



介绍 (Introduction)
This article is written as a guide for an end to end scraping of data from amazon.in website starting from product links from listing pages to each product data from their individual pages. I have explained every detail as simple as possible with the intention that anyone can use the logic used here to scrape different e-commerce sites as these sites are much trickier to scrape compared to traditional HTML sites. Please read the Terms & Conditions carefully for any website whether you can legally use the data. This is for educational purposes only.
本文旨在指导您从amazon.in网站端到端地抓取数据,从清单页面的产品链接到其各自页面的每个产品数据。 我已经尽可能详细地解释了每个细节,目的是任何人都可以使用此处使用的逻辑来刮擦不同的电子商务站点,因为与传统HTML站点相比,这些站点要抓取起来要困难得多。 无论您是否可以合法使用数据,请仔细阅读任何网站的条款和条件。 这仅用于教育目的。
什么是网页抓取? (What is Web scraping?)
Web scraping is the process of extracting data from websites. Unlike the traditional way of extracting data by copying and pasting, web scraping can be automated by using programming languages like python by defining some parameters and retrieving data in a shorter time.
Web抓取是从网站提取数据的过程。 与通过复制和粘贴提取数据的传统方式不同,可以通过使用python等编程语言通过定义一些参数并在更短的时间内检索数据来自动进行Web抓取。
Selenium的特征 (Features of Selenium)
Selenium makes it very easy to interact with dynamic websites with its bucket of useful features. It helps in identifying and extracting elements from websites with the help of function like
Selenium具有许多实用功能,可轻松与动态网站进行交互。 它可以借助以下功能帮助从网站中识别和提取元素:
- find_element_by_id find_element_by_id
- find_element_by_name find_element_by_name
- find_element_by_xpath find_element_by_xpath
- find_element_by_link_text find_element_by_link_text
- find_element_by_partial_link_text find_element_by_partial_link_text
- find_element_by_tag_name find_element_by_tag_name
- find_element_by_class_name find_element_by_class_name
- find_element_by_css_selector find_element_by_css_selector
Just by adding an extra “s” with the “element”, we can extract a list of elements. There are other features too but we will be mostly using these.
只需在“元素”上添加一个额外的“ s”,我们就可以提取元素列表。 还有其他功能,但我们将主要使用这些功能。
先决条件 (Prerequisites)
- Knowledge of Python Python知识
- Basic knowledge of HTML although it is not necessary HTML的基本知识,尽管不是必需的
安装 (Installation)
Anaconda: Download and install it from this link https://www.anaconda.com/ . We will be using Jupyter Notebook for writing the code
Anaconda :从此链接https://www.anaconda.com/下载并安装。 我们将使用Jupyter Notebook编写代码
Chromedriver — Webdriver for Chrome: Download it from this link https://chromedriver.chromium.org/downloads. No need of installing, just copy the file in the folder where we will create the python file. But before downloading, confirm that the driver‘s version matches that of the Chrome browser installed.
Chromedriver-Chrome的Webdriver :从此链接https://chromedriver.chromium.org/downloads下载。 无需安装,只需将文件复制到我们将创建python文件的文件夹中即可。 但是在下载之前,请确认驱动程序的版本与安装的Chrome浏览器的版本匹配。


3. Selenium: Install selenium by opening Anaconda prompt and type the code below and press enter
3. Selenium :通过打开Anaconda提示符安装Selenium ,然后键入以下代码,然后按Enter
pip install seleniumAlternatively, you can open MS command prompt and type the code and press enter
或者 ,您可以打开MS命令提示符并键入代码,然后按Enter键
python -m pip install selenium资料下载 (Downloads)
Here is the link to my GitHub repository https://github.com/chayb/web-scraping. I would recommend to download the file and follow the article simultaneously.
这是我的GitHub存储库https://github.com/chayb/web-scraping的链接。 我建议下载文件并同时关注本文。
导入库 (Importing the libraries)
We start by importing the following libraries
我们首先导入以下库
import selenium
from selenium import webdriver as wb
import pandas as pd
import timeExplanation:
说明:
- Selenium is used for browser automation and helps in locating web elements in the website code Selenium用于浏览器自动化,并有助于在网站代码中查找Web元素
- Pandas is a data analysis and manipulation tool which will be used for saving the extracted data in a DataFrame Pandas是一种数据分析和处理工具,将用于将提取的数据保存在DataFrame中
- The time library is used for several purposes but we will be using it for delaying the code execution here 时间库有多种用途,但在这里我们将使用它来延迟代码执行
启动浏览器 (Starting up the Browser)
First, we will be scraping product links of Smart TVs from the listing pages of Amazon.in. Then we will scrape the product data from each of the product pages.
首先,我们将从Amazon.in的列表页面抓取智能电视的产品链接。 然后,我们将从每个产品页面抓取产品数据。
So let’s open our Chrome browser and the designated starting URL by running this code
因此,通过运行以下代码,让我们打开Chrome浏览器和指定的起始URL
wbD = wb.Chrome('chromedriver.exe')
wbD.get('https://www.amazon.in/s?bbn=1389396031&rh=n%3A976419031%2Cn%3A%21976420031%2Cn%3A1389375031%2Cn%3A1389396031%2Cn%3A15747864031&dc&fst=as%3Aoff&qid=1596287247&rnid=1389396031&ref=lp_1389396031_nr_n_1')The browser should open to a webpage similar to this. (The webpage may vary as Amazon changes its product listing with time)
浏览器应打开与此类似的网页。 ( 随着亚马逊随时间更改其产品列表,该网页可能会有所不同)

探索和定位元素 (Exploring and locating Elements)
Now its time to explore the elements to find the links to the products.
现在是时候探索元素以找到产品的链接了。
产品链接探索 (Product Links Exploration)
Generally, the name of the products are clickable and point to the respective product page. So, right-click anywhere on the page and click inspect to open the developer tools.
通常,产品名称是可单击的,并指向相应的产品页面。 因此,右键单击页面上的任意位置,然后单击检查以打开开发人员工具。
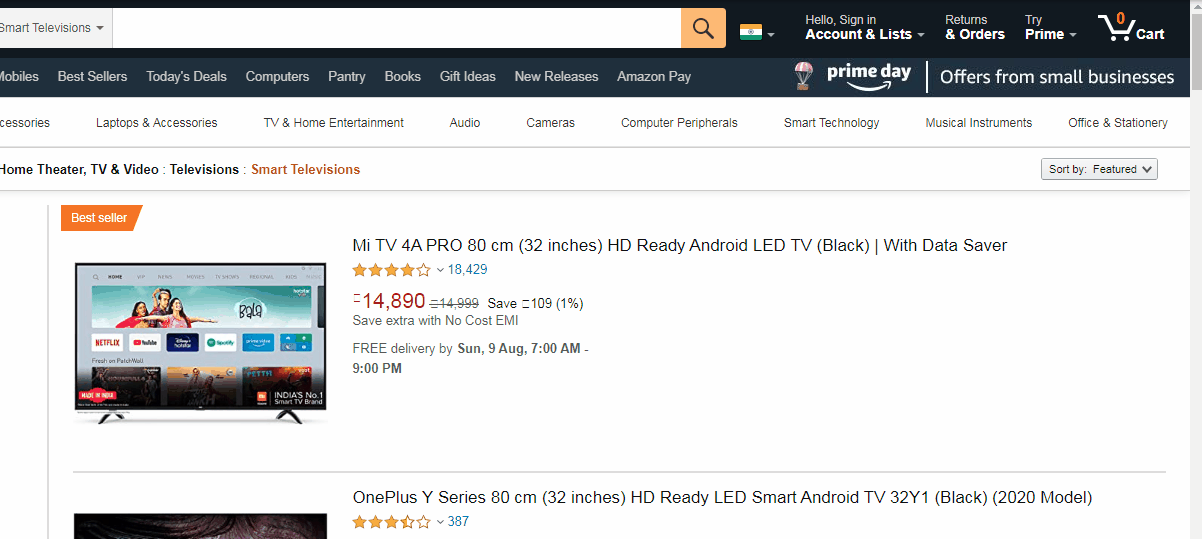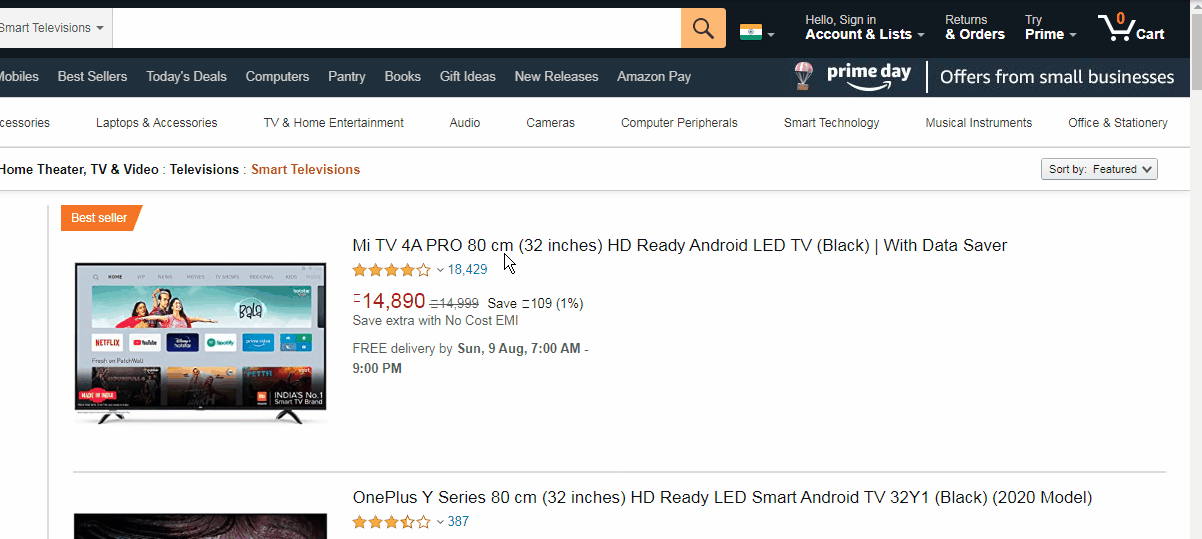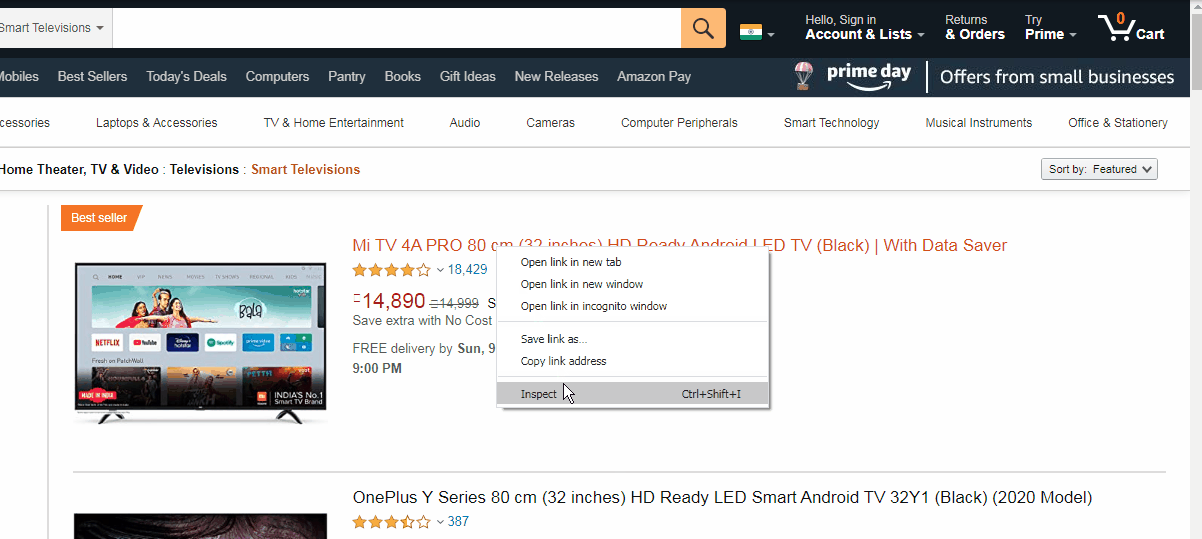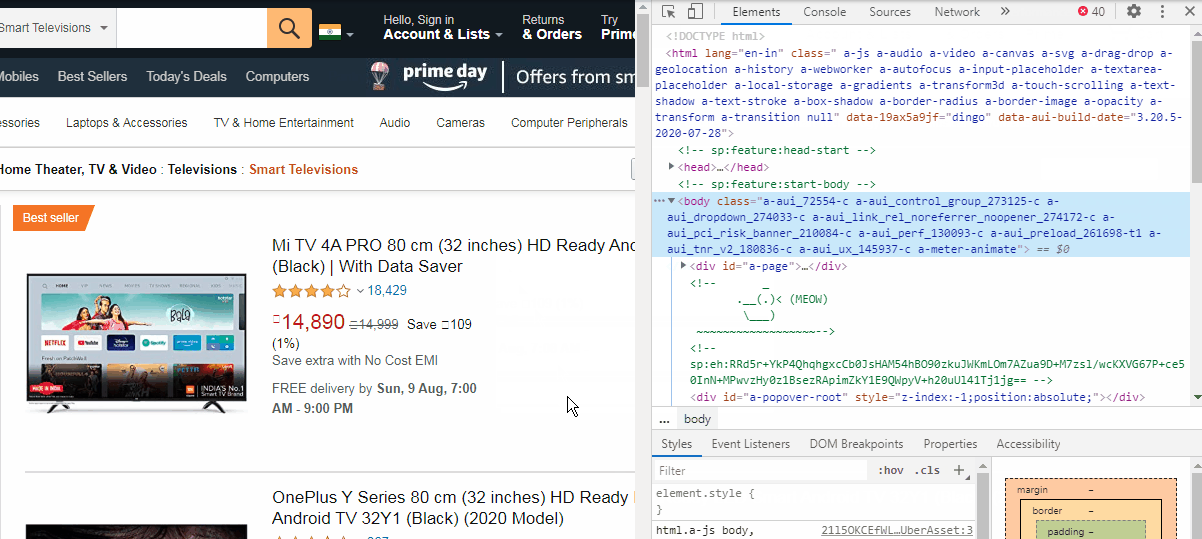
Now we need to right-click the product name to highlight the element in the developer tools window. We are looking for a URL which will be in the form of href = "url link" . These links point to their respective product pages. As we hover the mouse over the code, we see the title gets highlighted. We have also found the URL for the product page (see the image below).
现在,我们需要右键单击产品名称,以在开发人员工具窗口中突出显示该元素。 我们正在寻找一个以href = " url link "形式的href = " url link " 。 这些链接指向各自的产品页面。 当我们将鼠标悬停在代码上时,我们看到标题突出显示。 我们还找到了产品页面的URL( 请参见下图 )。
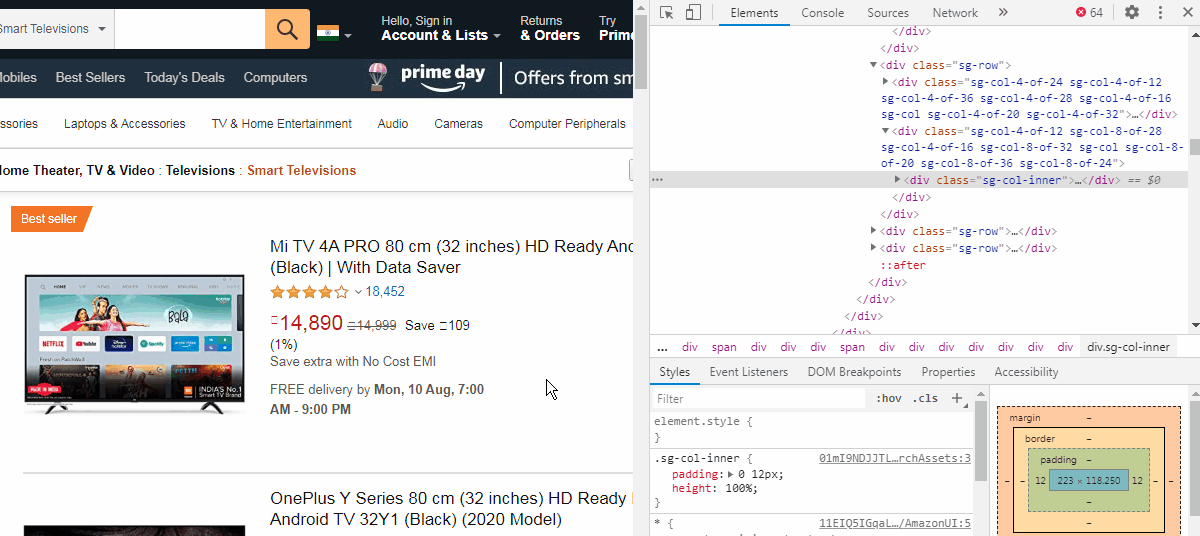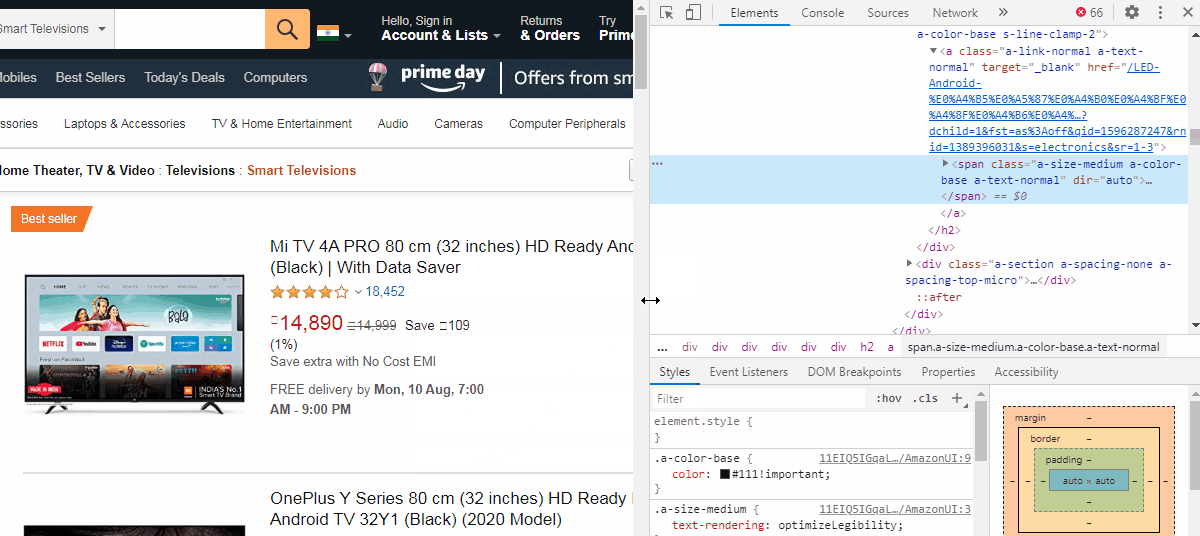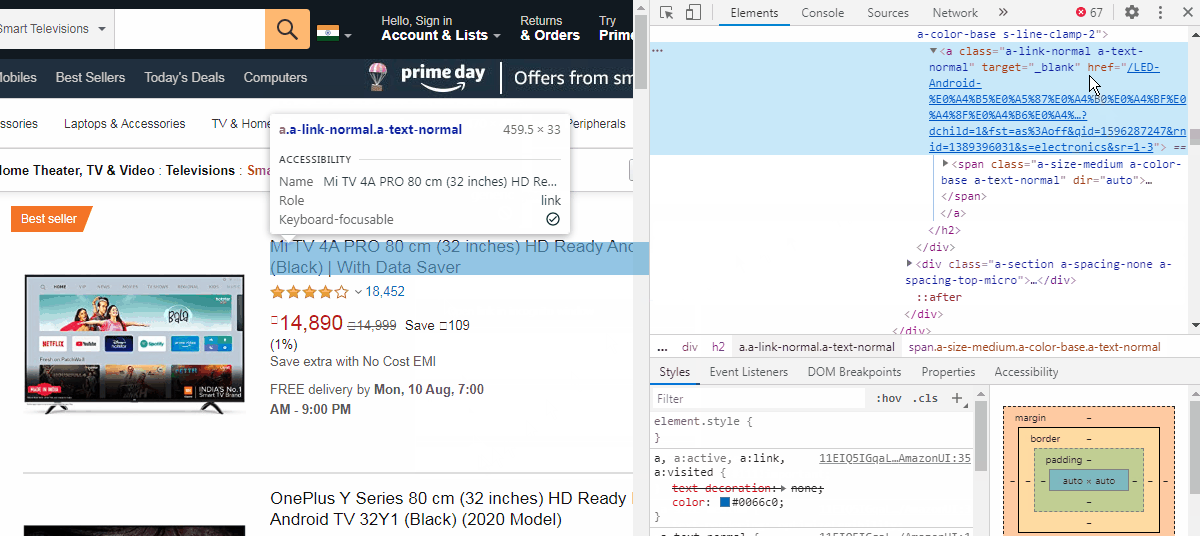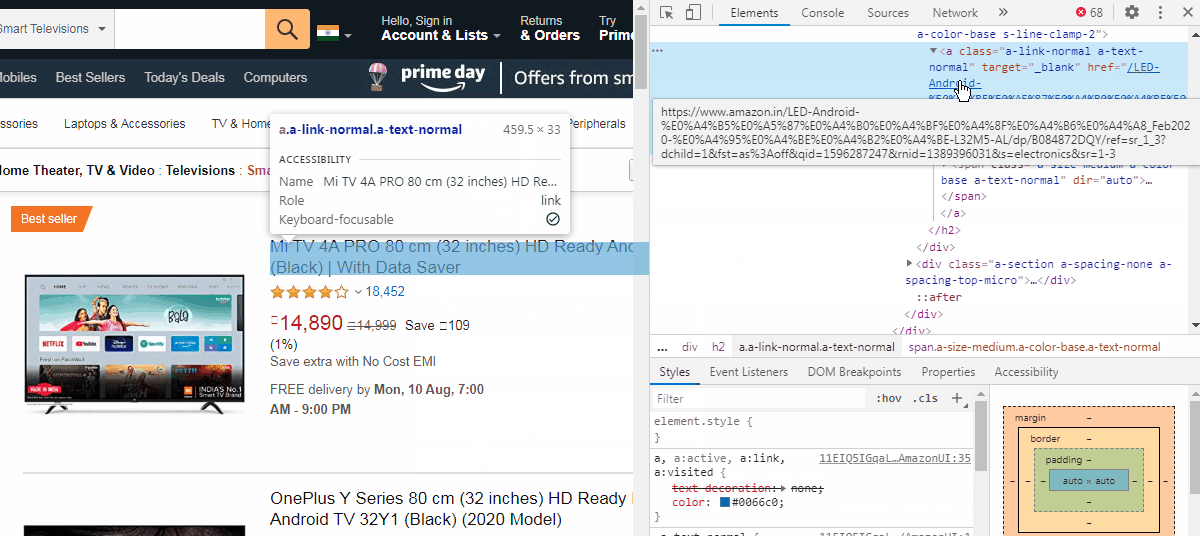
使用Class_name或Id提取元素 (Extract elements using Class_name or Id)
Now, we cannot directly extract this link. We need to find a “class” or “Id” attributes which are like containers for similar product links. We can see that the href is inside a <a> tag which is just below a <h2> tag of class name “a-size-mini a-spacing-none a-color-base s-line-clamp-2”. The indent of the <a> tag shows that it is a child of the <h2> tag element.
现在,我们不能直接提取此链接。 我们需要找到一个“ 类”或“ Id”属性,它们类似于类似产品链接的容器。 我们可以看到href位于<a>标记内,该标记位于类名称“ a-size-mini a-spacing-one a-color-base s-line-clamp-2 ”的<h2>标记下方。 <a>标签的缩进显示它是<h2>标签元素的子元素。

We can use this class name to try to extract the links. The class name has a lot of whitespaces, so we can use the part just before the first whitespace i.e. “a-size-mini”. You can also use the complete name by replacing the whitespace by periods(.).
我们可以使用此类名称尝试提取链接。 类名有很多空格,因此我们可以在第一个空格之前使用该部分,即“ a-size-mini”。 您也可以通过使用句点(。)替换空格来使用完整名称。
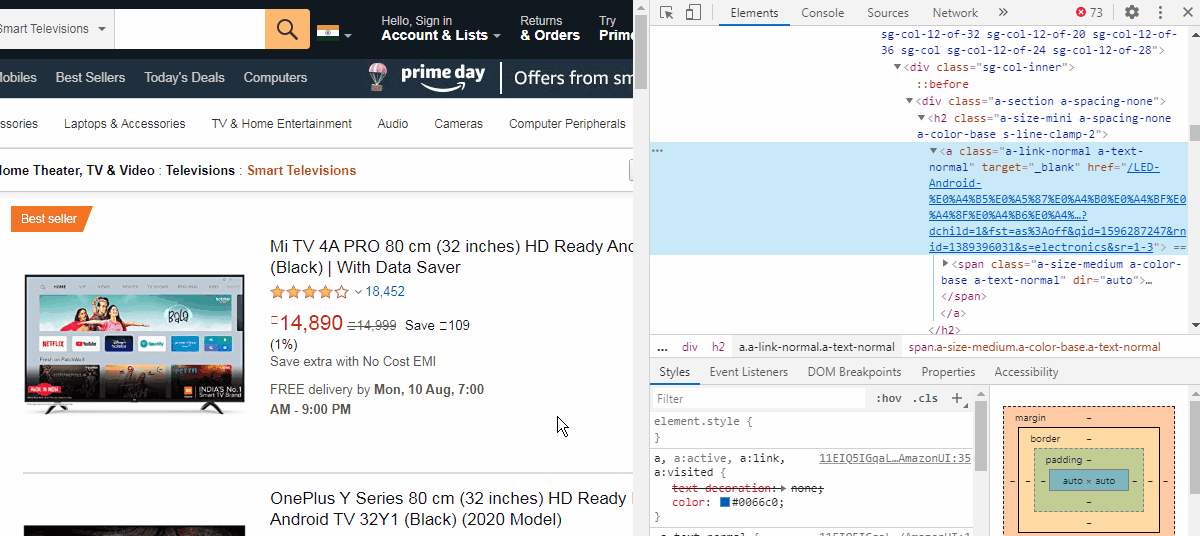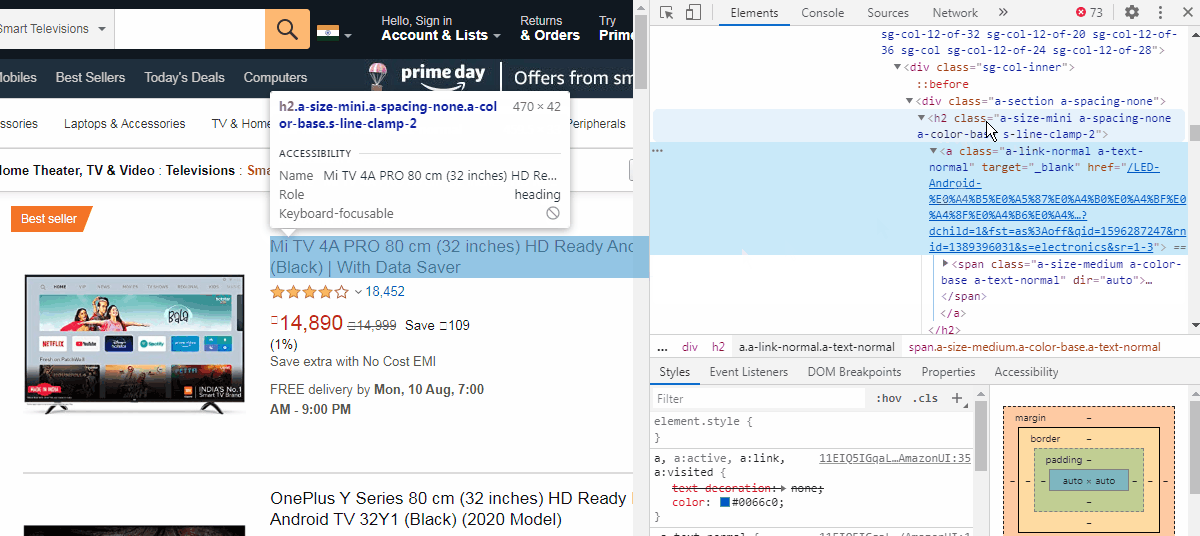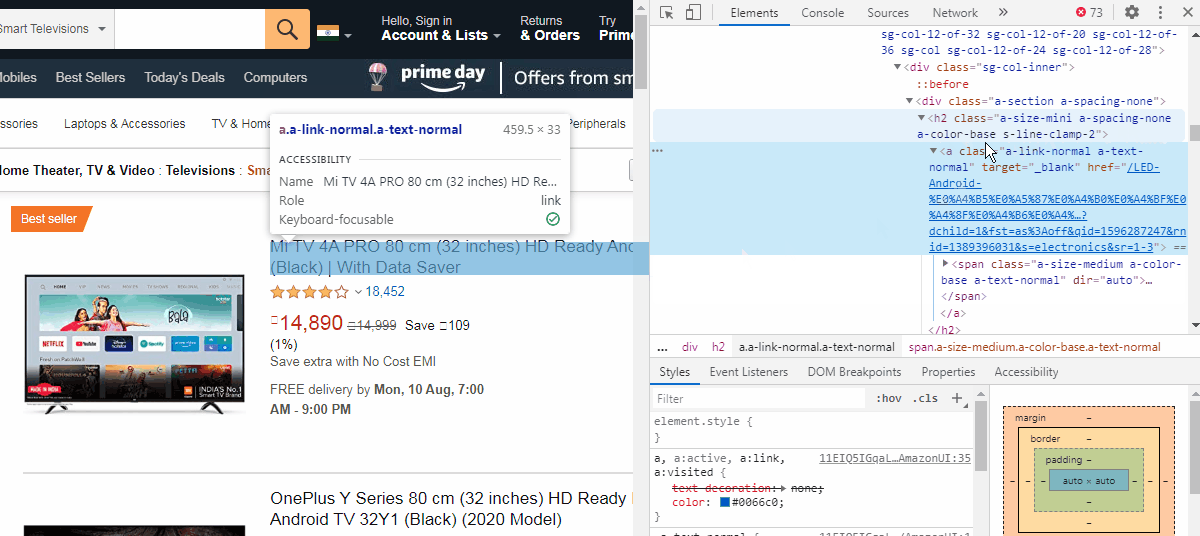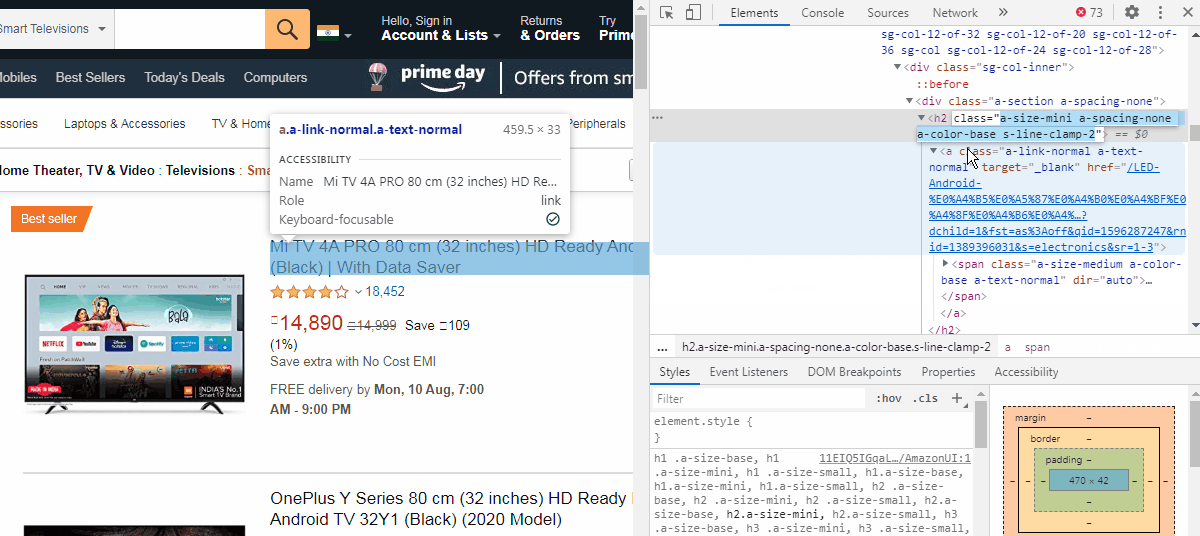
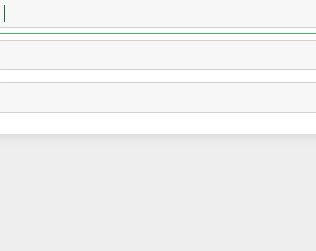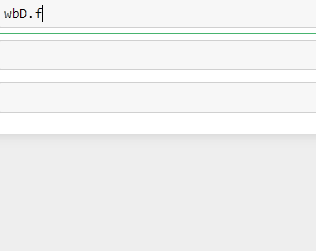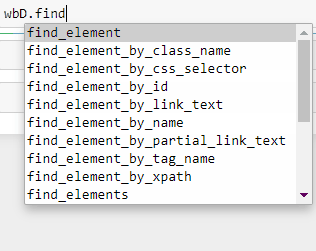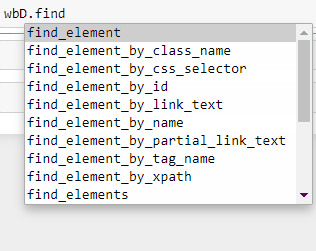
Let us check if we can extract the links by class name. (Tip: As soon as you type wbD.find, you can click the Tab key on the keyboard to get a list of commands available)
让我们检查是否可以按类名提取链接。 ( 提示:键入 wbD.find ,您可以单击键盘上的Tab键以获取可用命令列表 )
Selenium has a function called “find_elements_by_class_name”. Using that we will try to extract all the elements in the source code and store it inside the “productInfoList” variable. We will check if the no. of elements extracted is equal to the no. of product listings on the page.
Selenium具有一个名为“ find_elements_by_class_name ”的功能。 使用它,我们将尝试提取源代码中的所有元素并将其存储在“ productInfoList ”变量中。 我们将检查是否。 提取的元素数等于no。 页面上的产品列表。
productInfoList = wbD.find_elements_by_class_name('a-size-mini')
len(productInfoList)Output: 30The len()is used to check the number of elements we got by class name stored in “productInfoList”. The output is 30, although the page shows 24 product listings.
len()用于检查通过存储在“ productInfoList ”中的类名获得的元素数。 尽管页面显示了24个产品列表,但输出为30。
Note: This output can vary from time to time as amazon modify their listing. Also if you using an antivirus like Kaspersky, they block the sponsored ads from view by default and hence the output number may vary. There is another issue due to antivirus which I will discuss later.
注意:随着亚马逊修改其清单,此输出可能会不时变化 。 另外,如果您使用的是像卡巴斯基这样的防病毒软件,则默认情况下它们会阻止赞助广告,因此输出数量可能会有所不同。 由于防病毒,还有另一个问题,我将在后面讨论。
This means that some of the extra objects extracted either do not contain any links or contain sponsored links. We need to verify that. We see the href is within an <a> tag (see image above). Since the “productInfoList” is a list that contains many elements, we can extract each by an index number. Here we are taking index=0. To extract the data inside and also the href property we can first use
这意味着提取的某些额外对象要么不包含任何链接,要么包含赞助链接。 我们需要验证一下。 我们看到href位于<a>标记内( 请参见上图)。 由于“ productInfoList”是一个包含许多元素的列表,因此我们可以通过索引号提取每个元素。 在这里,我们采用索引= 0。 要提取内部数据以及href属性,我们可以首先使用
pp2=productInfoList[0].find_element_by_tag_name('a')After executing the command we got an error,
执行完命令后,我们得到了一个错误,
StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
(Session info: chrome=84.0.4147.105)which proves that there are no <a> tags inside and hence no links. We tried it from 0 to 4, where we observed that index 2 has a <a> tag inside and the rest didn’t.
证明里面没有<a>标记,因此也没有链接。 我们从0到4进行了尝试,发现索引2里面有一个<a>标记,其余的则没有。
productInfoList[2].find_elements_by_tag_name('a')Output:[<selenium.webdriver.remote.webelement.WebElement (session="64b5966ffc556de741895f1a68da5ff3", element="ff23ee89-d025-422d-830b-e297a15bbe23")>]But whether it has a product link or not can be confirmed by printing the text inside which should be the ‘name of the TV’. If it returns a blank, then it proves that it is redundant.
但是,是否带有产品链接可以通过打印其中应为“电视名称”的文字来确认。 如果返回空白,则证明它是多余的。
productInfoList[2].textOutput: ''The output is empty which proves that the element is not useful.
输出为空,这证明该元素没有用。
Note: Remember I spoke of an issue, it has been observed that if you are not using any antivirus or adblocker, then some of the above elements contain a text called “Sponsored” instead of a ‘ ’. So later on while capturing the links we need to ignore such elements also.
注意:请记住,我曾提到过一个问题,已经观察到,如果您未使用任何防病毒或adblocker,则上述某些元素包含名为“ Sponsored”而不是 '' 的文本 。 因此,稍后在捕获链接时,我们也需要忽略此类元素。
But index 5 gave a link which is not in the product list which proves it is a sponsored link. We will scrape these links too and we can remove it later from the excel sheet if needed at the end. Next, let us try the index ‘6’.
但是索引5给出了不在产品列表中的链接,这证明它是赞助者链接。 我们也会抓取这些链接,如果需要的话,我们可以稍后将其从excel表中删除。 接下来,让我们尝试索引“ 6”。
pp2=productInfoList[6].find_element_by_tag_name('a')
pp2.get_property('href')Output: 'https://www.amazon.in/Mi-inches-Ready-Android-Black/dp/B084872DQY/ref=sr_1_3?dchild=1&fst=as%3Aoff&qid=1596287247&rnid=1389396031&s=electronics&sr=1-3'No error. This gives the link for the first product on the page i.e. Mi TV 4A. Hence index numbers from 6 to 29 (index start from 0) are our product links. This gives the 24 products listed on the page. Now let us move to the next part i.e. to loop through page nos. to extract all the product links on all pages.
没错 这提供了页面上第一个产品的链接,即Mi TV 4A 。 因此,索引号从6到29( 索引从0开始)是我们的产品链接。 这给出了页面上列出的24个产品。 现在让我们进入下一部分,即遍历页面编号。 提取所有页面上的所有产品链接。
分页 (Pagination)
We need to locate the next button on the first page and inspect the element by right-clicking as we did previously.
我们需要在首页上找到下一个按钮,并像以前一样右键单击来检查元素。

We can see the next button has an href link and is inside a class called ‘a-last’. Hence like we did before let us extract the element by class name. But we do not need the href, instead, we will click the button with the help of Selenium.
我们可以看到next按钮具有href链接,并且位于名为“ a-last ”的类内。 因此,就像我们之前所做的那样,让我们通过类名称提取元素。 但是我们不需要href ,相反,我们将在Selenium的帮助下单击该按钮。
wbD.find_element_by_class_name('a-last').click()After executing the code, the website moves to the next page. Hence we are on the right path. We generally write the code inside a while loop so that when the last page is reached, then clicking the next button throws an error and the loop is terminated (using Try: & Except:). But here the case is different which I will explain next. So let us now write the complete code to extract the links and also move to the next page
执行代码后,网站将移至下一页。 因此,我们走在正确的道路上。 我们通常将代码编写在while循环内,以便在到达最后一页时,单击“ next”按钮将引发错误,并终止循环(使用Try:&Except :)。 但是这里的情况有所不同,我将在下面解释。 因此,让我们现在编写完整的代码以提取链接并移至下一页
listOflinks =[]
condition =True
while condition:
time.sleep(3)
productInfoList=wbD.find_elements_by_class_name('a-size-mini')
for el in productInfoList:
if(el.text !="" and el.text !="Sponsored"):
pp2=el.find_element_by_tag_name('a')
listOflinks.append(pp2.get_property('href'))
try:
wbD.find_element_by_class_name('a-last').find_element_by_tag_name('a').get_property('href')
wbD.find_element_by_class_name('a-last').click()
except:
condition=False说明: (Explanation:)
time.sleep(3)helps to delay the execution of the next line of code by 3 seconds. This is done as sometimes the webpage spends some time to load and if the code start searching for elements before the page loads, it will give an error. You can adjust the time as per requirement. Also if you make too many requests in a short time, the website might block your IP address.time.sleep(3)有助于将下一行代码的执行延迟3秒。 之所以如此,是因为有时网页会花费一些时间来加载,并且如果代码在页面加载之前开始搜索元素,就会出现错误。 您可以根据需要调整时间。 另外,如果您在短时间内提出过多请求,则该网站可能会阻止您的IP地址。foris used to store eachhreflink in the variable “listOflinks” using an indexfor将每个href链接存储在变量“ listOflinks ”中 使用索引Try:&Except:: Try will always be executed until the code inside it throws an error. The code “wbD.find_element_by_class_name(‘a-last’).click()” is used for clicking the next button. After all the pages are clicked, if we click the next button anymore, it will give an error which will make the condition false and the loop will breakTry:&Except::直到它里面的代码抛出错误尝试就一定会执行。 代码“ wbD.find_element_by_class_name('a-last')。click()”用于单击下一步按钮。 单击所有页面后,如果我们再单击下一步按钮,则会出现错误,使条件为假,并且循环将中断
在这里,我们遇到了一个特例。 (Here we have encountered a special case.)
If we click the next button right after all the pages have been scraped, it generally throws an error but here it does not throw an error, hence an infinite loop is created. We will use a workaround. So we check that on the last page the next button has no href link. Hence inside ‘Try:’, we are just checking whether there is any href link inside the next button, if no link is found it throws an error hence executing the code inside ‘Except:’ and breaks out of the loop.
如果我们在所有页面都被抓取后立即单击下一步按钮,通常会引发错误,但在这里不会引发错误,因此会创建无限循环。 我们将使用一种解决方法。 因此,我们检查最后一页上的下一个按钮是否没有href链接。 因此,在“ Try:”内部,我们只是检查是否有任何 href 下一个按钮内的链接,如果找不到链接,则会引发错误,因此在“ Except:”内执行代码,并跳出循环。
Below is the complete code snippet to extract all the product links from the listing pages.
以下是完整的代码段,用于从列表页面提取所有产品链接。
#importing libraries
import selenium
from selenium import webdriver as wb
from selenium.webdriver.support.ui import Select
import pandas as pd
import time
#Opening Chrome browser
wbD=wb.Chrome('chromedriver.exe')
#Opening webpage
wbD.get('https://www.amazon.in/s?bbn=1389396031&rh=n%3A976419031%2Cn%3A%21976420031%2Cn%3A1389375031%2Cn%3A1389396031%2Cn%3A15747864031&dc&fst=as%3Aoff&qid=1596287247&rnid=1389396031&ref=lp_1389396031_nr_n_1')
#Running loop to store the product links in a list
listOflinks =[]
condition =True
while condition:
time.sleep(3)
productInfoList=webD.find_elements_by_class_name('a-size-mini')
for el in productInfoList:
if(el.text !="" and el.text !="Sponsored"):
pp2=el.find_element_by_tag_name('a')
listOflinks.append(pp2.get_property('href'))
try:
wbD.find_element_by_class_name('a-last').find_element_by_tag_name('a').get_property('href')
wbD.find_element_by_class_name('a-last').click()
except:
condition=False
len(listOflinks)提取单个产品数据 (Extracting individual product data)
Next, let us explore the individual product page and inspect the elements which we want to scrape. Here we will scrape the data by using Xpath. (Read more about Xpath here: https://www.guru99.com/xpath-selenium.html)
接下来,让我们浏览单个产品页面并检查我们要抓取的元素。 在这里,我们将使用Xpath刮取数据。 ( 在此处了解有关Xpath的更多信息: https : //www.guru99.com/xpath-selenium.html )
Importing the library tqdm to show the progression bar while scraping
导入库tqdm以在抓取时显示进度条
from tqdm import tqdmLet say we want to scrape
假设我们要刮
- SKU (Product Name) SKU(产品名称)
- Price 价钱
- Category 类别
- Brand 牌
- Model 模型
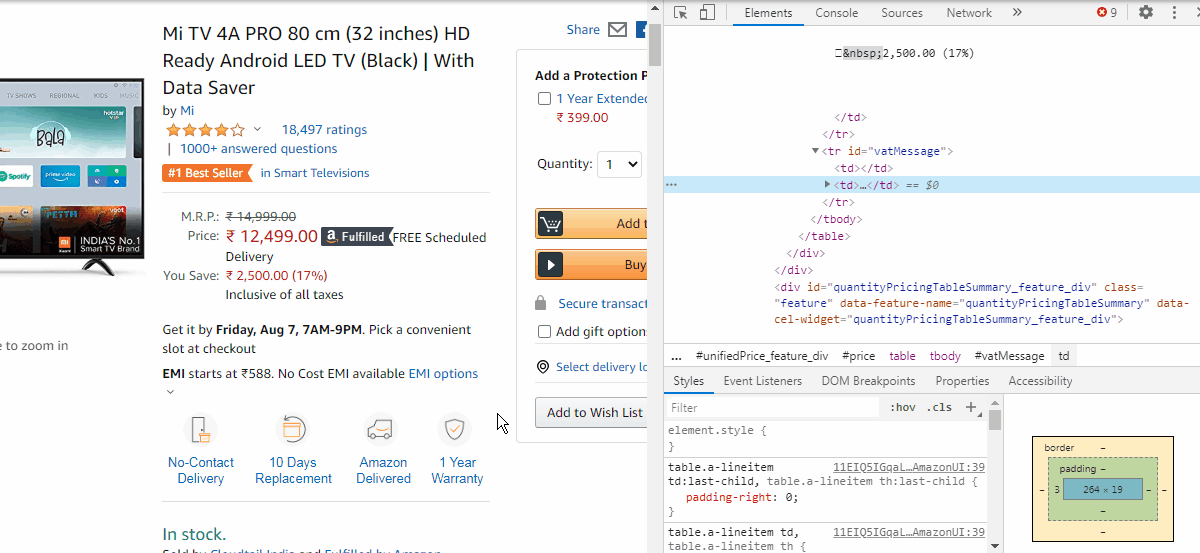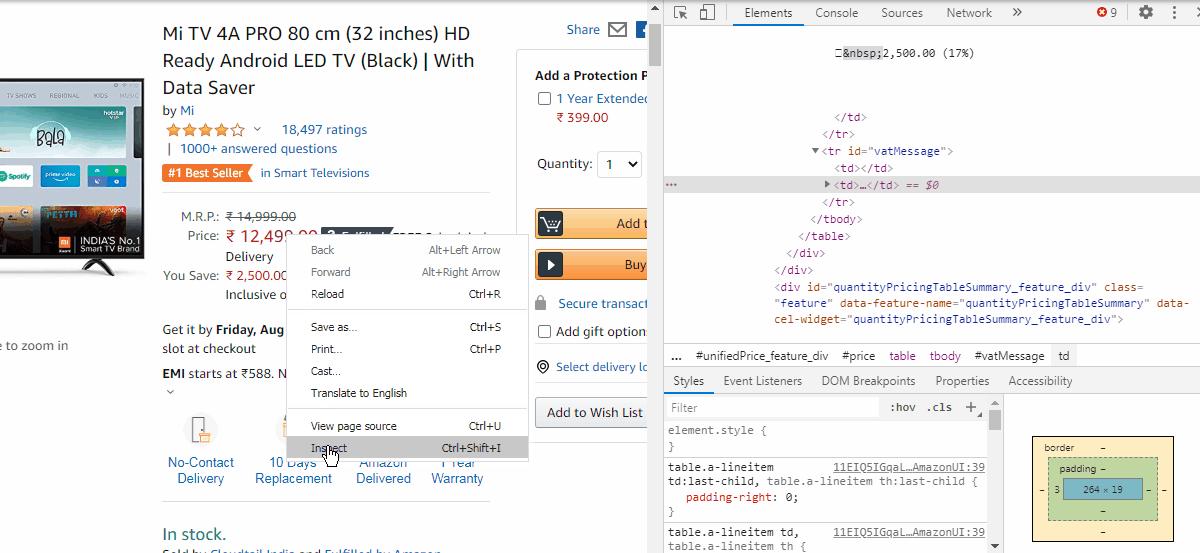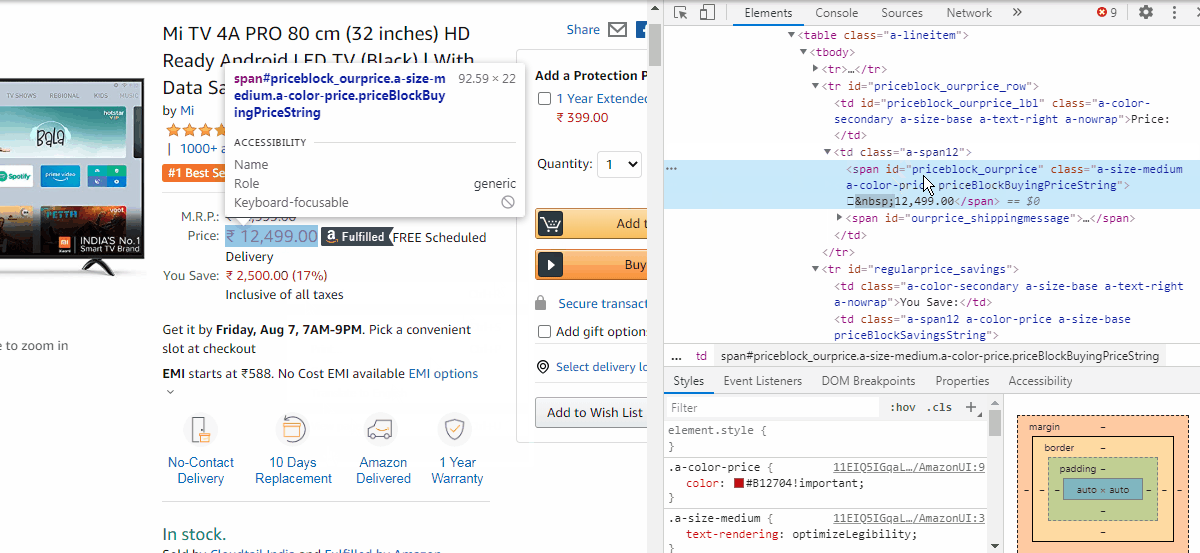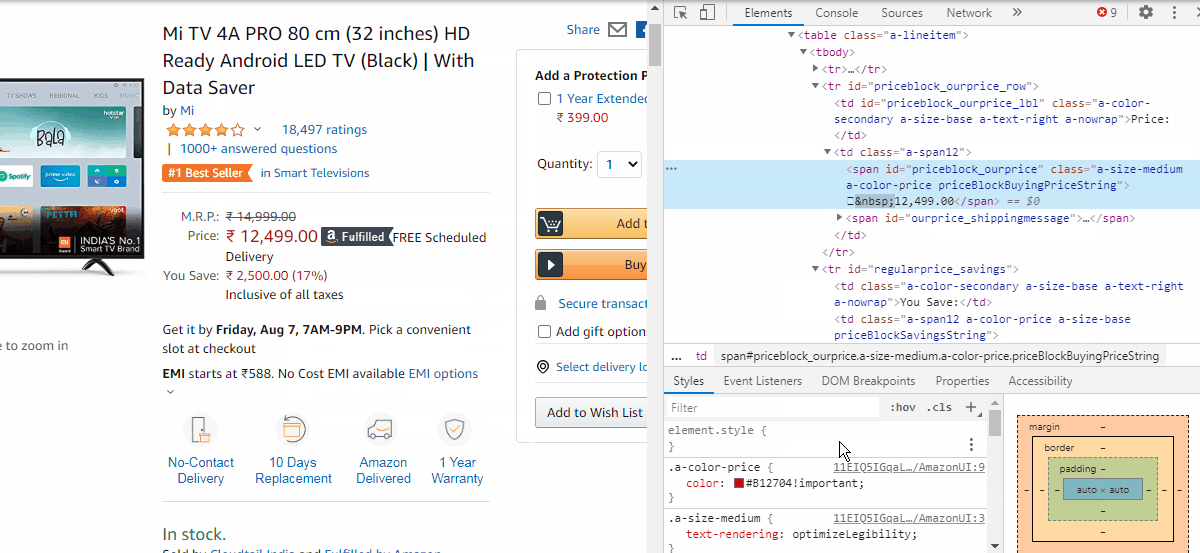
So let us open a product page say the first one. Open the developer tools by Ctrl+Shift+I. Then right-click the product name and click inspect. We can see the code gets highlighted. Right-click the code and copy the XPath. (see image below)
因此,让我们打开一个产品页面,说第一个页面。 通过Ctrl + Shift + I打开开发人员工具。 然后右键单击产品名称,然后单击检查。 我们可以看到代码突出显示。 右键单击代码,然后复制XPath。 ( 见下图 )
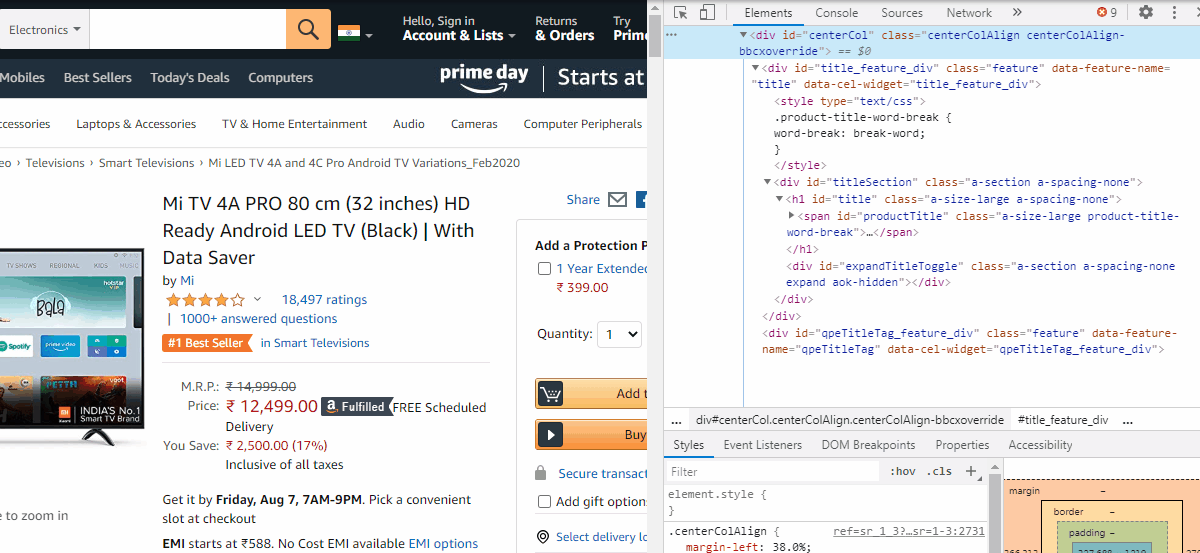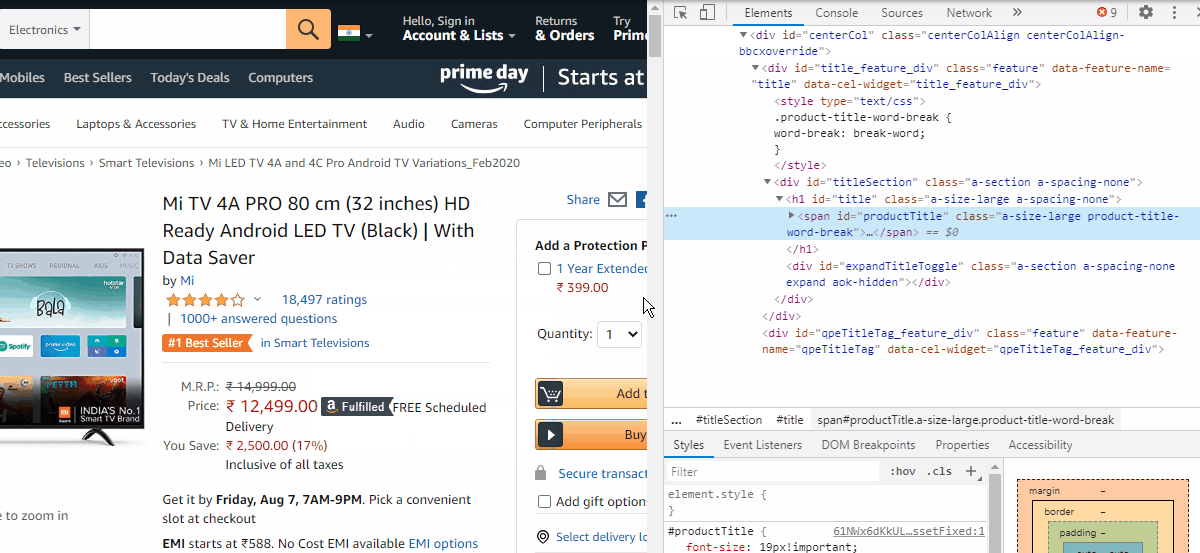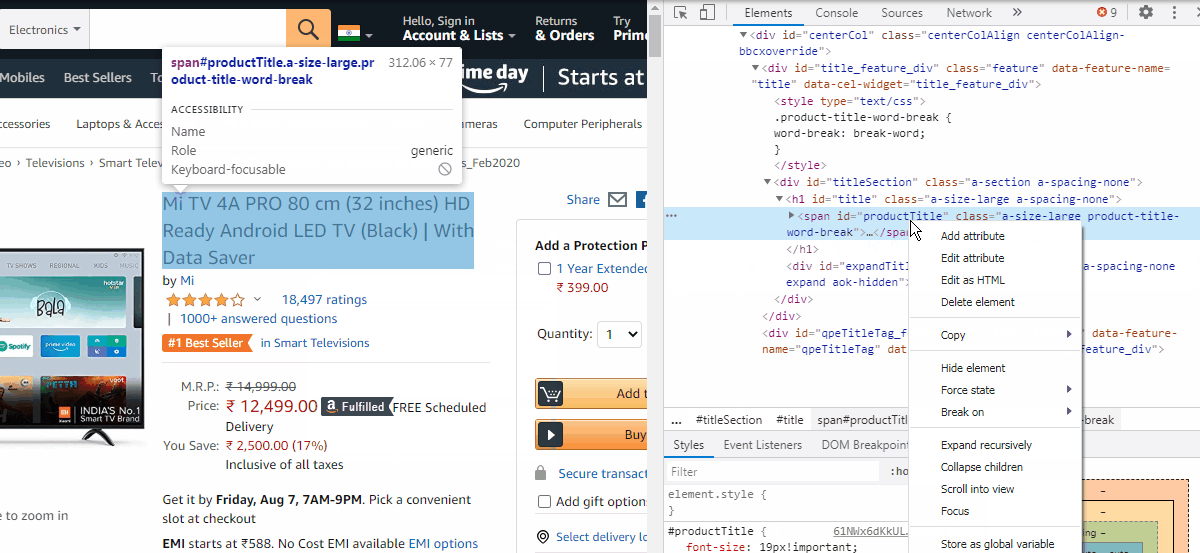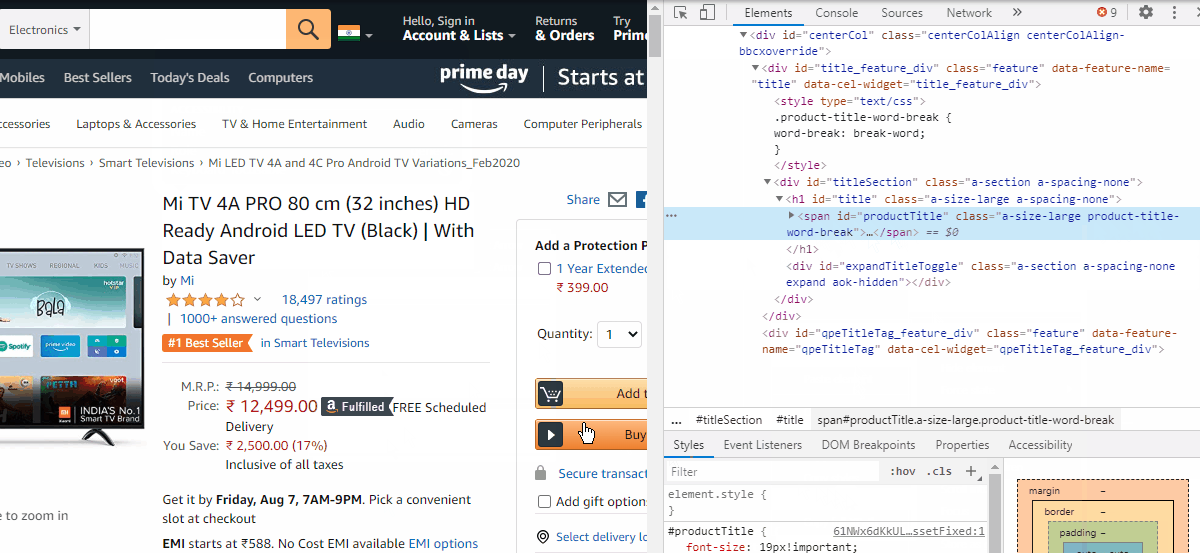
To extract the product name, paste it within the quotes of the find_element_by_xpath function
要提取产品名称,请将其粘贴在find_element_by_xpath函数的引号内
sku = webD.find_element_by_xpath('//*[@id="productTitle"]').textSimilarly, we will do the same for Price & Category.
同样,我们将对“价格和类别”执行相同的操作。
Extract the category name
提取类别名称
category= webD.find_element_by_xpath('//*[@id="wayfinding-breadcrumbs_feature_div"]/ul/li[7]/span/a').textIn the case of price, we need to copy the Xpath which is
对于价格,我们需要复制Xpath
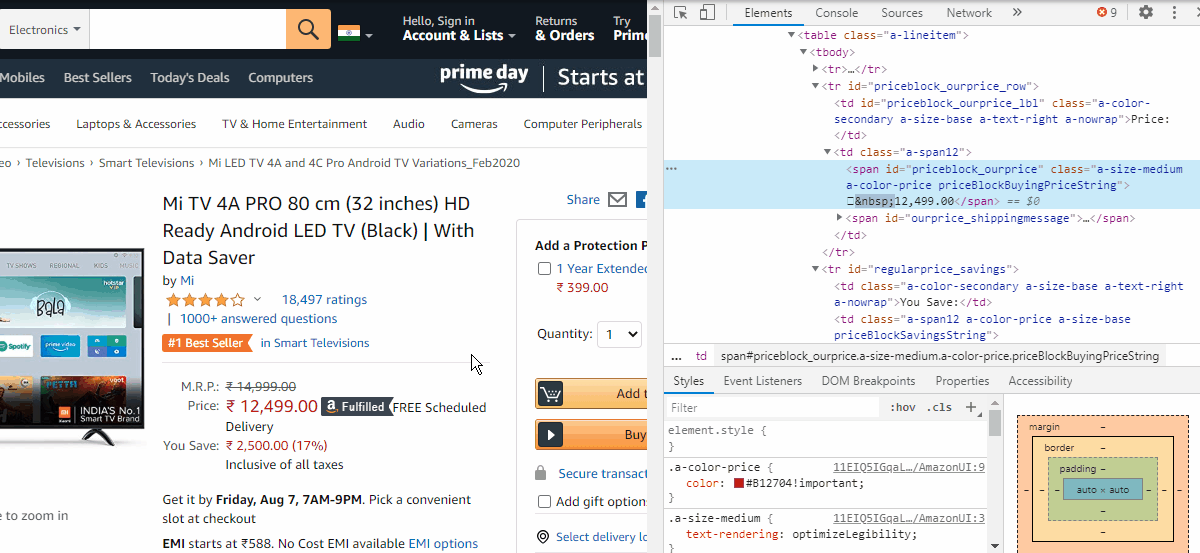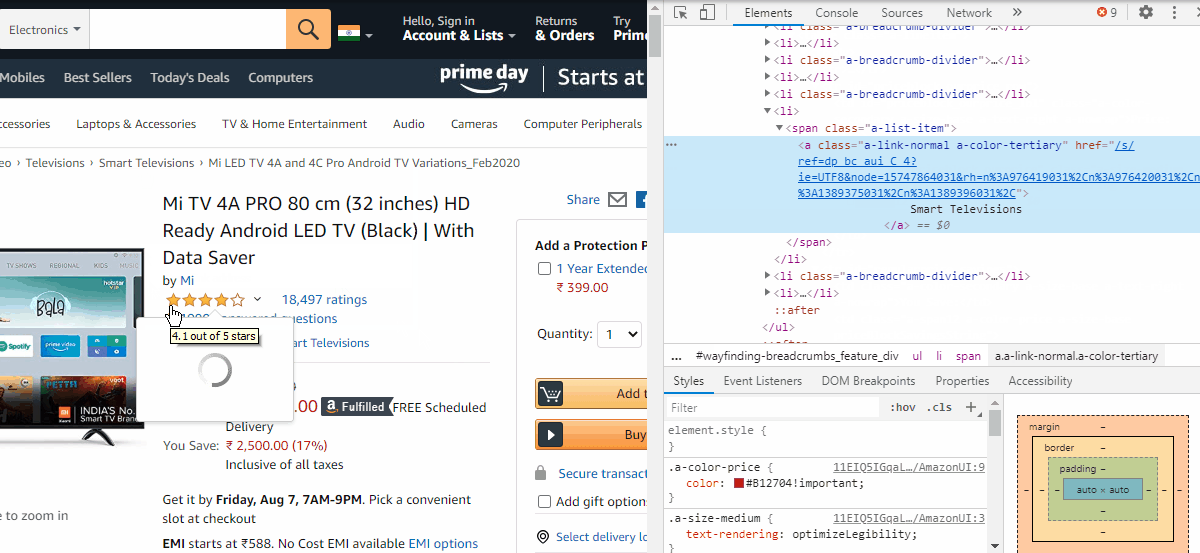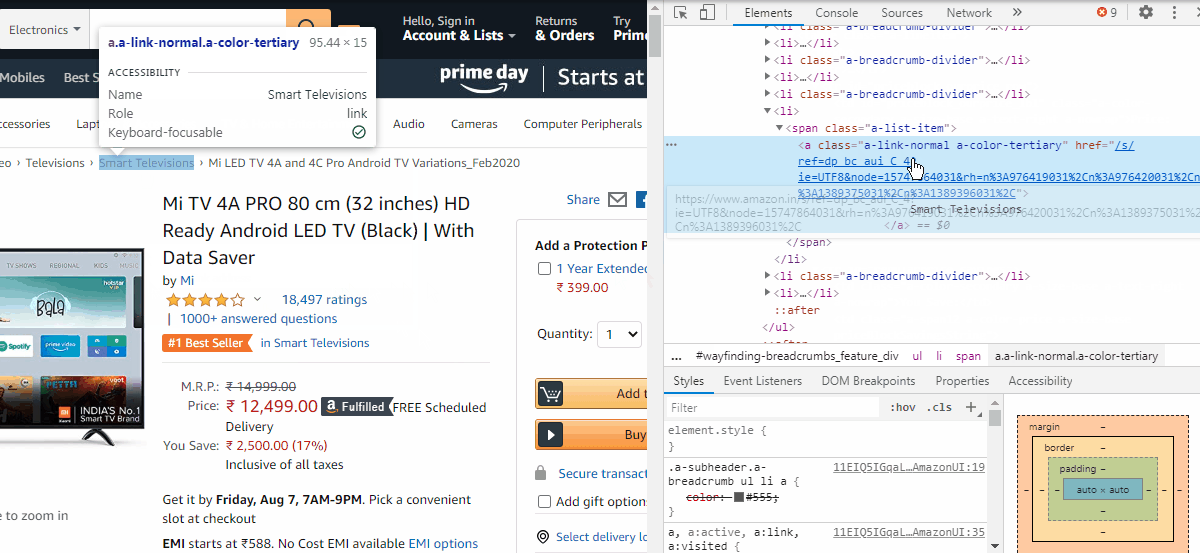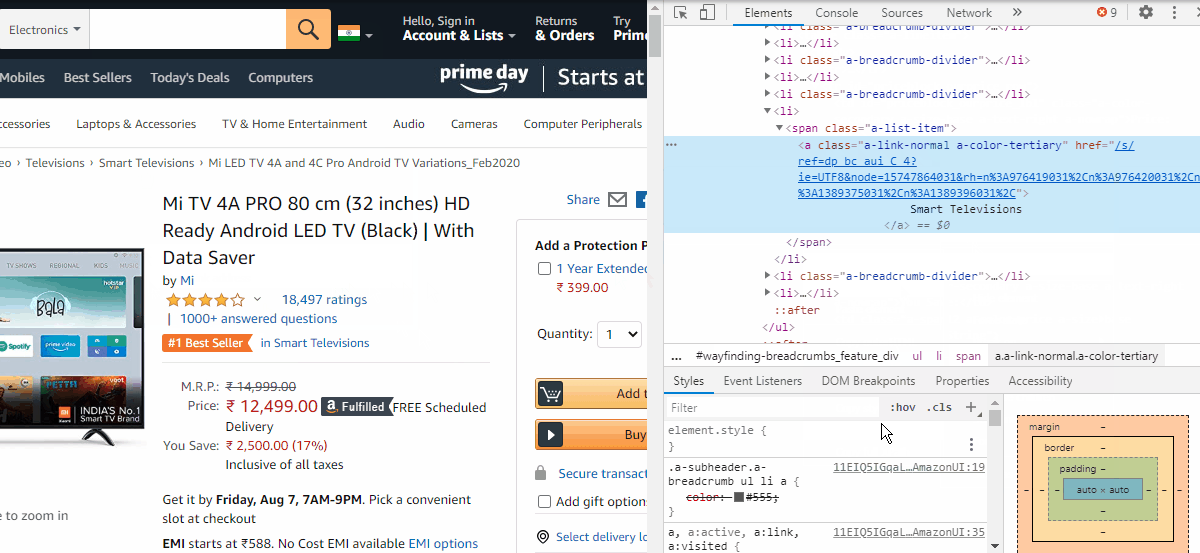
//*[@id="priceblock_ourprice"]But it is observed that in some cases the price is given by a different Xpath which is,
但据观察,在某些情况下,价格是由不同的Xpath给出的,即
//*[@id="priceblock_dealprice"]and in some cases, no price data is given as the product is unavailable. Hence we have three conditions for extracting price data which can be written as
在某些情况下,由于产品不可用,所以没有给出价格数据。 因此,我们有三个条件可以提取价格数据,可以写成
try:
try:
price = webD.find_element_by_xpath('//*[@id="priceblock_ourprice"]').text
except:
price = webD.find_element_by_xpath('//*[@id="priceblock_dealprice"]').text
except:
price=""说明: (Explanation:)
First “priceblock_ourprice” will be checked, if fails, it will check “priceblock_dealprice” and if both fail, the variable ‘price’ will be empty.
首先将检查“ priceblock_ourprice”,如果失败,将检查“ priceblock_dealprice”,如果都失败,则变量“ price”将为空。
Next, we need to scroll down below to the table where the product details are given.
接下来,我们需要向下滚动到提供产品详细信息的表格。

In order to extract the Brand & Model information, we need to explore these elements too. As we inspect, we observe that each info such as Brand, Model, etc. are stored inside <tr> tags. These <tr> tags are all stored under a class attribute called “pdTab”.
为了提取品牌和型号信息,我们也需要探索这些元素。 在检查时,我们观察到每个信息(例如品牌,型号等)都存储在<tr>标记内。 这些<tr>标记都存储在名为“ pdTab ”的类属性下。
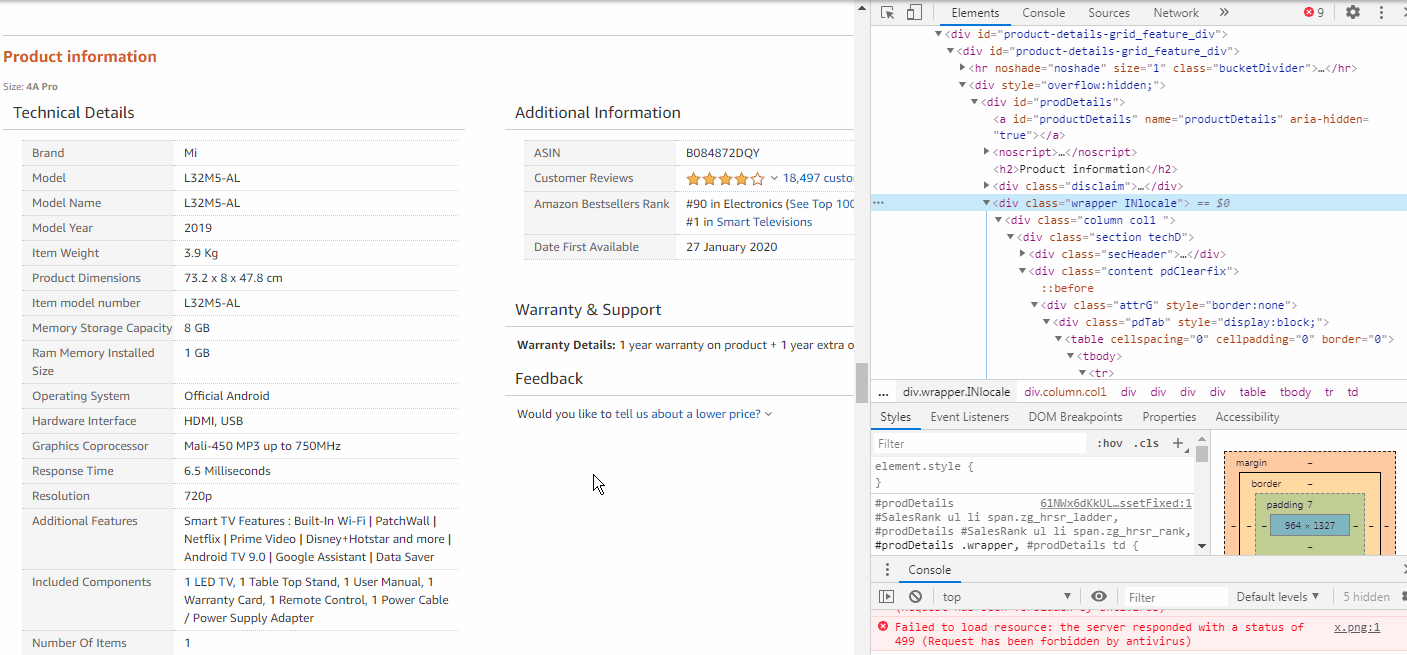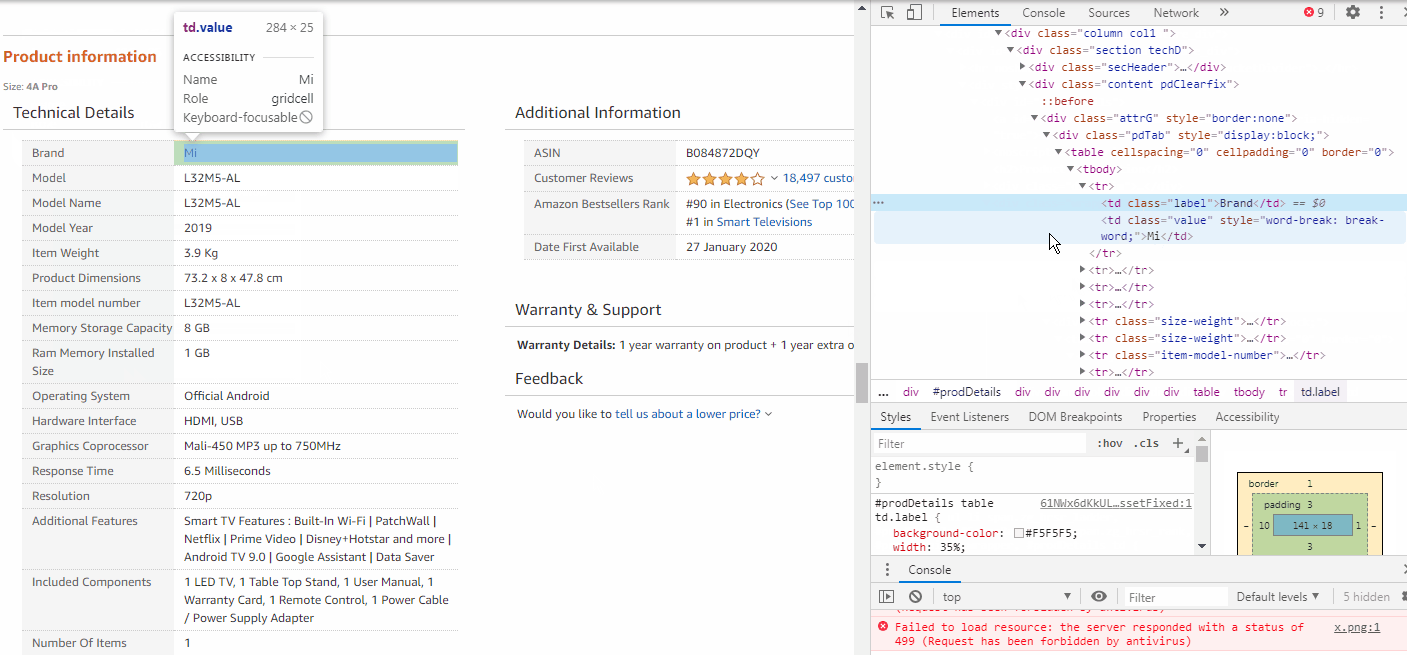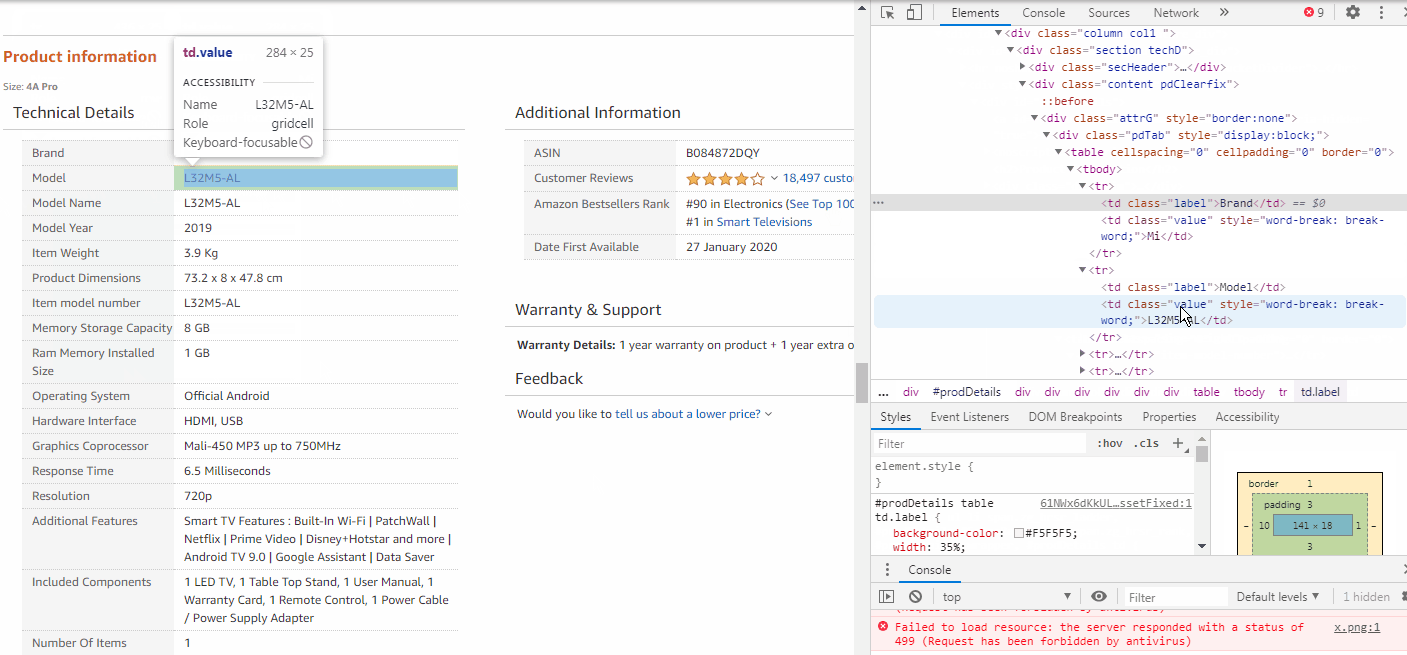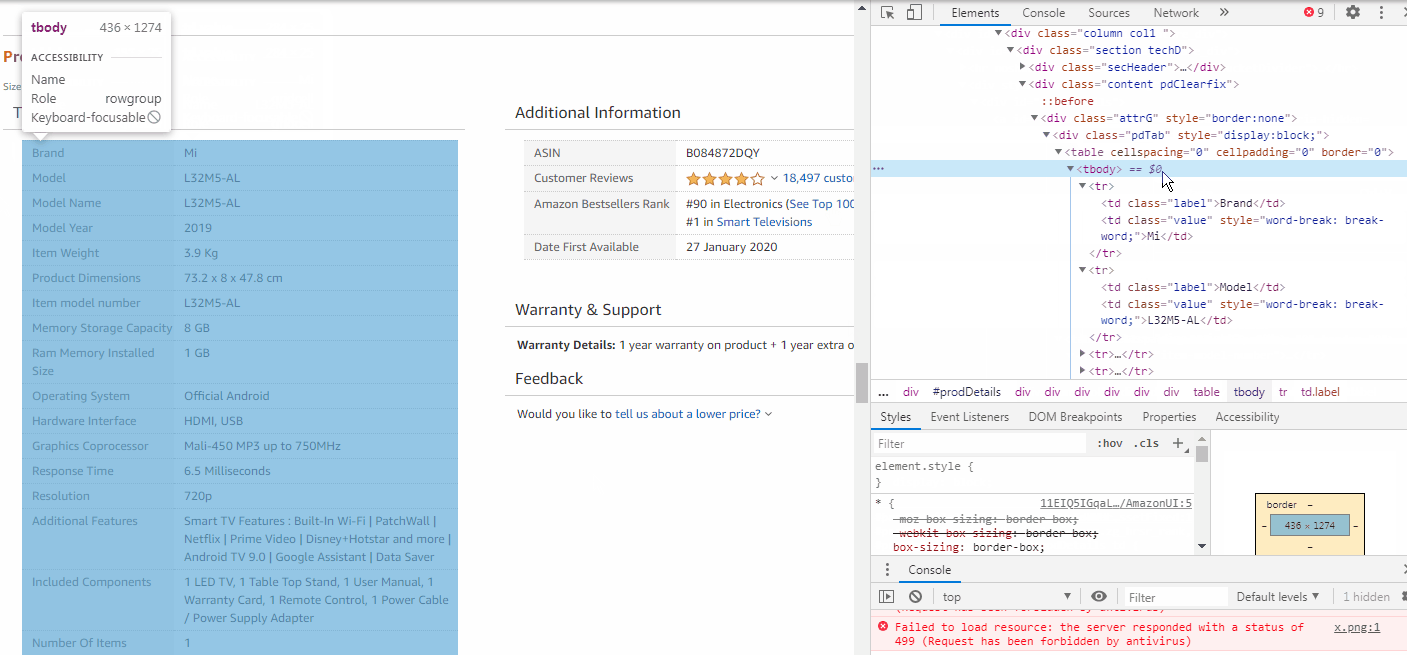
Hence we need to extract all the <tr> elements from inside the class name = pdTab.
因此,我们需要从类名称= pdTab中提取所有<tr>元素。
pp = wbD.find_element_by_class_name('pdTab')
pp1 = pp.find_elements_by_tag_name('tr')Now we use a for loop to check inside each <tr> tags, whether the class=”label” matches with ours, then we will store the text inside class=”value”.
现在,我们使用一个for循环检查每个<tr>标记内,是否class =” label”与我们的匹配,然后将文本存储在class =“ value”内 。

for el in range(len(pp1)-1):
if (pp1[el].find_element_by_class_name("label").text) == 'Brand':
brand= pp1[el].find_element_by_class_name("value").text
if (pp1[el].find_element_by_class_name("label").text) == 'Model':
model= pp1[el].find_element_by_class_name("value").textNext, we store them inside a python dictionary temp and append it to a list alldetails.
接下来,我们将它们存储在python字典temp中 ,并将其附加到列表alldetails中 。
All these codes will be placed inside a for loop which provides the product links we scraped earlier over each iteration.
所有这些代码都将放置在for循环内,该循环提供了我们在每次迭代中早些时候抓取的产品链接。
After running the code, we can print the list as a DataFrame.
运行代码后,我们可以将列表打印为DataFrame。
pd.DataFrame(alldetails)Output:
输出:

We can export the DataFrame as .csv file.
我们可以将DataFrame导出为.csv文件。
data = pd.DataFrame(alldetails)
data.to_csv('Amazon_tv.csv')Here is the complete code.
这是完整的代码。
#importing libraries
import selenium
from selenium import webdriver as wb
from selenium.webdriver.support.ui import Select
import pandas as pd
import time
#Opening Chrome browser
wbD=wb.Chrome('chromedriver.exe')
#Opening webpage
wbD.get('https://www.amazon.in/s?bbn=1389396031&rh=n%3A976419031%2Cn%3A%21976420031%2Cn%3A1389375031%2Cn%3A1389396031%2Cn%3A15747864031&dc&fst=as%3Aoff&qid=1596287247&rnid=1389396031&ref=lp_1389396031_nr_n_1')
#Running loop to store the product links in a list
listOflinks =[]
condition =True
while condition:
time.sleep(3)
productInfoList=webD.find_elements_by_class_name('a-size-mini')
for el in productInfoList:
if(el.text !="" and el.text !="Sponsored"):
pp2=el.find_element_by_tag_name('a')
listOflinks.append(pp2.get_property('href'))
try:
wbD.find_element_by_class_name('a-last').find_element_by_tag_name('a').get_property('href')
wbD.find_element_by_class_name('a-last').click()
except:
condition=False
len(listOflinks)
#scraping individual product details
from tqdm import tqdm
alldetails=[]
brand=""
model=""
for i in tqdm(listOflinks):
wbD.get(i)
time.sleep(3)
sku = wbD.find_element_by_xpath('//*[@id="productTitle"]').text
category= wbD.find_element_by_xpath('//*[@id="wayfinding-breadcrumbs_feature_div"]/ul/li[7]/span/a').text
try:
try:
price = wbD.find_element_by_xpath('//*[@id="priceblock_ourprice"]').text
except:
price = wbD.find_element_by_xpath('//*[@id="priceblock_dealprice"]').text
except:
price=""
pp=wbD.find_element_by_class_name('pdTab')
pp1=pp.find_elements_by_tag_name('tr')
for el in range(len(pp1)-1):
if (pp1[el].find_element_by_class_name("label").text) == 'Brand':
brand= pp1[el].find_element_by_class_name("value").text
if (pp1[el].find_element_by_class_name("label").text) == 'Model':
model= pp1[el].find_element_by_class_name("value").text
temp ={
'SKU':sku,
'Category':category,
'Price':price,
'Brand':brand,
'Model':model,
'linkofproduct':i}
alldetails.append(temp)
#printing the DataFrame
pd.DataFrame(alldetails)
#export the DataFrame as .csv
data = pd.DataFrame(alldetails)
data.to_csv('Amazon_tv.csv')结论 (Conclusion)
I hope I am able to succeed in my intention to teach you to scrape amazon.in & I hope you can use this knowledge to scrape any e-commerce site.
我希望我能够成功地教您抓取amazon.in,并希望您可以利用此知识来抓取任何电子商务网站。
Thank you for reading. Happy coding :)
感谢您的阅读。 快乐的编码:)
翻译自: https://medium.com/analytics-vidhya/web-scraping-e-commerce-sites-using-selenium-python-55fd980fe2fc

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









