





android 揭示动画
Majority of our computers now have multi-core architectures, and terms such as multi-threading often ring in our ears as a way to improve the processing efficiency of applications. Python does offer several tools to parallelize computation, but they are not often well known. Let’s pierce through their secrets in this article.
现在,我们大多数计算机都具有多核体系结构,诸如多线程之类的术语经常在我们耳边响起,以此来提高应用程序的处理效率。 Python确实提供了几种工具来并行化计算,但是它们并不为人们所熟知。 让我们在本文中介绍他们的秘密。
First a small reminder about threading. What is a thread? It’s a lightweight process that runs on your computer, executing it’s own set of instructions. When you run two programs on your computer, you actually create two processes. Each of them has a set of instructions(open your browser or increase the volume) that it wants to have read by the scheduler (the referee that decides what to feed to the processor). The particularity of threads versus processes is that they can share variables.
首先是有关线程的小提醒。 什么是线程? 这是在您的计算机上运行的轻量级进程,执行它自己的一组指令。 当您在计算机上运行两个程序时,实际上创建了两个进程。 他们每个人都有一组希望调度器(决定将什么内容馈送到处理器的裁判)阅读的指令(打开浏览器或提高音量)。 线程与进程的特殊之处在于它们可以共享变量。
For us in terms of coding, when we run two threads, we allow two pieces of code to run at the same time. However it is different than just executing two programs at the same time since threads give us more control. For example we can share some variables between threads or we can wait for the threads to finish, merge the results and go on with the rest of the code. It is a very powerful tool that can allow faster computation or the ability to handle concurrent events (think of robots with multiple sensor data to process).
对于我们来说,在编码方面,当我们运行两个线程时,我们允许两个代码同时运行。 但是,这与仅同时执行两个程序不同,因为线程为我们提供了更多控制权。 例如,我们可以在线程之间共享一些变量,也可以等待线程完成,合并结果,然后继续其余的代码。 它是一个非常强大的工具,可以允许更快的计算或处理并发事件的能力(想想要处理具有多个传感器数据的机器人)。
Let’s digress a bit and analyze the different possibilities Python offers to run computation in parallel. The three laureates are: Threads, Thread Pools, and Multi-Processing.
让我们讨论一下Python并行运行计算所提供的各种可能性。 这三个获奖者是: 线程 , 线程池和多进程 。
For clarity, let’s first introduce the function that we wish to parallelize. The sleep function, whose purpose is to… sleep.
为了清楚起见,让我们首先介绍我们希望并行化的功能。 睡眠功能,其目的是…睡眠。
def sleep(thread_index, agent):
print("Start sleeping for thread: %i", thread_index)
time.sleep(2)
print("Woke up for thread: %i", thread_index)
return "success"Threading: the most basic tool Python can offer to thread
线程 :Python可以提供的最基本的工具
import threading
threads = []
for i in range(num_threads):
thread = threading.Thread(target=sleep, args=(i,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()The Python library let us create Threads manually, for which we can specify the target (the function we wish to execute in this thread) and its arguments. The interface also includes a start function as well as a join function, which will wait until the execution of the thread is over. Joining threads is often desirable when we want to exploit the results returned by the thread. But the basic threading.Thread is quite limited in the sense that it does not let us access the variables returned by the sleep function.
Python库允许我们手动创建线程,我们可以为其指定目标(我们希望在该线程中执行的功能)及其参数。 该接口还包括一个启动函数和一个连接函数,它将等待直到线程执行结束。 当我们想利用线程返回的结果时,通常需要加入线程。 但是基本的threading.Thread在一定程度上是受限制的,因为它不允许我们访问sleep函数返回的变量。
2. Thread Pools: (and it’s library concurrent.futures)
2. 线程池:(和库并发。未来)
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = list()
for i in range(num_threads):
futures.append(executor.submit(sleep, i))
for future in futures:
return_value = future.result()
print(return_value)The thread pool executor provides a more complete set of interfaces for threading. However it’s underlying implementation still uses the Threading library, which gives the same advantages and drawbacks as the previous option. In terms of interface differences, it proposes the concept of future, which will seem familiar to users of C++ 14. The biggest advantage of the futures for us here is that it allows to get the variable returned by the function we are threading using the result() interface.
线程池执行程序提供了一套更完整的线程接口。 但是,它的基础实现仍使用Threading库,该库具有与以前的选项相同的优缺点。 在接口差异方面,它提出了Future的概念,这对于C ++ 14的用户来说似乎是熟悉的。在这里,futures的最大优点是它允许使用结果通过我们正在执行线程处理的函数返回的变量()界面。
3. Multi-processing (from the library multiprocessing)
3. 多重处理 (来自库多重处理)
import multiprocessing as mp
pool = mp.Pool()
if(mp.cpu_count() < num_threads):
print("Warning, trying to create more threads than available cores")
for i in range(num_threads):
pool.apply_async(sleep, args = (i, ), callback = callback)
pool.close()
pool.join()Multiprocessing is the most complete library that can provide threading capabilities. The main difference with the two others else than providing more interfaces, is its ability to serialize and de-serialize data using a third-party library called pickle. Serialization is the ability to transform data types (int, array etc.) into binaries, sequences of 0 and 1. To do so is required to be able to send data using protocols (tcp/ip, http, udp…) since these protocols are agnostic to the data types we use: the sender might be running his code in Python while the receiver might use C++. In the case of multi-processing, the serialization happens when we pass the function as well as the arguments to the pool object. This allows us to do something incredible: send this thread to be executed on.. another computer! As a matter of such, the multiprocessing library is aimed at enabling shared computation across multiple computers.
多重处理是可以提供线程功能的最完整的库。 除了提供更多接口之外,这两个其他程序的主要区别在于,它可以使用称为pickle的第三方库对数据进行序列化和反序列化。 序列化是将数据类型(整数,数组等)转换为二进制,0和1序列的能力。这样做必须能够使用协议(tcp / ip,http,udp…)发送数据,因为这些协议与我们使用的数据类型无关:发送者可能在Python中运行其代码,而接收者可能使用C ++。 在多处理的情况下,当我们将函数以及参数传递给池对象时,会发生序列化。 这使我们可以做一些不可思议的事情:将线程发送到另一台计算机上执行! 因此,多处理库旨在实现多台计算机之间的共享计算。
To note, the multi-processing library provides the apply (sync) and apply_async interfaces, standing for synchronous and asynchronous. In the first case, the threads are forced to return in the same order as they were launched while in the second case the threads come back as soon as they are over. The apply_async provides an additional argument “callback” that gives the possibility to execute a function when the thread returns (to store the result for example).
注意,多处理库提供了apply(sync)和apply_async接口,分别代表同步和异步。 在第一种情况下,线程被迫以与启动时相同的顺序返回,而在第二种情况下,线程一结束便返回。 apply_async提供了一个附加参数“回调”,使线程返回时可以执行一个函数(例如,存储结果)。
Now it’s time to compare the results of the different threading approaches. We first use the “sleep” function previously mentioned to benchmark the results:
现在是时候比较不同线程方法的结果了。 我们首先使用前面提到的“睡眠”功能对结果进行基准测试:

We also compute the sleep function sequentially to provide a base result for comparison. Sleeping for 2s each time, we get a total computation time for the sequential approach which seems logical. We get a computation time of 2s for the threading and multiprocessing approaches which means all the thread could run in parallel successfully, but we obtain 4s for the thread pool executor, showing that there is some additional computation cost time in that process. Now this is very nice with only 3 threads running in parallel, but we might want to run more than a thousand threads. Let’s see how it goes with a higher level of difficulty, say 100 threads:
我们还按顺序计算睡眠功能,以提供比较的基本结果。 每次睡眠2秒钟,就可以得出顺序方法的总计算时间,这似乎很合理。 对于线程和多处理方法,我们获得2s的计算时间,这意味着所有线程都可以成功并行运行,但是对于线程池执行器,我们获得4s的计算时间,这表明该过程中还有一些额外的计算成本时间。 现在这非常好,只有3个线程并行运行,但是我们可能要运行1000个以上的线程。 让我们看看如何以更高的难度(例如100个线程)进行处理:

As for threading and thread pooling, the results didn’t change from 3 to 100 threads. For the multi-processing approach however, the computation time jumped to 50s! To understand what is happening, let’s look look at the warning that we so thoughtfully placed: “Warning, trying to create more threads than available cores”. As such, multiprocessing will try to dispatch the threads to the available cores (4 in my case) but if no core is available, we can guess that the computation of the threads are queued and thus becoming sequential.
至于线程和线程池,结果没有从3个线程更改为100个线程。 但是对于多处理方法,计算时间跃升到50s! 为了了解正在发生的事情,让我们看一下我们经过深思熟虑后提出的警告:“警告,尝试创建比可用内核更多的线程”。 这样,多处理将尝试将线程分派到可用的内核(在我的例子中为4),但是如果没有可用的内核,我们可以猜测线程的计算已排队并且因此成为顺序的。
We could close off the topic and end up with, multi-processing is terrible, threading library is great. But wait a minute. Up until now, what we did in that threaded function was just sleeping, which means in terms of processing instructions: do nothing. Now, what if we have a thread which is much more greedy on computing resources. Let’s take the example of the counting function:
我们可以结束这个话题,最后,多处理很糟糕,线程库很棒。 等一下 到目前为止,我们在该线程函数中所做的只是睡眠,这意味着在处理指令方面:什么都不做。 现在,如果我们拥有一个对计算资源更加贪婪的线程该怎么办。 让我们以计数功能为例:
def count(thread_index):
print("Start counting for thread: %i", thread_index)
count = 0
for i in range(int(10e6)):
count += 1
print("Finished counting for thread: %i", thread_index)
return "success"We use 4 threads (number of cores I have on my personal computer) and can see the following results:
我们使用4个线程(我在个人计算机上拥有的内核数),可以看到以下结果:

Here the multi-processing approach is at least 4 times faster the other two. But more importantly, threading takes almost as much time as the sequential approach while the thread pooling approach takes twice as much time, when the initial goal is to optimize the computation time!
在这里,多处理方法至少是其他两种方法的4倍。 但是更重要的是,当最初的目标是优化计算时间时,线程占用的时间几乎是顺序方法的时间,而线程池方法的时间是顺序方法的两倍。
To understand why this is happening, we need to take a look at the GIL (Global Interpreter Lock). Python is an interpreted language while C or C++ are compiled language. What compilation does is transforming the written code into a language understandable by the processor: binaries. So when the code is executed it is directly read by the scheduler and then the processor. In the case of interpreted languages however, upon launching the program, the code is still written in human readable, here python syntax. So as to be read by the processor, it has to be interpreted at run-time by the so-called Python interpreter. However, a problem arises when threading. The Python interpreter does not allow to interpret multiple threads at the same time and consequently has a lock, the GIL to enforce that. Let’s see a diagram to understand the situation better:
要了解为什么会发生这种情况,我们需要看一下GIL(全局解释器锁定)。 Python是一种解释语言,而C或C ++是编译语言。 编译所做的是将书面代码转换为处理器可以理解的语言:二进制。 因此,在执行代码时,它会直接由调度程序然后由处理器读取。 但是,对于解释型语言,在启动程序时,代码仍以人类可读的方式编写,此处为python语法。 为了由处理器读取,必须在运行时由所谓的Python解释器对其进行解释。 但是,线程化时会出现问题。 Python解释器不允许同时解释多个线程,因此有一个锁,即GIL来强制执行。 让我们看一下图以更好地了解情况:

In that case, the GIL acts as a bottleneck and nullify the advantages of threading. That explains quite well why the Threading and Pool Threading cases in the comparative analysis performed so poorly. Each of the threads is fighting to get access over the Python interpreter each time their respective count needs to be incremented and this a billion times, whereas when the threads are sleeping, the Python interpreter is only solicited once during the whole duration of the thread existence. If that’s so, why is the multiprocessing approach providing significantly better results? The library is actually tricking the GIL by creating one instance of the Python interpreter for each thread:
在这种情况下,GIL会成为瓶颈,并使线程的优势无效。 这就很好地解释了为什么在比较分析中的“线程”和“池线程”案例的表现如此差劲。 每次需要增加各自的计数(十亿次)时,每个线程都在努力获取对Python解释器的访问权,而当线程处于睡眠状态时,在整个线程存在的整个过程中,只请求Python解释器一次。 如果是这样,为什么多处理方法可以提供明显更好的结果? 该库实际上是通过为每个线程创建一个Python解释器实例来欺骗GIL的:
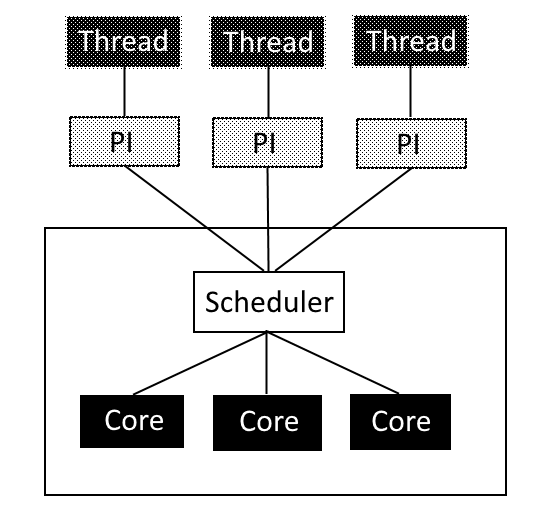
Thus the bottleneck disappears and the full threading potential can be unlocked.
因此,瓶颈消失了,可以释放全部穿线潜力。
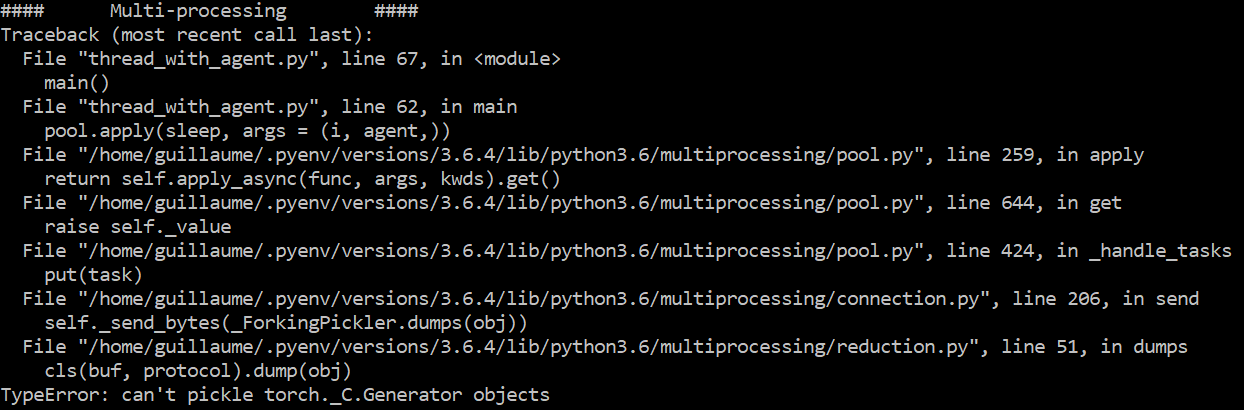
It is worth mentioning that multi-processing still has some down-sides due to the serialization process: not everything can be serialized. Especially, python generators or anything that has a pointer like behavior can’t be serialized (which seems rather normal). Let’s say we have and “agent” object with some unknown content (for example here some pytorch objects), we then end up with an error:
值得一提的是,由于序列化过程,多处理仍有一些缺点:并非所有内容都可以序列化。 特别是python 生成器 否则任何具有类似行为的指针的对象都无法序列化(这看起来很正常)。 假设我们有一个带有未知内容的“ agent”对象(例如,这里有一些pytorch对象),那么我们最终会出错:
We could interpret the differences between Threading and Multiproccessing in terms of computation efficiency. In this second part, we can take a closer look at the main difference as for how resources and variables are managed, especially for shared resources. Let’s consider the code below which makes the threads use a global variable:
我们可以从计算效率上解释线程化和多处理之间的差异。 在第二部分中,我们将仔细研究资源和变量(尤其是共享资源)的主要区别。 让我们考虑下面的代码,这些代码使线程使用全局变量:
print("Should only see this once")
#Defining a global variable
global_variable = 1
def count(thread_index):
count = 0
for i in range(int(10e6)):
count += global_variable
return "success"
def main(num_threads = 4):
start_mp = time.time()
pool = mp.Pool()
for i in range(num_threads):
print(pool.apply(count, args = (i, )))
pool.close()
pool.join()
print("Time needed for fork start method: %f", time.time() - start_mp)
if __name__ == '__main__':
mp.set_start_method("fork")
print("Should only see this once, for real")
main()This code runs totally fine even though we dispatched pieces of code to be evaluated by different processors (the child processes) accessing the same global variable. It means that all the python interpreters were able to access this global variable. So can the python interpreters communicate between each other at runtime? What is the sorcery behind this? Let’s consider a variation of the code below:
即使我们分派了要由访问同一全局变量的不同处理器(子进程)评估的代码段,该代码也可以正常运行。 这意味着所有python解释器都能够访问此全局变量。 那么python解释器可以在运行时相互通信吗? 这背后的法术是什么? 让我们考虑以下代码的变体:
global_variable = 1
def count(thread_index):
count = 0
global global_variable
time.sleep(thread_index)
print("global_variable has value: ", global_variable)
for i in range(int(10e4)):
global_variable +=1
count += global_variable
return countThe purpose of this code is to intentionally change the value of the global variable during runtime from different threads. Not only this, but they are also doing it with different timings (observe the sleep with different inputs).
该代码的目的是在运行时从不同线程有意更改全局变量的值。 不仅如此,而且他们还在不同的时间执行此操作(使用不同的输入观察睡眠)。

If this variable was really global, when the second thread outputs the value of the global variable, it should already have been incremented quite a bit. However, we see that this value consistently has the value 1 when the thread is printing it. So now we have a better idea of what is happening. When the thread is created (and with it the python interpreter), all the variables are copied to the new thread, no exception made with global variables. In a sense, all the threads are identical copies of the larger process that you are running with slightly different arguments passed to the thread. Now multiprocessing offers different options related to how are the child processes created. We can choose between three start methods, namely spawn, fork and forkserver. We will analyze the first two ones. According to the Python documentation:
如果此变量确实是全局变量,那么当第二个线程输出全局变量的值时,它应该已经增加了很多。 但是,我们看到线程打印它时,该值始终为1。 因此,现在我们对正在发生的事情有了更好的了解。 创建线程(以及带有python解释器的线程)后,所有变量都将被复制到新线程中,全局变量也不例外。 从某种意义上说,所有线程都是正在运行的较大进程的相同副本,并且传递给该线程的参数略有不同。 现在,多处理提供了有关如何创建子进程的不同选项。 我们可以在三种启动方法之间进行选择,即spawn,fork和forkserver。 我们将分析前两个。 根据Python文档:

So the main difference lies in what variables are inherited from the parent process upon creating a child process. Consider the code that was introduced above. If you observed carefully, you could notice that the start method was specified as “fork”. Let’s see what this code actually outputted:
因此,主要区别在于创建子流程时从父流程继承了哪些变量。 考虑上面介绍的代码。 如果仔细观察,您可能会注意到启动方法已指定为“ fork”。 让我们看看这段代码实际输出的内容:

Nothing special to see here, we know that the child process was able to access the global variable since it has copied it. Now let’s see what happens when we switch to “spawn”:
没什么特别的,我们知道子进程能够复制它,因此能够访问全局变量。 现在让我们看看切换到“生成”时会发生什么:

I can see the surprised expression in your eyes, no, you are not dreaming, you are seeing this multiple times. The “print(“Should only see this once”)” was made at the very beginning of the program and totally out of the loop where the threads are dispatched. Yet this was printed 4 times. So what is happening? The Python documentation only tells us that “The parent process starts a fresh python interpreter process” and that it only inherits the objects necessary for the run() method (understand the function that you are trying to thread). What you need to understand from this is inherited = copied, and not_inherited = re-evaluated. So when we are choosing “spawn”, every instruction of the process is re-interpreted, the function calls as well as variables memory allocation. Now you can notice the “if __name__ == ‘__main__’:” statement. What this does is signifying to the interpreter that whatever is inside is belonging to the main, and should therefore be inherited by the child process. Everything not in that statement will be re-evaluated for each child process. It means that by default “spawn” is trying to re-evaluate everything, but we do have control over what gets inherited, while for “fork”, every variable gets inherited by default. You could wonder why would this matters, in the case of our global variable it doesn’t change much. But for some objects, the copy constructor (when you are using the = operator) might not be well defined, which makes it unsafe to use the fork method in some occasions. For that reason, it can be seen in the python documentation that the spawn method is moving to be the default start method over all platforms.
我可以在您的眼睛中看到惊讶的表情,不,您不是在做梦,您已经多次看到了。 “ print(“应该只能看到一次”)是在程序的开始进行的,完全不在分配线程的循环之内。 但这被印刷了四次。 那么发生了什么事? Python文档仅告诉我们“父进程启动了一个全新的python解释器进程”,并且它仅继承了run()方法所需的对象(理解您要尝试使用的函数)。 您需要了解的是继承=复制 ,而不是not_inherited =重新评估 。 因此,当我们选择“生成”时,将重新解释过程的每条指令,函数调用以及变量的内存分配。 现在您可以注意到“ if __name__ =='__main__':”语句。 这对解释器意味着内部的任何内容都属于主体,因此应由子进程继承。 该语句中未包含的所有内容将针对每个子进程进行重新评估。 这意味着默认情况下,“ spawn”会尝试重新评估所有内容,但是我们确实可以控制继承的内容,而对于“ fork”,每个变量默认都将继承。 您可能想知道为什么这很重要,就我们的全局变量而言,它变化不大。 但是对于某些对象,复制构造函数(使用=运算符时)可能定义不正确,这使得在某些情况下使用fork方法并不安全。 因此,在python文档中可以看到spawn方法正在成为所有平台上的默认启动方法。
You might be wondering that this is a rather heavy limitation, if the threads created by multiprocessing are totally closed off, we lose the ability to have a degree of synchronization between the threads. This is not entirely true as the library put at our disposal some tools to do exactly that: Pipes.
您可能想知道这是一个很大的限制,如果完全关闭了由多处理创建的线程,我们将失去在线程之间具有一定程度的同步的能力。 这不是完全正确的,因为库为我们提供了一些工具来实现此目的:管道。
from multiprocessing import Process, Pipe
import time
def sleep(listener):
listener.recv()
time.sleep(1)
listener.close()
if __name__ == '__main__':
publisher, listener = Pipe()
p = Process(target=sleep, args=(listener,))
start_mp = time.time()
p.start()
time.sleep(1)
publisher.send("you can now sleep again")
p.join()
print("Total time: %f", time.time() - start_mp)Result: “Slept for: 2.00”, which means the thread actually waited to receive the data provided by the parent process before moving on. In a way, pipes are an equivalent of C++ futures where we are able to wait for the acquisition of some data provided by a different thread. But of course in this case, since the multiprocessing can be happening on different computers, the data sent through the pipes also need to be serialized under the hood.
结果: “为:睡眠:2.00”,这意味着线程在继续之前实际上等待接收父进程提供的数据。 在某种程度上,管道等效于C ++期货,在这里我们可以等待获取不同线程提供的某些数据。 但是,当然在这种情况下,由于可以在不同的计算机上进行多处理,因此通过管道发送的数据也需要在后台进行序列化。
We spoke about resources management for multiprocessing. For the threading library (and thread-pool executors), things are a bit different since we only have one python interpreter. Let’s see an example:
我们谈到了用于多处理的资源管理。 对于线程库(和线程池执行器),情况有所不同,因为我们只有一个python解释器。 让我们来看一个例子:
global_variable = 0
def count(thread_index):
time.sleep(thread_index)
global global_variable
print("Value of the global variable at: ", global_variable)
for i in range(int(10e5)):
global_variable += 1
return "success"We launch 4 threads at the same time, with a small different delay for each of them to actually start counting.
我们同时启动4个线程,每个线程实际开始计数的延迟略有不同。
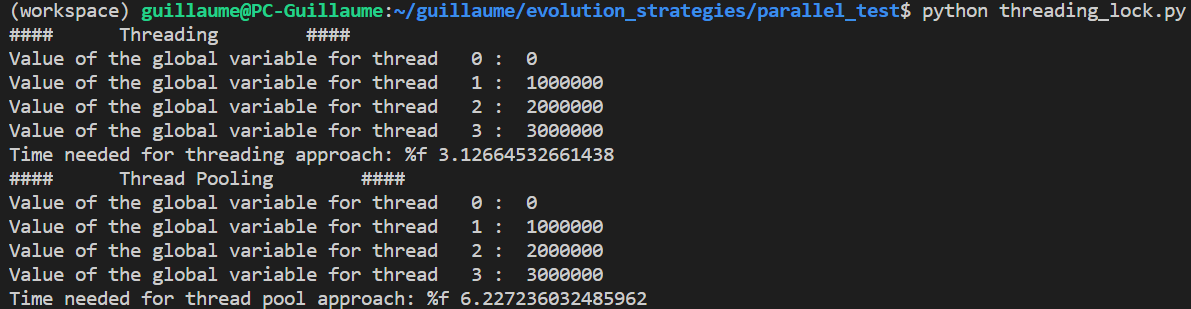
Contrary to multiprocessing, the global variable is here shared across the threads and do not hold a local copy. If you are used to manipulated threads, you would probably be horrified by the above code, shouting out terms as “race condition” or “locks”. A lock (which can be shared across threads), is a sort of gate keeper that only allows one thread to unlock the door of code execution at the same time, so as to prevent variables to be accessed or modified at the same time. Wait, we actually already heard that somewhere: The GIL (Global interpreter lock).
与多处理相反,全局变量在这里在线程之间共享,并且不保存本地副本。 如果您习惯于操纵线程,那么上面的代码可能会让您感到恐惧,并大喊“竞赛条件”或“锁”这样的术语。 锁(可以在线程之间共享)是一种看门人,它仅允许一个线程同时解锁代码执行的门,以防止变量被同时访问或修改。 等等,我们实际上已经在某处听说过:GIL(全局解释器锁)。
So python does already have a lock mechanism to prevent two threads to execute code at the same time. Great news, the above code might not be that horrible. Let’s prove it by printing the total count generated after the execution of the three threads (and removing the sleeps). Since the GIL protects us from thread executing instructions at the same time, no matter which thread is incrementing the global variable, we should add 10e5 * 4 times 1 so a total of 4.000.000.
因此python已经具有锁定机制,以防止两个线程同时执行代码。 好消息是,上面的代码可能并不那么可怕。 让我们通过打印三个线程执行后生成的总数(并删除Hibernate)来证明这一点。 由于GIL保护我们免受线程同时执行指令的影响,因此无论哪个线程在递增全局变量,我们都应将10e5 * 4乘以1,因此总计为4.000.000。

Ok, we need some explanation here. Especially how the GIL is actually working. The description “only let one thread run at the same time” might not be accurate enough to explain the situation. If we delve a bit more into the details, we can see this: “In order to support multi-threaded Python programs, the interpreter regularly releases and reacquires the lock — by default, every ten bytecode instructions”. So this is not the same as allowing only one line of actual python code being read at the same time. To fully understand this, we need to get down a level.
好的,我们在这里需要一些解释。 特别是GIL的实际工作方式。 描述“仅让一个线程同时运行”可能不够准确,无法解释这种情况。 如果我们进一步研究细节,我们可以看到:“ 为了支持多线程Python程序,解释器会定期释放并重新获取锁-默认情况下,每十个字节码指令 ”。 因此,这与只允许同时读取一行实际的python代码不同。 要完全理解这一点,我们需要下一个层次。
What happens when you execute a python program? The python interpreter will first compile the code (at runtime) into something more easily transformed into bytes (the food given to the processor unit). For python, this intermediate code is called bytecode. The full description of the bytecode operations can be found here. The dis module enables us to take a look at what the bytecode looks like for a specific function. If we try to have a glimpse over a function that adds 1 to a global variable:
当您执行python程序时会发生什么? python解释器将首先(在运行时)将代码编译为更容易转换为字节的内容(提供给处理器的食物)。 对于python,此中间代码称为字节码。 字节码操作的完整描述可以在这里找到。 dis模块使我们可以查看特定功能的字节码。 如果我们尝试瞥一向全局变量加1的函数:

To simply add one constant to a variable, we need 4 bytecode operations, fetching the variables, adding them together and storing the result.Now that we have a better understanding of what is a bytecode operation, we can notice that the GIL comes with settings that we can control: the sys.setcheckinterval() enables us to control every how many bytecodes we want to lock the GIL. But even though we set this to 1 (The GIL gets locked every bytecode instruction), this is not really going to help us. Let’s analyze what happens in the case where we have the GIL locking every 3 bytecodes:
为了简单地向一个变量添加一个常量,我们需要4个字节码操作,将变量取回,将它们加在一起并存储结果。我们可以控制的: sys.setcheckinterval()使我们能够控制要锁定GIL的每个字节码。 但是,即使我们将其设置为1(GIL在每个字节码指令中都被锁定),这也无济于事。 让我们分析一下在每3个字节码锁定GIL的情况下会发生什么:
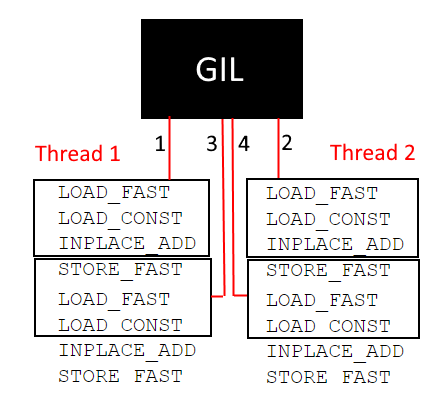
The numbers 1 to 4 represent the order in which the bytecode groups are allowed to be processed by the GIL. Now let’s imagine the global variable has initially a value of 0. In each thread, we are trying to add 1 to this variable. At the end of the execution of the bytecode group “1”, the copy of the variable that it got from LOAD_FAST got incremented (INPLACE_ADD) by 1. But the global variable itself was not modified yet as STORE_FAST was not executed. Now it’s the turn of the second thread: since the variable was not stored, it will still make a copy of the global variable with the value 0 and increments 1 to it. Now when the group 3 gets executed, the global_variable finally gets stored with the value 1. But as you can imagine, upon execution of group 4, the local copy also has the value 1 and the global variable will be store once again with a 1, while we would expect it to be 2. The bad news is, it doesn’t matter how frequently we lock the GIL, as long as the part of the “global_variable += 1” equivalent bytecodes get mixed up, we have a race condition.
数字1到4代表GIL允许处理字节码组的顺序。 现在,让我们想象一下全局变量的初始值为0。在每个线程中,我们都试图将1加到该变量上。 在字节码组“ 1”的执行结束时,它从LOAD_FAST获得的变量的副本(INPLACE_ADD)增加了1。但是由于未执行STORE_FAST,因此尚未修改全局变量本身。 现在轮到第二个线程了:由于未存储该变量,因此它仍将复制值为0的全局变量并将其递增1。 现在,当执行第3组时,最终将以值1存储global_variable。但是,您可以想象,在执行第4组时,本地副本也具有值1,并且全局变量将再次以1存储。 ,虽然我们希望它是2。坏消息是,只要锁定“ global_variable + = 1”等效字节码的一部分,我们就不必担心锁定GIL的频率如何,健康)状况。
So the GIL is not enough to protect our variables, and we have no choice than using locks to force it on the interpreter to only execute some block of code one at a time across threads:
因此,GIL不足以保护我们的变量,我们别无选择,只能使用锁在解释器上强制将其一次仅在线程中执行一些代码块:
global_variable = 0
lock = threading.Lock()
def count(thread_index):
global global_variable
for i in range(int(10e5)):
lock.acquire()
global_variable += 1
lock.release()
return "success"
That worked about right, the threads counted up to the correct number, while doing this job in parallel. However, if you look at the total computation time, this is over the roof. Acquiring and releasing the locks is indeed time consuming, and when we need to access the variables as often as we do here, it accumulates to form this very heavy computation time.
这样做正常,线程数达到正确的数量,同时并行执行此工作。 但是,如果您查看总的计算时间,那将是多余的。 获取和释放锁确实很耗时,并且当我们需要像在这里一样频繁地访问变量时,它会累积起来,从而形成非常繁重的计算时间。
Now it’s time to sum up our experience with parallel computation in Python:
现在是时候总结一下我们在Python中进行并行计算的经验了:
- We have two main libraries allowing us to do parallel computation: Threading and Multiprocessing. 我们有两个主要的库允许我们执行并行计算:线程和多处理。
- The Global Intepreter Lock (GIL) restricts python programs in terms of parallel computation efficiency, but Multiprocessing goes around it by creating multiple interpreters. 全局解释器锁(GIL)在并行计算效率方面限制了python程序,但是Multiprocessing通过创建多个解释器来解决它。
- Multiprocessing can make full usage of the multiple cores architecture, and even parallelize the computation over different computers by serializing/de-serializing the data necessary by each thread. However, it does create a copy or re-evaluate the resources of the environment. Each thread evolves in it’s confined environment and cannot exchange with the other threads unless using specific tools. 多处理可以充分利用多核体系结构,甚至可以通过序列化/反序列化每个线程所需的数据来并行化不同计算机上的计算。 但是,它确实会创建副本或重新评估环境资源。 每个线程都在其受限的环境中发展,除非使用特定工具,否则无法与其他线程交换。
- The threading library makes the child processes able to access and modify the same variables, however the GIL does not prevent race conditions and we have to use lock to prevent this from happening. 线程库使子进程能够访问和修改相同的变量,但是GIL不能阻止竞争条件,因此我们必须使用锁来防止这种情况的发生。
So when to use multiprocessing and when to use Threading? We can analyze two use cases of parallelization for applications.
那么什么时候使用多处理以及什么时候使用线程化呢? 我们可以分析应用程序并行化的两个用例。
Computation efficiency: the goal is to save computation time. In this case, we want to make full usage of the multi-core architecture, and not be bothered by the GIL. Choice: Multiprocessing.
计算效率:目标是节省计算时间。 在这种情况下,我们希望充分利用多核体系结构,而不会被GIL所困扰。 选择: 多处理。
I/O communication: when you might receive data from a number of sources, and wish to have the ability to monitor different data source input at the same time. In this case, you might want all the threads to have the same environment since they might want to modify the same variables, and you might not focus on computation efficiency. You also might want much more many threads than the number of available cores. Choice: Threading.
I / O通信:当您可能从多个源接收数据并且希望能够同时监视不同的数据源输入时。 在这种情况下,您可能希望所有线程都具有相同的环境,因为它们可能想要修改相同的变量,并且您可能不会关注计算效率。 您可能还需要比可用核心数更多的线程。 选择: 线程化 。
翻译自: https://towardsdatascience.com/unraveling-pythons-threading-mysteries-e79e001ab4c
android 揭示动画















 197
197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









