





 本文构建并分析了《哈利·波特与魔法石》的动态角色社交网络,揭示了故事情节、作者风格及角色间关系。通过NLP和网络科学交叉分析,探讨角色重要性、叙事结构变化、社区检测、摘要生成及与其它书籍的对比。
本文构建并分析了《哈利·波特与魔法石》的动态角色社交网络,揭示了故事情节、作者风格及角色间关系。通过NLP和网络科学交叉分析,探讨角色重要性、叙事结构变化、社区检测、摘要生成及与其它书籍的对比。
复杂网络 社交网络
Novels often offer a complex narrative that can be difficult to follow throughout the book for a reader. Proposing tools that help gain a better comprehension is therefore an interesting path, which is still rather unexplored yet. Indeed, despite the recent development of NLP algorithms like GPT-3 that produce outstanding performances in a wide variety of tasks (translation, question answering, text generation…), getting a true understanding of the book or even a good summary is still out of reach.
ñovels经常提供一个复杂的叙述,可能难以遵循贯穿全书的读者。 因此,提出有助于更好地理解的工具是一条有趣的道路,至今仍未探索。 实际上,尽管最近开发了GLP-3这样的NLP算法,该算法在各种任务(翻译,问题解答,文本生成……)中均表现出色,但仍然无法真正理解本书,甚至无法获得很好的总结。达到。
Nevertheless, there exists other ways to get rewarding insights from a novel. In this post, we turn to a concept that is at the crossroad of Natural Language Processing (NLP) and Network Science (NS) — a new and evolving branch of applied graph theory that brings together traditions from many disciplines, including mathematics, sociology, economics and computer science [3]. More precisely, we create a relevant dynamic heterogeneous social network of characters from the book’s textual content, and then leverage information from this graph to improve one’s comprehension of the novel. In particular, we focus on five different applications: characters’ importance, narrative structural change, community detection, summarisation and book comparison. Investigating them gives us precious clues about the book’s plot, the author’s style or characters’ importance, relations and roles.
然而,还有其他方法可以从小说中获得有意义的见解。 在这篇文章中,我们将转向自然语言处理(NLP)和网络科学(NS)交汇处的概念- 应用图论的一个新兴且不断发展的分支,它汇集了许多学科的传统,包括数学,社会学,经济学和计算机科学[3]。 更确切地说,我们从书的文本内容中创建了一个相关的动态动态异构字符社会网络 ,然后利用该图中的信息来提高人们对小说的理解。 特别是,我们专注于五个不同的应用程序:角色的重要性,叙事结构的变化,社区发现,摘要和书籍比较。 对它们的研究为我们提供了有关该书的情节,作者的风格或人物的重要性,关系和角色的宝贵线索。
We apply our analysis to the famous book of J.K. Rowling: “Harry Potter and the Philosopher’s Stone” (HP1) — although the analysis could be applied to absolutely any book.
我们将分析应用于著名的JK罗琳(JK Rowling)的著作:“ 哈利·波特与哲学之石” (HP1),尽管该分析可以应用于几乎所有书籍。
At this moment you might still be wondering “But what is a dynamic heterogenous social network of characters ?” To answer your question, a network of characters is nothing more than a graph, meaning a set of nodes V and edges E, where nodes represent characters of the book and edges interactions between them. While the vast majority of approaches in the literature focus on static methods, that are by definition fixed in time — one graph for the entire book, we follow a dynamic approach — a graph that constantly evolves in time and enables to keep the narrative’s temporal information. To create this dynamic aspect, we additionally make the graph heterogenous, that is, with several edge types and node types. In other words, all nodes will not be representing characters and all edges will not be representing interactions between them. But we will come back to this later.
在这一刻,您可能仍然想知道“ 但是什么是动态的字符异质性社交网络 ?” 为了回答您的问题, 字符网络不过是一个图形 ,它表示一组节点V和边E,其中节点代表该书的字符以及它们之间的边相互作用。 虽然文献中的大多数方法都集中在静态方法上,但根据定义,这些方法是固定的(整本书一张图,但我们遵循一种动态方法),该图随着时间不断变化并能够保留叙述的时间信息。 。 为了创建此动态方面,我们还使图具有异构性 ,即具有几种边缘类型和节点类型。 换句话说,所有节点都不会代表字符,并且所有边缘都不会代表它们之间的交互。 但是我们稍后会再谈。
Here is a more accurate overview of what will be covered.
这是所涵盖内容的更准确概述。
Text processing
文字处理
(1) Retrieve the book from the Internet and split it by chapter
(1)从互联网上检索该书,并按章节进行拆分
(2) Extract character names that appear in the text
(2)提取出现在文本中的字符名称
(3) Match each character occurrence with the corresponding entity
(3)将每个字符出现与相应实体匹配
Graph creation
图形创建
(1) Construct the full dynamic heterogenous graph
(1)构造完整的动态异构图
(2) Derive from it multiple graphs of interest (dynamic entity graph, static entity graph…)
(2)从中派生多个感兴趣的图(动态实体图,静态实体图…)
(3) Visualisation with a special software called
(3)使用称为
gephi
杰斐
Graph Analysis — with networkx
图分析 - 使用networkx
(1) Character importance
(1)性格重要性
(2) Structural change in the narrative
(2)叙述结构的变化
(3) Community detection
(3)社区发现
(4) Books’ writing style comparisons
(4)书籍写作风格比较
(5) Summarisation of a book via the graph’s k-core
(5)通过图的k核汇总一本书
(6) Other applications: relation prediction, genre/author/style classification…
(6)其他应用:关系预测,体裁/作者/风格分类…
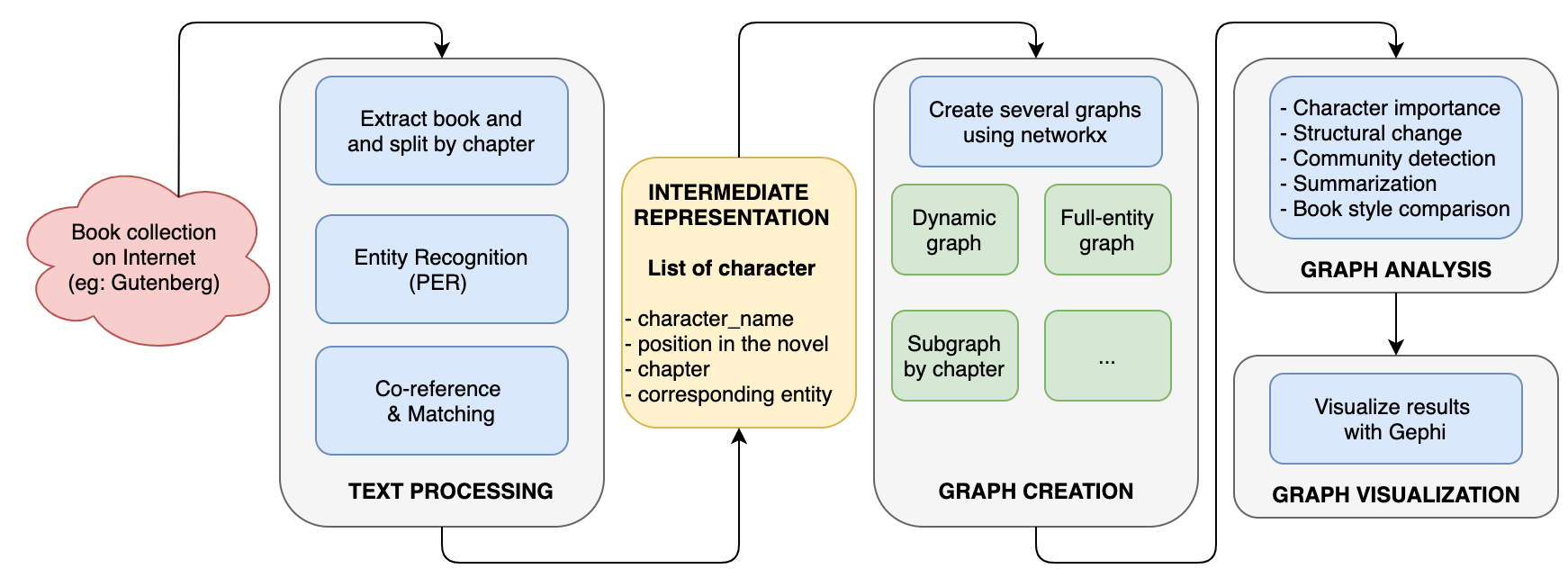
For more details about the Preprocessing and Graph Creation sections, you can refer to the original paper, where the code is available on Github. But feel free to skip them if the Graph Analysis part is the only thing you are interested in.
有关“预处理” 和“图形创建” 部分的 更多详细信息 ,您可以参考原始 论文 ,该代码在 Github 上可用 。 但是,如果 您仅对 “图形分析” 部分感兴趣,请 随时跳过它们 。
前处理 (Preprocessing)
In order to create a sort of dynamic character graph, we first need to do some NLP on the raw text. The pre-processing module aims to capture all occurrences of all characters in the book, under their different forms; and store the following information:
为了创建一种动态字符图,我们首先需要对原始文本进行一些NLP。 预处理模块旨在捕获书中所有字符以不同形式出现的所有情况 ; 并存储以下信息:
character_name: [str] name of character (eg: ‘Harry’) pos: [int] number of tokens since beginning (eg: 30490) chapter: [int] index of the chapter (eg: 2) entity : [str] corresponding entity (eg: ‘HARRY POTTER’)
character_name:[str]字符名称(例如:'Harry')pos:[int]自开始(例如:30490)章节以来的令牌数量:[int]该章节的索引(例如:2)实体:[str]对应实体(例如:“ HARRY POTTER”)
We retrieve the book from the Internet, in .txt format, using Project Gutenberg library and split it by chapter. Why ? Because the chapter is a unit of interest for the plot evolution.
我们使用Project Gutenberg库 从Internet上以.txt格式检索这本书,并按章节进行拆分。 为什么呢 因为该章是情节演变的兴趣单元。
We run BERT NER — the pre-trained google BERT fine tuned for entity recognition tasks — on the whole book, chapter by chapter, to detect all character occurrences. We only keep ‘PER’ entities (persons), which we store together with their position in the text and the corresponding chapter index.
我们在整本书中逐章地运行 BERT NER (针对实体识别任务进行了微调的预训练Google BERT),以检测所有字符出现。 我们仅保留“ PER”实体(人员),并将它们在文本中的位置以及相应的章节索引存储在一起。
We match each character mention to a unique entity (= protagonist). A social network relates entities, and thus it is a crucial step to group all the co-referents together. For instance, regarding Harry Potter, we would like Harry, Potter, Mr. Potter, H. Potter to be linked to a single entity. In this case HARRY POTTER. We follow the strategy developed by M.Ardanuy and C.Sporleder in [1] for this character resolution task. This is been done in 4 steps:
我们将每个提及的角色匹配到一个唯一的实体 (=主角)。 社交网络与实体相关,因此将所有共同对象归为一组是至关重要的一步。 例如,关于“哈利·波特”,我们希望将“哈利·波特”,“波特先生”,“ H·波特”链接到一个实体。 在这种情况下,哈里·波特(HARRY POTTER)。 我们遵循M.Ardanuy和C.Sporleder在[1]中为该字符解析任务开发的策略。 这是通过4个步骤完成的:
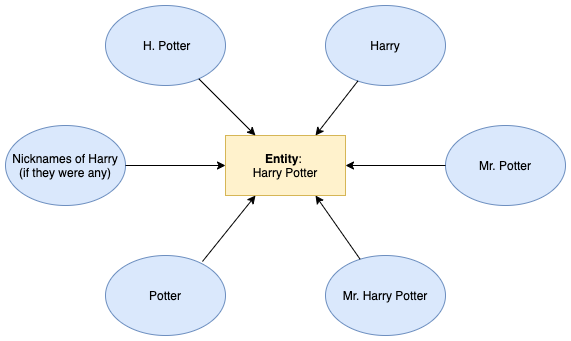
Human name parsing: use NameParser framework to parse a character name into a generic structure. For instance, Mr. Harry Potter will be parsed into : {title: Mr, first: Harry, last: Potter}
人名解析:使用NameParser框架将字符名称解析为通用结构。 例如,哈利·波特先生将被解析为:{标题:先生,第一个:哈利,最后一个:波特}
Gender assignation. Determine, if possible, the genre of the character. Here we simply assess it from the title and from the first name, using databases. For example, if the title is ’Mr’, the genre is ‘Male’.
性别分配 。 尽可能确定角色的类型。 在这里,我们只是使用数据库根据标题和名字对其进行评估。 例如,如果标题是“先生”,则类型是“男”。
Matching algorithm: maps each occurrence to an entity, grouping co-referents together. Without delving too much into details, let’s say that we first consider all occurrences showing a title, a first name and a last name — occurrences with the most complete form. If no existing entity has the occurrence’s first name, last name and eventually genre, we create a new one. We proceed as such for all mentions showing the same structure, and then focus on remaining ones that display first name and a last name only. Again, we repeat the same process, matching a new mention to an existing entity if first name and last name are the same. Next comes occurrences with title and first name, title and last name and finally first or last name. As a result, since the entity HARRY POTTER is conceived at the very beginning (by Mr. Harry Potter), Harry or Mr. Potter are directly associated to this entity.
匹配算法:将每个匹配项映射到一个实体,将辅助对象分组在一起。 在不过多研究细节的情况下,假设我们首先考虑所有显示标题,名字和姓氏的事件-具有最完整形式的事件。 如果没有现有实体具有该事件的名字,姓氏和最终类型,我们将创建一个新实体。 因此,对于所有提到的显示相同结构的内容,我们将继续进行,然后集中讨论仅显示名字和姓氏的其余部分。 同样,我们重复相同的过程,如果名字和姓氏相同,则将新提及内容与现有实体匹配。 接下来出现的是标题和名字,标题和姓氏,最后是姓氏或名字。 结果,由于实体HARRY POTTER最初是由(Harry Potter先生)构思的,因此Harry或Potter先生与该实体直接相关。
Refined matching process: considers nicknames, initials and small mistakes of the NER model. Indeed, in the current framework, H. Potter and Duddy are distinct entities and are not mapped to Harry Potter and Dudley Dursley, as we would like them to. We solved this issue by specifying carefully targeted rules to deal with initials and by using an existing nicknames database.
完善的匹配过程:考虑NER模型的昵称,缩写和小错误。 实际上,在当前框架中,H。Potter和Duddy是不同的实体,并未像我们希望的那样映射到Harry Potter和Dudley Dursley。 我们通过指定针对性强的规则来处理姓名首字母以及使用现有的昵称数据库来解决了这个问题。
图创建 (Graph Creation)
主动态图 (Main Dynamic Graph)
We now tackle a crucial point of our approach: how can we create a graph that keeps temporal information about the narrative’s dynamics ? We have chosen to build a graph using the information stored above, and presenting the following structure.
现在,我们解决了方法的关键点: 如何创建一个图表,以保留有关叙事动态的时间信息? 我们选择使用上面存储的信息来构建图,并提出以下结构。
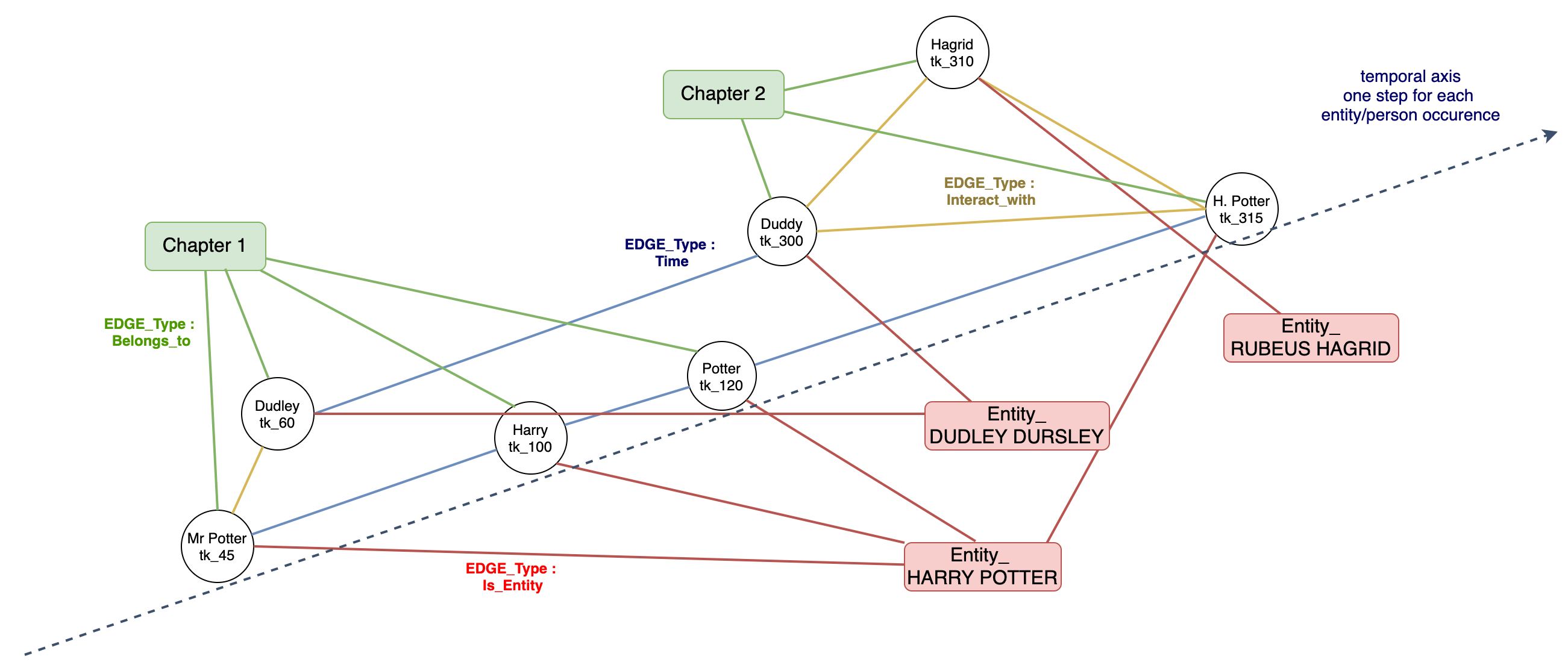
Our full graph is composed of 3 nodes types :
我们的完整图由3个节点类型组成:
occurrence-node : tuple (character name, occurrence position)
出现节点 :元组(字符名称,出现位置)
chapter-node : index of a chapter
章节节点 :章节索引
entity-node : string representing the entity
实体节点 :代表实体的字符串
There are also 4 different edge types:
还有4种不同的边类型 :
belong-to edge : connect an occurrence node to a chapter node if the occurrence is located in chapter node idx.
属于边缘 :如果事例位于章节点idx中,则将事例节点连接到章节点。
is-entity edge : connect an occurrence node to an entity node if the character name of the occurrence has been matched to the corresponding entity.
is-entity edge :如果事件的字符名称已与相应实体匹配,则将一个事件节点连接到实体节点。
interact-with edge : connect two occurrence nodes if they interact together and are not connected to the same entity node. We create an interaction edge between two occurrence nodes that correspond to different entities if their positions in the novel are not more than 20 token distant. This is exactly the idea of using a co-occurrence sliding window except that in our case, it is more straightforward to compute. Note that an edge between two characters doesn’t necessarily mean that they are friends — it simply means that they interact, speak of one another, or are mentioned together.
与边缘交互 :如果两个出现节点相互作用在一起且未连接到同一实体节点,则将其连接。 如果它们在小说中的位置不超过20个令牌距离,我们将在两个对应于不同实体的出现节点之间创建一个交互边。 这就是使用共现滑动窗口的想法,除了在我们的例子中,它更容易计算。 请注意,两个字符之间的边缘并不一定意味着他们是朋友-只是意味着它们相互作用,彼此交谈或一起被提及。
time edge : connect two occurrence nodes that are connected to the same entity if there does not exist another occurrence node connected to this entity which is located in between these two, in the novel.
时间边缘 :在小说中,如果不存在连接到同一实体的另一个出现节点,则不存在连接到该实体的另一个出现节点,该出现节点位于这两个实体之间。
The main interest of this full graph is we do not lose any information in the process: in fact we simply transform the occurrence list into a graph structure that will be easier to manipulate.
此完整图的主要兴趣在于,我们在此过程中不会丢失任何信息:实际上,我们只是将出现列表转换为易于操作的图结构。
子图 (Subgraphs)
For some applications, it is useful to take some modified versions of this full dynamic graph.
对于某些应用程序,获取此完整动态图的某些修改版本很有用。
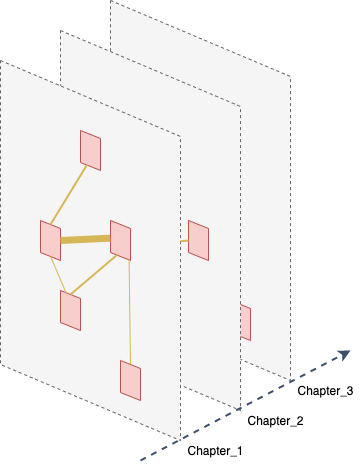
The entity graph, in particular, is useful for some global analysis of the book. It is a static collapsed version of the full graph that simply contains one type of node: entity-node and one type of edge: interact-with, which is weighted by the number of interactions between two entities. It is often interesting to cut it by chapter to embed temporal information. We thus collapse the dynamic graph into a sequence of entity graphs, one for each chapter.
实体图尤其对于本书的某些全局分析很有用。 它是完整图的静态折叠版本,其中仅包含一种类型的节点: 实体节点和一种类型的边线: 与之交互, 由两个实体之间的互动次数加权。 将其按章切割以嵌入时间信息通常很有趣。 因此,我们将动态图折叠为一系列实体图 ,每章一个。
We could extend this view ever further and produce a fine-grained dynamic entity interaction graph where the timeline is simply the number of token so far in the text, ie: the ’time’ goes from 0 to number of tokens in the novel.
我们可以进一步扩展此视图,并生成细粒度的动态实体交互图 ,其中时间线只是文本中到目前为止的令牌数量,即:“时间”从0到小说中的令牌数量。
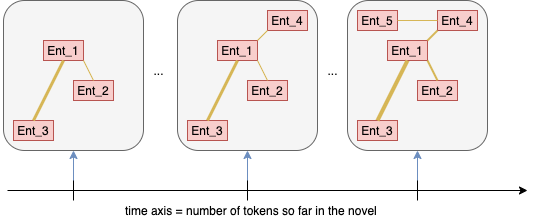
图分析 (Graph analysis)
角色重要性 (Character importance)
The first step of the analysis, and probably the most informative one, is to spot the most important characters of the book. To do so, we compute for each node a centrality measure in the book’s entity graph (static or dynamic), representative of the character’s importance in the narrative.
分析的第一步(也许是最有帮助的一步)是发现本书最重要的特征 。 为此,我们在书的实体图中(静态或动态)为每个节点计算一个中心度度量,代表角色在叙事中的重要性。
Several measures like degree centrality, betweenness centrality or pagerank centrality are available. They enable to capture different variants of importance. Indeed, a person can play a central role in multiple ways. She could be well connected, be centrally located, or be uniquely positioned to help disperse information or influence others. Refer to this resource for more information about those metrics. In short:
可以使用诸如度数中心度,中间度中心度或页面等级中心度等几种度量。 它们可以捕获不同的重要性变量。 确实,一个人可以通过多种方式发挥核心作用。 她可以很好地联系在一起,位于中心位置或处于独特位置,以帮助传播信息或影响他人。 有关这些指标的更多信息,请参考此资源 。 简而言之:
Degree Centrality: Do you have many connections?
学位中心 :您有很多联系吗?
Weighted Degree Centrality: Do you have many interactions?
加权度中心度 :您是否有很多互动?
Eigenvector Centrality: Do you have many connections to important people?
特征向量中心性 :您与重要人物有很多联系?
PageRank Centrality: Do you have many interactions with important people?
PageRank中心性 :您是否与重要人物互动?
Betweenness Centrality: Do you help to connect different parts of the network?
中间性中心 :您是否有助于连接网络的不同部分?
Here, we favoured Pagerank centrality, which, for the story, was used by Google to sort the web pages proposed to you. We obtain the following results:
在这里,我们赞成Pagerank的中心性,就故事而言,它被Google用来对提供给您的网页进行排序。 我们获得以下结果:
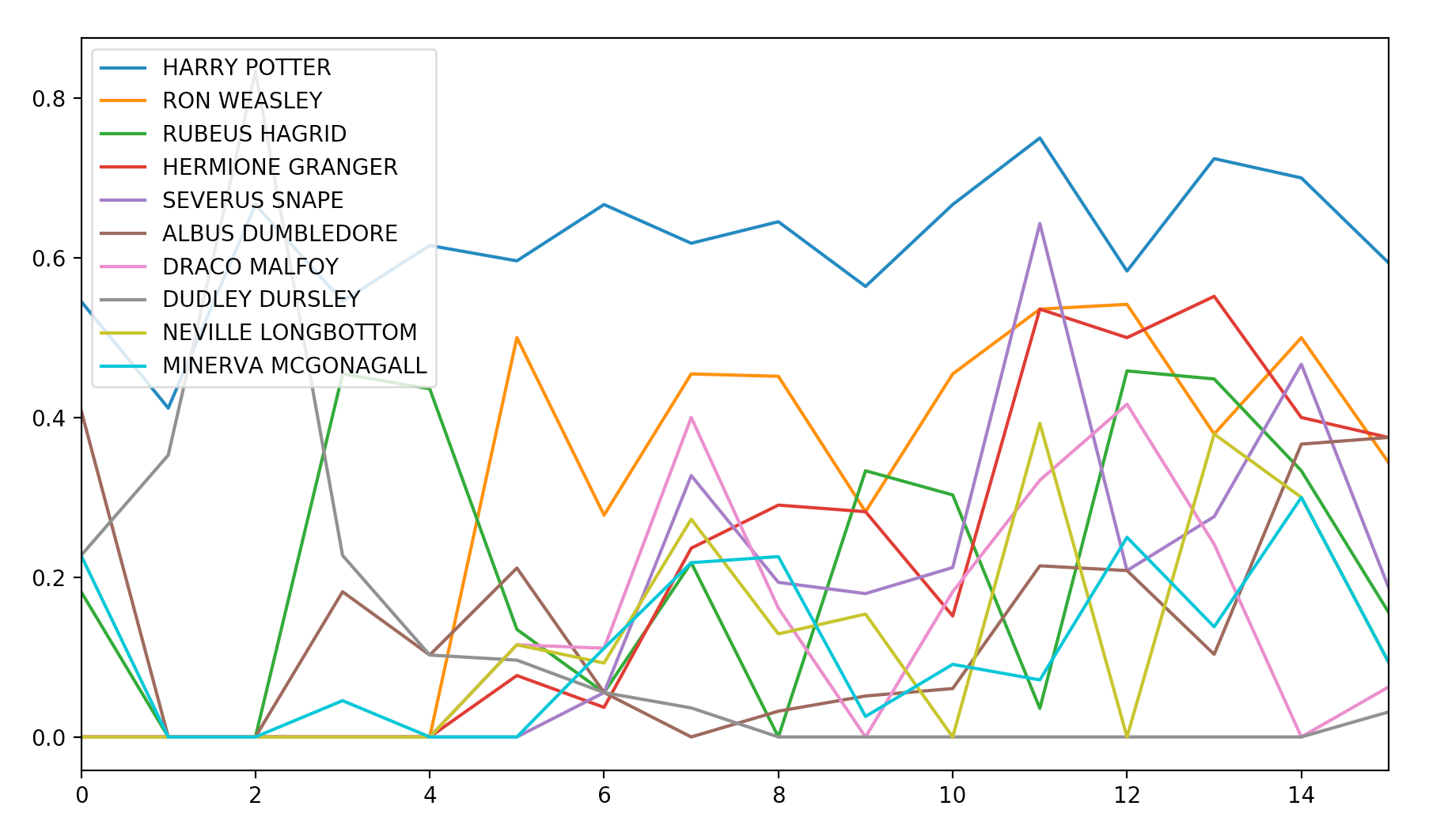
Results Description: after computing the 10 most important characters on the full static entity graph, we follow the centrality metric evolution across chapters, meaning on the dynamic entity graph. The results observed are extremely consistent with our knowledge of the book, I believe you would agree. Obviously, Harry is the most central character all along. It is uniquely positioned in the network and seems to be connected to everyone. Although it could seem surprising at first, Voldemort and Professor Quirrell are left out of this top 10 but are in fact still found to be important (ranked 11th and 13th). It makes sense given the great place given to the description of Harry’s daily routine at Hogwards in this first book, where Voldemort is not so often mentioned. Something even more striking is the sudden surge in pagerank centrality of most characters from chapter 5, which coincides with Harry’s arrival at Hogwards. While some characters like Ron immediately gain great importance, some others like Hermione progressively achieve it. Note that this passage also coincides with the disappearance of some influential characters like Dudley Dursley.
结果说明 :在计算完完整的静态实体图上的10个最重要的字符之后,我们遵循各章中中心性度量的演变,即在动态实体图上。 观察到的结果与我们对这本书的了解极为一致,我相信您会同意的。 显然,哈利一直是最核心的角色。 它在网络中的位置非常独特,似乎已连接到每个人。 尽管起初看起来似乎令人惊讶,但伏地魔和基雷尔教授被排除在前十名之外,但实际上仍然很重要(排名第11和第13)。 鉴于在第一本书中对哈利在霍格沃德日常生活中的日常描述的重要位置,这是很有意义的,在这本书中很少经常提到伏地魔。 更令人震惊的是,第5章中大多数角色的页面排名中心性突然激增,这与哈利到达霍格沃德(Hogwards)相吻合。 尽管像Ron这样的某些角色立即变得非常重要,但像Hermione这样的其他角色却逐渐实现了这一点。 请注意,这段文字还与一些颇有影响力的人物(例如达德利·达斯利)的消失相吻合。
In the next subsection, we check if this structural change in the narrative is confirmed by the evolution of other graph properties. This would enable to generalize our capability to spot a book’s main plot developments.
在下一个小节中 ,我们检查叙述中的这种结构变化是否被其他图属性的演变所证实。 这将使我们有能力发现书籍的主要情节发展。
结构变化 (Structural change)
We have selected a few properties, both static and dynamic, that could help us gain a better understanding of the plot evolution. We explain some of them:
我们选择了一些静态和动态属性,可以帮助我们更好地了解绘图的演变。 我们解释其中的一些:
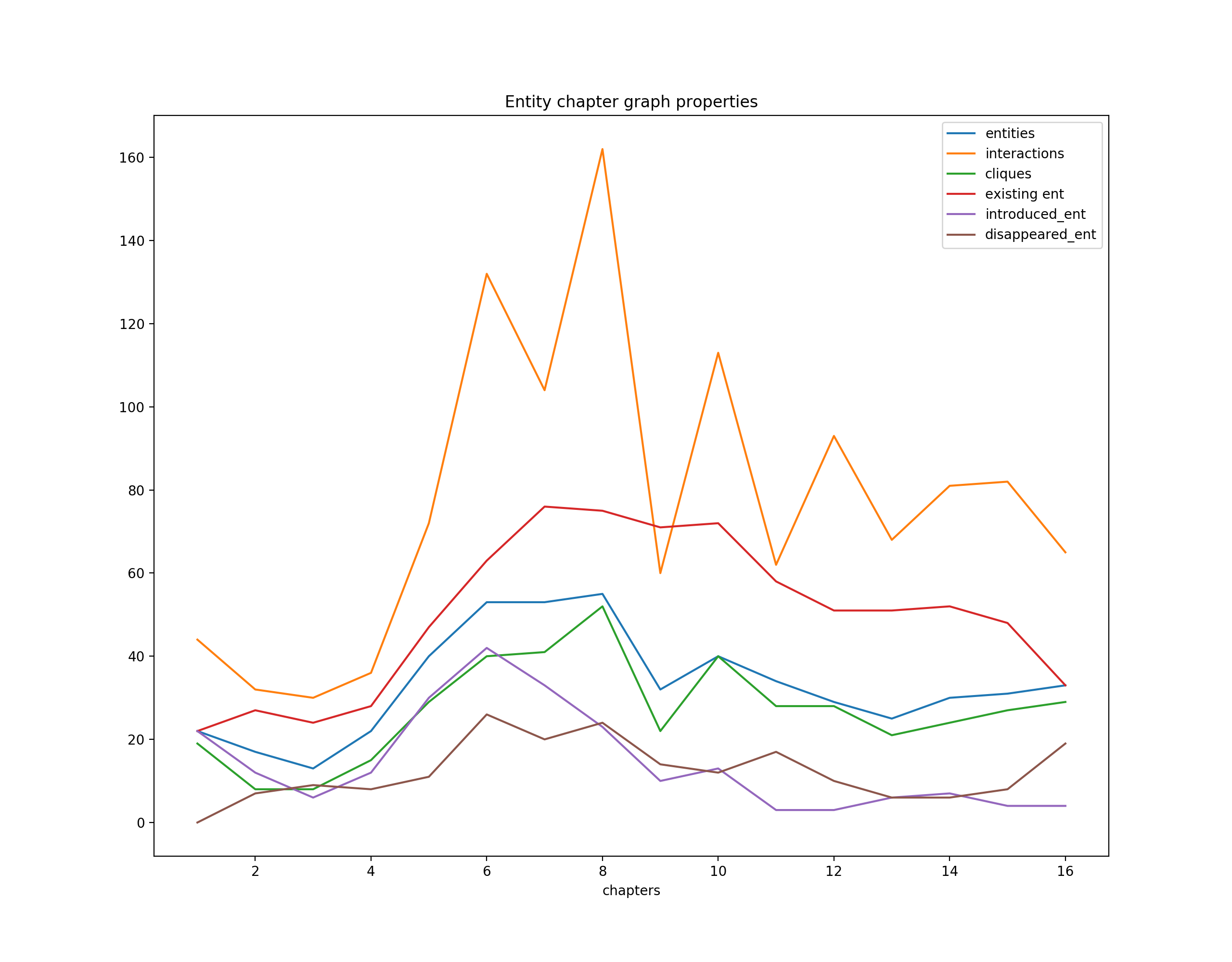
→ Number of nodes/edges/existing characters give precious clues about the story’s structure, the book’s type and the writing style of the author. On the other hand, the number of characters that disappear/are introduced give more dynamic insights regarding the plot’s development. It becomes easy to notice when the main character Harry arrives in new places. Observing the plot below, the surge in interactions and protagonists introduction confirm what was inferred in the previous section, as it corresponds to Harry’s arrival in Hogwards. Comparing this graph with other books allows us to differentiate between two genres, two authors…
→ 节点/边缘/现有字符的数量为故事的结构,书的类型和作者的写作风格提供了宝贵的线索。 另一方面, 消失/引入的角色数量为剧情的发展提供了更多动态的见解。 当主角哈利到达新地方时,很容易注意到。 观察下面的情节 ,互动和主角介绍的激增证实了上一节中的推断,因为这与哈利到达霍格沃德有关。 将此图与其他书籍进行比较,可以区分两种类型,两名作者……
→ Cliques related properties (clique= maximum connected subsets of nodes) are features that provide information about the density of the graph, meaning on the relations between characters and their evolution across the book. Looking for instance at the largest clique in each chapter enables to see which characters interact and what the global plot is about. Is it about the Dudleys, teacher-student interactions or Harry-Voldemort-Dumbledore ? Investigating the cosine similarity of the cliques could also turn out to be interesting to see if the action often turn around the same characters (as in HP) or if it often changes (as in GOT, LOTR). Furthermore, we can look at strongest edges or compare cliques with the graph k-core to see how much space the clique takes inside the chapter. Finally, using our dynamic graph, we can even conduct this analysis at a smaller scale, inside chapters.
→ 与团相关的属性 (clique =节点的最大连接子集)是提供有关图密度的信息的功能,即有关字符之间的关系及其在整本书中的演变的信息。 例如,查看每章中最大的集团,可以查看哪些角色进行交互以及总体情节是什么。 是关于达德利人,师生互动还是哈利-伏地魔-邓布利多? 调查这些派系的余弦相似度也可能很有趣,以查看动作是否经常转过相同的字符(如HP)或是否经常变化(如GOT,LOTR)。 此外,我们可以查看最强边缘或将团体与图表k核进行比较,以查看该团体在本章中占用了多少空间。 最后,使用动态图,我们甚至可以在章节内部以较小的比例进行此分析。

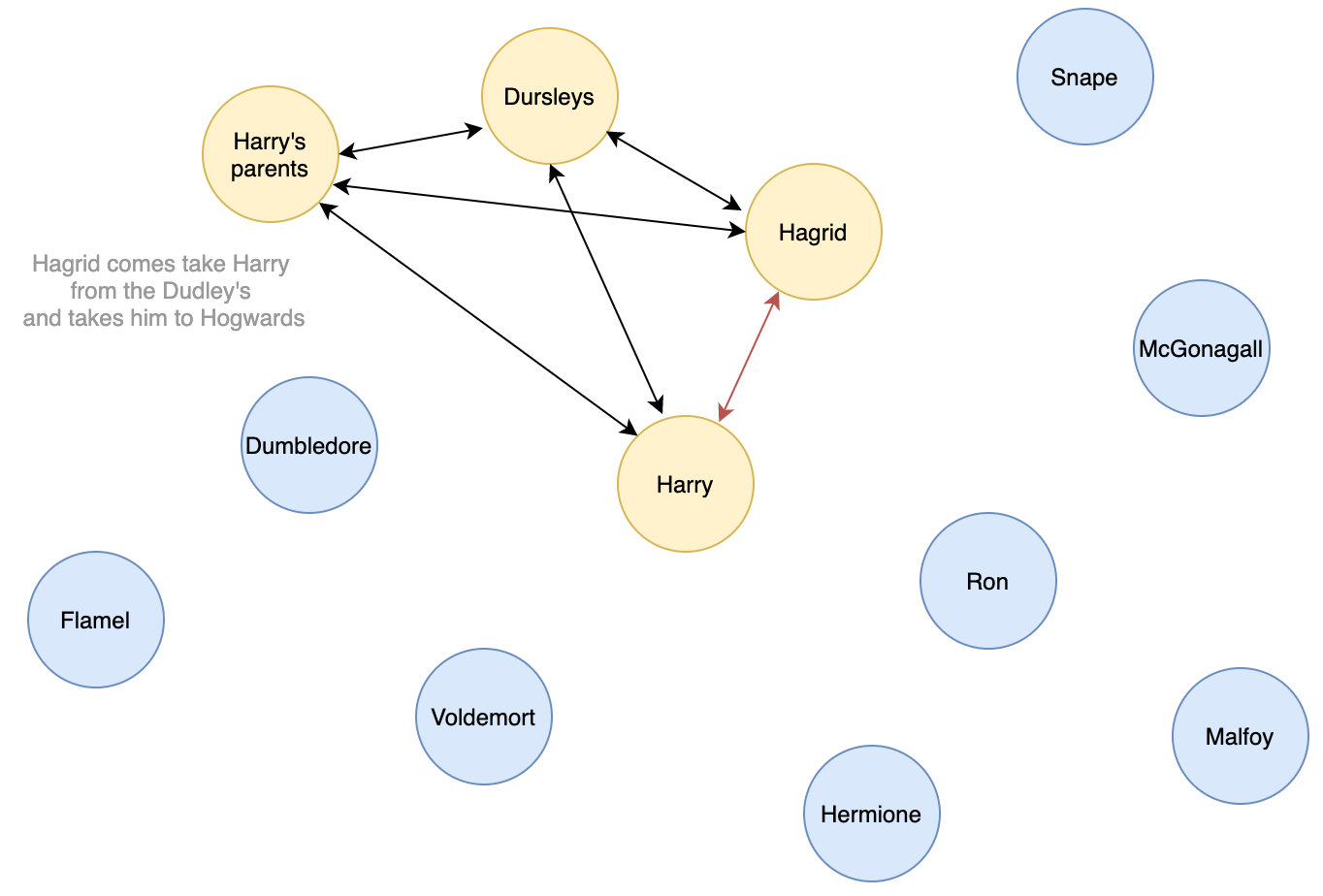
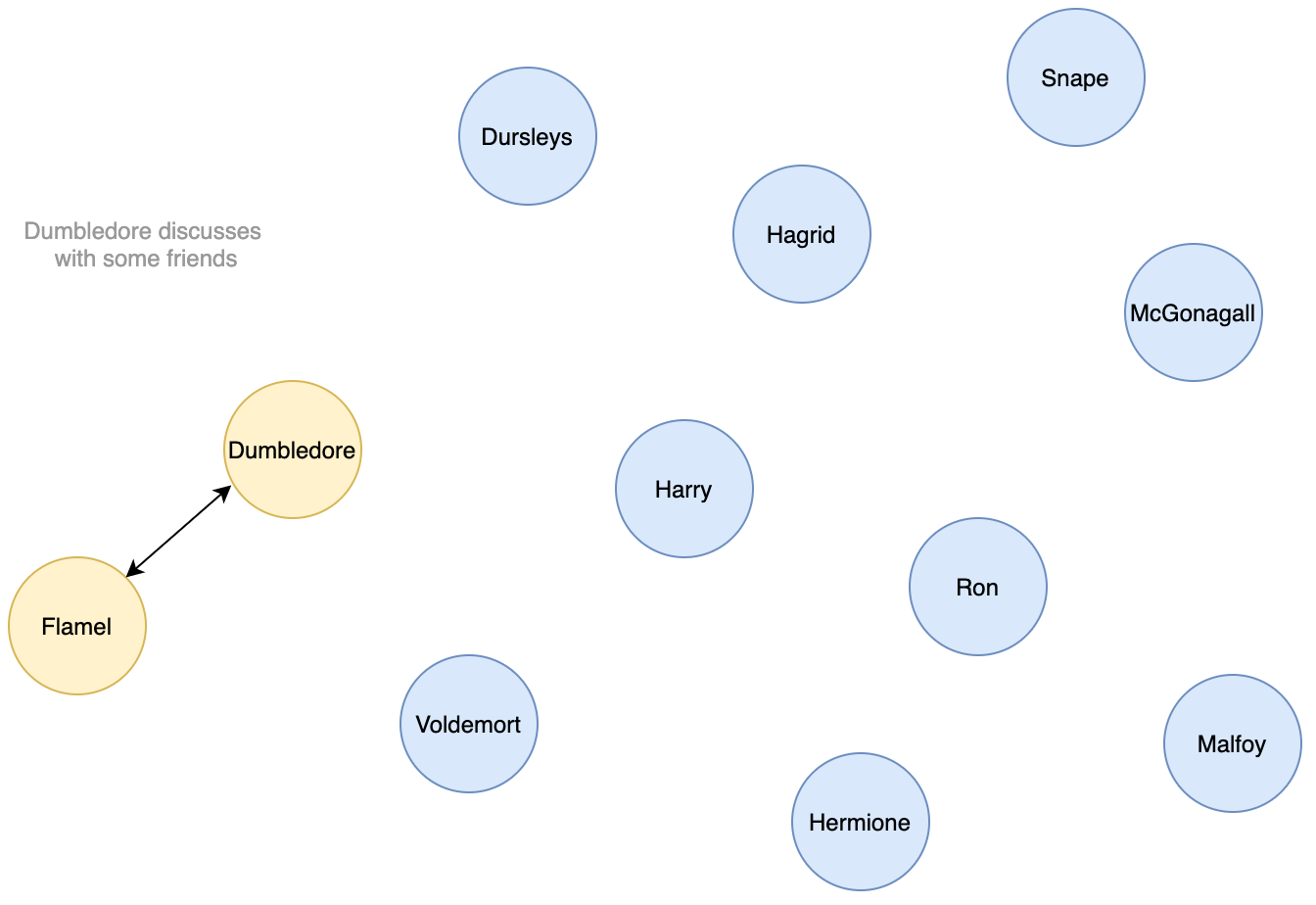
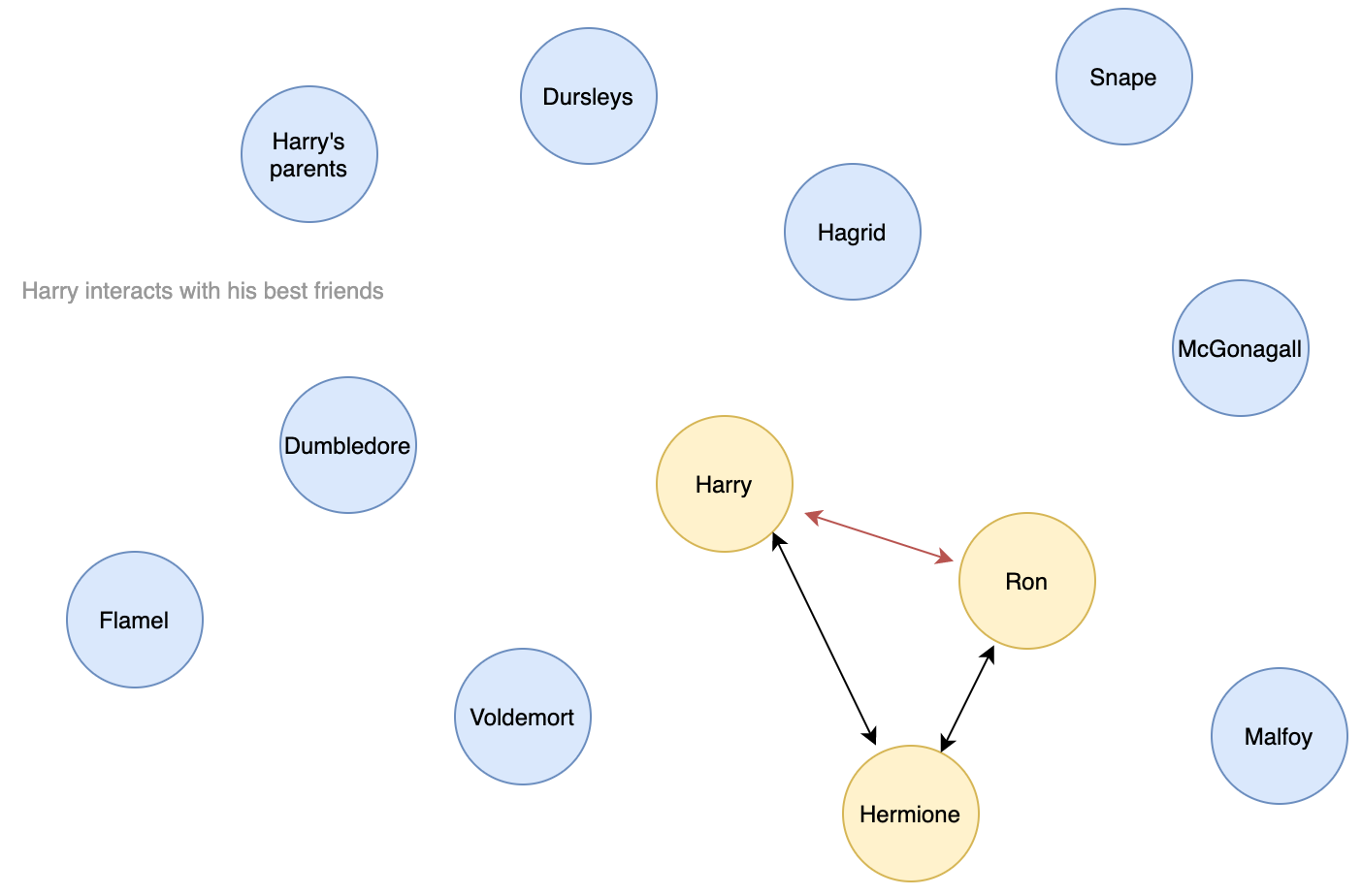
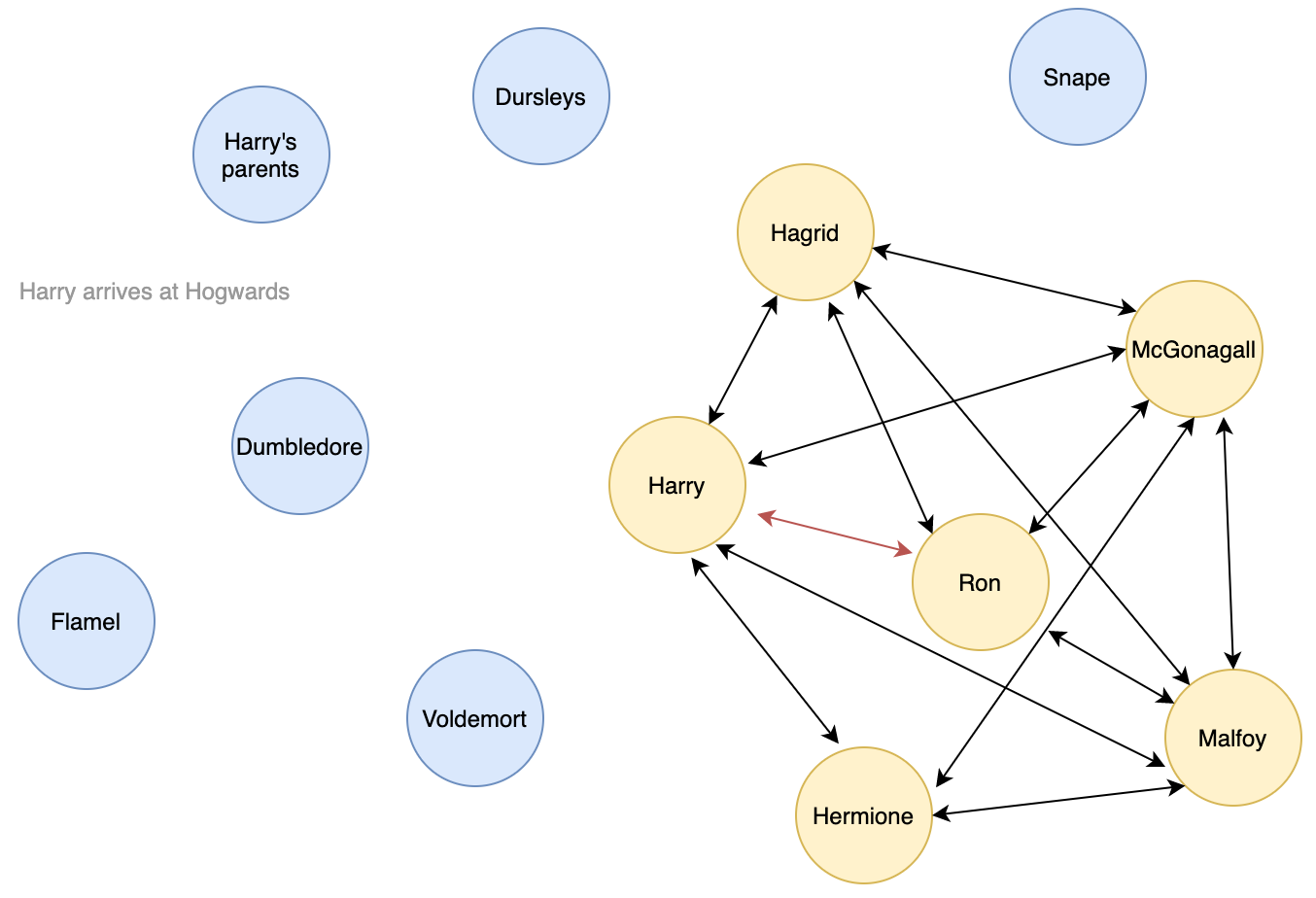
→ Looking at the proportion of important characters in each chapter may help us find what chapters are important in the storyline. It is not the most important features for Harry Potter but for books like LOTR or GOT, it can turn out very helpful as many storylines take place at the same time.
→ 查看每个章节中重要人物的比例可能有助于我们找到故事情节中哪些章节很重要。 对于哈利·波特来说,这不是最重要的功能,但对于LOTR或GOT这样的书,由于许多故事情节在同一时间发生,因此很有用。
→ The difference between the main and second main character importance gives information about the type of book written, is it a one-main character or several-main characters book.
→ 主要字符和第二个主要字符之间的区别提供了有关所写书籍类型的信息,是一本主书本还是几本主书本。
As a side note, bear in mind that we use handcrafted features here, as opposed to recent state-of-the-art approaches in the field of Network Representation Learning. These methods, often part of the Graph Neural Network family, extract graph properties implicitly and thus have the particularity of learning features on their own (using both graph structure and node features). They are used to obtain a vector representation for each node, which is later used in a downstream ML task such as node classification or link prediction. Examples in the everyday life are varied: recommend movies, suggest friends, predict the role of a molecule, answer your questions using a big database stored as a knowledge graph, predict the propagation of a virus…
附带说明一下 ,请记住,这里我们使用手工制作的功能,而不是网络表示学习领域中最新的方法。 这些方法通常是“图形神经网络”系列的一部分,它们隐式提取图形属性,因此具有自己的学习特征(使用图形结构和节点特征)。 它们用于获取每个节点的矢量表示,随后用于下游ML任务(例如节点分类或链接预测)中。 日常生活中的例子多种多样:推荐电影,推荐朋友,预测分子的作用,使用作为知识图存储的大型数据库回答您的问题,预测病毒的传播……
社区检测 (Community detection)
Although HP1 is not the most striking example for this kind of application, as opposed to GOT or LOTR, the complex structure of our network still reflects the interweaving plotlines of the story. Notably, we observe two characteristics found in many real-world networks. First, the network contains multiple denser subnetworks, held together by a sparser global web of edges. Second, it is organised around a subset of highly influential people, both locally and globally.
尽管与GOT或LOTR相比 , HP1不是这种应用程序中最引人注目的示例,但我们网络的复杂结构仍然反映了故事的交织情节。 值得注意的是,我们观察到许多现实网络中发现的两个特征。 首先,该网络包含多个密集的子网,这些子网由稀疏的全局边缘网连接在一起。 其次,它是围绕着本地和全球有影响力的人的一部分组织的。
To quantify these observations using the analytical tools of network science, we proceed to community detection on the static entity graph (or more dynamic versions if desired). More precisely, we apply the Girvan Newman algorithm on a subgraph of the full entity graph obtained by deleting the nodes with too few interactions — fewer than five in our case. In addition to making the graph more readable, it excludes a few fake entities spotted by BERT, and only keep the real ones.
为了使用网络科学的分析工具对这些观察进行量化,我们继续在静态实体图(或者需要时使用更多动态版本)上进行社区检测 。 更确切地说,我们应用Girvan Newman算法 在完整实体图的子图上,该子图是通过删除交互作用太少的节点(在我们的例子中少于五个)而获得的。 除了使图形更具可读性之外,它还排除了BERT发现的一些假实体,只保留了真实的实体。
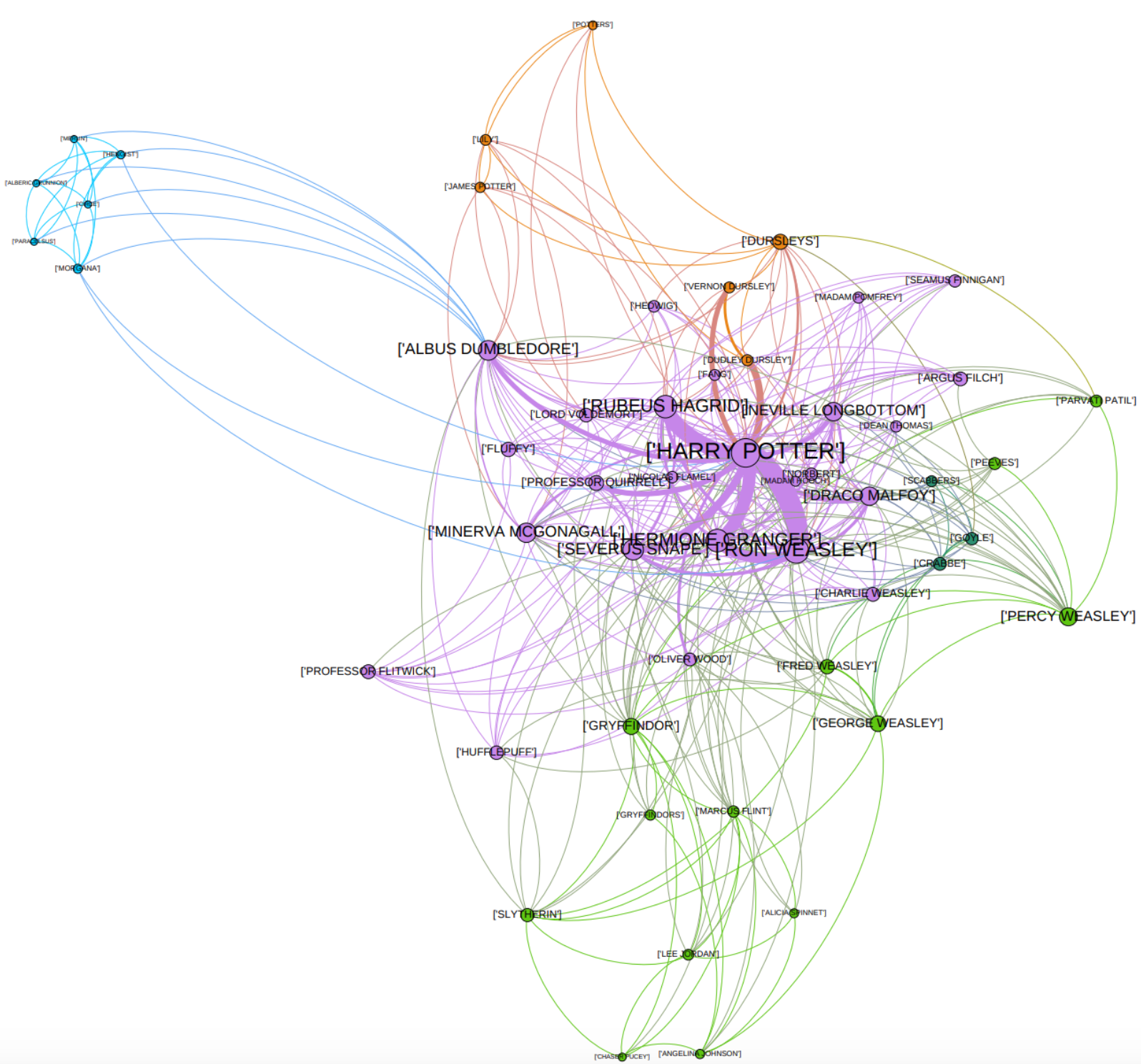
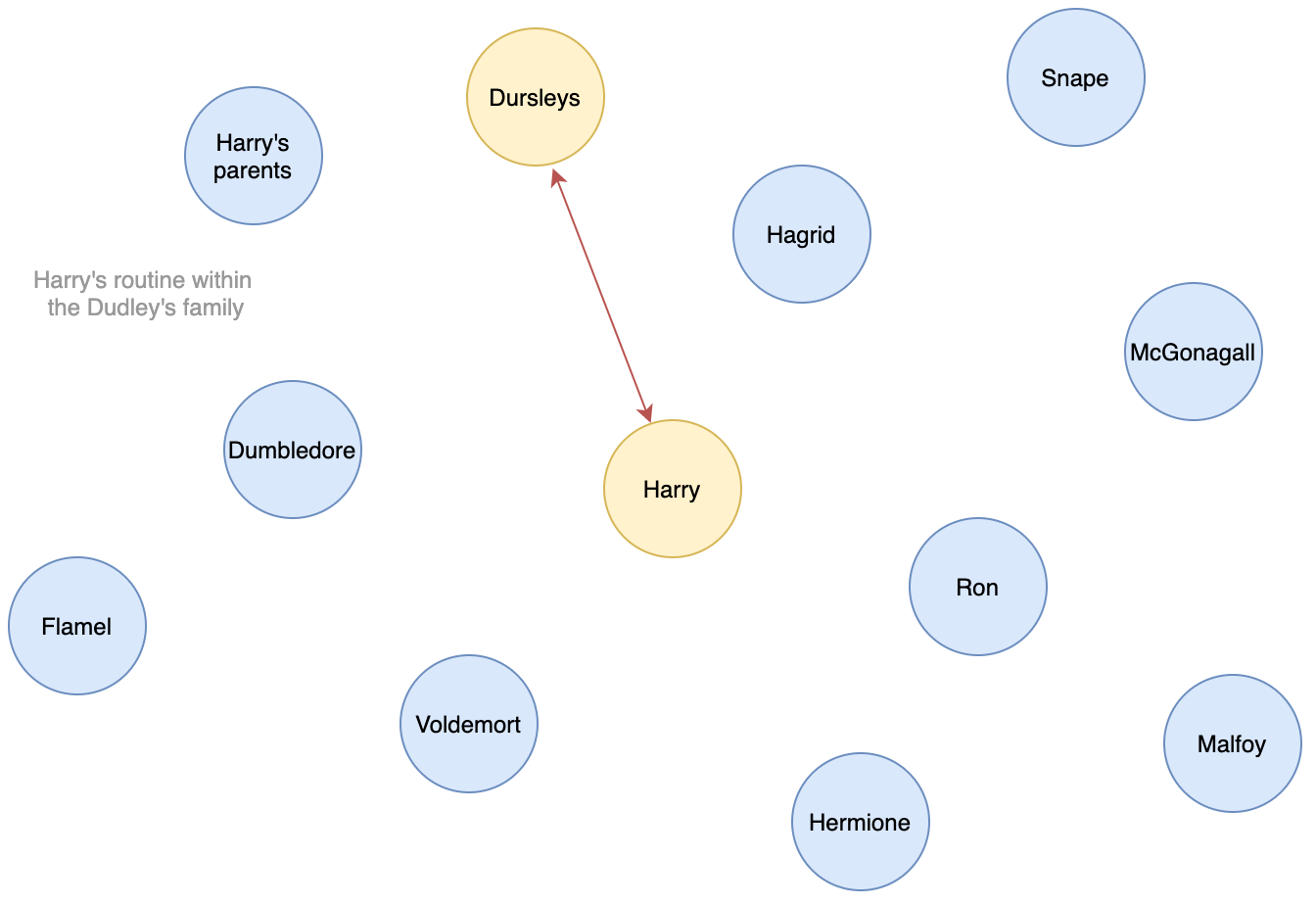
Description: In Harry Potter, we obtain four different communities. One involves Harry’s family, including his true parents and the Dudleys, as well as their entourage. A second one is formed by Dumbledore’s friends, which are a bit outside of the scope of the book’s main plot and are mentioned during one chapter. The members of the third one are related to quidditch: Griffondor’s team, Lee Jordan the speaker, Slytherin and Marcus Flint…. Finally, the last one includes all the main characters of the plot — Harry/Ron/Hermione of course, but also Voldemort/Quirrel/Snape/Dumbledore, as well as Harry’s teachers and fellow students.
描述:在哈利·波特中,我们获得了四个不同的社区。 其中一个涉及哈利的家人,包括他的真正父母和达德利夫妇,以及他们的随行人员。 第二个是由邓布利多的朋友组成的,这些人不在本书主要情节的范围之内,在一章中已提到。 第三个成员与魁地奇有关:格里芬多(Griffondor)的团队,议长李·乔丹(Lee Jordan),斯莱特林(Slytherin)和马库斯·弗林特(Marcus Flint)…。 最后, 最后一个包括剧情的所有主要角色-当然是Harry / Ron / Hermione,还包括Voldemort / Quirrel / Snape / Dumbledore,以及Harry的老师和同学。
Although it is difficult to assess how good this communities are, and that a few other decent options are consistent, I believe the algorithm did a pretty good job.
尽管很难评估该社区的良好程度,并且其他一些不错的选择也是一致的,但我相信该算法做得很好。
这本书的摘要 (Summary of the book)
We now would like to see if it is possible to obtain a graph that would summarise the main interactions between characters, and thus provide in this way a sort of summary of the book.
现在,我们想看看是否有可能获得一个图表,该图表可以总结字符之间的主要相互作用 , 从而以这种方式提供这本书的摘要。
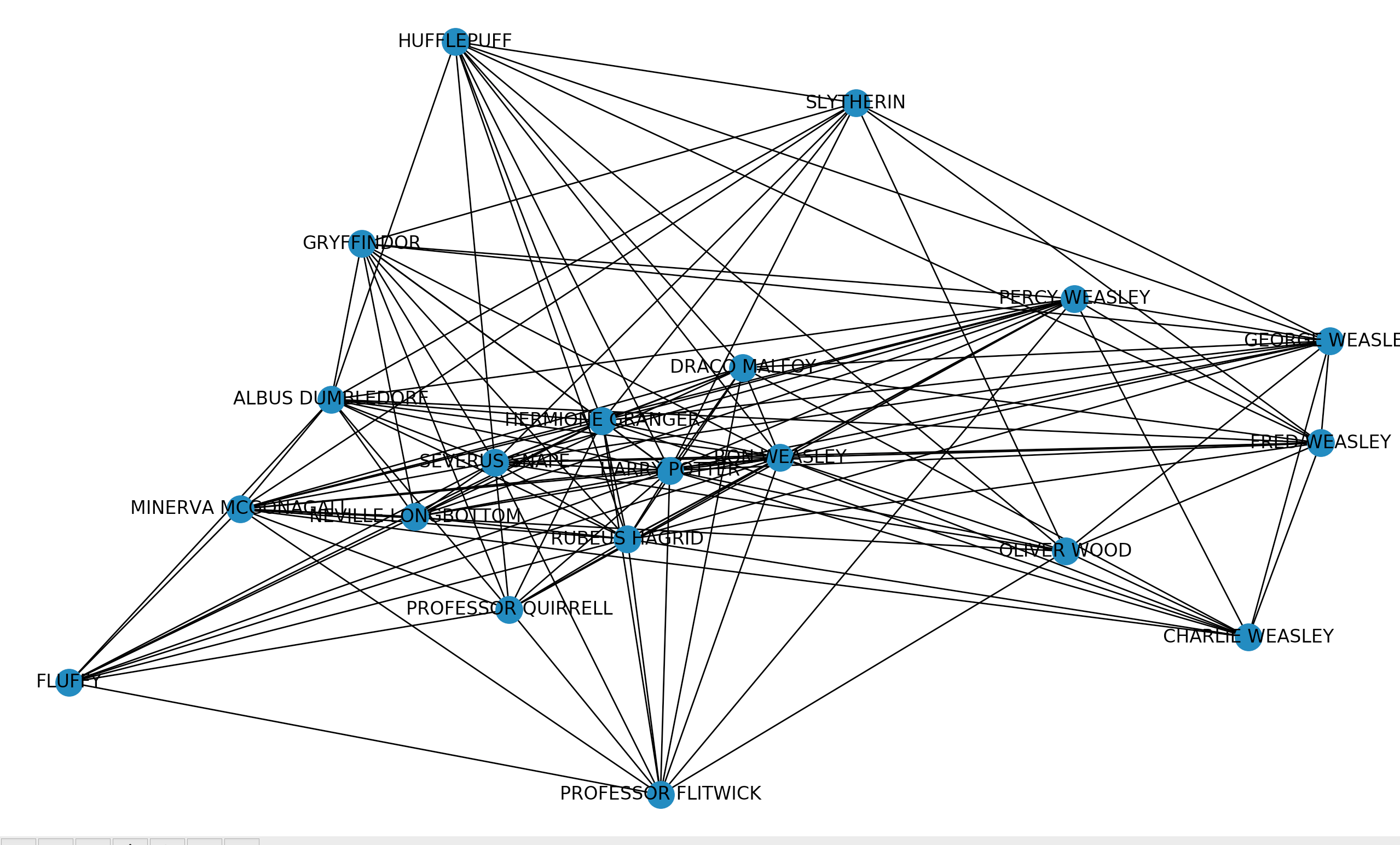
Our intuition entails using the k-core of the static entity graph as a summary of the book. To assess the relevance of this approach, we can easily find a good book summary to compare it with. The idea behind it is that we would like the k-core decomposition of the full graph to be similar to the graph of the summary of the book.
我们的直觉是将静态实体图的k核心用作本书的摘要。 为了评估这种方法的相关性,我们可以轻松找到一份不错的书摘进行比较。 其背后的想法是,我们希望整个图的k-core分解类似于本书摘要的图。
In practice, the two graphs nearly have the same number of nodes, the same connectedness and similar character relations. The entities involved differ only slightly, with an iou score of 0.5 (intersection / union of the two sets of characters). The main differences lie with the inclusion of the Dursleys and the Weasleys. So in conclusion, our graph obtained from the k-core of the full book could be used successfully as a summary of the book’s interactions.
实际上,两个图几乎具有相同数量的节点,相同的连通性和相似的字符关系。 所涉及的实体仅略有不同, 得分为0.5 (两组字符的交集/并集) 。 主要区别在于包含了Dursleys和Weasleys。 因此,总而言之,从整本书的k核获得的图形可以成功地用作该书相互作用的摘要。
与其他书籍的比较 (Comparison with other books)
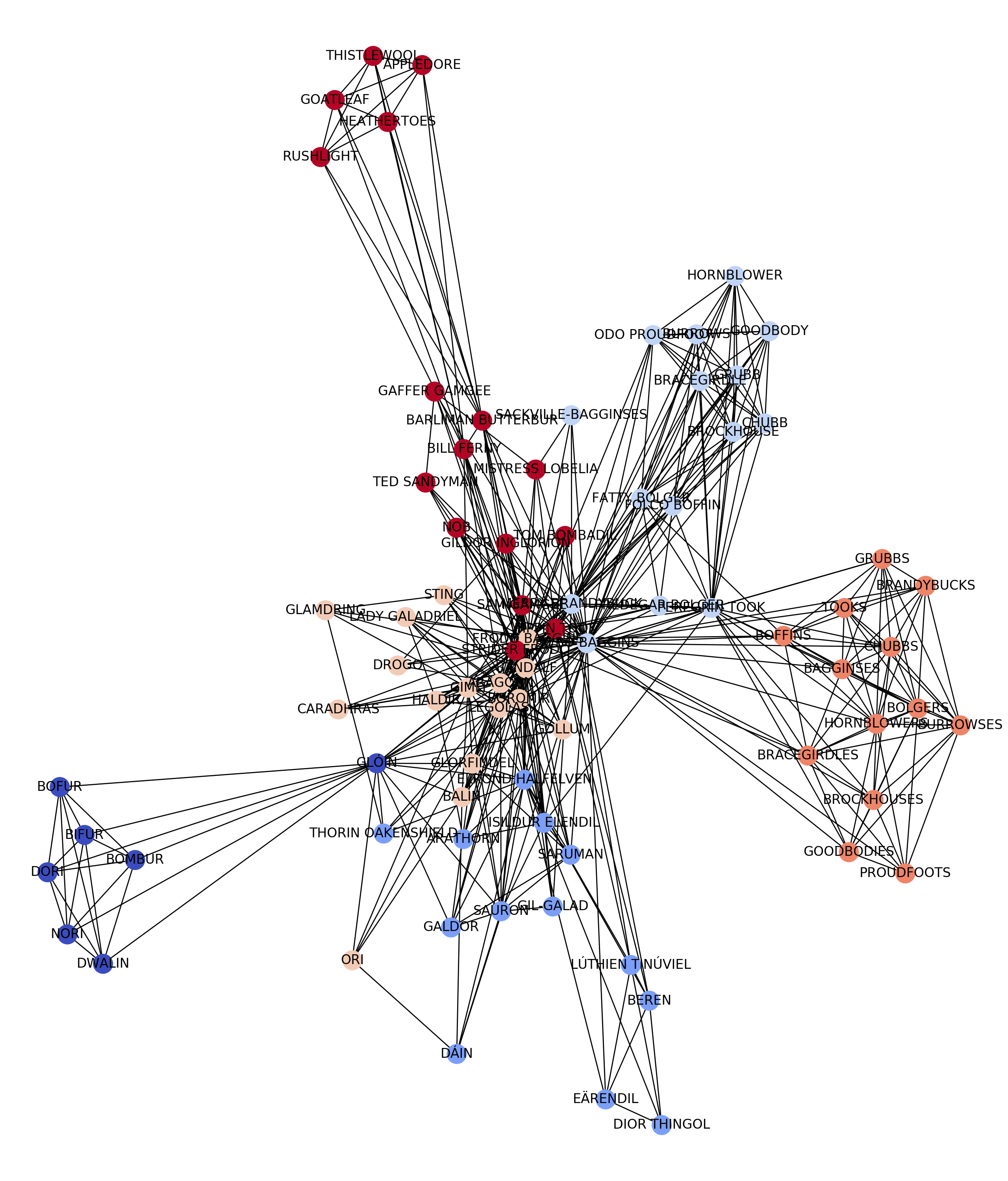
Comparison with Lord of the Rings. We compare the writing style of Harry Potter and the Philosopher’s Stone with Lord of the Rings: The Fellowship of the Ring. More precisely, we proceed to the exact same analysis for both books and search for similarity and differences between them. For instance, although LOTR is much longer, there is a similar number of existing entities and interactions in the two books. However, unlike Harry Potter, LOTR is centered around several characters and several plots.
与指环王比较。 我们将《 哈利·波特与魔法石》和《指环王》的写作风格进行了比较:《指环王》 。 更准确地说,我们对这两本书进行了完全相同的分析,并寻找它们之间的相似点和不同点。 例如,尽管LOTR更长,但两本书中存在相似数量的现有实体和交互。 但是,与《哈利·波特》不同,LOTR围绕着几个角色和多个情节。
Going further, we could compute the embedding of the full dynamic graph (like for graph classification in the field of network representation learning — resource) and calculate the distance between the two graphs’ embeddings. It would allow everyone to see which books are very similar. Note that it would be relevant only if more than two books are processed (not the case here) — in order to have an idea of the order of magnitude for the metric.
更进一步 ,我们可以计算完整动态图的嵌入(如网络表示学习领域中的图分类- 资源 ),并计算两个图的嵌入之间的距离。 它将使每个人都能看到哪些书籍非常相似。 请注意,只有在处理了多于两本书的情况下才有意义(此处不是这种情况),以便了解度量的数量级。
结论 (Conclusion)
In this post, we constructed and analysed a dynamic version of a novel’s social character network. We first processed the book’s textual content — extracting all character occurrences using BERT NER and placing a special emphasis on co-referencing to obtain graphs as accurate as possible. We then created a dynamic heterogeneous graph framework that embeds a time dimension into our network, and focused on five different tasks: character importance, structural change, community detection, graph summarisation and books comparison. Conducting them gave us precious information about the book’s plot, the author’s style, differences with other books’ writing scheme, characters (importance, relations, role, main interactions, etc.).
在这篇文章中,我们构建并分析了小说的社交角色网络的动态版本。 我们首先处理了本书的文字内容-使用BERT NER提取所有出现的字符,并特别强调共参考以获取尽可能准确的图形。 然后,我们创建了一个动态的异构图形框架,该框架将时间维度嵌入到我们的网络中,并专注于五个不同的任务:角色重要性,结构变化,社区检测,图形摘要和书籍比较。 进行这些活动可以为我们提供有关这本书的情节,作者的风格,与其他书籍写作方式的差异,人物(重要性,关系,角色,主要互动等)的宝贵信息。
Our network analysis confirmed some expectations and provided new insights into the richly imagined book Harry Potter and the Philosopher’s Stone. Note that we have considered a fanciful application of network science to give an enticing taste of its capabilities. Other related tasks include clustering of novels, predicting the genre, the author or even new character interactions. More generally, more serious applications abound, and network science promises to be invaluable in understanding our modern networked life.
我们的网络分析证实了一些期望,并提供了对丰富想象的《 哈利·波特与魔法石》的新见解。 请注意,我们已经考虑了网络科学的一种奇特应用,以使人对其功能产生诱人的味道。 其他相关任务包括小说的聚类,预言类型,作者甚至新角色的互动。 更广泛地讲,更严肃的应用比比皆是,网络科学有望在理解我们现代的网络生活中发挥无价的作用。
复杂网络 社交网络


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









