





As a matter of fact, the Paging Library as a part of Jetpack helps you load and display small amount of data at a time. Loading partial data on demand can be useful for diminishing usage of network bandwidth and system resources. This essay will discuss some concepts and steps in implementing Paging library for Android developers.
实际上,作为Jetpack的一部分的分页库可帮助您一次加载和显示少量数据。 按需加载部分数据对于减少网络带宽和系统资源的使用可能很有用。 本文将讨论为Android开发人员实现分页库的一些概念和步骤。
简介与概述 (Introduction and Overview)
Initially, most Android apps work with large sets of data; however, they just only require to load and display a small amounts of data at any given time. If you do not handle the process of loading data, you might request data that you do not actually need. This leads to waste your user’s battery and bandwidth. If the data you are displaying is constantly updating, it would be a difficult task to maintain your UI in sync and still send only a small amount of information over the network. The Paging Library as a part of Jetpack, addresses these issues appropriately. It enables you to load data gradually and gracefully. This library provides both large but bounded lists, as well as lists of unbounded sites like continuously-updating feeds. It offers integration with RecyclerView, which is typically used to display large data sets, and plays properly with either LiveData or RxJava for observing new data in your UI. In fact, the Paging library is based on the idea of sending lists to the UI with the LiveData of a list that is observed by the RecyclerView adapter. Then, it builds on this idea by adding Paging. Therefore, you can be able to load content
最初,大多数Android应用程序都可以处理大量数据。 但是,它们仅需要在任何给定时间加载并显示少量数据。 如果您不处理加载数据的过程,则可能会请求实际上不需要的数据。 这会浪费用户的电池和带宽。 如果要显示的数据不断更新,则要保持UI同步并通过网络仅发送少量信息将是一项艰巨的任务。 作为Jetpack一部分的分页库可以适当地解决这些问题。 它使您能够逐步且优雅地加载数据。 该库既提供大型但有边界的列表,也提供无边界站点的列表,例如不断更新的提要。 它提供了与RecyclerView的集成,后者通常用于显示大数据集,并且可以与LiveData或RxJava正常播放,以在UI中观察新数据。 实际上,分页库基于将列表与LiveCycle列表一起发送到UI的想法,该列表由RecyclerView适配器观察到。 然后,通过添加分页在此思想的基础上。 因此,您可以加载内容
The Paging Library helps you load and display small chunks of data at a time. Loading partial data on demand reduces usage of network bandwidth and system resources.gradually.
分页库可帮助您一次加载和显示小块数据。 按需加载部分数据会逐渐减少网络带宽和系统资源的使用。
分页库的主要组件 (Main components of Paging library)
The Paging library Includes some main core components as follows:
分页库包括一些主要的核心组件,如下所示:
PagedList
页面列表
Fundamentally, PagedList is a collection that loads data in pages, asynchronously. A PagedList can be used to load data from sources you define, and show it easily in your UI with a RecyclerView. The following code shows how you can configure your app’s ViewModel to load and present data using a LiveData holder of PagedList objects:
从根本上说, PagedLis t是一个集合,可异步加载页面中的数据。 PagedList可用于从您定义的源加载数据,并使用RecyclerView在UI中轻松显示它。 以下代码显示了如何配置应用程序的ViewModel以使用PagedList对象的LiveData持有者加载和呈现数据:
class ConcertViewModel(concertDao: ConcertDao) : ViewModel() {
val concertList: LiveData<PagedList<Concert>> =
concertDao.concertsByDate().toLiveData(pageSize = 40)
}PagedList — a collection that loads data in pages, asynchronously. A
PagedListcan be used to load data from sources you define, and present it easily in your UI with aRecyclerView.PagedList —一个异步加载页面中的数据的集合。
PagedList可用于从您定义的源中加载数据,并使用RecyclerView轻松将其呈现在UI中。
DataSource
数据源
In fact, a DataSource is the base class for loading snapshots of data into a given PagedList. A DataSource can be backed by the network, database, file, and anywhere that you want to retrieve data from it. You can be able to create the DataSource by using a DataSource. Factory object. The following example uses the Room persistence library to organize your app’s data:
实际上, DataSource是用于将数据快照加载到给定的PagedList中的基类。 数据源可以由网络,数据库,文件以及您要从中检索数据的任何位置支持。 您可以使用数据源来创建数据源。 工厂对象。 以下示例使用Room持久性库来组织应用程序的数据:
@Dao
interface ConcertDao {
@Query("SELECT * FROM concerts ORDER BY date DESC")
fun concertsByDate(): DataSource.Factory<Int, Concert>
}DataSource and DataSource.Factory — a
DataSourceis the base class for loading snapshots of data into aPagedList. ADataSource.Factoryis responsible for creating aDataSource.DataSource和DataSource.Factory —
DataSource是用于将数据快照加载到PagedList的基类。DataSource.Factory负责创建DataSource。
PagedListAdapter
PagedListAdapter
The Paging Library also provides a PagedListAdapter, which helps you represent your data from PagedList into a RecyclerView. The PagedListAdapter is notified when pages are loaded, and it uses DiffUtil to update new data that is received. For instance:
分页库还提供了PagedListAdapter ,它可以帮助您将PagedList中的数据表示到RecyclerView中。 加载页面时会通知PagedListAdapter ,它使用DiffUtil更新接收到的新数据。 例如:
class ReposAdapter : PagedListAdapter<Repo,
RecyclerView.ViewHolder>(REPO_COMPARATOR)class SearchRepositoriesActivity : AppCompatActivity() { viewModl.repos.observe(this, Observer<PagedList<Repo>> {
//updating adapter adapter.submitList(it)
})PagedListAdapter — a
RecyclerView.Adapterthat presents paged data fromPagedListsin aRecyclerView.PagedListAdapterlistens toPagedListloading callbacks as pages are loaded, and usesDiffUtilto compute fine-grained updates as newPagedListsare received.PagedListAdapter -一个
RecyclerView.Adapter呈现分页从数据PagedLists在RecyclerView。PagedListAdapter在页面加载时侦听PagedList加载回调,并在接收到新的PagedLists使用DiffUtil计算细粒度的更新。
LivePagedListBuider
LivePagedListBuider
The Paging library provides the LivePagedListBuider class for obtaining a LiveData object of type PagedList. To create a LivePagedListBuilder, you should pass the dataSourceFactory object and a Paging configuration. If you prefer working with RxJava instead of LiveData, you can use the RxPagedListBuilder. It is similar to LivePagedListBuilder, but instead of a LiveData object, it will return an observable or flowable. For example:
分页库提供LivePagedListBuider类,用于获取类型为PagedList的LiveData对象。 要创建LivePagedListBuilder ,您应该传递dataSourceFactory对象和Paging配置。 如果您更喜欢使用RxJava而不是LiveData,则可以使用RxPagedListBuilder 。 它与LivePagedListBuilder相似,但是它代替LiveData对象,而是返回一个可观察或可流动的对象。 例如:
val config = PagedList.Config.Builder()
.setPageSize(30)
.setInitialLoadSizeHint(5)
.setPrefetchDistance(10)
.setEnablePlaceholders(false)
.build()val data: LiveData<PagedList<Repo>> =
LivePagedListBuilder(
dataSourceFactory,
config
)
.build()LivePagedListBuilder — builds a
LiveData<PagedList>, based onDataSource.Factoryand aPagedList.Config.LivePagedListBuilder — 基于
DataSource.Factory和PagedList.Config构建一个LiveData<PagedList>。
加载数据的一些常见方案 (Some common scenarios of loading data)
The Paging Library Provides the following three common scenarios for loading data:
分页库提供以下三种常见的数据加载方案:
- Stored only in an on-device database. 仅存储在设备上的数据库中。
2. Served the database as a cache for data loaded from network
2.将数据库用作从网络加载的数据的缓存
3. Served only from a back-end server.
3.仅从后端服务器提供服务。
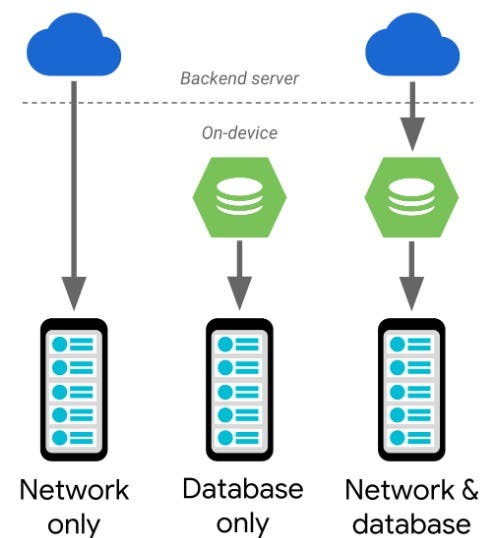
In the first case, the database is your data source. The Room persistence library provides native support for Paging Library data sources. For a given query, Room allows you to return a DataSource. Factory from the Dao, and manages the implementation of the DataSource for you. For example:
在第一种情况下,数据库是您的数据源。 Room 持久性 库为分页库数据源提供了本机支持。 对于给定的查询,Room允许您返回数据源。 来自Dao的Factory ,并为您管理DataSource的实现。 例如:
class ConcertViewModel(concertDao: ConcertDao) : ViewModel() {
val concertList: LiveData<PagedList<Concert>> =
concertDao.concertsByDate().toLiveData(pageSize = 40)
}In the second case, the database is a cache for data loaded from network. Thus, here you would still return a DataSource.Factory from the Dao, but you will also need to implement another Paging component, a BoundaryCallback. The BoundaryCallback loads more data when the user gets near the end of the data that is in the local cache. After the data is inserted, the Paging library automatically updates the UI. However, you must associate the BoundaryCallback with the LivePagedListBuilder you created earlier as follow:
在第二种情况下,数据库是从网络加载的数据的缓存。 因此,在这里您仍然会从Dao返回一个DataSource.Factory ,但是您还需要实现另一个Paging组件BoundaryCallback 。 当用户接近本地缓存中数据的末尾时, BoundaryCallback将加载更多数据。 插入数据后,分页库将自动更新UI。 但是,必须将BoundaryCallback与之前创建的LivePagedListBuilder关联,如下所示:
val data = LivePagedListBuilder(
dataSourceFactory,
config
)
.setBoundaryCallback(boundaryCallback)
.build()BoundaryCallback: signals when a PagedList has reached the end of available data.
BoundaryCallback :当PagedList到达可用数据的末尾时发出信号。
In the third case, you have just only the network as your DataSource. So, you will have to create both your DataSource and your DataSource.Factory. However, when you choose which data source type to extend, consider what your back-end API looks like. If you require a request data from your back-end based on a key, you will extend from ItemKeyedDataSource. For example, you might require to get the first 100 comments added to a GitHub repository after a certain date. Then the date will be the key for your DataSource. ItemKeyedDataSource allows you to define how to load the initial page as well as how to load items both after and before a keyed entry. If your back-end exposes APIs that work with pages, you would extend from PageKeyedDataSource.
在第三种情况下,只有网络作为数据源。 因此,您将必须同时创建DataSource和DataSource.Factory 。 但是,当您选择要扩展的数据源类型时,请考虑您的后端API的外观。 如果您需要基于密钥的后端请求数据,则将从ItemKeyedDataSource扩展。 例如,您可能需要在特定日期之后将前100条注释添加到GitHub存储库中。 然后,日期将成为您的数据源的关键。 ItemKeyedDataSource允许您定义如何加载初始页面以及如何在键入键之后和之前加载项目。 如果您的后端公开了可用于页面的API,则应从PageKeyedDataSource扩展。
Three implementations of DataSource:
数据源的三种实现:
ItemKeyedDataSource: provides some type of key to use to fetch the next data size and unknown list size. If you require to use data from item N to fetch item N+1. For instance, if you are fetching threaded comments for a discussion app, you might need to pass the ID of the last comment to get the contents of the next comment.
ItemKeyedDataSource:提供某种类型的密钥,用于获取下一个数据大小和未知列表大小。 如果您需要使用项目N中的数据来获取项目N + 1 。 例如,如果您要获取讨论应用程序的主题注释,则可能需要传递上一个注释的ID才能获取下一个注释的内容。
PageKeyedDataSource: provides a next/before link and has unknown list size. If you are fetching social media posts from the network, you may need to pass a
nextPagetoken from one load into a subsequent load.PageKeyedDataSource:提供下一个/前一个链接,并且列表大小未知。 如果要从网络中获取社交媒体帖子,则可能需要将
nextPage令牌从一个负载传递到后续负载。PositionalDataSource: useful for sources that provide a fixed size list that can be fetched with arbitrary positions and sizes. In other words, if you need to fetch pages of data from any location you select in your data store. This class supports requesting a set of data items beginning from whatever location you choose. For instance the request might return the 50 data items beginning with location 1500.
PositionalDataSource:对于提供固定大小列表的源很有用,该列表可以使用任意位置和大小获取。 换句话说,如果您需要从数据存储区中选择的任何位置获取数据页。 此类支持从您选择的任何位置开始请求一组数据项。 例如,请求可能返回从位置1500开始的50个数据项。
实现分页库的步骤 (Steps for implementing Paging library)
All in all, five steps can be mentioned for implementing Paging library briefly as follows:
总而言之,可以简单地提及实现分页库的五个步骤,如下所示:
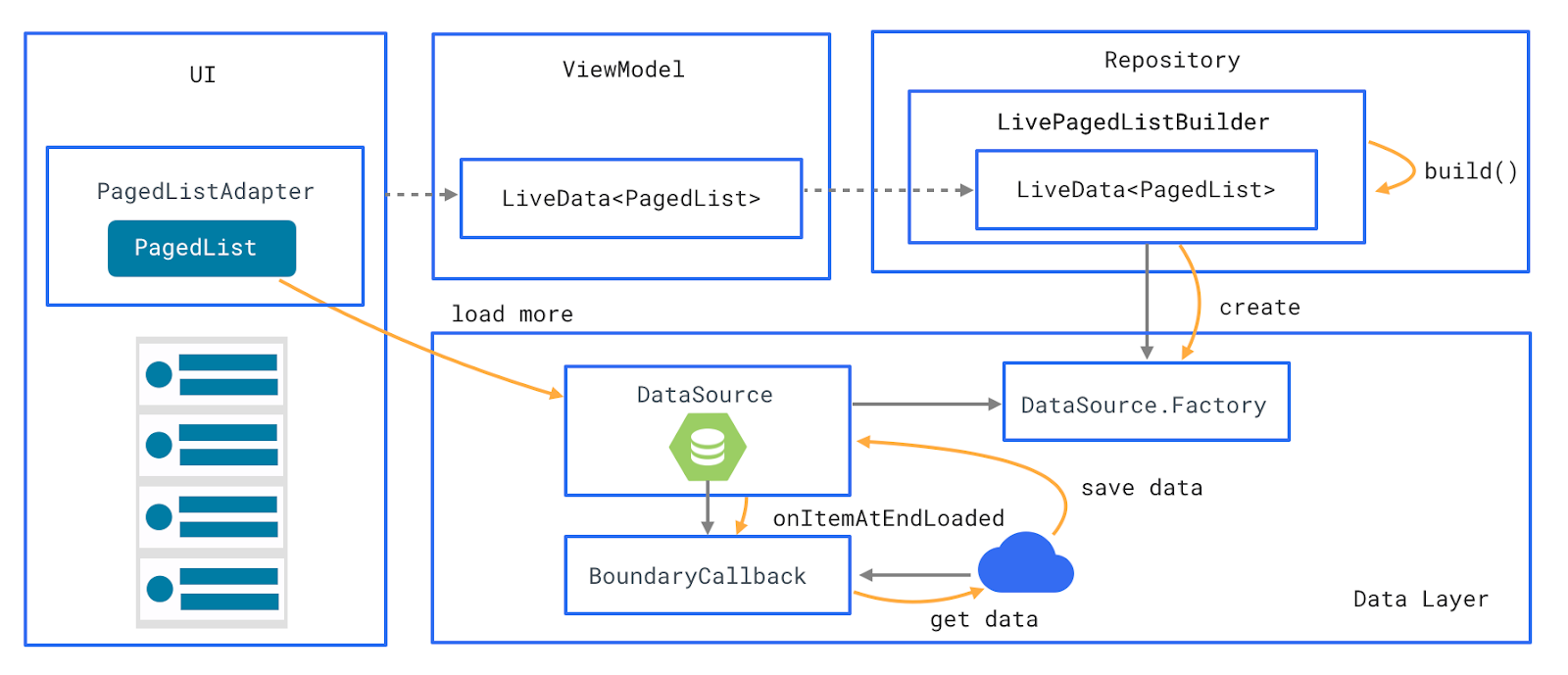
1. Define your DataSource.
1.定义您的数据源。
2. Create a BoundaryCallback if it is needed.
2.如果需要,创建一个BoundaryCallback。
3. Create a LiveData of a PagedList with help of a LivePagedListBuilder.
3.在LivePagedListBuilder的帮助下创建PagedList的LiveData。
4. Update your adapter to be a PagedListAdapter.
4.将您的适配器更新为PagedListAdapter。
5. Observe the LiveData a PagedList in your UI and send the PagedList to your adapter.
5.在UI中观察LiveData的PagedList,然后将PagedList发送到适配器。
结论 (In conclusion)
This essay considered some concepts and steps in implementing Paging library in Android. A typical feature is to load data automatically as a user scrolls through the items like infinite scroll. Previously, there were some custom solutions for this issue like third party options that could accomplish this task. Recently, Google’s new Paging Library provides this support.
本文考虑了在Android中实现分页库的一些概念和步骤。 一个典型的功能是在用户滚动浏览项目时自动加载数据,例如无限滚动。 以前,有一些针对此问题的自定义解决方案,例如可以完成此任务的第三方选项。 最近,Google的新分页库提供了此支持。
翻译自: https://medium.com/kayvan-kaseb/android-jetpack-paging-e9779d6877d















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









