





This is an entry level post to cover the fundamentals of GraphQL which will lead into a video demo that creates a basic API that can sit between client applications and some existing REST services.
这是一篇入门级文章,涵盖了GraphQL的基础知识,这将导致一个视频演示,该演示创建一个可以位于客户端应用程序和某些现有REST服务之间的基本API。
GraphQL (or GQL) is a query language for your API. It’s not a programming language that does any computation but it’s a specification used to parse and execute queries with code implementations that support the spec.
GraphQL(或GQL)是API的查询语言。 它不是进行任何计算的编程语言,而是用于通过支持该规范的代码实现解析和执行查询的规范。
Later we will talk about Apollo Service which is a library that leverages the GraphQL spec to build a Graph API on Node.
稍后我们将讨论Apollo Service,它是一个利用GraphQL规范在Node上构建Graph API的库。
为什么选择GraphQL? (Why GraphQL?)
A key design principle of GraphQL is to be product centric. This is good news for UI Engineers as GraphQL servers are unapologetically driven by the requirements of the view and the engineers that build them.
GraphQL的关键设计原则是以产品为中心。 这对UI工程师来说是个好消息,因为GraphQL服务器不受视图和构建它们的工程师的强烈要求。
The 2 problem’s that GraphQL was designed to solve are:
GraphQL设计要解决的两个问题是:
- Avoid multiple round trips 避免多次往返
- Avoid over and under fetching data避免获取数据过多和不足
The immediately apparent comparison between GraphQL and REST is that data is requested and mutated over a single endpoint. The other comparison is that the client can explicitly request the fields it wants instead of a predefined set of fields set by the REST service(s) and its developers.
GraphQL和REST之间立即明显的比较是,在单个端点上请求并更改了数据。 另一个比较是,客户端可以显式请求其所需的字段,而不是由REST服务及其开发人员设置的预定义字段集。
In other words, the fact that all required data can be returned in 1 request means the client doesn’t need to make multiple requests when data is stored across multiple services or sources. Then also because the client can specify exactly what fields it wants, the client is not going to receive more or less data than it needs to perform its duty.
换句话说,所有必需的数据都可以在一个请求中返回的事实意味着,当数据跨多个服务或源存储时,客户端不需要发出多个请求。 然后,由于客户端可以准确指定所需的字段,因此客户端接收的数据不会超过执行任务所需的数据。
With these two problems solved a front end developer can enjoy a better developer experience (or DX) getting data and managing state.
通过解决这两个问题,前端开发人员可以享受更好的开发人员体验(或DX)来获取数据和管理状态。
Graph API在堆栈中的哪个位置? (Where does a Graph API belong on the stack?)
A common question is where should a Graph API sit on the stack. Some people might be wondering if Graph API’s are trying to replace REST but that’s not the case or its goal.
一个常见的问题是Graph API应该放在堆栈中的什么位置。 某些人可能想知道Graph API是否正在尝试取代REST,但事实并非如此或它的目标。
If you have existing Graph API’s the it should act like a middleware between the client and those services. If you don’t have services already then it will be the middleware between the client and the database. Here’s a visual guide:
如果您有现有的Graph API,则它应该像客户端和那些服务之间的中间件。 如果您还没有服务,那么它将是客户端和数据库之间的中间件。 这是视觉指南:
演示的示例用例 (Example Use case for the Demo)
Before I show you, an example query lets imagine as a UI engineer you are building a page that shows the first name of a user and a list of their posts. In the list of posts you want to display the title alongside a figure that tells the reader how long it might take to read and a link to view the post.
在向您展示之前,有一个示例查询让我们想象作为UI工程师,您正在构建一个显示用户名字和其帖子列表的页面。 在帖子列表中,您想在标题旁边显示一个图,该图告诉读者阅读可能需要多长时间,以及查看该帖子的链接。
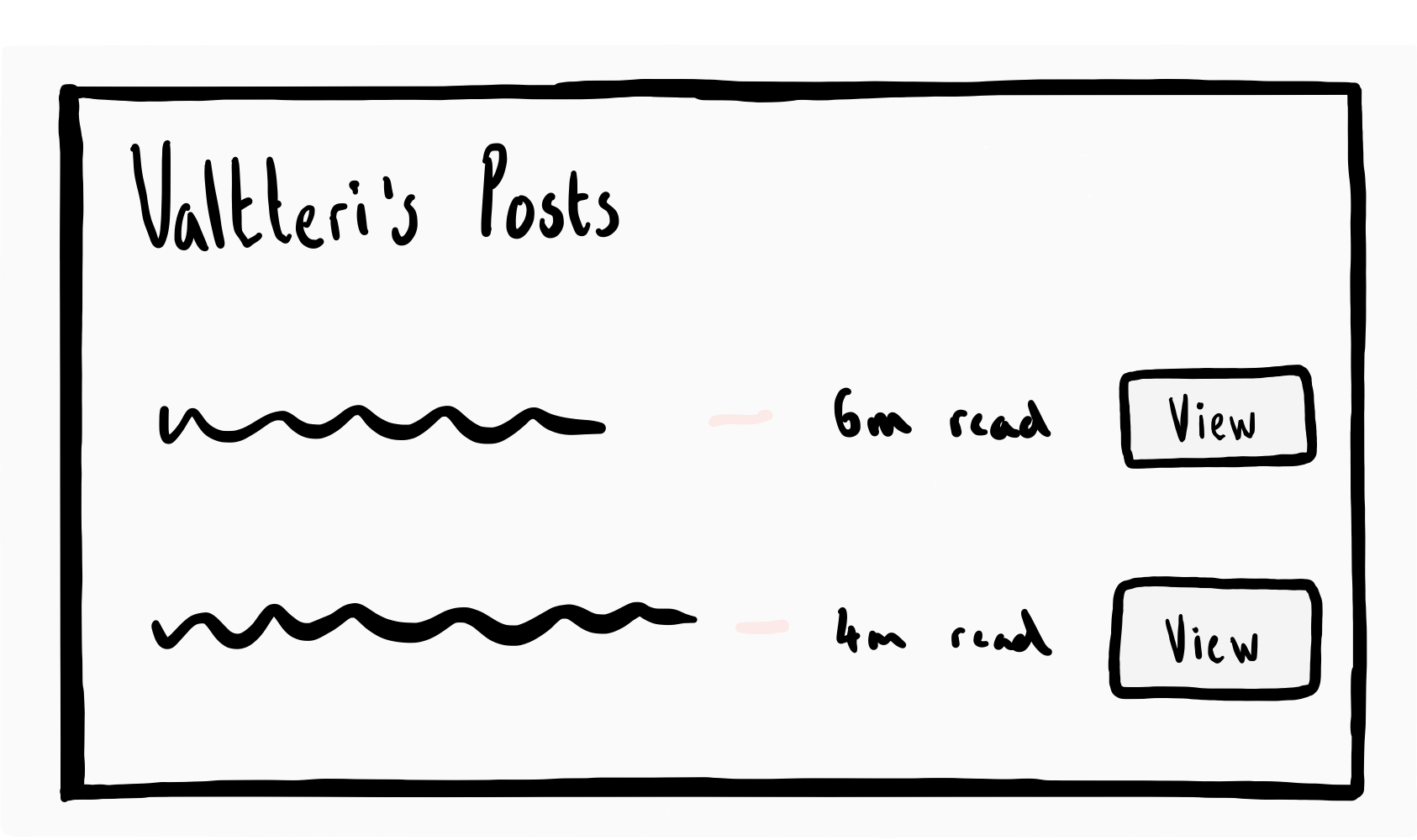
REST如何解决?(How would this be resolved with REST?)
In a client / server world you would you typically need to make a request for the user data from a user service which likely has their name and a list of post ids. After the users call you would then make a call for each post’s data from a posts service that would return a response containing all data in relation to that post. Depending on how many posts that user has you would make that many requests plus 1 for the user so that you can render this view.
在客户端/服务器环境中,您通常需要从用户服务中请求用户数据,该用户数据可能具有其名称和帖子ID列表。 在用户致电之后,您随后将通过帖子服务呼叫每个帖子的数据,该服务将返回包含与该帖子有关的所有数据的响应。 根据该用户拥有的帖子数,您将向该用户提出多个请求,再加上1,以便可以呈现此视图。
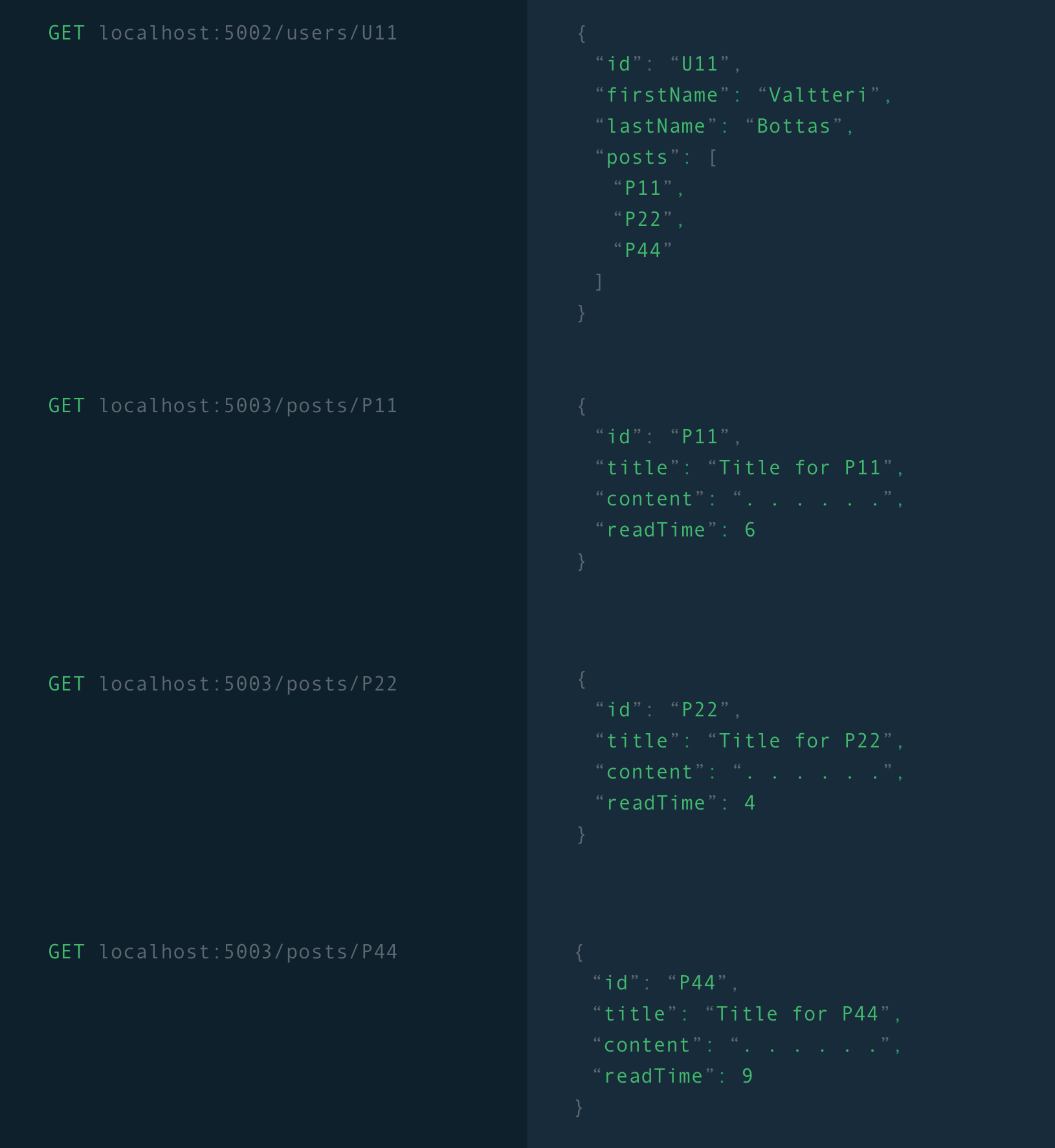
Note: This receives all the data we require but we’ve also over fetched data such as the users last name and each posts content value.
注意:这将接收到我们需要的所有数据,但我们也处理了获取的数据,例如用户的姓氏和每个帖子的内容值。
GraphQL如何解决? (How would this be resolved with GraphQL?)
Now it’s time to show how you would request the same data using a query.
现在是时候展示如何使用查询请求相同的数据了。
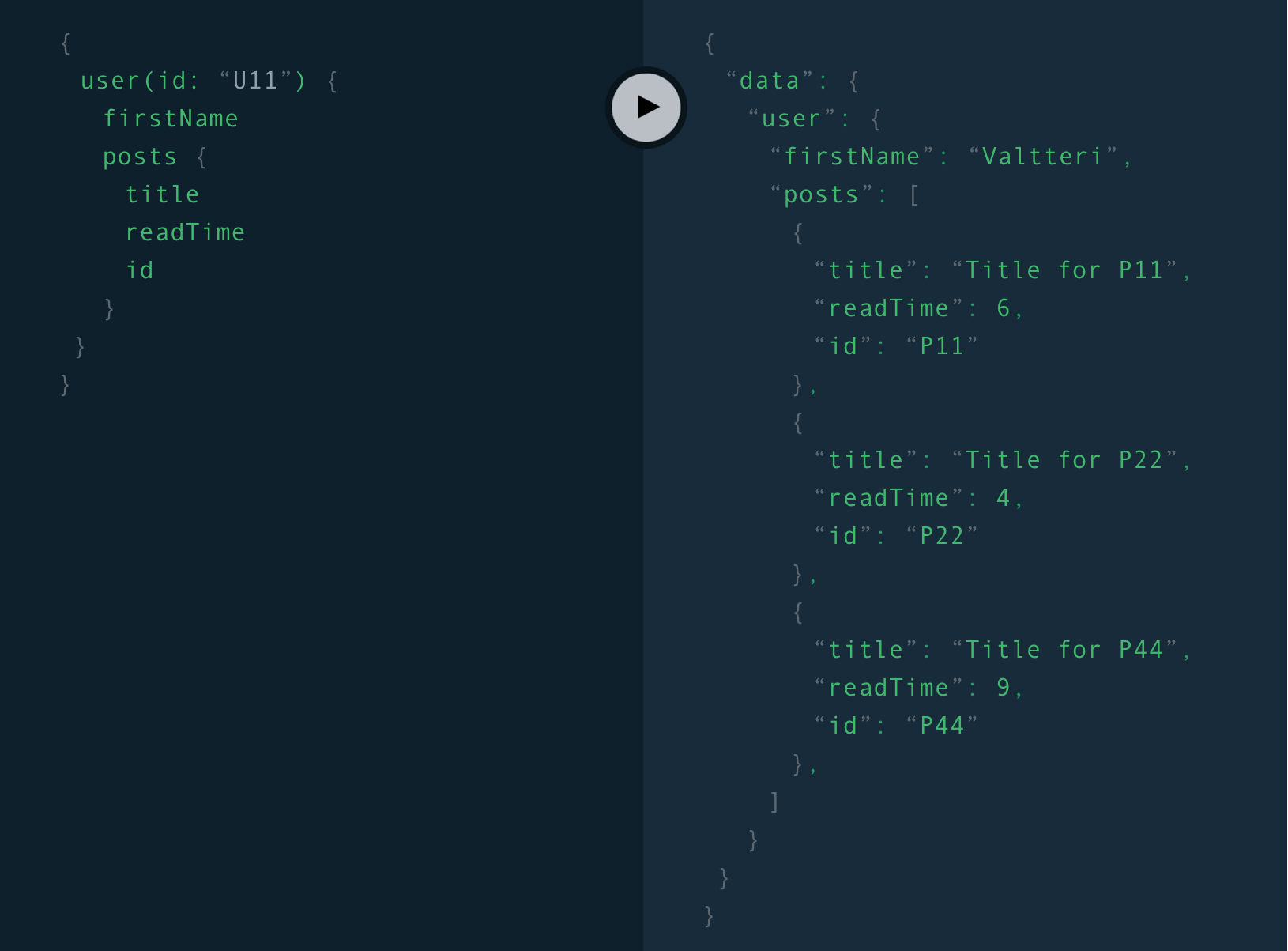
The query is shown on the image above on the left hand side. As you can see, the query is a sequence of text that lists the fields we want. It’s sent as the request payload over a POST request to the endpoint /graph. You’ll see that line 1 of the query takes an argument of the users id. The endpoint path could be anything you want but it’s common to use /graph or /api. On the right side you can see that the response data reflects the shape of the query only it’s given as the value of a prop called data. Finally, you’ll see that the response includes the values of all the fields requested in the query with nothing less or more than we need to populate the page.
该查询显示在上方图像的左侧。 如您所见,查询是一系列文本,列出了我们想要的字段。 它通过POST请求作为请求负载发送到端点/ graph。 您将看到查询的第1行采用用户ID的参数。 端点路径可以是您想要的任何路径,但是通常使用/ graph或/ api。 在右侧,您可以看到响应数据仅反映查询的形状,只是作为名为data的prop的值给出的。 最后,您会看到响应中包含查询中请求的所有字段的值,而这些字段的值只不过是填充页面所需的值。
我该如何开始? (How do I get started?)
To build a GraphQL server that can accept queries you need to start by defining a schema that states the field types and hierarchy of your data.
要构建可以接受查询的GraphQL服务器,您需要首先定义一个模式,该模式说明数据的字段类型和层次结构。
Once you have a schema you then need to provide functions that know how to resolve each field in the schema. These functions are simply called resolvers.
一旦有了模式,就需要提供知道如何解析模式中每个字段的函数。 这些功能简称为解析器。
架构图 (Schema)
A schema defines a collection of types and the relationships between those types. The schema enables client developers to see exactly what data is available and request a specific subset of that data with a single optimised query.
模式定义类型的集合以及这些类型之间的关系。 该模式使客户端开发人员可以准确查看可用的数据,并通过单个优化查询请求该数据的特定子集。
种类 (Types)
There are a few categories of types that can be used in the SDL. A brief overview of the SDL type categories is below.
SDL中可以使用几种类型的类型。 下面是SDL类型类别的简要概述。
Side note: Fields can be annotated with ! to state that it is required (cannot be null) and its type may be surrounded by [] to state that it is an array of that type
旁注:字段可用注释! 声明它是必需的(不能为null),并且它的类型可能被[]包围,以表明它是该类型的数组
标量类型(Scalar Types)
These are native GraphQL types
这些是本机GraphQL类型
- String串
- Int整数
- Float浮动
- Boolean布尔型
- IDID
firstName: String对象类型(Object Types)
These are types that represent a group of fields. The name of the type is entirely up to the programmer. Each field maps to either a Scalar type or an Object type.
这些是代表一组字段的类型。 类型的名称完全取决于程序员。 每个字段都映射为标量类型或对象类型。
type User {
id: ID!
firstName: String
}根级别类型(Root Level Types)
Root types act as entry points to your schema. You only need one of each in your schema (that’s if you need it at all). The fields on these types will map to Scalar or Object types.
根类型充当架构的入口点。 您只需在架构中选择一个(即是否完全需要)。 这些类型上的字段将映射为标量或对象类型。
They are:
他们是:
- Query 询问
- Mutation突变
- Subscription.订阅。
We haven’t talked much about mutations yet but if queries are comparable to REST Get requests, mutations are comparable to REST Patch, Put, Post and Delete requests. We also haven’t talked about Subscriptions but will save those for another day.
我们对突变的讨论还不多,但是如果查询与REST Get请求相当,那么突变与REST Patch,Put,Post和Delete请求相当。 我们也没有讨论过订阅,但是会将其保存另一天。
Query {
users: [User] # Surrounding a type with [] represents an array of that type
}
Mutation {
deleteUser(id: ID!): User
}输入类型(Input Types)
These are a special type that describe what can be passed as an argument to a query or mutation. These are incredibly helpful as its common to make a Get request for a set of data on a resource but when creating or updating that resource you might only need to send a subset of that data. (EG when creating a user you don’t need to send an ID because the service will set one itself).
这些是特殊类型,用于描述可以作为参数传递给查询或变异的内容。 这些请求对资源上的一组数据进行Get请求非常有用,但是当创建或更新该资源时,您可能只需要发送该数据的子集。 (例如,EG在创建用户时不需要发送ID,因为该服务会自行设置)。
input NewUserInput {
firstName: String
}
type User {
id: ID!
firstName: String
}
type Mutation {
createUser(NewUserInput): User
}其他种类(Other types)
There are a few other types (Union, Custom Scalar and Enum ) that we haven’t discussed but to save time we’ll move on and leave a link to the spec here that will give you all the info you need.
我们还没有讨论过其他几种类型(Union,Custom Scalar和Enum),但是为了节省时间,我们将继续进行操作,并在此处保留指向规范的链接,它将为您提供所需的所有信息。
模式范例 (Example schema)
Now that we know a little about the SDL. Let’s create a schema for the API that can be used by our imaginary user posts page.
现在,我们对SDL有所了解。 让我们为虚构的用户帖子页面创建一个API架构。
type User {
id: ID
firstName: String
lastName: String
posts: [Post]
}
type Post {
id: ID
title: String
content: String
readTime: Int
}
type Query {
user(id: ID): User
}解析器(Resolvers)
As mentioned, resolvers are functions that know how to resolve each field of your query. By resolve, we mean to execute some code and return a value that corresponds to that field. In GQL fields on query types are resolved simultaneously but fields on mutation types are resolved sequentially.
如前所述,解析器是知道如何解析查询的每个字段的函数。 通过解决,我们的意思是执行一些代码并返回与该字段对应的值。 在GQL中,查询类型的字段被同时解析,而突变类型的字段则被顺序解析。
As functions, resolvers can receive arguments. Depending on the library you use to build your GQL server the arguments passed to a resolver may differ slightly however its typical for a resolver function to receive:
作为函数,解析器可以接收参数。 取决于用于构建GQL服务器的库,传递给解析器的参数可能会略有不同,但是解析器函数接收的参数通常是:
- Parent — This is the return value of the resolver for this fields parent 父级-这是此字段父级的解析器的返回值
- Args — An object of any query arguments for this field (Eg in our schema, you would expect the user field resolver on type Query to receive an id argument)Args-该字段的任何查询参数的对象(例如,在我们的架构中,您希望Query类型的用户字段解析器接收到id参数)
- Context — This is an object that is given to all resolvers for the duration of a query execution. (Eg authentication detail) 上下文-这是在查询执行期间分配给所有解析器的对象。 (例如身份验证详细信息)
- Info — This contains information on the operations execution state (eg field name, path to field from root etc) 信息—包含有关操作执行状态的信息(例如,字段名称,从根目录到字段的路径等)
As mentioned resolvers can execute some code to get a value for its corresponding field. This code is entirely up to you and your system. Quite often it might be an API request to an existing REST service or a database call but it could also simply return a computed or hardcoded value.
如前所述,解析器可以执行一些代码来获取其对应字段的值。 此代码完全取决于您和您的系统。 通常可能是对现有REST服务的API请求或对数据库的调用,但也可能仅返回计算或硬编码的值。
const userResolver = async (, { id }) => {
try {
const user = await get(`/users/$id`);
return user;
} catch(error) {
throw new error;
}
}演示时间(Demo time)
Ok now it’s time to demonstrate what we’ve talked about so far with a demo.
好了,现在该通过演示演示我们到目前为止讨论的内容了。
谢谢 (Thanks)
Thanks for reading and watching. Well done for following along and I hope this was helpful or interesting as an introduction to GraphQL and Apollo. I’ll stop here however I plan on following this up with a few more posts about mutations, data loaders and Apollo for client-side development.
感谢您的阅读和观看。 后续工作做得很好,我希望这对GraphQL和Apollo有所帮助或有趣。 我将在这里停止,不过我计划在此之后再发布一些有关突变,数据加载器和用于客户端开发的Apollo的文章。















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









