。
识别具有过去客户购买历史的数据源,并将其加载到BigQuery (Identify the data source with past customers purchase history and load it to BigQuery)
Where does your data reside? Determine the best pre-processing techniques to bring the data to BigQuery. You can automate the pre-processing in a MLOps pipeline, which you will see later in the article. The dataset, you are going to use, is hosted on BigQuery, provides 12 months (August 2016 to August 2017) of obfuscated Google Analytics 360 data from the Google Merchandise Store, a real ecommerce store that sells Google-branded merchandise.
您的数据存放在哪里? 确定将数据带入BigQuery的最佳预处理技术。 您可以在MLOps管道中自动化预处理,您将在本文稍后看到。 您将要使用的数据集托管在BigQuery上,可提供12个月(2016年8月至2017年8月)来自Google Merchandise Store的混淆的Google Analytics 360数据,这是一家销售Google品牌商品的真实电子商务商店。
Here’s a sample of some of the raw data from Google Analytics:
以下是一些来自Google Analytics(分析)的原始数据的示例:
准备用于ML任务的数据 (Prepare the data for ML tasks)
Now that you have identified the dataset, you start to prepare the data for your ML model development. Select the appropriate features and labels if you want to use supervised learning. For this article you will use a couple of features for demonstration purposes.
既然已经确定了数据集,就可以开始为ML模型开发准备数据了。 如果要使用监督学习,请选择适当的功能和标签。 在本文中,您将使用几个功能进行演示。
The query below will create the training data, features (`bounces`, `time_on_site`) and a label (`will_buy_on_return_visit`) that you will use to build your model later:
以下查询将创建训练数据,功能(“弹跳”,“ time_on_site”)和标签(“ will_buy_on_return_visit”),您将在以后使用它们来构建模型:
## follows schema from https://support.google.com/analytics/answer/3437719?hl=en&ref_topic=3416089
# select initial features and label to feed into your model
CREATE
OR REPLACE TABLE bqml.rpm_ds.rpm_ds_propensity_training_samples_tbl OPTIONS(
description = "Google Store curated Data"
) AS
SELECT
fullVisitorId,
bounces,
time_on_site,
will_buy_on_return_visit # <--- your label
FROM
# features
(
SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20160801'
AND '20170430'
) # train on first 9 months
JOIN (
SELECT
fullvisitorid,
IF(
COUNTIF(
totals.transactions > 0
AND totals.newVisits IS NULL
) > 0,
1,
0
) AS will_buy_on_return_visit
FROM
`bigquery-public-data.google_analytics_sample.*`
GROUP BY
fullvisitorid
) USING (fullVisitorId)
ORDER BY
time_on_site DESC # order by most time spent firstBelow is the partial result of running the above query:
以下是运行上述查询的部分结果:
建立ML模型,以确定哪个因素决定了客户的购买倾向 (Build an ML model to determine which determines propensity of a customer to purchase)
Which model type should we use? What are all the features to use? What should be the hyper parameter set for the model? These are typical data scientists challenges.
我们应该使用哪种型号? 所有要使用的功能是什么? 该模型的超级参数应该设置什么? 这些是典型的数据科学家挑战。
You need to classify if a customer has the propensity to purchase. Hence, it is a classification task. One commonly-used classification model is logistic regression. You will build a logistic regression using BigQuery ML.
您需要对客户是否有购买倾向进行分类。 因此,这是一个分类任务。 一种常用的分类模型是逻辑回归。 您将使用BigQuery ML建立逻辑回归。
The query below will create the model:
下面的查询将创建模型:
CREATE
OR REPLACE MODEL `rpm_ds.rpm_bqml_model` OPTIONS(
MODEL_TYPE = 'logistic_reg', labels = [ 'will_buy_on_return_visit' ]
) AS
SELECT
*
EXCEPT
(fullVisitorId)
FROM
`bqml.rpm_ds.rpm_ds_propensity_training_samples_tbl`Once the model is created, you can check how well the model performs based on certain rules. We have taken some rules-of-thumbs (e.g. ROC-AUC > 0.9) but you can adjust them based on your specific need.
创建模型后,您可以根据某些规则检查模型的性能。 我们已经采用了一些经验法则(例如ROC-AUC> 0.9),但是您可以根据自己的特定需求进行调整。
The query below will evaluate the model to check for expected ROC AUC:
以下查询将评估模型以检查预期的ROC AUC:
SELECT
roc_auc,
CASE WHEN roc_auc >.9 THEN 'good' WHEN roc_auc >.8 THEN 'fair' WHEN roc_auc >.7 THEN 'decent' WHEN roc_auc >.6 THEN 'not great' ELSE 'poor' END AS modelquality
FROM
ML.EVALUATE(MODEL `rpm_ds.rpm_bqml_model`)Running the query produces the following output:
运行查询将产生以下输出:
Do you really think we managed to build a good model? Hmm…most likely not…Because the ROC_AUC of 78% is considered a fair score. It takes a lot of domain knowledge, hyperparameter tuning, feature engineering, etc. to build a google model. This is not the best model you could create but it gives you a baseline. As the focus of this article is to build an end-to-end pipeline rather than model performance, fine tuning the model is outside the scope of this article.
您是否真的认为我们成功建立了良好的模型? 嗯...很可能不是...因为78%的ROC_AUC被认为是合理的分数。 建立Google模型需要大量领域知识,超参数调整,功能工程等。 这不是您可以创建的最佳模型,但是它为您提供了基准。 由于本文的重点是建立端到端管道而不是模型性能,因此微调模型不在本文讨论范围之内。
The trained model can assist you in reaching out to your customers in an offline campaign or in an online campaign. We will use batch prediction for the former and online prediction for the later.
经过训练的模型可以帮助您通过离线广告系列或在线广告系列来吸引客户。 对于前者,我们将使用批处理预测,而对于后者,将使用在线预测。
You can use the trained model for batch prediction of a large dataset in BigQuery. Or you could deploy the model in Google Cloud AI Platform for online prediction.
您可以将训练有素的模型用于BigQuery中大型数据集的批量预测。 或者,您可以在Google Cloud AI平台中部署模型以进行在线预测。
将批量预测用于离线广告系列 (Use batch prediction for offline campaign)
For the offline campaign scenario, you can do asynchronous batch prediction on a large dataset. Let us check how to do batch prediction. You can create a table in BigQuery and insert all your inputs for which you want to predict. You will create a table `rpm_ds_propensity_prediction_input_tbl` in BigQuery, with each row as one customer with bounces and time_on_site features. Then use the trained model to predict for all the inputs/rows.
对于离线市场活动方案,您可以对大型数据集进行异步批量预测。 让我们检查如何进行批量预测。 您可以在BigQuery中创建一个表,然后插入要预测的所有输入。 您将在BigQuery中创建一个表rpm_ds_propensity_prediction_input_tbl,每行都是一位具有跳动和time_on_site功能的客户。 然后,使用经过训练的模型来预测所有输入/行。
The query below shows the batch prediction:
以下查询显示了批次预测:
# predict the inputs (rows) from the input table
SELECT
fullVisitorId, predicted_will_buy_on_return_visit
FROM
ML.PREDICT(MODEL rpm_ds.rpm_bqml_model,
(
SELECT
fullVisitorId,
bounces,
time_on_site
from bqml.rpm_ds.rpm_ds_propensity_prediction_input_tbl
))Below is the partial result of running the above query:
以下是运行上述查询的部分结果:
In the output above, the model predicted that these four customers have the propensity to purchase as the `predicted_will_buy_on_return_visit` returns 1.
在上面的输出中,模型预测这四个客户具有购买意愿,因为“ predicted_will_buy_on_return_visit”返回1。
Do you think the model is predicting that each of the above the customer has the propensity to purchase? Maybe. To be sure, you need to dig deeper. You might want to check the features, parameters, threshold (which is 0.5 by default, in the above ML.PREDICT), etc. to tune the model.
您认为该模型是否在预测上述每个客户都有购买倾向? 也许。 可以肯定的是,您需要深入研究。 您可能需要检查功能,参数,阈值(在上面的ML.PREDICT中, 默认值为0.5 )等以调整模型。
使用在线预测进行在线广告系列 (Use online prediction for online campaign)
For the online campaign scenario, we need to deploy the model in Cloud AI Platform. It is a two step process. First, you need to export the model and then deploy to the Cloud AI Platform, which exposes a REST endpoint to serve online prediction.
对于在线活动场景,我们需要在Cloud AI Platform中部署模型。 这是一个两步过程。 首先,您需要导出模型,然后部署到Cloud AI Platform,该平台公开了REST端点以提供在线预测。
Below is the command to export the BiqQuery ML model to Google Cloud Storage :
以下是将BiqQuery ML模型导出到Google Cloud Storage的命令 :
# export the model to a Google Cloud Storage bucket
bq extract -m rpm_ds.rpm_bqml_model gs://bqml_sa/rpm_data_set/bqml/model/export/V_1Second, you need to deploy the exported model to Cloud AI Platform Prediction, which hosts your trained model, so that you can send the prediction requests to it.
其次,您需要将导出的模型部署到托管已训练模型的Cloud AI Platform Prediction ,以便可以向其发送预测请求。
Below is the command to deploy the model to Cloud AI Platform Prediction:
以下是将模型部署到Cloud AI Platform Prediction的命令:
# export the model to a Google Cloud Storage bucket
# deploy the above exported model
gcloud ai-platform versions create --model=rpm_bqml_model V_1 --framework=tensorflow --python-version=3.7 --runtime-version=1.15 --origin=gs://bqml_sa/rpm_data_set/bqml/model/export/V_1/ --staging-bucket=gs://bqml_saNow, you can predict online via a web request/response. You could use the endpoint in your web app to take on the spot action such as displaying personalized content or triggering an async process such as sending a personalized email or a postcard. Below is the command where you can quickly test the online prediction:
现在,您可以通过Web请求/响应在线进行预测。 您可以使用Web应用程序中的端点来执行现场操作,例如显示个性化内容或触发异步过程,例如发送个性化电子邮件或明信片。 以下是可以快速测试在线预测的命令:
# Perform online predict (create a input table with the input features)
# create a json file (input.json) with the below content
{"bounces": 0, "time_on_site": 7363}
# use the above json to predict
gcloud ai-platform predict --model rpm_bqml_model --version V_1 --json-instances input.jsonRunning the command produces output similar to the following:
运行该命令会产生类似于以下内容的输出:
Predicted results for {"bounces": 0, "time_on_site": 7363} is PREDICTED_WILL_BUY_ON_RETURN_VISIT WILL_BUY_ON_RETURN_VISIT_PROBS WILL_BUY_ON_RETURN_VISIT_VALUES
['1'] [0.9200436491721313, 0.07995635082786867] ['1', '0']In the output above, the model predicted that this particular customer has the propensity to purchase as the `PREDICTED_WILL_BUY_ON_RETURN_VISIT` returns 1. Given this test of “0” bounces and “7363” seconds on time_ont_site, the model tells us that there’s a 92% chance they have the propensity to purchase. Using this information, you can then send the customer a coupon (or perhaps you only want to give coupons to people between 0.5 and 0.8 probability, because if it’s a high probability they may purchase the item without incentives).
在上面的输出中,该模型预测该特定客户具有购买意愿,因为“ PREDICTED_WILL_BUY_ON_RETURN_VISIT”返回1。给定time_ont_site的“ 0”跳动和“ 7363”秒测试,该模型告诉我们有92%他们有购买倾向的机会。 然后,您可以使用此信息向客户发送优惠券(或者您可能只想将优惠券提供给0.5到0.8之间的人,因为如果这种可能性很高,他们可能会在没有激励的情况下购买该商品)。
Of course, you don’t have to use only gcloud, you could certainly use your favorite tools (wget, curl, postman, etc.) to quickly check the REST endpoint.
当然,您不必仅使用gcloud,当然可以使用自己喜欢的工具(wget,curl,postman等)快速检查REST端点。
将客户数据与CRM系统结合以收集客户详细信息 (Join the customer data with a CRM system to gather customer details)
So we can now predict if a customer has the propensity to purchase either in batch or online mode. Now what? Well, we are using the fullvisitorid in the data set. We will need the details of the customer such as email address, because your dataset doesn’t have them. The idea is to gather them from a Customer Relationship Management (CRM) system. Thus we need to integrate with a CRM system to accomplish the objective.
因此,我们现在可以预测客户是否有批量购买或在线购买的倾向。 怎么办? 好吧,我们在数据集中使用了fullvisitorid。 我们将需要客户的详细信息,例如电子邮件地址,因为您的数据集没有这些详细信息。 想法是从客户关系管理(CRM)系统中收集它们。 因此,我们需要与CRM系统集成以实现目标。
You will get an idea of the integration here. The article talks about how to integrate the Google Analytics 360 integration with Salesforce Marketing Cloud. The integration lets you publish audiences created in Analytics 360 to Marketing Cloud, and use those audiences in your Salesforce email and SMS direct-marketing campaigns. You will need to determine the appropriate integration mechanism based on your CRM platform.
您将在此处获得有关集成的想法。 本文讨论了如何将Google Analytics 360集成与Salesforce Marketing Cloud集成。 通过集成,您可以将在Analytics 360中创建的受众群体发布到Marketing Cloud,并在Salesforce电子邮件和SMS直销市场活动中使用这些受众群体。 您将需要根据您的CRM平台确定适当的集成机制。
The accompanying notebook doesn’t implement this step.
随附的笔记本没有执行此步骤。
解决方案的其余步骤 (Rest of the steps of the solution)
The rest of the steps in the solution are self explanatory though it might not be that trivial to integrate and interoperate the systems. But, well, that’s an ongoing challenge in the Software Development Life Cycle in general, isn’t it? You can also check some guidance as potential next steps continue to build on the existing solution.
解决方案中的其余步骤不言自明,尽管集成和互操作这些系统可能并不容易。 但是,这通常是软件开发生命周期中的一个持续挑战,不是吗? 您还可以查看一些指南,因为潜在的后续步骤将继续建立在现有解决方案的基础上。
ML管道 (ML Pipeline)
You are now going to build a ML pipeline to automate the solution steps 1, 2, and 3. The rest of the steps are left for either feature article or as an exercise to the reader. We are going to use Kubeflow Pipelines(KFP) and use managed KFP, Cloud AI Platform Pipelines on Google Cloud.
现在,您将构建一个ML管道来自动化解决方案的步骤1、2和3。其余步骤留给专题文章或作为练习供读者阅读。 我们将使用Kubeflow Pipelines(KFP)并在Google Cloud上使用托管的KFP, Cloud AI Platform Pipelines 。
Below is the visual representation of the solution steps, which are available in a Jupyter notebook in the git repo:
以下是解决方案步骤的直观表示,可在git repo的Jupyter笔记本中使用:
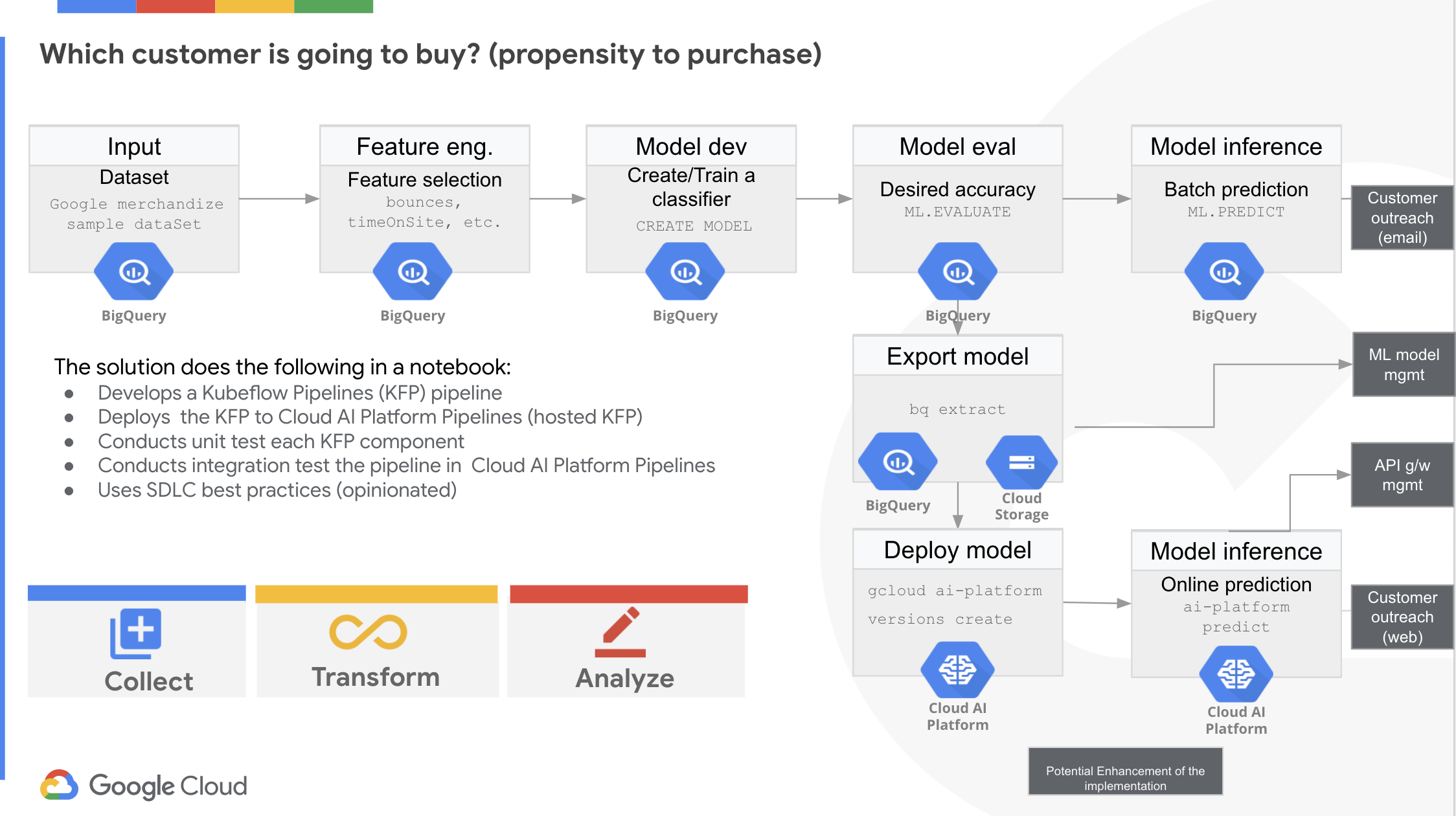
Below is the visual representation of the solutions steps that build on the current implementation. The notebook doesn’t implement these steps:
以下是基于当前实现的解决方案步骤的直观表示。 笔记本电脑不执行以下步骤:

The three links in the above diagrams are:
上图中的三个链接是:
Refer to the article, to get an idea about how to use the predicted customers that have propensity to purchase with a CRM system.
请参阅文章 ,以获取有关如何使用倾向于使用CRM系统进行购买的预测客户的想法。
Refer to the article, to get an idea about how you can use Matrix Factorization for product recommendation. The article also refers to a notebook.The article uses the same BigQuery public dataset you used in the current article.
请参阅文章 ,以了解如何使用矩阵分解进行产品推荐。 本文还引用了一个笔记本。本文使用与当前文章相同的BigQuery公共数据集。
Refer to the Chapter 6 “Frequent Itemsets” of the book “Mining of Massive Datasets” authored by a professor from Stanford University, to get an idea of how to build a frequently used product list.
请参阅由斯坦福大学的一位教授撰写的“大规模数据集的挖掘”一书的第6章“常用项目集” ,以了解如何构建常用产品列表。
Below is the below output from Cloud AI Platform Pipelines when you run the KFP experiment from the notebook. When you execute the experiment, your output may vary:
当您从笔记本计算机运行KFP实验时,以下是Cloud AI Platform Pipelines的以下输出。 执行实验时,您的输出可能会有所不同:
Each box represents a KFP component. You can refer to the notebook for the semantics, syntaxes, parameters passings in the function, etc. The notebook demonstrates the following features:
每个框代表一个KFP组件。 您可以参考笔记本以获取函数中的语义,语法,参数等。 笔记本具有以下功能:
* Environment Setup
- Setup Cloud AI Platform Pipelines (using the CloudConsole)
- Install KFP client
- Install Python packages for Google Cloud Services
* Kubeflow Pipelines (KFP) Setup
- Prepare Data for the training
-- Create/Validate a Google Cloud Storage Bucket/Folder
-- Create the input table in BigQuery
- Train the model
- Evaluate the model
- Prepare the Model for batch prediction
-- Prepare a test dataset (a table)
-- Predict the model in BigQuery
- Prepare the Model for online prediction
- Create a new revision (for model revision management)
-- Export the BigQuery Model
-- Export the Model from BigQuery to Google Cloud Storage
-- Export the Training Stats to Google Cloud Storage
-- Export the Eval Metrics to Google Cloud Storage
- Deploy to Cloud AI Platform Prediction
- Predict the model in Cloud AI Platform Prediction
* Data Exploration using BigQuery, Pandas, matplotlib
* SDLC methodologies Adherence (opinionated)
- Variables naming conventions
-- Upper case Names for immutable variables
-- Lower case Names for mutable variables
-- Naming prefixes with rpm_ or RPM_
- Unit Tests
- Cleanup/Reset utility functions
* KFP knowledge share (demonstration)
- Pass inputs params through function args
- Pass params through pipeline args
- Pass Output from one Component as input of another
- Create an external Shared Volume available to all the Comp
- Use built in Operators
- Built light weight Component
- Set Component not to cache下一步 (Next Steps)
There are a number of improvements or alternatives that you could use for your specific use case.
您可以针对特定用例使用许多改进或替代方法。
预测输入数据的备用数据源 (Alternative Data Sources for Prediction Input Data)
You could also use a federated data source, if that works for you.
如果适用,您还可以使用联合数据源 。
替代型号 (Alternative Models)
We have used logistic regression in this article, but you could use XGBoost or others. You could, also, train multiple models in parallel and then evaluate to decide which model performs better for your scenario. You could do so in the MLOps pipeline and let BigQuery do the heavy lifting for you in taking care of computation required in training the models.
我们在本文中使用了逻辑回归,但您可以使用XGBoost或其他方法 。 您也可以并行训练多个模型,然后评估以确定哪种模型更适合您的方案。 您可以在MLOps管道中执行此操作,并让BigQuery在处理训练模型所需的计算时为您完成繁重的工作。
在线预测终点 (Online prediction endpoint)
Now that you have an endpoint for the online prediction, you could publish the API to your web developer and/or to monitor its usage. You could use Google Apigee, an API management platform, for doing so and much more.
现在您有了用于在线预测的端点,您可以将API发布给您的Web开发人员和/或监视其使用情况。 您可以使用API管理平台Google Apigee进行更多操作。
确定我们应该推荐客户的产品 (Determine which product(s) we should recommend the customer)
After we determine, which customer(s) has the propensity to purchase, we need to find out what product(s) we should recommend to them. We could launch a campaign which uses the personalized messages for a targeted customer base. However, the accompanying notebook doesn’t implement this step.
在确定哪些客户有购买倾向之后,我们需要找出应该推荐给他们的产品。 我们可以开展一项针对特定客户群使用个性化消息的活动。 但是,随附的笔记本电脑未实现此步骤。
There are many approaches to determine the product(s) that we should recommend to the customer. You could use either a Matrix Factorization or a MarketBasket FrequentItemSet technique as your starting point.
有很多方法可以确定我们应该推荐给客户的产品。 您可以使用矩阵分解或MarketBasket FrequentItemSet技术作为起点。
MarketBasket model could also provide an online stateful prediction model i.e. when a customer browses (or any equivalent action such adds to the Shopping Cart) Product A, then you could recommend the next Product B and so on. You can embed the intelligence in your web application to better understand the customer’s intent. As an illustration if someone is purchasing Diaper you might want to recommend them to purchase Beer (based on an interesting discovery, please check the Chapter 6 material reference below for additional information.) Or if a customer has added potting soil to their cart, you could recommend them plant food. The better you learn about the customer’s intent the better you could recommend other pertinent products. Choices are endless…
MarketBasket模型还可以提供在线状态预测模型,即当客户浏览(或任何等效操作,例如添加到购物车中的等效操作)产品A时,您可以推荐下一个产品B,依此类推。 您可以将情报嵌入Web应用程序中,以更好地了解客户的意图。 例如,如果有人要购买纸尿裤,您可能希望推荐他们购买啤酒(基于有趣的发现,请参阅下面的第6章材料参考以获取更多信息。)或者,如果客户在购物车中添加了盆栽土,则可以可以推荐他们种植食物。 您越了解客户的意图,就越能推荐其他相关产品。 选择无止境……
摘要 (Summary)
Congratulations! You now learnt how to build a Propensity model using BigQuery ML and how to orchestrate an ML pipeline in Kubeflow Pipelines. You could continue to build upon the current solution for a complete activation but you could use the notebook as a starting point.
恭喜你! 您现在学习了如何使用BigQuery ML构建倾向模型,以及如何在Kubeflow Pipelines中编排ML管道。 您可以继续在当前解决方案的基础上进行完整激活,但可以将笔记本用作起点。
想要更多? (Want more?)
Please leave me your comments with any suggestions or corrections.
请给我您的意见与任何建议或更正。
I work in Google Cloud. I help our customers to build solutions on Google Cloud.
我在Google Cloud中工作。 我帮助我们的客户在Google Cloud上构建解决方案。
bigquery使用教程















 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









