





 本文翻译自《Monitoring Your Machine Learning Model》,主要探讨了如何监控机器学习模型的状态,确保其在实际应用中保持良好的性能和准确性。监控对于及时发现模型退化、数据漂移等问题至关重要,以保证机器学习系统的稳定性和可靠性。
本文翻译自《Monitoring Your Machine Learning Model》,主要探讨了如何监控机器学习模型的状态,确保其在实际应用中保持良好的性能和准确性。监控对于及时发现模型退化、数据漂移等问题至关重要,以保证机器学习系统的稳定性和可靠性。
模型状态 监控机器学习
多播 (MLOps)
Over the last few years, Machine Learning and Artificial Intelligence have become more and more a staple in organizations that leverage their data. With that maturity came new challenges to overcome such as deploying and monitoring Machine Learning models.
在过去的几年中,机器学习和人工智能已越来越成为利用其数据的组织中的主要内容。 随着成熟,随之而来的是要克服的新挑战,例如部署和监视机器学习模型。
Although deploying and monitoring software has been a well-tested practice, doing so for Machine Learning models has turned out to differ significantly. Monitoring your model can help you understand how accurate your predictions are over time.
尽管部署和监视软件已经过了良好的测试,但是事实证明,对于机器学习模型而言,部署和监视软件存在很大差异。 监视模型可以帮助您了解预测的准确性。
Prevent erroneous predictions by monitoring your model
通过监视模型来防止错误的预测
From personal experience, it seems that there are many organizations, mostly SME’s, that are now facing the challenges with this production stage of Machine Learning.
从个人经验来看,似乎有许多组织(主要是中小型企业)正在面对机器学习这一生产阶段的挑战。
This article will focus on monitoring your Machine Learning model in production. However, if you are not familiar with deploying your model, I would advise you to look at the following article to get you up to speed:
本文将重点关注在生产中监视您的机器学习模型。 但是,如果您不熟悉模型的部署 ,建议您阅读以下文章以使您快速入门:
NOTE: There is no one right way to monitor your model. This article merely serves as food for thought when designing your monitoring framework. Your miles may vary depending on the solution you’re working on.
注意:没有正确的方法来监视模型。 本文仅是设计监视框架时的思考参考。 您的里程可能会根据您正在使用的解决方案而有所不同。
1.为什么要监视您的模型? (1. Why monitor your Model?)
All production software is prone to failure and every software company knows that it is important to monitor its performance to prevent problems. Typically, we monitor the quality of the software itself whereas, in the context of Machine Learning, one might focus more on monitoring the quality of predictions.
所有生产软件都容易出现故障,每个软件公司都知道监视其性能以防止出现问题很重要。 通常,我们监控 软件本身的质量,而在机器学习的背景下,我们可能会更多地关注监控 预测 的质量 。
N
ñ
There are several reasons why you would want to monitor your model:
为什么要监视模型有以下几个原因:
- The relationship between your model and the input data changes 您的模型与输入数据之间的关系发生了变化
- The distribution of your data changes such that your model is less representative 数据的分布会发生变化,从而使模型的代表性降低
- Change in measurements and/or user base which changes the underlying meaning of variables 测量值和/或用户群的变化会改变变量的基本含义
漂移 (Drift)
At the base of the above reasons, you can typically find the cause in drift. In its essence, drift is the phenomenon of changes in the statistical properties of your data that causes your predictions to degrade over time. In other words, since data is always changing, drift occurs naturally.
基于上述原因,通常可以在漂移中找到原因。 从本质上讲, 漂移是数据统计属性变化的现象,导致您的预测随着时间推移而下降。 换句话说,由于数据始终在变化,因此自然会发生漂移。

Take, for example, data from customers on an online store. A predictive model may use features such as their personal information, buying behavior, and money spent on advertisements. Over time, these features may not represent the features as they were originally trained on.
以在线商店中客户的数据为例。 预测模型可以使用诸如其个人信息,购买行为以及在广告上花费的钱之类的特征。 随着时间的流逝,这些功能可能不再代表最初训练时的功能。
Drift is often referred to as concept drift, model drift, or data drift
漂移通常称为概念漂移,模型漂移或数据漂移
It is important to monitor your model to make sure that the data input is similar to that used when training.
监视模型以确保数据输入与训练时使用的数据相似非常重要。
为什么不只是重新训练您的模型? (Why not just retrain your model?)
Although retraining a model sounds like it is always a good idea, it might be a bit more nuanced than that!
尽管重新训练模型听起来总是一个好主意,但可能比这更加细微!
What if you do not have timely labels? If your prediction is weeks in the future, it will be difficult to validate your model in practice as you need to wait weeks for the ground truth.
如果没有及时标签怎么办? 如果您的预测是未来数周,那么在实践中将很难验证模型,因为您需要等待数周才能获得基本事实。
Or… what if you automatically retrain your model only to have it running for 10 hours before retraining it the next day? This could cost the organization significant computing time while having a marginally positive effect.
或者...如果您自动重新训练模型,使其仅运行10个小时,然后在第二天进行训练,该怎么办? 这可能会花费组织大量的计算时间,同时又会产生轻微的积极影响。
Or… what if you retrain a model in an online fashion only to have its performance degrade due to the focus on only newly added data?
或者…如果您以在线方式重新训练模型而又由于仅关注新添加的数据而导致其性能下降,该怎么办?
Blindly retraining a model could lead to more costs, time waisted, or even a worse model. By monitoring your model you can be more precise in deciding the best method and time for retraining.
盲目地重新训练模型可能导致更多的成本,更多的时间甚至更糟糕的模型。 通过监视模型,您可以更精确地确定最佳的重新训练方法和时间。
2.监控 (2. Monitoring)
There is a huge amount of variations in methods for monitoring your deployed models. In practice, it will mostly depend on your application, model type, performance measures, and data distribution. However, there are a few things that you see most often when monitoring your model.
监视已部署模型的方法有很多变化。 实际上,它主要取决于您的应用程序,模型类型,性能指标和数据分布。 但是,在监视模型时,您最常看到一些东西。
监控预测 (Monitor Predictions)
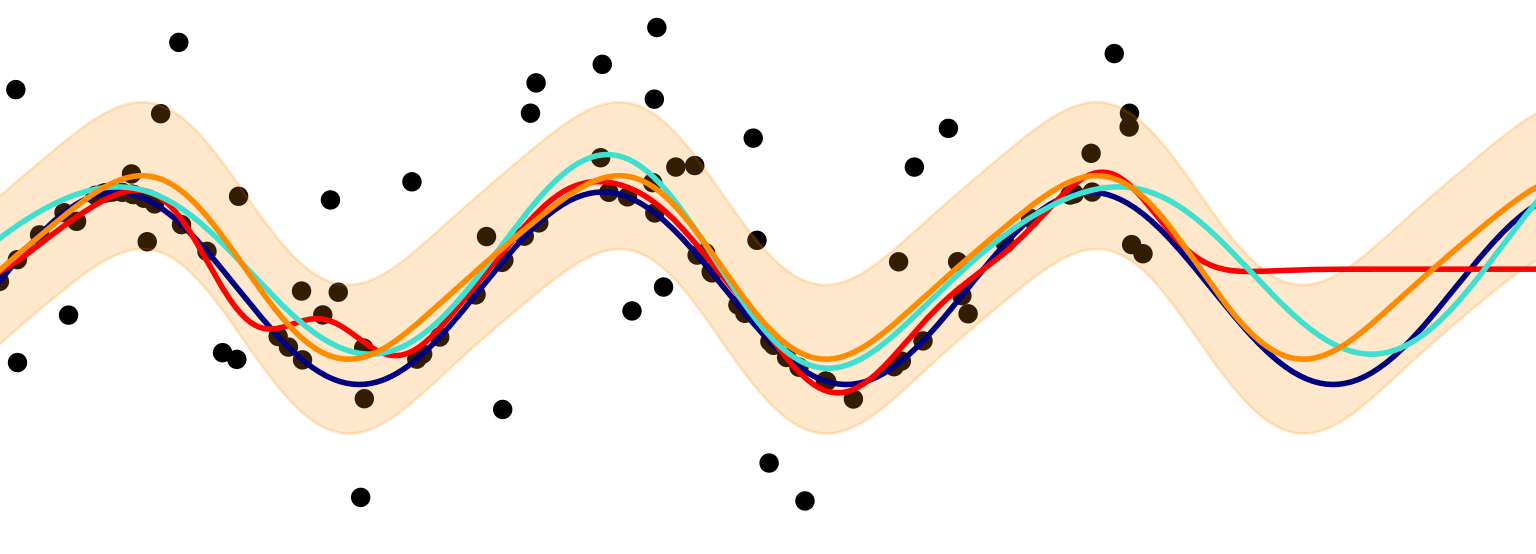
If you are lucky, there is little time between your prediction and what you aim to predict. In other words, after making a prediction, you will quickly have the true labels. In that case, it is a simple matter of monitoring standard performance measures such as accuracy, F1-score, and ROC AUC.
如果幸运的话,在您的预测与目标预测之间几乎没有时间。 换句话说,做出预测后,您将很快拥有真实的标签。 在这种情况下,只需监视标准性能指标即可,例如准确性,F1得分和ROC AUC。
However, when you do not have timely labels, performance measures cannot be used (e.g., disease prediction) and you would have to look at other methods:
但是,如果您没有及时的标签,则无法使用绩效指标(例如疾病预测),您将不得不考虑其他方法:
Distribution of predictions*
预测分布*
You can use the distribution and frequency of predictions in regression and classification tasks to track whether the new set of predictions has a similar distribution to the training data. A significant deviation might indicate degradation in performance.
您可以在回归和分类任务中使用预测的分布和频率来跟踪新的预测集是否与训练数据具有相似的分布。 明显的偏差可能表明性能下降。
Prediction probabilitiesMany machine learning models can output classification probabilities. These indicate how “certain” a model is that this is the correct prediction. If these probabilities are relatively low, then the model might be struggling in deployment.
预测概率许多机器学习模型都可以输出分类概率。 这些表明模型有多“确定”该正确预测。 如果这些概率相对较低,则该模型在部署中可能会遇到困难。
*NOTE: If you want to compare distributions, then we are typically looking at statistical tests such as the student’s t-test or the non-parametric Kolmogorov Smirnov. This might help you select the right statistical test for your data.
*注意 :如果您想比较分布,那么我们通常会考虑统计检验,例如学生的t检验或非参数Kolmogorov Smirnov 。 这可以帮助您为数据选择正确的统计检验。
监控输入 (Monitor Input)
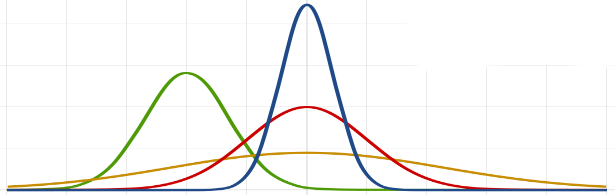
If you have timely labels or not, it is often good practice to also monitor the input of your model. This helps you understand what is typically fed to your model and can help you track the deterioration of your predictions.
如果没有及时的标签,通常最好同时监视模型的输入。 这可以帮助您了解通常向模型提供的内容,并可以帮助您跟踪预测的恶化情况。
Methods include:
方法包括:
Distribution of featuresAs with the predictions, you can use the distribution input data to track whether it has a similar distribution to the training data. If you find a significant difference, this might indicate that your training data is not representative of what you find in production.
特征的分布与预测一样,您可以使用分布输入数据来跟踪其是否与训练数据具有相似的分布。 如果发现明显差异,则可能表明您的培训数据不能代表您在生产中发现的内容。
Outlier detectionDepending on your preprocessing steps, you typically do not allow certain values to be used in your prediction model. The number of categories in a variable might increase over time which your model did not anticipate.
离群值检测根据您的预处理步骤,通常不允许在预测模型中使用某些值。 变量中类别的数量可能会随着时间的推移而增加,这是模型无法预期的。
人工监控 (Human Monitoring)

In the age of automation, why would I suggest manual human monitoring? Especially when human behavior is extremely sensitive to errors?
在自动化时代,为什么我建议手动进行人工监控? 特别是当人类行为对错误极为敏感时?
Well… although human monitoring should be a last resort, there are some cases where it would be beneficial to have a human take a look at the predictions a model generates. If a monitored prediction is way off even though it had a probability of over 90%, then it would be nice if these exceptions are looked over by a human.
好吧……虽然人工监视应该是最后的手段,但是在某些情况下,让人们看看模型生成的预测会很有益。 如果即使有超过90%的可能性,监视的预测仍遥遥无期,那么如果人类查看了这些异常,那就太好了。
Human monitoring might even be necessary when you do not have the ground truth labels of predictions in practice.
当您在实践中没有地面预测的真实标签时,甚至可能需要人工监视。
3.阴影模式 (3. Shadow mode)
Whenever you want to deploy a retrained model, you might want to hold off deploying it to production. Instead, deploying it in shadow mode might be preferred. Shadow mode is a technique where you run production data through a newly trained model without giving the predictions back to the user.
每当您要部署重新训练的模型时,您可能都希望推迟将其部署到生产中。 相反,可能更希望以影子模式部署它。 阴影模式是一种技术,您可以通过新训练的模型运行生产数据,而无需将预测反馈给用户。

Shadow mode allows you to simultaneously run both models while testing the performance of the newer model in a production environment. You can store its predictions to monitor its behavior before actually deploying to production.
影子模式允许您在生产环境中测试较新模型的性能的同时运行两个模型。 您可以存储其预测,以在实际部署到生产之前监视其行为。
Moreover, you can use this mode to check whether the model works as intended without the need to mimic a production environment as it is technically a copy of production.
此外,您可以使用此模式检查模型是否按预期工作,而无需模拟生产环境,因为从技术上讲,它是生产的副本。
感谢您的阅读! (Thank you for reading!)
If you are, like me, passionate about AI, Data Science, or Psychology, please feel free to add me on LinkedIn or follow me on Twitter.
如果您像我一样对AI,数据科学或心理学充满热情,请随时在LinkedIn上添加我或在Twitter上关注我。
Click one of the posts below for more information about machine learning in production:
单击下面的帖子之一,以获取有关生产中机器学习的更多信息:
翻译自: https://towardsdatascience.com/monitoring-your-machine-learning-model-6cf98c106e99
模型状态 监控机器学习















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









