





In C/C++ applications it’s usual to use structures to group related data registers. The data contained into these structures can be persisted/loaded into/from a file through a serialization/deserialization process.
在C / C ++应用程序中,通常使用结构对相关数据寄存器进行分组。 可以通过序列化/反序列化过程将包含在这些结构中的数据持久化/从文件中加载/加载到文件中。
During the development of one of my pet projects I needed to analyze my workout statistics registered in my Geoanute ONMove 220 GPS watch. In a previous research, I discovered that this watch stores the workout statistics and the GPS track log into binary files. The content of these files is defined by C structures, so I had to do some more research. Fortunately, I discovered the omx2gpx project and I was able to know the format of these structures.
在开发其中一个宠物项目时,我需要分析在Geoanute ONMove 220 GPS手表中注册的锻炼统计数据。 在先前的研究中,我发现该手表将锻炼统计信息和GPS跟踪日志存储到二进制文件中。 这些文件的内容由C结构定义,因此我不得不做更多的研究。 幸运的是,我发现了omx2gpx项目,并且能够知道这些结构的格式。
锻炼形式 (The workout format)
The watch registers the workout into two separate files: a OMH file containing the workout data, such as the distance, the time and the date, and a OMD file containing the GPS track data.
手表将锻炼记录到两个单独的文件中:一个包含锻炼数据(例如距离,时间和日期)的OMH文件,以及一个包含GPS轨迹数据的OMD文件。
In this post I´ll show you how to load the workout data stored into the OMH file using Python. As I said before, this file holds the serialized version of a structure containing the data. In the following gist we can see the format of this structure stored into the OMH file:
在本文中,我将向您展示如何使用Python将锻炼数据加载到OMH文件中。 如前所述,该文件包含包含数据的结构的序列化版本。 在下面的要点中,我们可以看到存储在OMH文件中的此结构的格式:
通过读取原始字节加载数据 (Loading the data by reading the raw bytes)
A first approach to load this data is just to open the file in binary mode and read the different fields in byte chunks, performing the needed conversions:
加载此数据的第一种方法就是以二进制模式打开文件并读取字节块中的不同字段,然后执行所需的转换:
Notice that, inside the file, the structure registers are stored sequentially. Also, we have to keep in mind the byte ordering of these registers.
请注意,在文件内部,结构寄存器是按顺序存储的。 另外,我们必须牢记这些寄存器的字节顺序 。
This is a valid and simple approach but I thought that there may be a more elegant way to do this. That was how I discovered the struct module from the python standard library.
这是一种有效且简单的方法,但我认为可能会有一种更优雅的方法。 这就是我从python标准库中发现struct模块的方式。
使用struct加载数据 (Loading the data using struct)
As we can see in the docs, the struct module performs conversions between Python values and C structs represented as Python bytes objects. We can use this module to handle binary data stored in files or network connections, among other sources.
如我们在文档中所见,struct模块在Python值和以Python bytes对象表示的C结构之间执行转换。 我们可以使用此模块来处理存储在文件或网络连接中的二进制数据,以及其他来源。
Using this module is simple: we need to define a declarative format string to specify the type of data being packed/unpacked. Also, with some special characters we can control the Byte Order, Size, and Alignment.
使用此模块很简单:我们需要定义一个声明性格式字符串以指定要打包/解压缩的数据的类型。 同样,使用一些特殊字符,我们可以控制字节顺序,大小和对齐方式 。
In the following table we can see the available format characters with their type equivalences:
在下表中,我们可以看到可用的格式字符及其类型等效项:
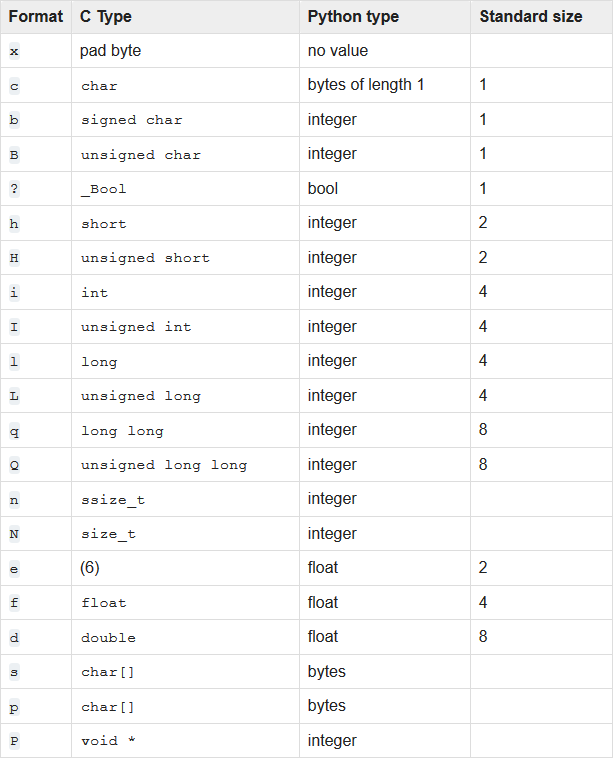
With these format characters we declare the format string that specifies the structure. Then, loading the workout data is pretty simple now:
使用这些格式字符,我们声明了指定结构的格式字符串。 然后,加载锻炼数据现在非常简单:
We only need to pass two arguments to the unpack function: the format string <I4H8BH18B5H10B and the byte data. With the first character of the format string we specify the byte ordering: we’re using < to tell the unpack function that the registers are stored using little-endian byte ordering. Next, we use the format characters to describe the format of the structure registers: one unsigned integer I for the distance (field 0); four unsigned short 4H for the time (1), average speed (2), max speed (3) and kilocalories (4); eight unsigned char 8B for the average heart rate (5), max heart rate (6), year in short format (7), month (8), day (9), hour (10), minute (11) and file number; one unsigned short H; eighteen unsigned char 18B; five unsigned short 5H and ten unsigned char 10B.
我们只需要将两个参数传递给unpack函数:格式字符串<I4H8BH18B5H10B和字节数据。 在格式字符串的第一个字符处,我们指定字节顺序:我们使用<告诉unpack函数,寄存器是使用小尾数字节顺序存储的。 接下来,我们使用格式字符描述结构寄存器的格式:距离(字段0)为一个无符号整数I ; 时间(1),平均速度(2),最大速度(3)和千卡(4)的四个无符号短4H ; 八个无符号字符8B用于平均心率(5),最大心率(6),短格式的年份(7),月份(8),日期(9),小时(10),分钟(11)和文件号; 一个无符号的短H ; 十八个未签名的字符18B ; 5个未签名的short 5H和10个未签名的char 10B 。
Notice that although we’re only getting some registers of the struct we must provide a format string for the whole structure.
请注意,尽管我们仅获得该结构的一些寄存器,但我们必须为整个结构提供格式字符串。
And that’s it. Using the struct module we can read binary files in a simple way. I hope you found this post useful :)
就是这样。 使用struct模块,我们可以以一种简单的方式读取二进制文件。 我希望您发现这篇文章有用:)















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









