






 本文探讨了机器学习中的决策树和随机森林。重点介绍了随机森林这一集成学习方法,它是通过构建多个决策树并结合它们的预测来提高模型的准确性和鲁棒性。随机森林在处理复杂数据集时表现出色,广泛应用于分类和回归任务。
本文探讨了机器学习中的决策树和随机森林。重点介绍了随机森林这一集成学习方法,它是通过构建多个决策树并结合它们的预测来提高模型的准确性和鲁棒性。随机森林在处理复杂数据集时表现出色,广泛应用于分类和回归任务。
机器学习中决策树的随机森林
机器学习 (Machine Learning)
Machine learning is an application of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. The 3 main categories of machine learning are supervised learning, unsupervised learning, and reinforcement learning. In this post, we shall focus on supervised learning for classification problems.
中号 achine学习是人工智能,它提供系统能够自动学习并从经验中提高,而不明确地编程能力的应用。 机器学习的3个主要类别是监督学习,无监督学习和强化学习。 在这篇文章中,我们将专注于分类问题的监督学习。
Supervised learning learns from past data and applies the learning to present data to predict future events. In the context of classification problems, the input data is labeled or tagged as the right answer to enable accurate predictions.
监督学习从过去的数据中学习,并将学习应用于当前的数据以预测未来的事件。 在分类问题的上下文中,将输入数据标记或标记为正确答案,以实现准确的预测。
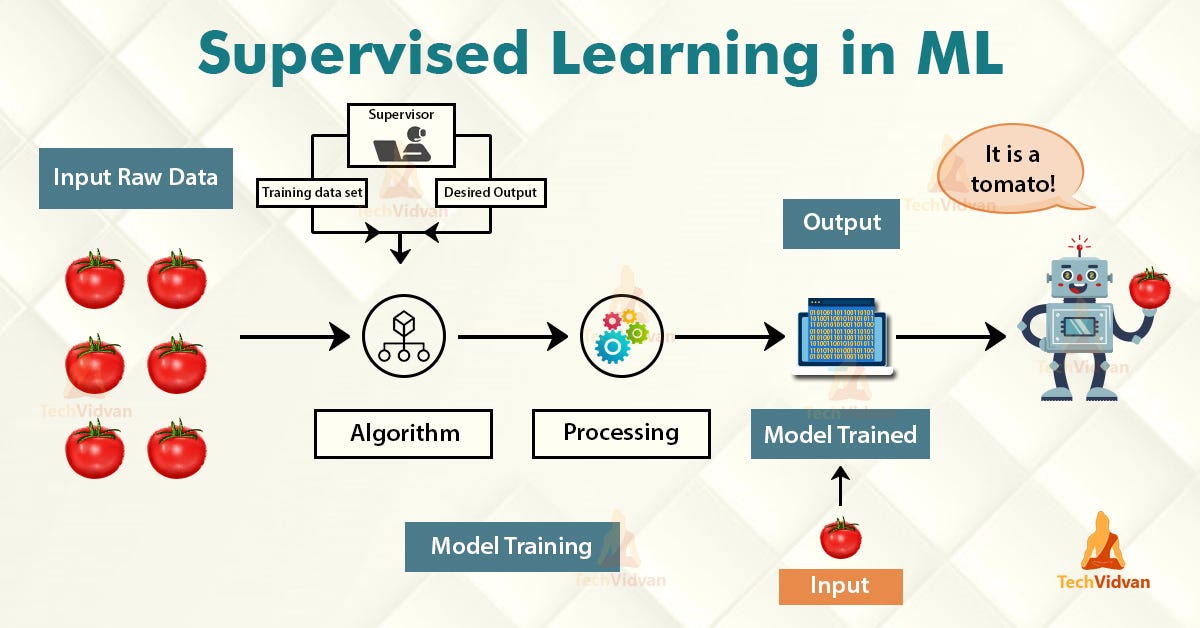
Tree-based learning algorithms are one of the most commonly used supervised learning methods. They empower predictive models with high accuracy, stability, ease of interpretation, and are adaptable at solving any classification or regression problem.
基于树的学习算法是最常用的监督学习方法之一。 它们使预测模型具有较高的准确性,稳定性,易解释性,并且适用于解决任何分类或回归问题。
Decision Tree predicts the values of responses by learning decision rules derived from features. In a tree structure for classification, the root node represents the entire population, while decision nodes represent the particular point where the decision tree decides on which specific feature to split on. The purity for each feature will be assessed before and after the split. The decision tree will then decide to split on a specific feature that produces the purest leaf nodes (ie. terminal nodes at each branch).
决策树通过学习从要素派生的决策规则来预测响应的值。 在用于分类的树结构中 , 根节点代表整个种群,而决策节点则代表决策树确定要分割的特定特征的特定点。 在拆分之前和之后,将评估每个功能部件的纯度。 然后,决策树将决定拆分产生一个最纯叶节点 (即每个分支的终端节点)的特定功能。
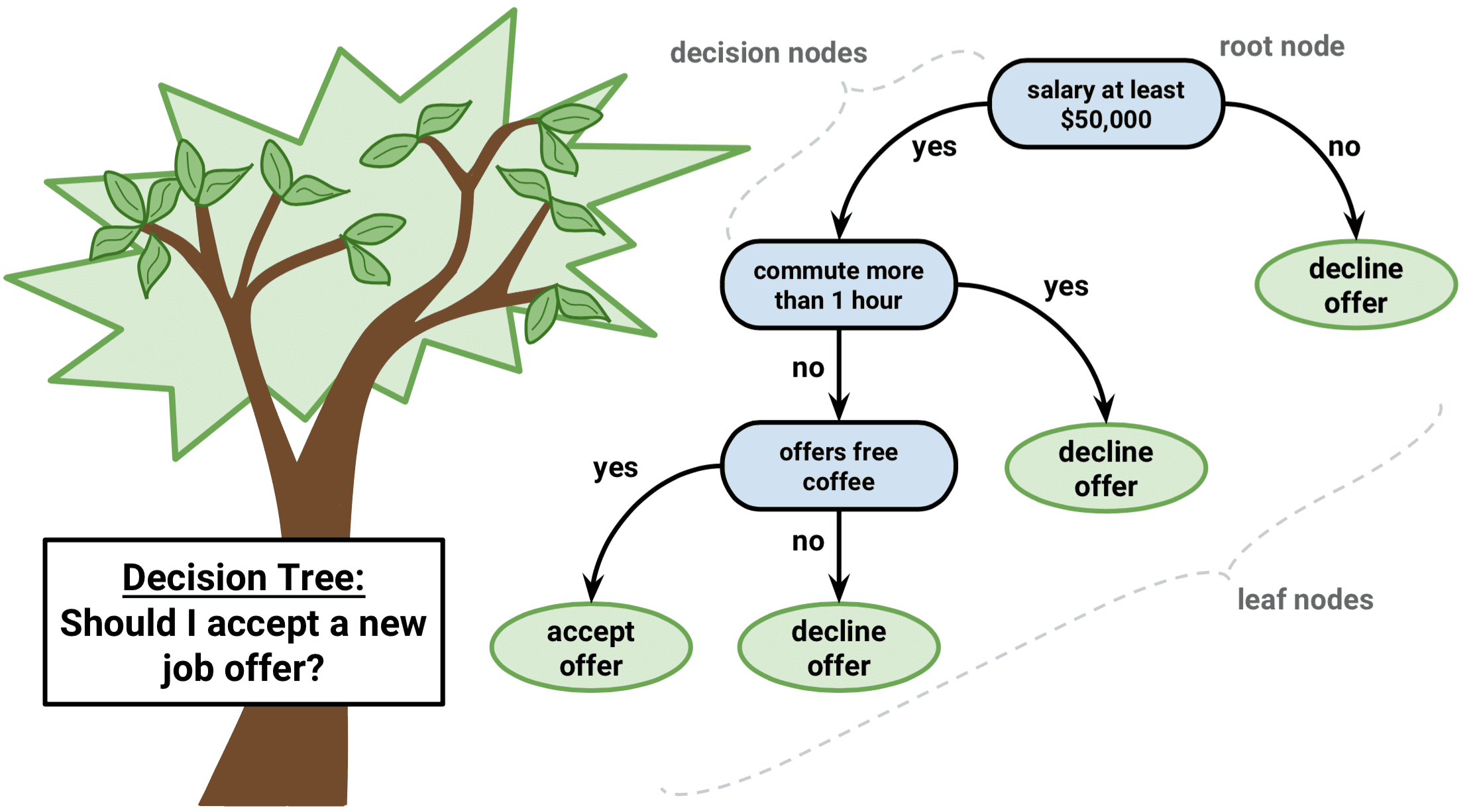
A significant advantage of a decision tree is that it forces the consideration of all possible outcomes of a decision and traces each path to a conclusion. It creates a comprehensive analysis of the consequences along each branch and identifies decision nodes that need further analysis.
决策树的显着优势在于,它可以强制考虑决策的所有可能结果,并跟踪得出结论的每条路径。 它对每个分支的后果进行全面分析,并确定需要进一步分析的决策节点。
However, a decision tree has its own limitations. The reproducibility of the decision tree model is highly sensitive, as a small change in the data can result in a large change in the tree structure. Space and time complexity of the decision tree model is relatively higher, leading to longer model training time. A single decision tree is often a weak learner, hence a bunch of decision tree (known as random forest) is required for better prediction.
但是, 决策树有其自身的局限性 。 决策树模型的可重复性非常敏感,因为数据的微小变化会导致树形结构的巨大变化。 决策树模型的时空复杂度相对较高,导致模型训练时间更长。 单个决策树通常学习能力较弱,因此需要一堆决策树(称为随机森林)才能更好地进行预测。
The random forest is a more powerful model that takes the idea of a single decision tree and creates an ensemble model out of hundreds or thousands of trees to reduce the variance. Thus giving the advantage of obtaining a more accurate and stable prediction.
随机森林是一个功能更强大的模型,它采用单个决策树的概念,并从数百或数千棵树中创建一个集成模型以减少差异。 因此具有获得更准确和稳定的预测的优势 。
Each tree is trained on a random set of observations, and for each split of a node, only a random subset of the features is used for making a split. When making predictions, the random forest does not suffer from overfitting as it averages the predictions for each of the individual decision trees, for each data point, in order to arrive at a final classification.
每棵树都在一组随机的观测值上训练,并且对于节点的每个拆分,仅使用特征的随机子集进行拆分。 在进行预测时,随机森林不会遭受过度拟合的影响,因为它会针对每个数据点对每个单独决策树的预测取平均,以得出最终分类。
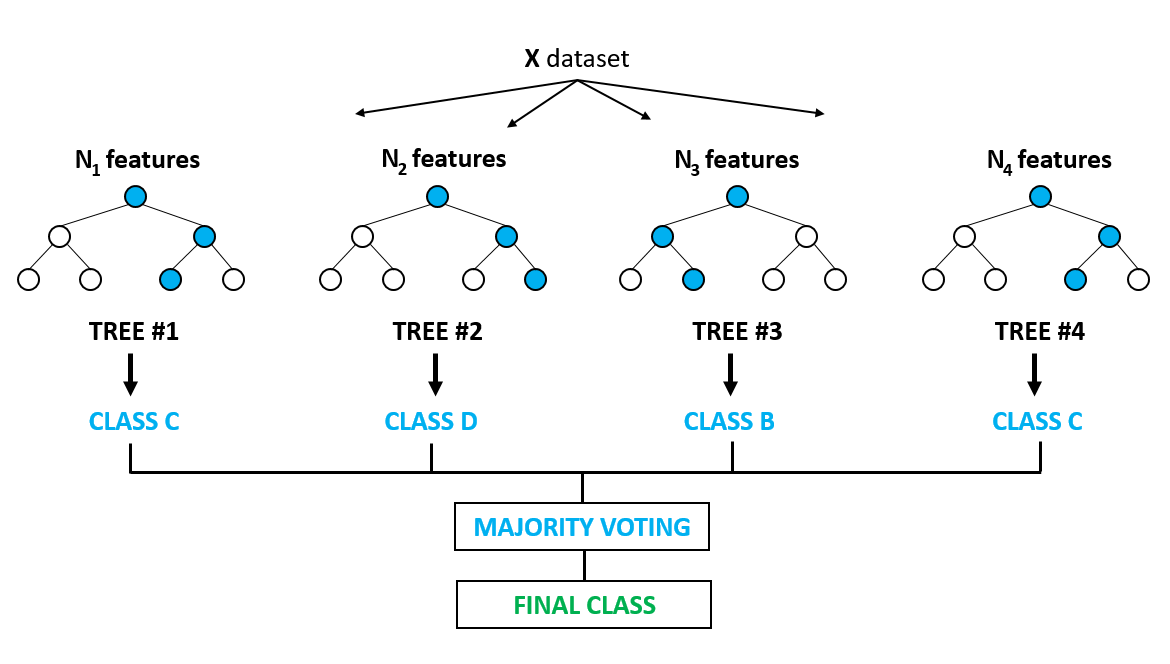
We shall approach a classification problem and explore the basics of how decision trees work, how individual decisions trees are combined to form a random forest, how to fine-tune the hyper-parameters to optimize random forest, and ultimately discover the strengths of using random forests.
我们将研究分类问题,并探索决策树如何工作,如何将单个决策树组合以形成随机森林,如何微调超参数以优化随机森林的基础知识,并最终发现使用随机森林的优势。森林。
问题陈述:预测一个人每年的收入是否超过50,000美元。 (Problem Statement: To predict whether a person makes more than U$50,000 per year.)
让我们开始编码! (Let’s start coding!)
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.utils import resample
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report, precision_recall_curve, roc_curve, roc_auc_score
import scikitplot as skplt
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline资料准备 (Data Preparation)
Load the Census Income Dataset from the URL and display the top 5 rows to inspect the data.
从URL加载人口普查收入数据集 ,并显示前5行以检查数据。
# Add header=None as the first row of the file contains the names of the columns.
# Add engine='python' to avoid parser warning raised for reading a file that doesn’t use the default ‘c’ parser.
income_data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data',
header=None, delimiter=', ', engine='python')
income_data.head()
# Add headers to dataset
headers = ['age','workclass','fnlwgt','education','education_num','marital_status','occupation','relationship',
'race','sex','capital_gain','capital_loss','hours_per_week','native_country','income']
income_data.columns = headers
income_data.head()
数据清理 (Data Cleaning)
# Check for empty cells and if data types are correct for the respective columns
income_data.info()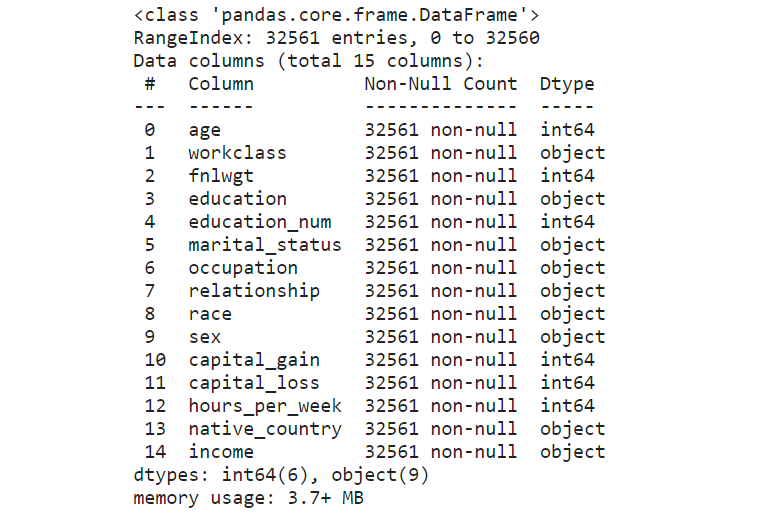
Box plots are useful as they show outliers for integer data types within a data set. An outlier is an observation that is numerically distant from the rest of the data. When reviewing a box plot, an outlier is defined as a data point that is located outside the whiskers of the box plot.
箱形图很有用,因为它们显示了数据集中整数数据类型的离群值。 离群值是在数值上与其余数据相距遥远的观测值 。 查看箱形图时,离群值定义为位于箱形图晶须之外的数据点。
# Use a boxplot to detect any outliers
income_data.boxplot(figsize=(30,6), fontsize=20);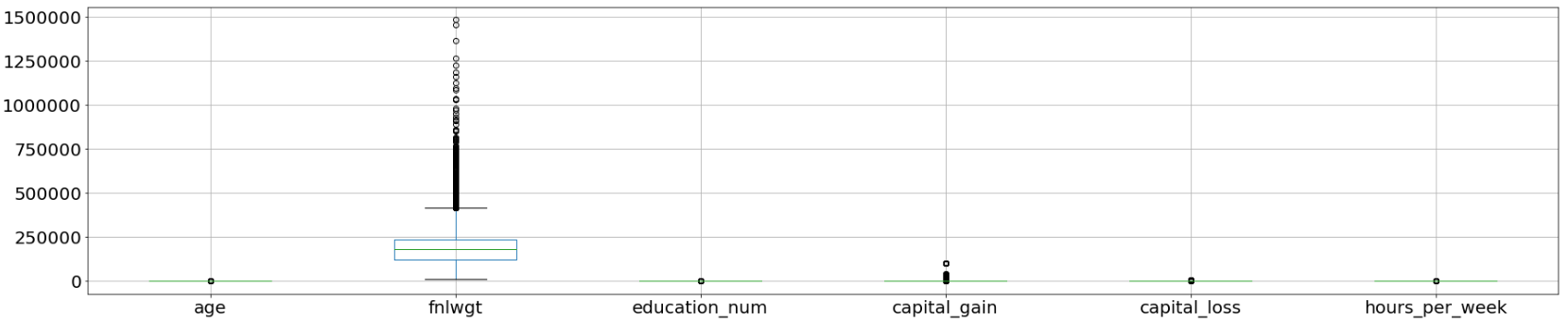
As extracted from the attributes listing in the Census Income Data Set, the feature “fnlwgt” refers to the final weight. It states the number of people the census believes the entry represents. Therefore, this outlier would not be relevant to our analysis and we would proceed to drop this column.
从“ 人口普查收入数据集 ”中的属性列表中提取的功能“ fnlwgt”是指最终权重。 它指出了人口普查相信该条目所代表的人数。 因此,此异常值与我们的分析无关,我们将继续删除此列。
clean_df = income_data.drop(['fnlwgt'], axis=1)
clean_df.info()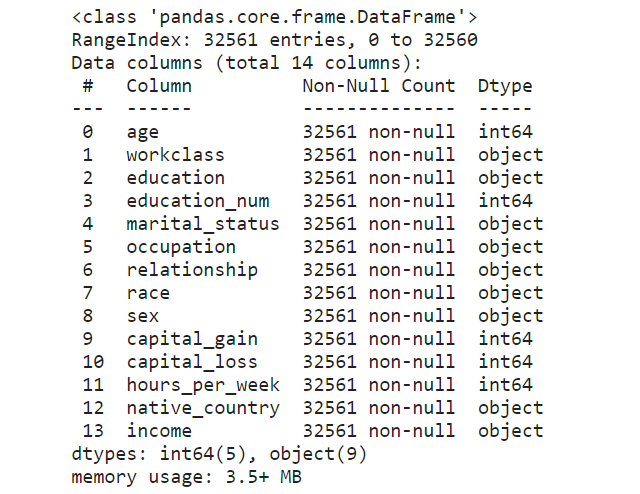
# Select duplicate rows except first occu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3996
3996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









