





nlp文本建模算法
This is part 3 of a 4 part post. Until now we have talked about:
这是4部分帖子的第3部分。 到目前为止,我们一直在谈论:
Topic Modeling using Latent Dirichlet allocation (LDA)- We are here
使用潜在Dirichlet分配(LDA)进行主题建模-我们在这里
In this article, we will be using a summary version of long text documents to find what topics makeup each document. We summarize the text before topic modeling because there could be extra details in some documents. Whereas, others might have just the gist.
在本文中,我们将使用长文本文档的摘要版本来查找每个文档的主题 。 我们在主题建模之前对文本进行了总结,因为某些文档中可能会有其他细节。 而其他人可能只有主旨。
Wait, but why model topics? What does that even mean?
等等,但是为什么要建模主题? 那有什么意思?
Topic modelling is for discovering the abstract “topics” that occur in a collection of documents. It is a frequently used text-mining tool for discovery of hidden semantic structures in a text body.
主题建模用于发现文档集合中出现的抽象“主题”。 它是一种常用的文本挖掘工具,用于发现文本主体中的隐藏语义结构。
We want to keep just crisp and concise information to identify topics for each long document. So, we summarized this text to look like this:
我们只想保留简洁明了的信息,以标识每个长文档的主题。 因此,我们将文本总结如下:

主题建模 (Topic Modeling)
We will not do any further preprocessing because we have essentially preprocessed when cleaning the text initially and only have phrases in summary.
我们将不进行任何进一步的预处理,因为在最初清除文本时,我们已经进行了实质性的预处理,并且仅包含摘要。
Like in the previous sections, we first proved if summarization was possible. Let us inspect whether clustering will be viable.
像前面的部分一样,我们首先证明了汇总是否可行。 让我们检查集群是否可行。
from numpy import dot
from numpy.linalg import normexam = nlp.parser.vocab[u"exam"]# cosine similarity
cosine = lambda v1, v2: dot(v1, v2) / (norm(v1) * norm(v2))allWords = list({w for w in nlp.parser.vocab if w.has_vector and w.orth_.islower() and w.lower_ != "exam"})# sort by similarity to Exam
allWords.sort(key=lambda w: cosine(w.vector, exam.vector))
allWords.reverse()
print("Top 5 most similar words to exam:")
for word in allWords[:5]:
print(word.orth_)
Wow!!! so does that mean we can even find similarities between documents? YES!! So, we can potentially find clusters of these different documents!!!!
哇!!! 这是否意味着我们甚至可以找到文档之间的相似之处? 是!! 因此,我们有可能找到这些不同文档的簇!
寻找最佳主题数 (Finding the Optimum Number of Topics)
The Latent Dirichlet allocation (LDA) is a Bayesian probabilistic model of text documents. It determines sets of observations from unobserved groups. Hence, explaining the similar parts of data.
潜在狄利克雷分配(LDA)是文本文档的贝叶斯概率模型。 它确定了未观察组的观察结果集。 因此,解释数据的相似部分。
Observations are words from documents. Each document is an amalgamation of a small number of topics. Each word’s presence is attributable to one of the document’s topics.
意见是文件中的文字。 每个文档都是少量主题的组合。 每个单词的出现可归因于文档的主题之一。

How many of you actually understood what happened in the above section? Let me know if you did not and I will be happy to write another article on the interpretation of this dictionary!
你们当中有多少人真正理解了上一节中发生的事情? 让我知道您是否愿意,我将很乐意就该词典的解释写另一篇文章!
Can we VISUALIZE the topics above though? Yes, we can.
我们可以可视化上面的主题吗? 我们可以。
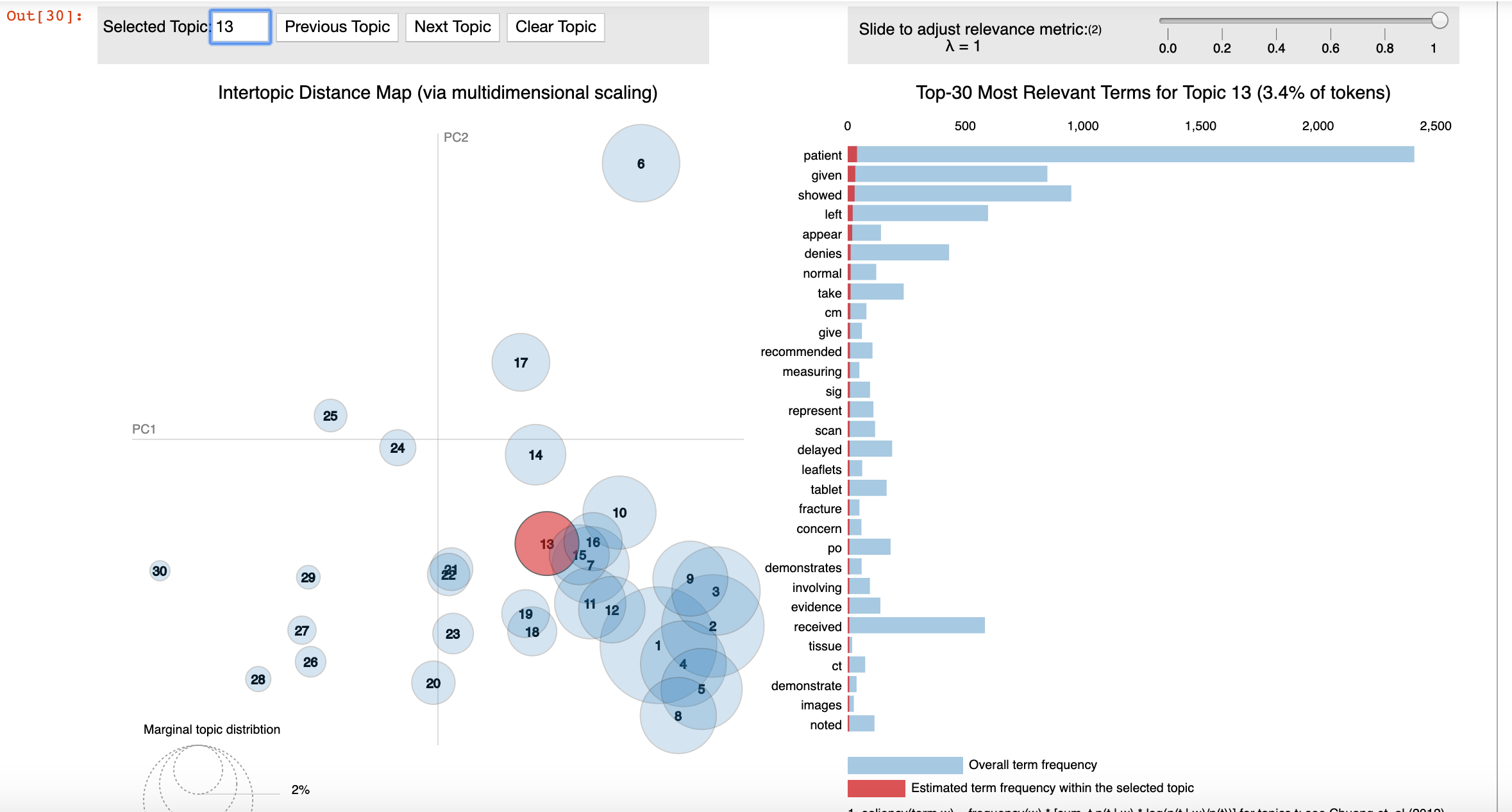
This shows that topics are getting assigned based on the disease/condition being talked about. Great, let us see the topic propensity among the transcripts.
这表明正在根据所谈论的疾病/状况分配主题。 太好了,让我们来看一下笔录中的主题倾向。
When LDA found topics above, it was essentially trying to find the occurrence of words in groups. This does mean we have a probability score associated to every chart for every topic. But, we are not confident of all of them. So we only extract those that are above 90% propensity.
当LDA找到上面的主题时,它实际上是在尝试查找组中单词的出现。 这确实意味着我们对每个主题都有与每个图表相关的概率得分。 但是,我们对所有这些都不充满信心。 因此,我们仅提取倾向高于90%的那些。
If notice closely, not all charts have gotten topics. And that is because the algorithm did not meet our cut off criteria for topic propensity.
如果密切注意,并非所有图表都具有主题。 那是因为该算法不符合我们对主题倾向的判断标准。
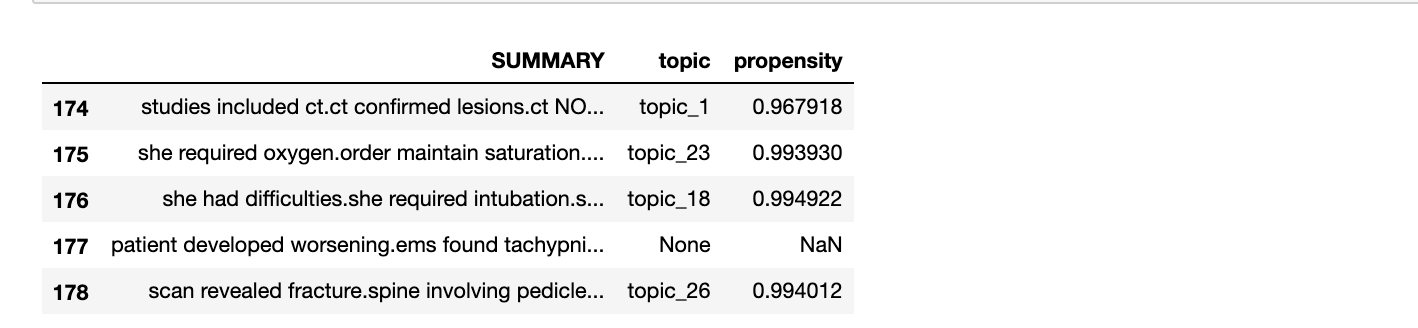
Let us visualize the topics/clusters and frequency of charts we have identified
让我们可视化已确定的主题/集群和图表的频率

结论 (Conclusion)
Here, we can see that topic_21 has the most charts. It is closely followed by topic_15 and topic_14.
在这里,我们可以看到topic_21的图表最多。 紧随其后的是topic_15和topic_14 。
Next, we have clustering of these text documents!
接下来,我们将这些文本文档聚类!
If you want to try the entire code yourself or follow along, go to my published jupyter notebook on GitHub: https://github.com/gaurikatyagi/Natural-Language-Processing/blob/master/Introdution%20to%20NLP-Clustering%20Text.ipynb
如果您想亲自尝试或遵循整个代码,请转至我在GitHub上发布的jupyter笔记本: https : //github.com/gaurikatyagi/Natural-Language-Processing/blob/master/Introdution%20to%20NLP-Clustering% 20Text.ipynb
翻译自: https://towardsdatascience.com/nlp-topic-modeling-to-identify-clusters-ca207244d04f
nlp文本建模算法















 9059
9059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









