





随机森林 极限随机森林
One of the most deceptively obvious questions in machine learning is “are more models better than fewer models?” The science that answers this question is called model ensembling. Model ensembling asks how to construct aggregations of models that improve test accuracy while reducing the costs associated with storing, training and getting inference from multiple models.
在机器学习中,最具有欺骗性的显而易见的问题之一是“更多的模型胜于更少的模型?” 回答这个问题的科学称为模型集成 。 模型集成询问如何构建模型的聚合,以提高测试准确性,同时降低与存储,训练和从多个模型进行推断相关的成本。
We will explore a popular ensembling method applied to decision trees: Random Forests.
我们将探索一种适用于决策树的流行合奏方法: 随机森林。
In order to illustrate this, let’s take an example. Imagine we’re trying to predict what caused a wildfire given its size, location, and date.
为了说明这一点,让我们举一个例子。 想象一下,鉴于其大小,位置和日期,我们正在尝试预测导致野火的原因。

The basic building blocks of the random forest model are decision trees, so if you want to learn how they work, I recommend checking out my previous post. As a quick refresher, decision trees perform the task of classification or regression by recursively asking simple True or False questions that split the data into the purest possible subgroups.
随机森林模型的基本构建模块是决策树,因此,如果您想了解它们的工作原理,建议您查阅我以前的文章 。 作为快速更新,决策树通过递归询问简单的True或False问题来执行分类或回归的任务,这些问题将数据分为最纯净的子组。
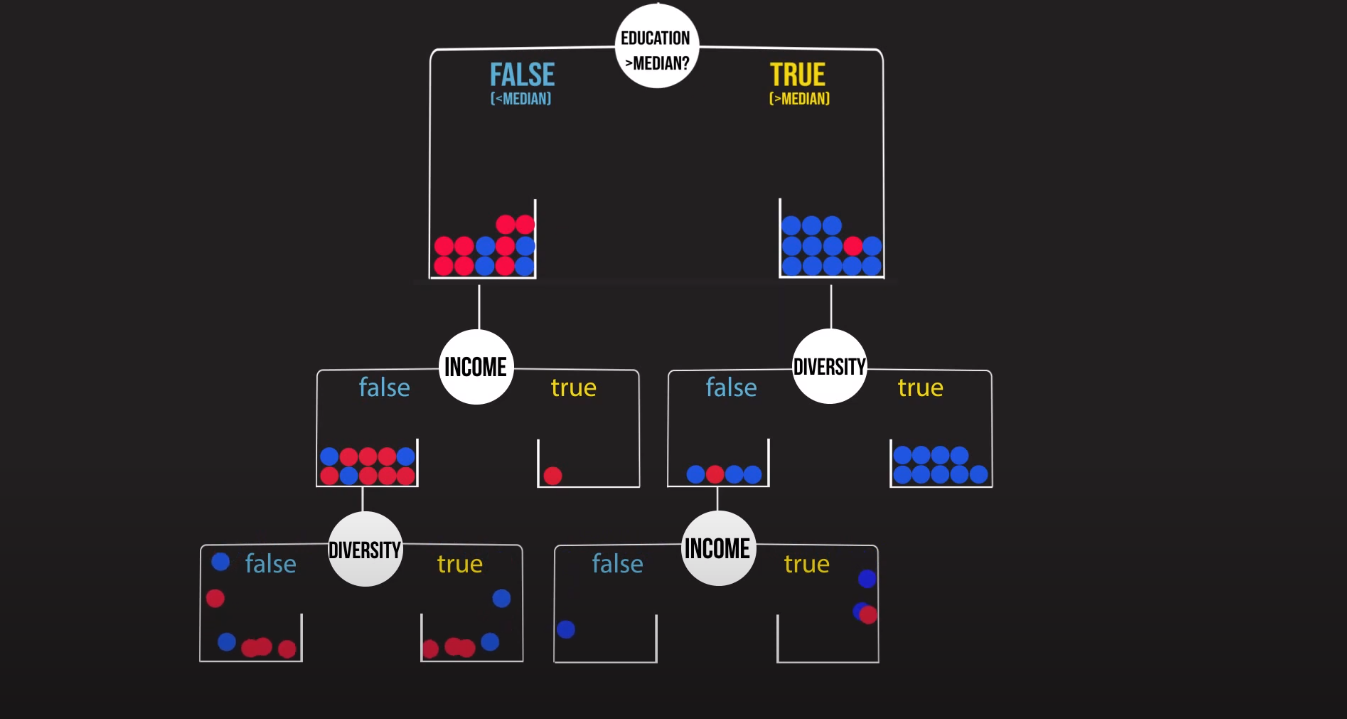
Now back to random forests. In this method of ensembling, we train a bunch of decision trees (hence the name “forest”) and then take a vote among the different trees. One tree one vote.
现在回到随机森林。 在这种合奏方法中,我们训练一堆决策树(因此称为“森林”),然后在不同的树之间进行投票。 一棵树一票。

In the case of classification, each tree spits out a class prediction and then the class with the most votes becomes the output of the random forest.
在分类的情况下,每棵树吐出一个类别预测,然后投票最多的类别将成为随机森林的输出。

In the case of a regression, a simple average of each individual tree’s prediction becomes the output of the random forest.
在回归的情况下,每棵树的预测的简单平均成为随机森林的输出。
The key idea behind random forests is that there is wisdom in crowds. Insight drawn from a large group of models is likely to be more accurate than a prediction from any one model alone.
随机森林背后的关键思想是人群中有智慧。 从大量模型中得出的见解可能比任何一个单独模型的预测都更准确。
Simple right? Sure, but why does this work? What if all our models learn the exact same thing and vote for the same answer? Isn’t that equivalent to just having one model make the prediction?
简单吧? 可以,但是为什么行得通呢? 如果我们所有的模型都学习完全相同的东西并投票赞成相同的答案怎么办? 这不等于只用一个模型进行预测吗?

Yes, but there’s a way to fix that.
是的,但是有一种解决方法。
But first, we need to define a word that will help explain: uncorrelatedness. We need our decision trees to be different from each other. We want them to disagree on what the splits are and what the predictions are. Uncorrelatedness is important for random forests. A large group of uncorrelated trees working together in an ensemble will outperform any of the constituent trees. In other words, the forest is shielded from the errors of individual trees.
但是首先,我们需要定义一个有助于解释的词: 不相关 。 我们需要决策树彼此不同。 我们希望他们不同意分裂是什么和预测是什么。 不相关性对于随机森林很重要。 在一个集合中一起工作的一大堆不相关的树将胜过任何组成树。 换句话说,保护森林免受单个树木的错误的影响。

There are a few different methods to ensure our trees are uncorrelated:
有几种不同的方法可确保我们的树不相关:
The first method is called “bootstrapping”. Bootstrapping is creating smaller datasets out of our training set through sampling. Now, with normal decision trees, we feed the entire training set to the tree and allow it to generate a prediction. However with bootstrapping, we allow each tree to randomly sample the training data with replacement, resulting in different trees. When we allow replacement, some observations may be repeated in the sample. Often, the sample size of the bootstrap is the same as the size of the original dataset, but it is possible to sample subsets of the dataset for the sake of computational efficiency. Using bootstrapping to create uncorrelated models, and then aggregating their results is called bootstrap aggregating, or bagging for short.
第一种方法称为“引导” 。 自举是通过抽样从我们的训练集中创建较小的数据集。 现在,使用普通决策树,我们将整个训练集馈入该树,并使其生成预测。 但是,使用自举时,我们允许每棵树替换随机抽样训练数据,从而得到不同的树。 当我们允许替换时,样本中可能会重复一些观察。 引导程序的样本大小通常与原始数据集的大小相同,但是出于计算效率的考虑,可以对数据集的子集进行采样。 使用自举创建不相关的模型,然后汇总其结果称为引导汇总 ,或简称为袋装 。

The second way to introduce variation in our trees is by shuffling which features each tree can split on. This method is called Feature Randomness. Remember, with basic decision trees, when it’s time to split the data on a node, the tree considers each possible feature and picks the one that leads to the purest subgroups. However, with random forests, we limit the number of features that each tree can even consider splitting on. Some libraries randomize features at the split level rather than the tree level. This does not matter if we assume the trees are decision stumps, meaning there is only 1 split, or max depth = 1. In both cases, the goal is to limit the number of possible features in order to decorrelate the individual trees.
在我们的树中引入变异的第二种方法是通过改组每棵树可以分裂的特征。 这种方法称为特征随机性。 请记住,使用基本决策树时,是时候在节点上拆分数据时,该树会考虑每个可能的特征,并选择一个导致最纯子组的特征。 但是,对于随机森林,我们限制了每棵树甚至可以考虑分割的特征数量。 一些库在拆分级别而不是树级别将功能随机化。 如果我们假设这些树是决策树,则无所谓,这意味着只有1个分割或最大深度=1。在这两种情况下,目标都是限制可能的特征数量以对各个树进行解相关。

Because the individual trees are very simple and they are only trained on a subset of the training data and feature set, training time is very low so we can afford to train thousands of trees. Random Forests are widely used in academia and industry. Now that you understand the concept, you’re almost ready to implement a random forest model to use with your own projects! Stay tuned for the Random Forests coding tutorial and for a new post on another ensembling method — Gradient Boosted Trees!
因为单个树非常简单,并且仅在训练数据和特征集的子集上对其进行训练,所以训练时间非常短,因此我们有能力训练数千棵树。 随机森林广泛用于学术界和工业界。 现在您已经了解了这个概念,您几乎可以准备实现一个随机森林模型以用于您自己的项目了! 请继续关注“随机森林”编码教程,以及有关另一种集成方法的新文章-梯度增强树!
Check out the video below to see everything you learned in action!
观看下面的视频,了解您在实践中学到的一切!
翻译自: https://towardsdatascience.com/a-visual-guide-to-random-forests-b3965f453135
随机森林 极限随机森林















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









