





神经网络初始化权重
Machine learning and deep learning techniques has encroached in every possible domain you can think of. With increasing availability of digitized data and advancement of computation capability of modern computers it will possibly flourish in near future. As part of it every day more and more people are delving into the task of building and training models. As a newbie in the domain I also have to build and train few neural network models. Well, most of the time, my primary goal remain normally to make a highly accurate as well generalized model. And in order to achieve that I normally break my head over finding proper hyper parameters for my model, what all different regularization techniques I can apply ,or thinking about the question do I need to further deepen my model and so on. But often I forget to play around with the weight-initialization techniques. And I believe this is the case for many other like me.
中号 achine学习和深入学习技术侵犯了你能想到的每一个可能的领域。 随着数字化数据可用性的提高和现代计算机计算能力的提高,它可能会在不久的将来蓬勃发展。 作为每天的一部分,越来越多的人开始研究构建和训练模型的任务。 作为该领域的新手,我还必须构建和训练一些神经网络模型。 好吧,在大多数时候,我的主要目标通常是制作一个高度准确且通用化的模型。 为了实现这一点,我通常会为寻找适合模型的超级参数而烦恼,我可以应用所有不同的正则化技术,或者思考这个问题是否需要进一步加深模型等等。 但是我经常忘记使用权重初始化技术。 我相信其他许多像我一样的情况。
Wait, weight initialization? Does it matter at all? I dedicate this article to find out the answer of the questions. When I went over the internet to find the answer of the question, there are overwhelming information about it. Some articles talk about the mathematics behind this articles, some compare this techniques theoretically and some are more into deciding whether uniform initialization is better or the normal one.In this situation I resorted in a result based approach. I tried to find out the impact of weight initialization techniques via a small experiment. I applied few of these techniques into a model and tried to visualize the training process itself, keeping aside the goal of achieving high accuracy for some time.
等一下,重量初始化吗? 有关系吗? 我致力于本文以找出问题的答案。 当我上网查找问题的答案时,有大量有关此问题的信息。 一些文章讨论了本文背后的数学原理,一些文章从理论上比较了这种技术,还有一些文章更多地用于确定统一初始化是更好还是常规初始化。在这种情况下,我采用了一种基于结果的方法。 我试图通过一个小实验找出权重初始化技术的影响。 我将这些技术中的极少数应用到了模型中,并试图可视化训练过程本身,将目标保持一段时间以保持较高的准确性。
设置 : (The setup:)

I have created a simple CNN model with combination Conv-2D, Max-pool, Dropout, Batch-norm and Dense layers with Relu activation(except for the last layer, which is Softmax). I have trained it for classification task of Cifar-10 data set. I have initialized the model with six different kernel initialization methods and analyzed the training phase. I trained the model with 30 epochs and with batch size of 512 using SGD optimizer. The six initialization methods used in this experiment namely are:
我创建了一个简单的CNN模型,结合了Conv-2D,Max-pool,Dropout,Batch-norm和Dense层以及Relu激活(最后一层是Softmax)。 我已经针对Cifar-10数据集的分类任务对其进行了培训。 我已经用六种不同的内核初始化方法对模型进行了初始化,并分析了训练阶段。 我使用SGD优化器以30个时期训练了模型,并以512个批处理大小进行了训练。 本实验中使用的六个初始化方法是:
- Glorot Uniform Glorot制服
- Glorot Normal Glorot普通
- He Uniform 他制服
- He Normal 他正常
- Random Uniform 随机制服
- Random Normal 随机正态

Note: The default kernel initialization method for Keras layers is Glorot Uniform.
注意 :Keras层的默认内核初始化方法是Glorot Uniform。
实验结果: (Experiment results:)
let us first have a look how uniform and normal initialization behaved for the three different method.
首先让我们看一下这三种不同方法的统一初始化和正常初始化的行为。

For First two methods validation accuracy curve for the model with normal initialization techniques almost followed the uniform technique, if not always. For Glorot methods(first plot) after it took a slow start, and then it started to rise. After tenth epoch both curves for normal and uniform showed a very jumpy behavior. But for last few epochs the normal curve took a downward journey, where as for uniform one the overall trend is upward.
对于前两种方法,使用标准初始化技术的模型验证准确性曲线(如果不是总是)几乎遵循统一技术。 对于Glorot方法(第一个绘图),它起步缓慢,然后开始上升。 在第十个时期之后,正常曲线和均匀曲线都显示出非常跳跃的行为。 但是在最近的几个时期中,正常曲线是向下移动的,对于统一曲线而言,总体趋势是向上的。
For random methods(last plot), the trend for both the curves didn’t match at all. The overall validation accuracy trend for the random normal remained very low, below 40%(except two sharp spikes upward). Whereas the uniform method showed a better result. Although the curve for uniform technique is very unstable and jumpy in nature. After 23rd epoch both the curves showed a downfall of validation accuracy. Following the trend of Glorot methods, here also we see a very slow start up to epoch 5, showing a validation accuracy as low as ~10% . For Glorot and Random methods validation accuracy curve didn’t show a proper convergence pattern what so ever and remained unstable for the entire training process.
对于随机方法(最后一个图),两条曲线的趋势根本不匹配。 随机法线的总体验证准确性趋势仍然很低,低于40%(除了两个向上的尖峰)。 而统一方法显示出更好的结果。 尽管统一技术的曲线本质上非常不稳定且跳跃。 在第23个时期之后,两条曲线均显示出验证准确性下降。 遵循Glorot方法的趋势,在这里我们也看到启动到第5阶段的过程非常缓慢,显示出验证精度低至〜10%。 对于Glorot和Random方法,验证准确性曲线从未像现在这样显示出适当的收敛模式,并且在整个训练过程中仍然不稳定。
The He methods(middle plot) performed better than the other two in this aspect. The curves for uniform and normal techniques are similar and followed each other till the end of training of 30 epochs. And they both showed a overall upward trend, and the curves are comparative less jumpy. Unlike Glorot and Random, when used He methods, the validation accuracy started to rise from very first epoch without showing a slow start.
He方法(中间图)在这方面比其他两个方法表现更好。 统一技术和正常技术的曲线相似,并且相互遵循,直到训练30个纪元为止。 而且它们都显示出整体上升趋势,并且曲线的跳跃性相对较小。 与Glorot和Random不同,当使用He方法时,验证准确度从一开始就开始提高,而没有显示出缓慢的开始。
Let us now take a deep dive and analyse the performance of these methods on few desirable aspects.
现在让我们深入研究,并在一些可取的方面分析这些方法的性能。
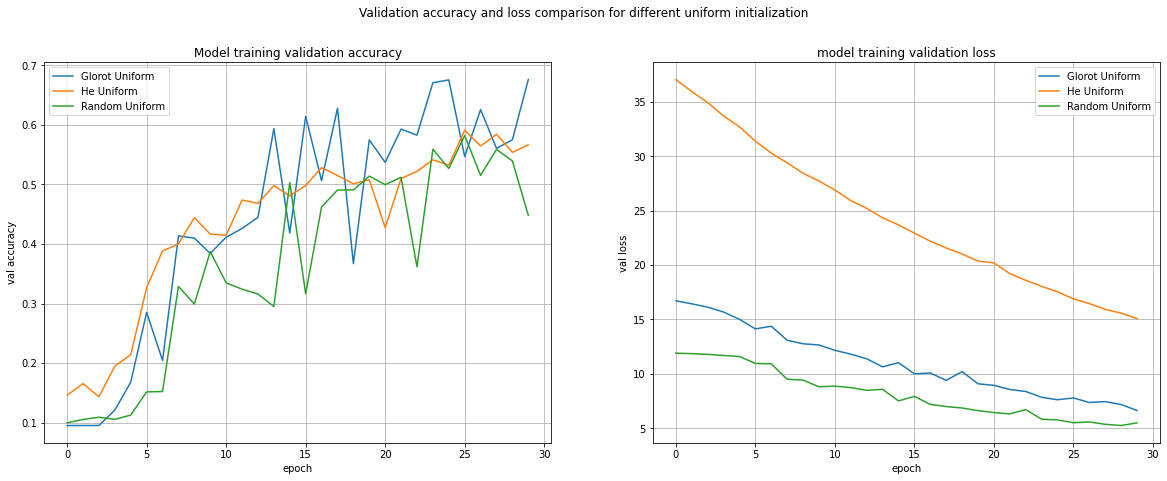

Accuracy: As far as accuracy is concerned highest validation accuracy is achieved using Glorot methods(Blue curves). Although as the curves suggest it failed to maintain the position rather shown a very unstable behavior. He methods(Orange curves) are are far more stable and reliable than rest two and the validation accuracy is comparable with Glorot. Among these, Random techniques, both uniform and normal, produced the lowest validation accuracy throughout training. The below table will give you a overall summary about how these methods behaved.
准确性 :就准确性而言,使用Glorot方法(蓝色曲线)可获得最高的验证准确性。 尽管如曲线所示,它无法保持位置,但表现出非常不稳定的行为。 他的方法(橙色曲线)比其余两种方法更加稳定和可靠,并且验证精度与Glorot相当。 在这些方法中,统一和常规的随机技术在整个训练过程中产生的验证准确性最低。 下表将为您提供有关这些方法的行为的总体摘要。

Convergence: Now a days people are training very deep models. GPT-3 is having 175 billion parameters to train, so faster and distinct convergence is always a desirable aspect. As I already mentioned Glorot and Random methods’ curves are very unstable and jumpy, so it’s difficult to deduce whether convergence is achieved or not. If we analyze over all trend, Random initialization methods perform very poor and we can say that the training for random normal converged at around 40% mark, where as for Random Uniform its below 50%. Random curves took as minimum as 15–16 epochs to reach that level of validation accuracy. For Glorot Uniform and Normal initialization, the validation accuracy converges between 50–60%(some random spikes above 60%). And the convergence trend started to formalize after 15 epochs. He curves after increasing constantly, crossed the 50% mark at around 12 epochs(He Normal curve was faster). After that both He uniform and normal curves continued to go upward and finished at around 60% mark. Also if we look at he loss curves, the starting loss for Glorot uniform and Random uniform methods are low compared to He Uniform. This is probably He initialization method initializes the weights a bit on higher side.
融合 :现在,人们正在训练非常深入的模型。 GPT-3具有1,750亿个要训练的参数,因此,更快和独特的融合始终是理想的方面。 正如我已经提到的Glorot和Random方法的曲线非常不稳定且波动很大,因此很难推断出是否实现收敛。 如果我们对所有趋势进行分析,那么随机初始化方法的效果会很差,可以说,对随机法线的训练收敛在40%左右,而对于Random Uniform,其训练低于50%。 随机曲线最少要花15-16个纪元才能达到验证精度水平。 对于Glorot均匀和法线初始化,验证精度在50-60%之间收敛(某些随机峰值超过60%)。 15个时代之后,趋同趋势开始正式化。 他在不断增加后弯曲,在大约12个时代越过了50%(正常曲线更快)。 此后,He均匀曲线和正常曲线都继续上升,并最终达到60%左右。 同样,如果我们查看He损失曲线,则与He Uniform相比,Glorot均匀法和Random均匀法的起始损失较低。 这可能是He的初始化方法在较高方面初始化权重。
Stability and randomness of training: The Validation accuracy comparison curves show very clearly that with Glorot and Random methods are very jumpy and as a consequence it hinders the decision making ability of the designer for making a early stop of training process. This is a very vital trick for reducing over-fitting and making a well generalized model. On the other hand, when the model initialized with He uniform or random methods the validation accuracy curves shows a very stable and consistent behavior. This also gives confidence to the designer about the training process of the model. The designer can stop at any desirable position as per their whim. In order to prove that are findings are correct we trained the model five times with each of the initialization methods.
训练的稳定性和随机性:验证准确性的比较曲线非常清楚地表明,使用Glorot和Random方法的跳跃性非常高,因此,这阻碍了设计者提前停止训练过程的决策能力。 这是减少过度拟合并建立良好通用模型的重要技巧。 另一方面,当用He均匀或随机方法初始化模型时,验证精度曲线显示出非常稳定和一致的行为。 这也使设计人员对模型的训练过程充满信心。 设计师可以根据自己的想法停在任何理想的位置。 为了证明发现是正确的,我们使用每种初始化方法对模型进行了五次训练。



The plots clearly shows how jumpy the training process could be when initialized with Glorot and Random methods. The Random Uniform method failed to show any increment up to 5th epoch and the story is same for Glorot Uniform up to 3rd epoch.
这些图清楚地表明了使用Glorot和Random方法初始化训练过程的过程有多快。 随机制服方法无法显示到第5个纪元的任何增量,而故事情节与Glorot制服到第3个纪元的情况相同。
Generalization: Along with accuracy we as designers want to train a model that is generalized well as well as accurate, so that it perform well on unseen data. So we expect our model to show minimal gap between training and testing.
泛化 :除准确性外,我们作为设计师还希望训练一个模型,该模型具有良好的泛化和准确性,因此可以在看不见的数据上表现良好。 因此,我们希望我们的模型显示出培训和测试之间的最小差距。



As these above plots show that the gap between the training and testing is narrowest when the model is initialized with He Uniform method. The validation loss and training loss curve almost superimposes on one another. The gap is biggest when the model is initialized with Random Uniform technique, ending up with a highly over-fitted model
如上图所示,当使用He Uniform方法初始化模型时,训练和测试之间的差距最窄。 验证损失和训练损失曲线几乎相互叠加。 当使用随机均匀技术初始化模型时,差距最大,最终出现高度过度拟合的模型
Environment: Yes you read it correct. The heading is environment. A article published on MIT technical review says “Training a single AI model can emit as much carbon as five cars in their lifetimes”.
环境:是的你 正确阅读。 标题是环境。 麻省理工学院技术评论上发表的一篇文章说:“训练一个AI模型可以在其生命周期内排放多达五辆汽车的碳”。
As AI is shaping the future of human kind, on other side while training our model we must reduce carbon footprint generated by exploiting computation power of computers to keep the world inhabitable. As model training is a cyclic process, we must look for techniques that converges fast. Looking at the training curves, we can see model initialized with He methods are fast to converge and smooth training curves can enable the designer for a early stop.
随着AI塑造人类的未来,另一方面,在训练模型时,我们必须减少通过利用计算机的计算能力而产生的碳足迹,以使世界可居住。 由于模型训练是一个循环的过程,因此我们必须寻找快速收敛的技术。 查看训练曲线,我们可以看到用He方法初始化的模型可以快速收敛,平滑的训练曲线可以使设计人员早日停下来。
Well when the deep learning community is divided on which initialization method works best, what should we use Uniform or Normal, this experiment gives me confidence that HE initialization methods performed better on few aspects under the setting of this task given the model.
好吧,当深度学习社区在哪种初始化方法上效果最好时,我们应该使用Uniform还是Normal,该实验使我充满信心,在给定模型的情况下,HE初始化方法在此任务设置下在某些方面表现更好。
1) Very stable and smooth training progression
1)非常稳定和流畅的训练进度
2) Fast to converge to a desirable validation accuracy
2)快速收敛到理想的验证精度
3) Constant increase of validation accuracy from very fast epoch
3)从非常快的时代开始不断提高验证准确性
4) Multiple runs are similar, and less randomness in training process
4)多次跑步相似,训练过程中的随机性较低
5) Clear convergence and very thin generalization gap(training vs testing) compared to others.
5)与其他方法相比,具有清晰的收敛性和非常小的泛化鸿沟(培训与测试)。
神经网络初始化权重















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









