





Python (PYTHON)
Window calculations can add a lot of depth to your data analysis.
窗口计算可以为您的数据分析增加很多深度。
The Pandas library lets you perform many different built-in aggregate calculations, define your functions and apply them across a DataFrame, and even work with multiple columns in a DataFrame simultaneously. A feature in Pandas you might not have heard of before is the built-in Window functions.
通过Pandas库,您可以执行许多不同的内置聚合计算,定义函数并在DataFrame中应用它们,甚至可以同时处理DataFrame中的多个列。 内置的Window 功能是您以前可能从未听说过的Pandas 功能 。
Window functions are useful because you can perform many different kinds of operations on subsets of your data. Rolling window functions specifically let you calculate new values over each row in a DataFrame. This might sound a bit abstract, so let’s just dive into the explanations and examples.
窗口函数很有用,因为您可以对数据的子集执行许多不同种类的操作。 滚动窗口功能特别允许您计算DataFrame中每一行的新值。 这听起来可能有点抽象,所以让我们深入了解一下解释和示例。
Examples in this piece will use some old Tesla stock price data from Yahoo Finance. Feel free to run the code below if you want to follow along. For more information on pd.read_html and df.sort_values, check out the links at the end of this piece.
本文中的示例将使用Yahoo Finance的一些旧特斯拉股价数据。 如果您想继续,请随时运行以下代码。 有关pd.read_html和df.sort_values更多信息,请查看本文末尾的链接。
import pandas as pddf = pd.read_html("https://finance.yahoo.com/quote/TSLA/history?period1=1546300800&period2=1550275200&interval=1d&filter=history&frequency=1d")[0]
df = df.head(11).sort_values(by='Date')
df = df.astype({"Open":'float',
"High":'float',
"Low":'float',
"Close*":'float',
"Adj Close**":'float',
"Volume":'float'})
df['Gain'] = df['Close*'] - df['Open']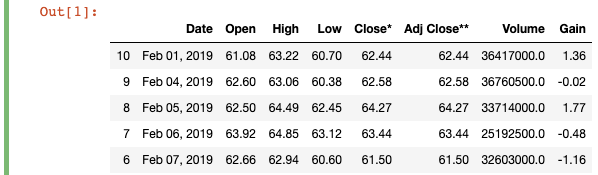
在Pandas DataFrame中滚动功能 (Rolling Functions in a Pandas DataFrame)
So what is a rolling window calculation?
那么什么是滚动窗口计算?
You’ll typically use rolling calculations when you work with time-series data. Again, a window is a subset of rows that you perform a window calculation on. After you’ve defined a window, you can perform operations like calculating running totals, moving averages, ranks, and much more!
处理时间序列数据时,通常会使用滚动计算。 同样, 窗口是执行窗口计算所依据的行的子集。 定义窗口后,您可以执行诸如计算运行总计,移动平均值,排名等操作!
Let’s clear this up with some examples.
让我们用一些例子来澄清这一点。
1.窗口滚动平均值(移动平均值) (1. Window Rolling Mean (Moving Average))
The moving average calculation creates an updated average value for each row based on the window we specify. The calculation is also called a “rolling mean” because it’s calculating an average of values within a specified range for each row as you go along the DataFrame.
移动平均计算基于我们指定的窗口为每一行创建一个更新的平均值。 该计算也称为“滚动平均值”,因为它是在沿DataFrame进行计算时,为每一行计算指定范围内的平均值。
That sounds a bit abstract, so let’s calculate the rolling mean for the “Close” column price over time. To do so, we’ll run the following code:
这听起来有点抽象,所以让我们计算“关闭”列价格随时间的滚动平均值。 为此,我们将运行以下代码:
df['Rolling Close Average'] = df['Close*'].rolling(2).mean()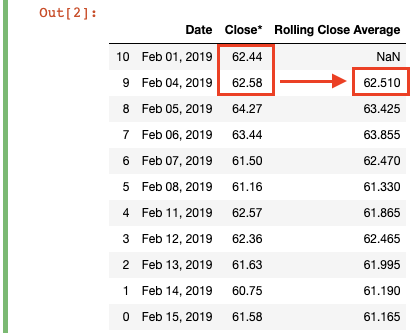
We’re creating a new column “Rolling Close Average” which takes the moving average of the close price within a window. To do this, we simply write .rolling(2).mean(), where we specify a window of “2” and calculate the mean for every window along the DataFrame. Each row gets a “Rolling Close Average” equal to its “Close*” value plus the previous row’s “Close*” divided by 2 (the window). In essence, it’s Moving Avg = ([t] + [t-1]) / 2.
我们正在创建一个新列“滚动收盘平均线”,该列采用窗口内收盘价的移动平均线。 为此,我们只需编写.rolling(2).mean() ,在其中我们将窗口指定为“ 2”并计算沿DataFrame的每个窗口的均值。 每行将获得一个“滚动平均收支”,该值等于其“关闭*”值加上前一行的“关闭*”除以2(窗口)。 本质上,它是Moving Avg = ([t] + [t-1]) / 2 。
In practice, this means the first calculated value (62.44 + 62.58) / 2 = 62.51, which is the “Rolling Close Average” value for February 4. There is no rolling mean for the first row in the DataFrame, because there is no available [t-1] or prior period “Close*” value to use in the calculation, which is why Pandas fills it with a NaN value.
实际上,这意味着第一个计算值(62.44 + 62.58) / 2 = 62.51 ,它是2月4日的“滚动平均收盘(62.44 + 62.58) / 2 = 62.51 ”值。由于没有可用的数据帧,因此第一行没有滚动平均值。 [t-1]或上一个期间的“ Close *”值要在计算中使用,这就是Pandas用NaN值填充它的原因。
2.窗户滚动标准偏差 (2. Window Rolling Standard Deviation)
To further see the difference between a regular calculation and a rolling calculation, let’s check out the rolling standard deviation of the “Open” price. To do so, we’ll run the following code:
为了进一步了解常规计算和滚动计算之间的区别,让我们检查一下“开放”价格的滚动标准偏差。 为此,我们将运行以下代码:
df['Open Standard Deviation'] = df['Open'].std()
df['Rolling Open Standard Deviation'] = df['Open'].rolling(2).std()
I also included a new column “Open Standard Deviation” for the standard deviation that simply calculates the standard deviation for the whole “Open” column. Beside it, you’ll see the “Rolling Open Standard Deviation” column, in which I’ve defined a window of 2 and calculated the standard deviation for each row.
我还为标准偏差添加了一个新列“开放标准偏差”,该列仅计算整个“开放”列的标准偏差。 在它旁边,您将看到“滚动打开标准偏差”列,其中我定义了一个2的窗口并计算了每一行的标准偏差。
Just as with the previous example, the first non-null value is at the second row of the DataFrame, because that’s the first row that has both [t] and [t-1]. You can see how the moving standard deviation varies as you move down the table, which can be useful to track volatility over time.
与前面的示例一样,第一个非null值位于DataFrame的第二行,因为这是同时具有[t ]和[t-1]的第一行。 您可以看到随着向下移动表格的移动标准偏差的变化,这对于跟踪一段时间内的波动率很有用。
Pandas uses N-1 degrees of freedom when calculating the standard deviation. You can pass an optional argument to ddof, which in the std function is set to “1” by default.
熊猫在计算标准偏差时使用N-1个自由度。 您可以将可选参数传递给ddof ,该参数在std函数中默认设置为“ 1”。
3.窗口滚动总和 (3. Window Rolling Sum)
As a final example, let’s calculate the rolling sum for the “Volume” column. To do so, we run the following code:
作为最后一个示例,让我们计算“体积”列的滚动总和。 为此,我们运行以下代码:
df['Rolling Volume Sum'] = df['Volume'].rolling(3).sum()
We’ve defined a window of “3”, so the first calculated value appears on the third row. The sum calculation then “rolls” over every row, so that you can track the sum of the current row and the two prior row’s values over time.
我们定义了一个窗口“ 3”,因此第一个计算出的值出现在第三行上。 然后,总和计算将“滚动”到每一行,以便您可以随时间跟踪当前行和前两个行的值之和。
It’s important to emphasize here that these rolling (moving) calculations should not be confused with running calculations. Rolling calculations, as you can see int he diagram above, have a moving window. So with our moving sum, the calculated value for February 6 (the fourth row) does not include the value for February 1 (the first row), because the specified window (3) does not go that far back. In contrast, a running calculation would take continually add each row value to a running total value across the whole DataFrame. You can check out the cumsum function for that.
在此必须强调的是,这些滚动 (移动)计算不应与运行计算混淆。 如上图所示,滚动计算有一个移动的窗口。 因此,使用我们的移动总和,2月6日(第四行)的计算值不包括2月1日(第一行)的值,因为指定的窗口(3)不会那么远。 相反,正在运行的计算将需要连续将每个行值添加到整个DataFrame的正在运行的总值中。 您可以cumsum查看cumsum函数。
I hope you found this very basic introduction to logical comparisons in Pandas using the wrappers useful. Remember to only compare data that can be compared (i.e. don’t try to compare a string to a float) and manually double-check the results to make sure your calculations are producing the intended results.
我希望您发现使用包装程序对熊猫进行逻辑比较非常基础的介绍很有用。 请记住,仅比较可比较的数据(即不要尝试将字符串与浮点数进行比较),并手动仔细检查结果以确保您的计算产生了预期的结果。
Go forth and compare!
继续比较吧!
翻译自: https://towardsdatascience.com/dont-miss-out-on-rolling-window-functions-in-pandas-850b817131db















 3051
3051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









