





kotlin可变迭代器
Let's see the difference between them and use the benchmark library to compare their efficiency
让我们看看它们之间的区别,并使用基准库比较它们的效率
清单的用法 (Usage of lists)
In Android it is really hard to think about an application without a RecyclerView. There are so many usages in our apps, like lists of contacts, users, clients, products, etc. Lists are part of our everyday life as developers, and of course, as users too!
在Android中,如果没有RecyclerView,很难考虑一个应用程序。 我们的应用程序中有很多用途,例如联系人,用户,客户,产品等的列表。列表是我们作为开发人员,当然也包括用户的日常生活的一部分!
Kotlin中的列表使操作变得简单 (Lists in Kotlin made it easy)
Kotlin made to deal with Lists a really easy task.
Kotlin使得处理Lists变得非常容易。
Who already thought nowadays, while needed to make some changes in a Java class with some collection operations, the following phrase: "Humm, if this code was written in Kotlin I could simplify it so much".
如今,谁已经想到了,尽管需要通过一些集合操作对Java类进行一些更改,但使用以下短语: “嗯,如果这段代码是用Kotlin编写的,那么我可以做得这么简单”。
Well, so let's remember how we would do some operations with lists in Java, such as filtering and transformations.
好吧,让我们记住如何对Java中的列表进行一些操作,例如过滤和转换。
想象一个真实的案例 (Imagining a real case)
To do this, imagine a list of To-do items, and a method that is responsible for filtering this list and return just the items checked as done. After that, this method sorts the filtered list, using the item name and sorting alphabetically:
为此,请想象一个待办事项列表,以及负责过滤该列表并仅返回已完成检查的项目的方法。 之后,此方法使用项目名称并按字母顺序对排序的列表进行排序:
List<TodoItem> getDoneItemOrderedTitle() {
List<TodoItem> resultList = new ArrayList<>();
for(TodoItem todoItem: todoItemList) {
if(todoItem.getDone()) {
resultList.add(todoItem);
}
}
Collections.sort(resultList, new Comparator<TodoItem>() {
@Override
public int compare(TodoItem todoItem1, TodoItem todoItem2) {
return todoItem1.getName().compareTo(todoItem2.getName());
}
});
return resultList;
}As you can see, a lot of code is done there. 😰(emoji of cold sweat)
如您所见,在那里完成了很多代码。 😰 (冷汗的表情符号)
To remember the difference in dealing with lists between Java and Kotlin, the same function described above could be written just like this in Kotlin:
为了记住Java和Kotlin在处理列表方面的区别,可以在Kotlin中这样写上面描述的相同函数:
fun getDoneItemOrderedTitle(): List<TodoItem> =
todoItemList
.filter { it.done }
.sortedBy { it.name }So, the difference we can see is really huge! And as we need to do more operations, the difference becomes even bigger. Besides being smaller, the Kotlin function becomes much more readable and it is easier to understand what is done in each step (first filtering by done items and second sorting by name).
因此,我们可以看到的差异确实很大! 而且,由于我们需要执行更多操作,因此差异变得更大。 除了更小之外,Kotlin函数变得更具可读性,并且更容易理解每个步骤中完成的操作(首先按完成的项目进行过滤,然后按名称进行排序)。
但是在Kotlin中,我们可以使用Sequences或Iterables,它们之间有什么区别? (But in Kotlin, we can use Sequences or Iterables, what is the difference between them?)
First of all, let’s see how we can create a sequence in Kotlin:
首先,让我们看看如何在Kotlin中创建序列 :
sequenceOf(0, 1, 2, 3)And now, an iterable could be created, like this:
现在,可以创建一个可迭代的对象 ,如下所示:
listOf(0, 1, 2, 3)As we can see, they are very similar, but there are some differences between them when we are talking about the operations done with these kinds of collections and how they are executed.
可以看到,它们非常相似,但是当我们谈论使用这些类型的集合执行的操作以及如何执行它们时,它们之间存在一些差异。
For iterable, each operation is executed in the whole list, and also in every operation a new intermediate collection is returned, with the result got from the last operation.
对于iterable ,每个操作都在整个列表中 执行 ,并且在每个操作中都返回一个新的中间 集合 ,其结果是从上一个操作获得的。
On the other hand, sequences implement an approach called multi-step collection processing, while (when it is possible) the operation is actually executed just when the final result is returned. And, instead of executing each operation on the whole collection, it executes each operation in every single collection item.
另一方面,序列实现了一种称为多步收集处理的方法 ,而(可能的话)仅在返回最终结果时才实际执行操作 。 并且,代替在整个集合上执行每个操作 ,它在每个单个集合项中执行每个操作 。
Let's see what it means in a real example 🤔 (emoji thinking)
让我们看看一个真实示例example (表情符号思考)的含义
Imagine that we have a collection with numeric data, and a function responsible for doing the following collection operations:
想象一下,我们有一个包含数字数据的集合,以及一个负责执行以下集合操作的函数:
- Map it with the result of a multiplication 用乘法结果映射它
- Filter just the even items 仅过滤偶数项
- Take the first item 拿第一项
- Print the result 打印结果
The code with iterable and sequence are represented by functions getFirstFromList() and getFirstFromSequence() respectively, as we can see by the following code, they are very similar:
具有可迭代和顺序的代码分别由函数getFirstFromList()和getFirstFromSequence()表示 ,如下面的代码所示,它们非常相似:
fun getFirstFromList() {
LIST
.map { println("map $it"); it * 5 }
.filter { println("filter $it"); it % 2 == 0 }
.take(1)
.forEach { println("list $it") }
}
fun getFirstFromSequence() {
SEQUENCE
.map { println("map $it"); it * 5 }
.filter { println("filter $it"); it % 2 == 0 }
.take(1)
.forEach { println("sequence $it") }
}But, giving a list of 3 elements (0, 1, 2) if we compare these two blocks of code execution results, we can see the difference described above.
但是,如果我们比较这两个代码执行结果块,则给出3个元素(0、1、2)的列表,我们可以看到上述差异。
For the first method, where the operations run in an iterable instance, the results are:
对于第一种方法,其中操作在可迭代实例中运行,结果是:

As we can see the first (map) and the second (filter) operations are run on the whole collection, even it isn’t necessary, because we get just the first item at the end of the execution. This happens because all the operations are executed on the whole list in iterable and every step returns a new intermediate list.
正如我们看到的那样,第一个(映射)和第二个(过滤器)操作是在整个集合上运行的,即使没有必要,因为我们在执行结束时仅获得了第一项。 发生这种情况是因为所有操作都以可迭代的方式在整个列表上执行,并且每个步骤都返回一个新的中间列表。
While with sequence, we got a different print result:
使用sequence时 ,我们得到了不同的打印结果:

As it executes all the operations one item at a time, it is more efficient in this case, because it just runs on the first element, the one that matters to this function.
由于它一次执行一项所有操作,因此在这种情况下效率更高,因为它只在第一个元素上运行,而第一个元素对该功能至关重要 。
So, as this analysis result we can assume that sequences optimize operations execution, preventing unnecessary tasks being executed.
因此,作为该分析结果,我们可以假设序列优化了操作执行,从而防止了不必要的任务被执行。
将结果与Andoidx基准库进行比较 (Comparing the results with Andoidx Benchmark Library)
Benchmark library, allows us to compare code in Android apps, due to the execution of instrumented tests, then it gives us the results on Android Studio output.
基准库,由于执行了已测试的测试,可让我们比较Android应用中的代码,然后在Android Studio输出上为我们提供结果。
So, now we are going to compare the code mentioned above, with this tool. 🤓(emoji of nerd's face)
因此,现在我们将使用该工具比较上面提到的代码。 🤓 (书呆子的表情符号)
First, you can configure the module that you want to benchmark as the official documentation describes, or you can create a module with your benchmark tests only. The second option will be the one described here.
首先,您可以按照官方文档中的说明配置要进行基准测试的模块,也可以仅使用基准测试创建模块。 第二个选项将是此处描述的选项。
This option was chosen because this way we can isolate where benchmark tests go and all the configuration necessary to make it run, as the one in AndroidManifest file, where we have to configure the application as not debuggable:
选择此选项是因为,这样我们就可以隔离基准测试的运行位置和使其运行所需的所有配置,就像AndroidManifest文件中的那个配置一样,我们必须将应用程序配置为不可调试:
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
...
<application
android:debuggable="false"
android:requestLegacyExternalStorage="true"
tools:ignore="HardcodedDebugMode"
tools:replace="android:debuggable" />
</manifest>So, to start configuring your benchmark module, you can use the benchmarking module template in Android Studio, just select the option:
因此,要开始配置基准测试模块,可以使用Android Studio中的基准测试模块模板,只需选择以下选项:
File -> New -> New Module
文件->新建->新建模块
And then, select the benchmark template:
然后,选择基准模板:

Then, the benchmark code should be configured correctly, in this example, the benchmark module is called listsbenchmark.
然后,应该正确配置基准测试代码,在此示例中,基准测试模块称为listbenchmark 。
In our example, we would use the above code (functions getFirstFromList() and getFirstFromSequence()) in the benchmark, and it is in an Android library module called lists. So, we have to add it as a dependency in our build.gradle in listsbenchmark module.
在我们的示例中,我们将在基准测试中使用以上代码(函数getFirstFromList()和getFirstFromSequence() ),并且该代码位于一个名为list的Android库模块中 。 因此,我们必须将其作为依赖添加到listbenchmark模块的build.gradle中。
dependencies {
implementation fileTree(dir: "libs", include: ["*.jar"])
implementation project(':lists')
androidTestImplementation 'androidx.benchmark:benchmark-junit4:1.0.0'
...
}Now, let's implement the instrumented tests where the benchmark is really done, and we will be able to see if the results between the execution of operations in iterable and sequence we got above really affect the performance.
现在,让我们在真正完成基准测试的地方实施测试化的测试,然后我们将能够看到以迭代方式执行的操作与上面获得的顺序之间的结果是否真的影响了性能。
But, in our example above, we compare the results of small collections. Now, to check the performance, let's implement the tests with larger ones, with a thousand elements, declaring them in constants, in our test file:
但是,在上面的示例中,我们比较了小型馆藏的结果。 现在,要检查性能,让我们在测试文件中用带有一千个元素的较大的测试实现,并在常量中声明它们:
private val LARGE_LIST = (0..1000)
private val LARGE_SEQUENCE = LARGE_LIST.asSequence()Implementing benchmarks with Jetpack Library is really simple. You can use BenchmarkRule, which is a JUnit rule for benchmarking code on an Android device. On its class there are some useful methods that can be used to benchmark app code, in our example we will be using measureRepeated, to measure how much time each function spends to be executed. Our benchmark test class will be just like this:
使用Jetpack库实施基准测试非常简单。 您可以使用BenchmarkRule ,这是一个JUnit规则,用于在Android设备上对代码进行基准测试。 在其类上,有一些有用的方法可用于对应用程序代码进行基准测试,在我们的示例中,我们将使用measureRepeated来衡量每个函数花费多少时间来执行。 我们的基准测试类将如下所示:
@RunWith(AndroidJUnit4::class)
class CompareIterableSequenceBenchmarkTest {
@get:Rule
val benchmarkRule = BenchmarkRule()
@Test
fun benchmarkListOperations() = benchmarkRule.measureRepeated {
getFirstFromList(LARGE_LIST)
}
@Test
fun benchmarkSequenceOperations() = benchmarkRule.measureRepeated {
getFirstFromSequence(LARGE_SEQUENCE)
}
}Running benchmark tests can be done just like running any instrumented tests in Android Studio. On Android Studio 3.4 and higher, you can see output sent to the console.
就像在Android Studio中运行任何已测试的测试一样,可以运行基准测试。 在Android Studio 3.4及更高版本上,您可以看到发送到控制台的输出。
The output from the execution of these tests, comparing the same operations done in iterable and sequence is:
这些测试的执行结果(将可迭代和顺序 相同的操作进行比较)为:
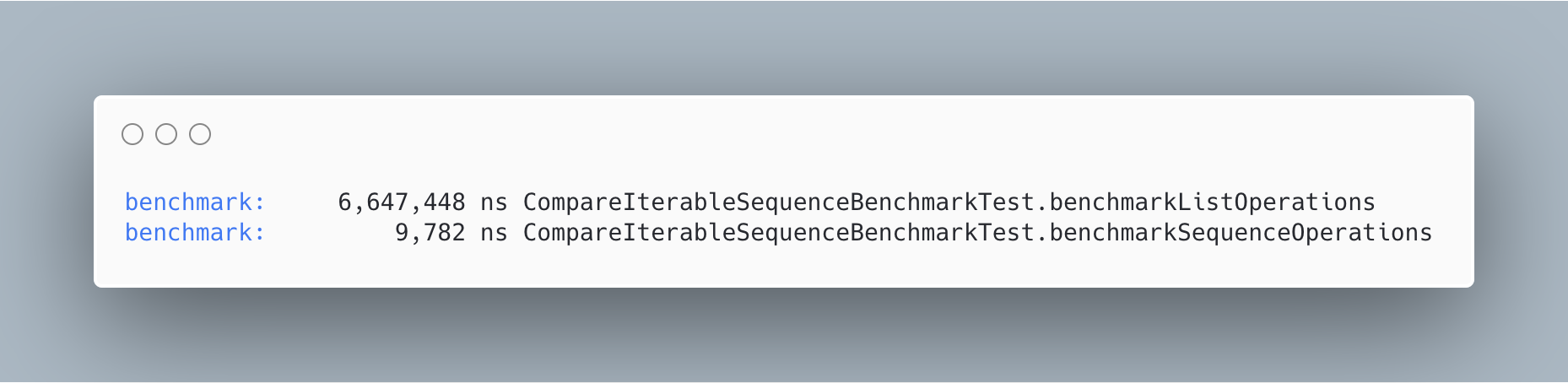
As we can see, the test that executed operations with list took 6,647,448 ns to be finished, while the one that did it with sequences, took 9,782 ns. So, we got a result of 600x faster with sequences.
如我们所见,使用list执行操作的测试花费了6,647,448 ns来完成,而使用序列执行的测试花费了9,782 ns 。 因此,序列得到的结果快了600倍。
Just for curiosity here is the result of execution with a small list, with three elements:
出于好奇,这里是一个带有三个 元素的小清单的执行结果:

For small lists, we can see that the sequence result is almost the same, because of the ordering and optimization done on this kind of collection operations execution. On the other hand, for lists the time is faster for the smaller entrance, once it depends directly on collection size.
对于小列表,我们可以看到序列结果几乎相同 ,这是因为对这种收集操作执行进行了排序和优化。 另一方面,对于列表来说, 较小的入口的时间更快 ,这直接取决于集合的大小。
结论 (Conclusions)
So, in this article we could see how these two types of collections differ from each other, in terms of ordering and performance. But, as the Kotlin official documentation says:
因此,在本文中,我们可以看到这两种类型的集合在排序和性能方面如何彼此不同。 但是,正如Kotlin官方文档所述 :
However, the lazy nature of sequences adds some overhead which may be significant when processing smaller collections or doing simpler computations. Hence, you should consider both
SequenceandIterableand decide which one is better for your case但是,序列的延迟性质增加了一些开销,这些开销在处理较小的集合或进行更简单的计算时可能很重要。 因此,您应该同时考虑
Sequence和Iterable并确定哪种情况更适合您的情况
So, each kind of collection can fit your implementation, it depends on your needs. And, once a question arrives with the doubt between using one or another… Of course you can measure it, using the Android Benchmark library or any tool that you like.
因此,每种类型的集合都可以适合您的实现,这取决于您的需求。 而且,一旦出现问题,便会怀疑是使用另一个还是另一个之间的问题……当然,您可以使用Android Benchmark库或您喜欢的任何工具来衡量它。
Happy coding! 😉 (winkling emoji)
祝您编码愉快! 😉 (眨眼表情符号)
翻译自: https://proandroiddev.com/sequences-x-iterable-in-kotlin-b5df65cad2d2
kotlin可变迭代器















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}