





易变列放在索引的后面
Choosing the optimal indexing strategy for your SQL Server workloads is one of the most challenging tasks. As you probably know, indexes can dramatically improve the performance of your queries, but at the same time, they can cause additional overhead when it comes to maintenance.
为您SQL Server工作负载选择最佳的索引策略是最具挑战性的任务之一。 您可能知道,索引可以极大地提高查询的性能,但是同时,它们在维护方面可能会导致额外的开销。
In complete honesty, I would never call myself an expert on indexing. However, I wanted to share my experience from the recent project, as it opened a whole new perspective to me and I thought that it can be beneficial to others also.
老实说,我永远不会称自己是索引专家。 但是,我想分享最近项目的经验,因为它为我打开了一个全新的视野,我认为它也可能对其他人有益。
First of all, up until a few months ago, I have never used Columnstore indexes, since the working environment in my company was based on SQL Server 2008R2. I’ve had theoretical knowledge about Columnstore indexes and I was aware of the difference between them and traditional B-Tree indexes, but I’ve never tried them in reality.
首先,直到几个月前,由于我公司的工作环境是基于SQL Server 2008R2的,所以我从未使用过Columnstore索引。 我具有有关Columnstore索引的理论知识,并且知道它们与传统的B-Tree索引之间的区别,但是我从未在实际中尝试过它们。
But, first things first…
但是,首先是……
什么是Columnstore索引? (What is a Columnstore index ?)
As opposed to a rowstore type of data storage, which physically stores data in a row-wise format, columnstore operates on a columnar level of the table. It was first introduced with SQL Server 2012 and later improved with every newer version of SQL Server. While traditional rowstore indexes (I will refer them as B-tree indexes) store the key value of each row, so that the SQL Server engine can use this key to retrieve the row data, columnstore indexes store each table column separately!
与行存储类型的数据存储(以物理方式按行格式存储数据)相反,列存储在表的列级上运行。 它最初是在SQL Server 2012中引入的,后来在每个较新版本SQL Server中进行了改进。 传统的行存储索引(我将它们称为B树索引)存储每行的键值,以便SQL Server引擎可以使用此键来检索行数据,而列存储索引则分别存储每个表列!

The main reason for using the Columnstore index is its high compression! That brings significant gains in terms of memory footprint and, consequentially, better performance when used in a proper way.
使用Columnstore索引的主要原因是它的高压缩率! 如果以适当的方式使用,这将显着提高内存占用量,并因此带来更好的性能。
There are really a lot of great resources on the web for learning about Columnstore indexes architecture, and Microsoft’s documentation is also quite comprehensive on this topic, but I wanted to show some real examples when the usage of Columnstore indexes makes sense.
Web上确实有很多很棒的资源可用于学习Columnstore索引体系结构,并且Microsoft的文档在此主题上也很全面,但是当使用Columnstore索引有意义时,我想展示一些真实的示例。
Just to emphasize that I will use clustered columnstore indexes exclusively (non-clustered columnstore indexes are out of the scope of this article).
只是为了强调我将只使用集群式列存储索引(非集群式列存储索引不在本文讨论范围之内)。
For all examples, I’m using the Stack Overflow database.
对于所有示例,我正在使用Stack Overflow数据库。
爬上B树 (Climbing on a B-tree)
Let’s first run a few simple queries on our Posts table, which has slightly more than 17 million records, just to get a feeling about the data. At the very beginning, I don’t have any indexes on this table, except the clustered index on the primary key column.
让我们首先在Posts表上运行一些简单的查询,该表具有略多于1700万条的记录,只是为了了解数据。 刚开始时,除了主键列上的聚集索引之外,此表上没有任何索引。
My goal is to find all posts from the 1st half of the year 2010, with more than 3000 views:
我的目标是查找2010年上半年以来的所有帖子,并获得3000多次观看:
SELECT *
FROM dbo.Posts P
WHERE CreationDate >= '20100101'
AND CreationDate < '20100701'
AND ViewCount > 3000This query returned 88.547 rows and it took more than a minute to execute!
该查询返回了88.547行,并且花费了超过一分钟的时间来执行!
Since no index exists on this table, SQL Server had to scan a whole table to satisfy our request, performing around 4.2 million logical reads. Let’s help a little bit our poor SQL Server, and create a nonclustered index on the CreationDate column:
由于此表上不存在索引,因此SQL Server必须扫描整个表以满足我们的要求,执行大约420万次逻辑读取。 让我们来帮助一下我们较差SQL Server,并在CreationDate列上创建一个非聚集索引:
CREATE NONCLUSTERED INDEX [ix_creationDate] ON [dbo].[Posts]
(
[CreationDate] ASC
)Now, when I ran again exactly the same query, I’ve got back my results in 9 seconds, but the number of logical reads (5.6 million) suggests that this query is still far from being good. SQL Server is thankful for our new index since it was used to narrow down the scope for the initial search. However, selecting all columns is obviously not a good idea, as SQL Server had to pick up all other columns from the clustered index, performing an enormous number of random readings.
现在,当我再次运行完全相同的查询时,我在9秒钟内就得到了我的结果,但是逻辑读取数(560万)表明该查询仍然差强人意。 SQL Server感谢我们的新索引,因为它用于缩小初始搜索的范围。 但是,选择所有列显然不是一个好主意,因为SQL Server必须从聚簇索引中选取所有其他列,从而执行大量的随机读取。
Now, the first question I would ask myself is: what data do I really need? Do I need Body, ClosedDate, LastEditDate, etc.? Ok, so I will rewrite the query to include only necessary columns:
现在,我要问自己的第一个问题是:我真正需要什么数据? 我是否需要Body,ClosedDate,LastEditDate等? 好的,因此我将重写查询以仅包括必要的列:
SELECT P.Id AS PostId
,P.CreationDate
,P.OwnerUserId AS UserId
,P.Score
,P.ViewCount
FROM dbo.Posts P
WHERE P.CreationDate >= '20100101'
AND P.CreationDate < '20100701'
AND P.ViewCount > 3000We are getting exactly the same execution plan, with less logical reads (4 million), since the amount of data that’s being returned was decreased.
由于返回的数据量减少了,因此我们得到的执行计划完全相同,逻辑读取次数更少(400万次)。
SQL Server suggests creating an index on our predicate columns (columns in WHERE clause), and including remaining columns in the index. Let’s obey SQL Server’s wish and modify our index:
SQL Server建议在谓词列(WHERE子句中的列)上创建索引,并将其余列包括在索引中。 让我们遵循SQL Server的愿望并修改索引:
CREATE NONCLUSTERED INDEX [ix_creationDate_viewCount] ON [dbo].[Posts]
(
[CreationDate],
[ViewCount]
)
INCLUDE ([OwnerUserId],[Score])Now, when I run my query, it executes in less than a second, performing only 3626 logical reads! Wow! So, we’ve created a nice “covering” index, which works perfectly for this query. I’ve intentionally bolded the part “for this query”, since we can’t create a covering index for every single query that runs against our database. Here, it’s fine for the demo purposes.
现在,当我运行查询时,它在不到一秒钟的时间内执行,仅执行3626次逻辑读取! 哇! 因此,我们创建了一个不错的“覆盖”索引,该索引非常适合此查询 。 我故意将“用于此查询”的部分加粗,因为我们无法为针对数据库运行的每个查询创建覆盖索引。 在这里,出于演示目的很好。
列存储索引发挥作用 (Columnstore index comes into play)
Ok, we couldn’t optimize the previous query more than we did. Let’s now see how will columnstore index performs.
好的,我们对上一个查询的优化不能超过我们的优化。 现在让我们看一下列存储索引的性能。
The first step is to create a copy of dbo.Posts table, but instead of using the B-tree index, I will create a clustered columnstore index on this new table (dbo.Posts_CS).
第一步是创建dbo.Posts表的副本,但不是使用B树索引,而是在此新表(dbo.Posts_CS)上创建集群列存储索引。
CREATE CLUSTERED COLUMNSTORE INDEX cix_Posts
ON dbo.Posts_CSFirst thing you may notice is the huuge difference in the memory footprint of these two identical tables:
您可能会注意到的第一件事是这两个相同表的内存占用量之间的巨大差异:

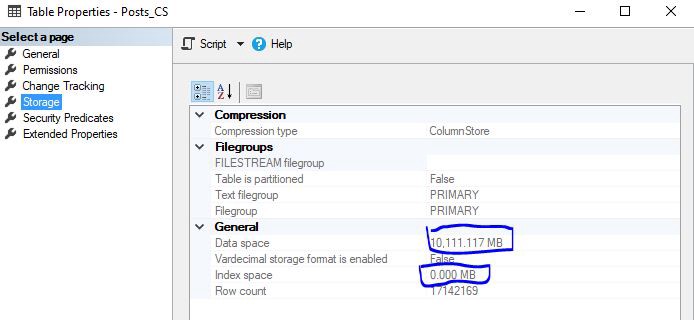
So, a table with a clustered columnstore index on it consumes almost 4x less memory comparing to an original one with a B-tree index! If we also take non-clustered indexes into consideration, the difference only gets bigger. As I’ve already mentioned, data is much better compressed on the column level.
因此,与具有B树索引的原始表相比,具有簇列存储索引的表所消耗的内存几乎减少了4倍! 如果我们还考虑非聚集索引,则差异只会变得更大。 正如我已经提到的,在列级上压缩数据要好得多。
Now, let’s run exactly the same query on our newly created columnstore indexed table.
现在,让我们在新创建的列存储索引表上运行完全相同的查询。
SELECT P.Id AS PostId
,P.CreationDate
,P.OwnerUserId AS UserId
,P.Score
,P.ViewCount
FROM dbo.Posts_CS P
WHERE P.CreationDate >= '20100101'
AND P.CreationDate < '20100701'
AND P.ViewCount > 3000Data in columnstore index is stored in segments. So, depending on the data distribution within the table, SQL Server has to read more or fewer segments in order to retrieve the requested data.
列存储索引中的数据存储在段中。 因此,根据表中的数据分布,SQL Server必须读取更多或更少的段才能检索请求的数据。

As you can see in the above illustration, to return my 88.547 records, SQL Server went through 26 segments and skipped 72. That’s because the data in our columnstore index is not sorted in any specific order. We could sort it by, let’s say, CreationDate (assuming that most of our queries will use CreationDate as a predicate), and in that case performance should be even better, since SQL Server would exactly know in which segments to look for the data, and which could be skipped.
从上图中可以看到,要返回我的88.547条记录,SQL Server遍历了26个段并跳过了72个段。这是因为columnstore索引中的数据未按任何特定顺序排序。 我们可以用CreationDate进行排序(假设大多数查询将使用CreationDate作为谓词),在这种情况下,性能应该会更好,因为SQL Server会确切知道要在哪些段中查找数据,并且可以跳过。
Now, let’s run both queries together and compare the query costs:
现在,让我们一起运行两个查询并比较查询成本:

Traditional B-tree index seek has a cost of 3.7, while columnstore scan costs 10.7. Quite obvious, since we have a perfectly matching non-clustered index that covers all columns we need. Still, the difference is not so big.
传统的B树索引查找的成本为3.7,而列存储扫描的成本为10.7。 很明显,因为我们有一个完全匹配的非聚集索引,可以覆盖我们需要的所有列。 不过,两者之间的差异并不大。
添加更多成分… (Adding more ingredients…)
But, let’s say that after some time we need to expand our output list and retrieve data for LastActivityDate. Let’s check what will happen:
但是,假设一段时间之后,我们需要扩展输出列表并检索LastActivityDate的数据。 让我们检查会发生什么:

Oops!!! By adding just one column, results completely changed in the favor of columnstore index. Now, B-tree non-clustered index doesn’t have all the necessary data and it needs to pick up LastActivityDate from the clustered index — that makes the cost of this query rise up to 236! On the other hand, columnstore index became slightly more expensive and now costs 14!
糟糕! 通过仅添加一列,结果完全改变为支持列存储索引。 现在,B树非聚集索引没有所有必要的数据,它需要从聚集索引中提取LastActivityDate ,这使该查询的成本上升到236! 另一方面,columnstore索引的价格稍高一些,现在为14!
Of course, as you can notice in the picture above, SQL Server asks for another index (or existing ones to be expanded), but that’s what I stressed above — you shouldn’t blindly obey all of SQL Server wishes, or you will finish with “over-indexed” tables!
当然,正如您在上图中所注意到的,SQL Server要求另一个索引(或要扩展的现有索引),但这就是我在上面强调的内容–您不应该盲目地服从SQL Server的所有愿望,否则您将完成与“过度索引”表!
运行分析查询 (Running Analytical Queries)
By definition, the area where columnstore indexes should excel is when running analytical queries. So, let’s check this on the following scenario: I want to retrieve the users who registered in the first half of the year 2010, posted in the years 2010 and 2011, and the user’s overall Reputation is greater than 3000 and respective posts have more than 3000 views…I also need to see the user’s Location and DisplayName. Sounds complicated, but it really isn’t:)
根据定义,列存储索引应擅长的区域是运行分析查询时。 因此,让我们在以下情况下进行检查:我想检索在2010年上半年注册,在2010年和2011年发布的用户,并且该用户的整体信誉大于3000,而相应帖子的数量超过3000次浏览…我还需要查看用户的Location和DisplayName 。 听起来很复杂,但实际上并非如此:)
Here is the query:
这是查询:
SELECT U.Id
,U.Location
,U.DisplayName
,P.CreationDate
,P.Score
,P.ViewCount
FROM dbo.Users U
INNER JOIN dbo.Posts P ON U.Id = P.OwnerUserId
WHERE U.CreationDate >= '20100101'
AND U.CreationDate < '20100701'
AND U.Reputation > 3000
AND P.ViewCount > 3000
AND P.CreationDate >= '20100101'
AND P.CreationDate < '20120101'The query returns 37.332 rows and we want to help SQL Server a little bit, by creating a non-clustered index on the CreationDate column in the Users table.
该查询返回37.332行,我们希望通过在Users表的CreationDate列上创建非聚集索引来帮助SQL Server。
CREATE NONCLUSTERED INDEX [ix_creationDate] ON [dbo].[Users]
(
[CreationDate]
)When I run the query, SQL Server comes with the following execution plan:
当我运行查询时,SQL Server附带以下执行计划:
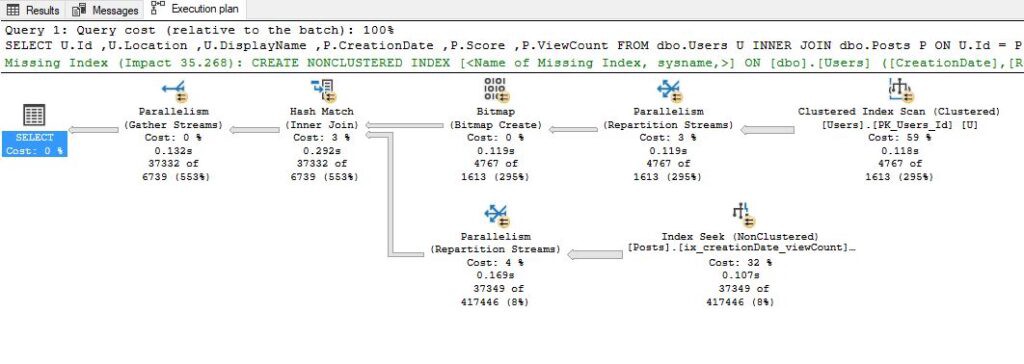
Since our index doesn’t cover all the necessary columns, SQL Server assumes that it’s cheaper to perform a scan on the Users table, instead of doing Index Seek and then expensive key lookups. This query costs 58.4.
由于我们的索引未涵盖所有必需的列,因此SQL Server假定在Users表上执行扫描要便宜一些,而不是进行Index Seek和昂贵的键查找。 该查询的费用为58.4。
Now, I will create a copy of the Users table (Users_CS) and create a clustered columnstore index on it:
现在,我将创建Users表(Users_CS)的副本,并在其上创建集群列存储索引:
CREATE CLUSTERED COLUMNSTORE INDEX cix_Users
ON dbo.Users_CSLet’s now run bot of our queries at the same time and compare the performance:
现在让我们同时运行查询机器人,并比较性能:
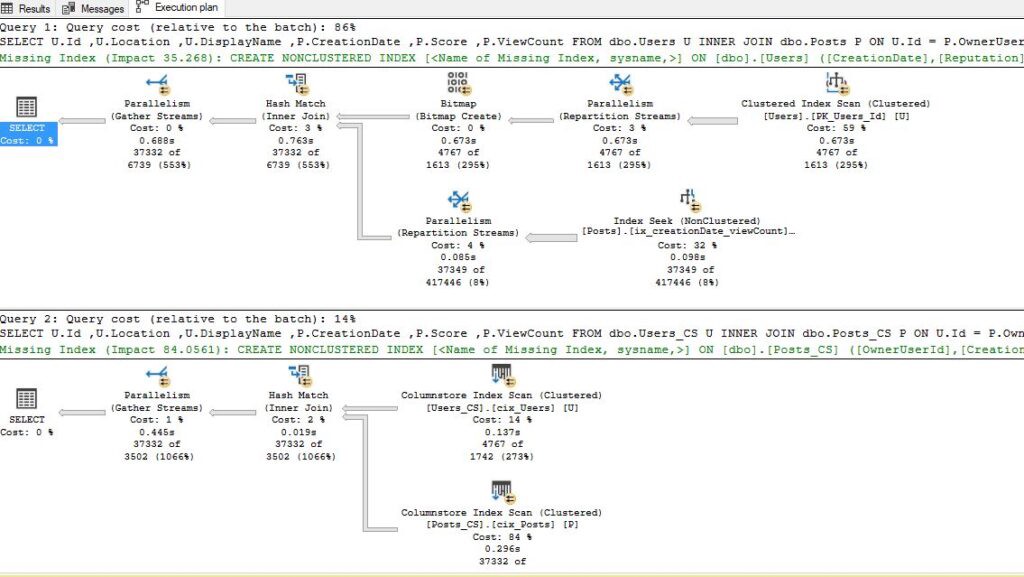
Again, the table with columnstore index on it easily outperforms the original one with the B-tree index. The cost of the second query is 9.2! And keep in mind that we didn’t even optimize the columnstore index itself (we were not sorting the data during the insertion)!
同样,带有列存储索引的表很容易胜过带有B树索引的原始表。 第二个查询的成本为9.2! 并且请记住,我们甚至没有优化columnstore索引本身(在插入过程中我们没有对数据进行排序)!
One last example comes from my real project, where we were comparing performance between columnstore and B-tree indexes on our actual workload. The query itself is so simple: I want to summarize total deposits per every single customer between January 1st and end of July this year:
最后一个示例来自我的真实项目,我们在此比较了实际工作负载下列存储索引和B树索引之间的性能。 查询本身非常简单:我想总结一下今年1月1日至7月底每个客户的存款总额:
SELECT customerID
,SUM(amount) total
FROM factDeposit
WHERE isSuccessful = 1
AND datetm >='20200101'
AND datetm < '20200801'
GROUP BY customerID
SELECT customerID
,SUM(amount) total
FROM factDeposit_cs
WHERE isSuccessful = 1
AND datetm >='20200101'
AND datetm < '20200801'
GROUP BY customerIDAnd here are the results:
结果如下:
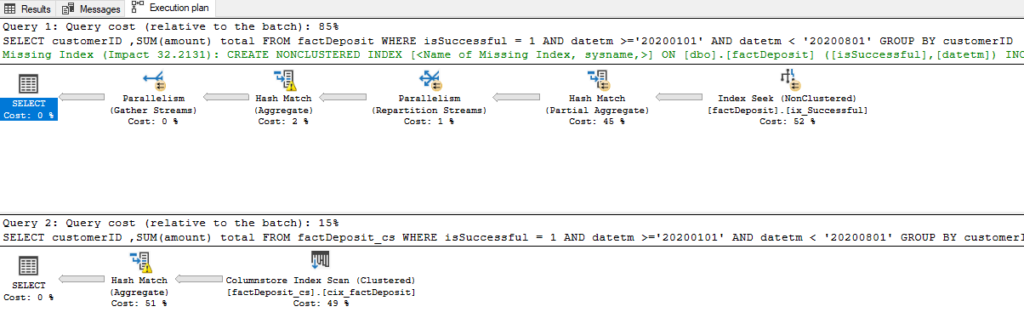
Again, columnstore index convincingly “wins” with 4.6 vs 26 query cost!
同样,columnstore索引以4.6 vs 26的查询成本令人信服地“胜出”!
那么,为什么我要完全使用B树索引呢? (So, why would I use B-tree indexes at all??!!)
Before you fall into the trap of concluding that traditional B-tree indexes aren’t needed anymore, you should ask yourself: where is the catch? And the catch is obviously there since B-tree indexes are still heavily used in most of the databases.
在断定不再需要传统B树索引的陷阱之前,您应该问自己:陷阱在哪里? 由于B树索引在大多数数据库中仍被大量使用,因此显然存在问题。
The biggest downside of the columnstore indexes is UPDATE/DELETE operations. Deleted records are not really deleted — they are just flagged as deleted, but they still remain part of the columnstore index, until the index is rebuilt. Updates perform even worse since they are being executed as two consecutive actions: delete and then insert…Inserts “per se” are not an issue, because SQL Server keeps them in the structure called Deltastore (which, by the way, has B-tree structure), and performs a bulk load into the columnstore index.
列存储索引的最大缺点是UPDATE / DELETE操作。 删除的记录并没有真正删除-它们只是标记为已删除,但是它们仍然是列存储索引的一部分,直到重建索引为止。 更新执行得更糟,因为它们被执行为两个连续的动作:删除然后插入…“本身”插入不是问题,因为SQL Server将其保留在名为Deltastore的结构中(顺便说一下,它具有B树)结构),并批量加载到columnstore索引中。
Therefore, if you are often performing updates and/or deletes, be aware that you will not extract maximum benefit from the columnstore index.
因此,如果您经常执行更新和/或删除,请注意,您不会从列存储索引中获得最大的收益。
So, the right question should be:
因此,正确的问题应该是:
什么时候应该使用B树索引和何时使用列存储IDEXES? (WHEN should I use B-tree indexes, and WHEN columnstore idexes?)
The answer is, as in 99% cases within SQL Server debates — IT DEPENDS!
答案是,正如在SQL Server辩论中的99%情况下一样-IT依赖!
寻找适当的工作量 (Finding the appropriate workload)
The key challenge is to identify the scenario, or better say the workload, that suits best to the usage of columnstore vs rowstore indexes.
关键的挑战是确定最适合使用列存储索引和行存储索引的方案,或者更确切地说是工作负载 。
Here are some recommendations for best practice usage for each of the index types:
以下是针对每种索引类型的最佳实践用法的一些建议:
- Use columnstore indexes on large tables (with at least a few million records), that are not being updated/deleted frequently 在不经常更新/删除的大型表(至少具有几百万条记录)上使用列存储索引
- Columnstore indexes perform best on static data, such as in OLAP workloads, with a lot of queries that simply reads the data from the tables, or bulk loading new data periodically 列存储索引在静态数据(例如OLAP工作负载)中的性能最佳,其中许多查询仅从表中读取数据,或者定期批量加载新数据
- Columnstore indexes excel in scanning and performing aggregations on big data ranges (doing SUM, AVG, COUNT, etc), because they are able to process around 900 rows in one batch, while traditional B-tree index process one-by-one (up until SQL Server 2019, which added a batch mode for row-based workload) 列存储索引擅长在大数据范围(执行SUM,AVG,COUNT等)上扫描和执行聚合,因为它们能够一批处理大约900行,而传统的B树索引则可以一对一处理(向上直到SQL Server 2019,这为基于行的工作负载添加了批处理模式)
- Use B-tree indexes on highly transactional workloads, when your table is being frequently modified (updates, deletes, inserts) 当表经常被修改(更新,删除,插入)时,在具有高事务性的工作负载上使用B树索引
B-tree indexes will usually perform better in queries with high selectivity, for example, when you are returning a single value or small number of values, or if you are querying a small range of values (SEEKing for a value)
B树索引通常在具有高选择性的查询中表现更好,例如,当您返回单个值或少量值时,或者在查询较小范围的值时( SEEK查找值)
To say that you should use columnstore indexes in OLAP workloads while using B-tree indexes in OLTP environment, will be huge oversimplifying. In order to get the proper answer to this question, you should ask yourself: what kind of queries are mostly used for the specific table? As soon as you get the answer to this question, you will be able to define the proper indexing strategy for your own workload.
说您应该在OLAP工作负载中使用列存储索引,而在OLTP环境中使用B树索引时,将大大简化。 为了获得对该问题的正确答案,您应该问自己: 特定表最常使用哪种查询? 一旦获得该问题的答案,就可以为自己的工作量定义适当的索引编制策略。
And, finally, in case you wonder if you can take the best from both worlds: the answer is — YES! Starting from SQL Server 2016, you can combine columnstore and traditional B-tree indexes on the same table!
最后,以防万一,您是否想从两个方面都做到最好:答案是-是的! 从SQL Server 2016开始,您可以在同一张表上组合列存储和传统B树索引!
That’s, however, a separate and complex topic that requires serious planning and various considerations, which is out of the scope of this article.
但是,那是一个单独且复杂的主题,需要认真计划和各种考虑,这不在本文的讨论范围之内。
Thanks for reading!
谢谢阅读!
翻译自: https://towardsdatascience.com/rows-or-columns-where-should-i-put-my-index-on-65d429692dee
易变列放在索引的后面















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









