





fcn从头开始
Be it a Whatsapp chat, Telegram group, Slack channel, or any product website, I’m sure you have encountered one of these bots popping out of nowhere. You ask some questions and it will try it’s best to resolve your queries. Today we’ll try to build a chatbot that could respond to some basic queries and respond in real-time.
无论是Whatsapp聊天,Telegram组,Slack频道还是任何产品网站,我相信您都遇到了这些机器人之一。 您提出一些问题,它将尽力解决您的问题。 今天,我们将尝试构建一个可以响应一些基本查询并实时响应的聊天机器人。
Let us just assume that we’ll be building a chatbot for a restaurant. Our client has certain requirements for the chatbot.
让我们假设我们将为餐厅构建一个聊天机器人。 我们的客户对聊天机器人有某些要求。
The bot should be able to:
该漫游器应该能够:
- Greet the visitors on the website. 在网站上问候访客。
- Book seats. 预定座位。
- Show available seats. 显示可用的座位。
- Show what’s on the menu. 显示菜单上的内容。
- Show the working hours. 显示工作时间。
- Show contact information. 显示联系信息。
- Show the location of the restaurant. 显示餐厅的位置。
In the end, our chatbot will look like this:
最后,我们的聊天机器人将如下所示:
If you have a basic understanding of Natural Language Processing (NLP), Fully Connected layers in Deep Learning, and Flask framework, this project will be a breeze for you. Even if you aren’t familiar with these terms I’ll try my best to explain everything in simple language and link helpful resources wherever possible.
如果您对自然语言处理(NLP),深度学习中的全连接层和Flask框架有基本的了解,那么这个项目对您来说将是一件轻而易举的事。 即使您不熟悉这些术语,我也会尽力用简单的语言来解释所有内容,并尽可能地链接有用的资源。
With that being said, let's start building our chatbot.
话虽如此,让我们开始构建我们的聊天机器人。
训练数据 (Training Data)
Now it’s time to see what kind of data we’re dealing with here. The data required for building a chatbot is a little different than the conventional datasets we tend to see. Every intelligent machine needs data that it can see and interpret. We won’t be downloading any particular dataset for this project. We already have a small set of data. Let’s have a look at it.
现在是时候看看我们在处理什么样的数据了。 构建聊天机器人所需的数据与我们倾向于看到的常规数据集略有不同。 每个智能机都需要它可以看到和解释的数据。 我们不会为该项目下载任何特定的数据集。 我们已经有少量数据。 让我们来看看它。
{"intents": [
{"tag": "greeting",
"patterns": ["Hi", "Hey", "How are you", "Is anyone there?", "Hello", "Good day", "Whats up"],
"responses": ["Hello!", "Good to see you again!", "Hi there, how can I help?", "Hello! I'm Dexter. How may I help you?", "Hey there!"],
"context_set": ""
}
]
}This is an example of how our data looks like. It is a JSON format file that is normally used to store and transmit data. The three important terms to be noted here are “tag”, “patterns” and “responses”.
这是我们的数据外观的一个示例。 这是一个JSON格式的文件,通常用于存储和传输数据。 这里要注意的三个重要术语是“标签” , “样式”和“响应” 。
Whatever queries a user enters for the chatbot to interpret must be included in “patterns”.
用户输入的用于聊天机器人解释的任何查询都必须包含在“模式”中 。
After interpreting the user’s query, the chatbot will have to reply to the query and this reply will be randomly selected from the set of predefined replies in “responses”.
解释了用户的查询后,聊天机器人将不得不答复该查询,并且将从“响应”中的一组预定义答复中随机选择此答复。
The “tag” groups a set of similar patterns and responses to a specific category so that it’ll be easier for the model to predict which category a particular pattern represents.
“标签”将一组相似的模式和对特定类别的响应进行分组,以便模型更容易预测特定模式所代表的类别。
You can now copy the data given below into a file. I have named my file “intents.json”.
您现在可以将下面给出的数据复制到文件中。 我已将文件命名为“ intents.json”。
{"intents": [
{"tag": "greeting",
"patterns": ["Hi", "Hey", "How are you", "Is anyone there?", "Hello", "Good day", "Whats up"],
"responses": ["Hello!", "Good to see you again!", "Hi there, how can I help?", "Hello! I'm Dexter. How may I help you?", "Hey there!"],
"context_set": ""
},
{"tag": "book_table",
"patterns": ["Book a table","Can I book a table?", "I want to book a table", "Book seat", "I want to book a seat", "Can I book a seat?"],
"responses": [""],
"context_set": ""
},
{"tag": "available_tables",
"patterns": ["How many seats are available?", "Available seats", "How many tables are available?", "Available tables"],
"responses": [""],
"context_set": ""
},
{"tag": "goodbye",
"patterns": ["cya", "See you later", "Goodbye", "I am Leaving", "Have a Good day", "cya later", "I gotta go now", "I gotta rush now"],
"responses": ["Sad to see you go :(", "Talk to you later", "Goodbye!"],
"context_set": ""
},
{"tag": "age",
"patterns": ["how old", "how old is Dexter", "what is your age", "how old are you", "age?"],
"responses": ["My master built me just a month ago.", "Just a month old!"],
"context_set": ""
},
{"tag": "name",
"patterns": ["what is your name", "what should I call you", "whats your name?"],
"responses": ["You can call me Dexter.", "I'm Dexter!", "I'm Dexter aka The Restaurant Superbot."],
"context_set": ""
},
{"tag": "hours",
"patterns": ["when are you guys open", "what are your hours", "hours of operation", "hours", "what is the timing"],
"responses": ["We are open 10am-12am Monday-Friday!"],
"context_set": ""
},
{"tag": "menu",
"patterns": ["Id like to order something", "whats on the menu", "what do you reccommend?", "could i get something to eat", "Im hungry"],
"responses": [""],
"context_set": ""
},
{"tag": "contact",
"patterns": ["contact information", "contact us", "how can i contact you", "can i get the contact details", "I wanna give some feedback", "how can i give some feedback?"],
"responses": ["You can contact us at contact@restaurantname.com"],
"context_set": ""
},
{"tag": "address",
"patterns": ["what is the location?","whats the location", "where are you locatated?", "where is the restaurant located?", "address", "whats the address?"],
"responses": ["You can locate us at Taj Lands End, Bandra Bandstand, Bandra West, Mumbai, Maharashtra 400 050"],
"context_set": ""
}
]
}As you can see the data provided here meets all of the requirements given by our client. I have intentionally set the responses of the tags “menu”, “book_table” and “available_tables” as an empty list. I’ll explain the reason later in our project.
如您所见,此处提供的数据符合我们客户提供的所有要求。 我特意将标签“ menu”,“ book_table”和“ available_tables”的响应设置为空列表。 我将在项目后面解释原因。
With this data, we can now train our own neural network and it will predict and try to classify it into one of the tags from the file. Once the tag is known, a random response will be selected from that tag and shown to the user. You can add any other tags you wish to this data. Just make sure that the syntax isn’t wrong. The more tags, patterns, and responses you provide, the more robust the chatbot will be.
有了这些数据,我们现在可以训练自己的神经网络,它将预测并尝试将其分类为文件中的标签之一。 一旦知道标签,就会从该标签中选择一个随机响应并显示给用户。 您可以向该数据添加任何其他标签。 只要确保语法没有错误即可。 您提供的标签,模式和响应越多,聊天机器人的功能就越强大。
Now that you're familiar with the data let’s load it onto the kernel using Python. The version that I’m using is Python 3.6.
现在您已经熟悉了数据,现在让我们使用Python将其加载到内核中。 我使用的版本是Python 3.6。
设置 (The Setup)
Before starting with any code, it’s recommended to set up a virtual environment so that any libraries we’ll be installing won't clash with existing ones or cause any redundancy issues.
在开始编写任何代码之前,建议先设置一个虚拟环境,以使我们将要安装的任何库都不会与现有库冲突或导致任何冗余问题。
I’ll be creating a virtual environment using conda. (See here on how to install Anaconda.)
我将使用conda创建一个虚拟环境。 ( 有关如何安装Anaconda的信息, 请参见此处 。)
Open your command prompt and enter the command.
打开命令提示符并输入命令。
conda create -n simple_chatbot python=3.6Here “simple_chatbot” is the name of the virtual environment. You can give it any name you like.
这里的“ simple_chatbot”是虚拟环境的名称。 您可以给它任何喜欢的名字。
To activate this virtual environment, just enter:
要激活此虚拟环境,只需输入:
conda activate simple_chatbotOnce activated, the name of your environment should show up on the left something like this:
激活后,您的环境名称应显示在左侧,如下所示:

We’ll be using pip to install the following libraries:
我们将使用pip安装以下库:
- numpy==1.16.5 numpy == 1.16.5
- nltk==3.4.5 nltk == 3.4.5
- tensorflow==1.13.2 张量流== 1.13.2
- tflearn==0.3.2 tflearn == 0.3.2
- flask==1.1.1 烧瓶== 1.1.1
I have also added the version of the libraries just to be safe.
为了安全起见,我还添加了库的版本。
pip install packagename==version //Enter packages mentioned aboveNow that we’re prepped up, let's dive into the code.
现在我们已经准备好了,让我们深入研究代码。
导入库并加载数据 (Importing Libraries and Loading Data)
Now we’ll be importing some libraries needed to load, process, and transform our data and then feed it into a deep learning network. Just remember to keep your JSON file in the same directory as your python file. I’ll be naming my file “main.py”.
现在,我们将导入一些需要的库,以加载,处理和转换我们的数据,然后将其输入到深度学习网络中。 只需记住将JSON文件与python文件放在同一目录中即可。 我将命名文件“ main.py”。
#Imports
import nltk
import os
from nltk.stem.lancaster import LancasterStemmer
import numpy as np
import tflearn
import tensorflow as tf
import random
import json
import pickle
#Loading Data
with open("intents.json") as file:
data = json.load(file)文字预处理 (Text Preprocessing)
Now, we have to take the “tag” and “patterns” out of the file and store it in a list. We’ll also make a collection of unique words in the patterns to create a Bag of Words (BoW) vector.
现在,我们必须从文件中取出“标签”和“样式”,并将其存储在列表中。 我们还将在模式中收集唯一的单词,以创建单词袋 (BoW)向量。
#Initializing empty lists
words = []
labels = []
docs_x = []
docs_y = []
#Looping through our data
for intent in data['intents']:
for pattern in intent['patterns']:
pattern = pattern.lower()
#Creating a list of words
wrds = nltk.word_tokenize(pattern)
words.extend(wrds)
docs_x.append(wrds)
docs_y.append(intent['tag'])
if intent['tag'] not in labels:
labels.append(intent['tag'])In the code above, we have created four empty lists.
在上面的代码中,我们创建了四个空列表。
words: Holds a list of unique words.
单词:包含唯一单词的列表。
labels: Holds a list of all the unique tags in the file.
标签:包含文件中所有唯一标签的列表。
docs_x: Holds a list of patterns.
docs_x:包含模式列表。
docs_y: Holds a list of tags corresponding to the pattern in docs_x.
docs_y:包含与docs_x中的模式相对应的标签列表。
As we loop through the data, we convert all patterns into lower case, tokenize each pattern and then add them to the respective lists. We also add the pattern’s tag into docs_y simultaneously.
在遍历数据时,我们将所有模式都转换为小写,对每个模式进行标记,然后将它们添加到相应的列表中。 我们还将模式的标签同时添加到docs_y中。
抽干 (Stemming)
Now that we’ve got the words in a list, it’s time to perform stemming on them. Stemming is basically trying to find the root origin of a word. It removes all the prefixes and suffixes of a word so that the model that we’re building will get a general idea of that word instead of getting trapped in all the intricacies of the same word with different forms. There are different types of stemmers like Porter Stemmer, Snowball Stemmer, Lancaster Stemmer, etc. We’ll be using Lancaster Stemmer in our code. (Learn more about Stemmers here.)
现在,我们已经在列表中添加了单词,是时候对它们进行词干分析了。 词干基本上是试图找到单词的根源。 它删除了单词的所有前缀和后缀,因此我们正在构建的模型将对该单词有一个大致的了解,而不会陷入具有不同形式的同一个单词的所有复杂情况。 有多种类型的词干提取器,例如Porter Stemmer,Snowball Stemmer,Lancaster Stemmer等。我们将在代码中使用Lancaster Stemmer。 ( 在此处了解有关Stemmers的更多信息。)
向量化 (Vectorization)
It’s known that Machine Learning and Deep Learning models only accept numerical inputs. So we have to convert this stemmed list of words into some kind of numerical input so that we can feed it to the neural network. This is where vectorization methods like Bag of Words, TF-IDF, Word2vec, and others come into the picture.
众所周知,机器学习和深度学习模型仅接受数字输入。 因此,我们必须将词干列表转换为某种数字输入,以便将其馈送到神经网络。 这是矢量袋化方法,例如“词袋”,TF-IDF,Word2vec等。
We’ll be using Bag of Words (BoW) in our code. It basically describes the occurrence of a word within a document. In our case, we’ll be representing each sentence with a list of the length of all unique words collected in the list “words”. Each position in that list will be a unique word from “words”. If a sentence consists of a specific word, their position will be marked as 1 and if a word is not present in that position, it’ll be marked as 0.
我们将在代码中使用单词袋(BoW)。 它基本上描述了单词在文档中的出现。 在我们的例子中,我们将用“单词”列表中收集的所有唯一单词的长度列表来表示每个句子。 该列表中的每个位置都是“单词”中的唯一单词。 如果句子由特定单词组成,则其位置将标记为1,如果该位置不存在单词,则标记为0。
With this method though, the model can only understand the occurrence of a word in the sentence. The sequence of the words within the sentence will be lost, hence the name “Bag of Words”. Other methods like TF-IDF, Word2Vec tries to capture some of these lost semantics in their own way. I’d recommend you to try out other vectorization methods as well.
但是,使用这种方法,模型只能理解句子中单词的出现。 句子中单词的顺序将丢失,因此名称为“单词袋”。 其他方法(例如TF-IDF,Word2Vec)尝试以自己的方式捕获这些丢失的语义中的一些。 我建议您也尝试其他向量化方法。
Similarly, for the output, we’ll create a list which will be the length of the labels/tags we have in our JSON file. A “1” in any of those positions indicates the belonging of a pattern in that particular label/tag.
同样,对于输出,我们将创建一个列表,该列表将是我们在JSON文件中具有的标签/标签的长度。 在那些位置中的任何一个位置上的“ 1”表示该图案在该特定标签/标签中的归属。
stemmer = LancasterStemmer()
words = [stemmer.stem(w.lower()) for w in words if w not in "?"]
words = sorted(list(set(words)))
labels = sorted(labels)
training = []
output = []
out_empty = [0 for _ in range(len(labels))]
for x,doc in enumerate(docs_x):
bag = []
wrds = [stemmer.stem(w) for w in doc]
for w in words:
if w in wrds:
bag.append(1)
else:
bag.append(0)
output_row = out_empty[:]
output_row[labels.index(docs_y[x])] = 1
training.append(bag)
output.append(output_row)
#Converting training data into NumPy arrays
training = np.array(training)
output = np.array(output)
#Saving data to disk
with open("data.pickle","wb") as f:
pickle.dump((words, labels, training, output),f)We will be also saving all the processed data in a pickle file so that it can be used later for processing inputs from the user as well.
我们还将所有处理过的数据保存在一个pickle文件中,以便以后也可以将其用于处理来自用户的输入。
建立模型 (Building a Model)
Now that we’re done with data preprocessing, it’s time to build a model and feed our preprocessed data to it. The network architecture is not too complicated. We will be using Fully Connected Layers (FC layers) with two of them being hidden layers and one giving out the target probabilities. Hence, the last layer will be having a softmax activation.
现在我们已经完成了数据预处理,现在该构建模型并将预处理后的数据提供给模型了。 网络架构不是太复杂。 我们将使用完全连接层(FC层),其中两个为隐藏层,一个为目标概率。 因此,最后一层将具有softmax激活。
Feel free to mess around with the architecture and the numbers to get the model that suits your requirements. You could also choose to add a bit more steps into text preprocessing to get more out of the data. The more trial and error cycles you perform better will be your understanding of the architecture.
随意弄乱体系结构和编号以获得适合您要求的模型。 您还可以选择在文本预处理中添加更多步骤,以更多地利用数据。 您执行得越多的试验和错误周期就越多,这将是您对体系结构的理解。
tf.reset_default_graph()
net = tflearn.input_data(shape = [None, len(training[0])])
net = tflearn.fully_connected(net,8)
net = tflearn.fully_connected(net,8)
net = tflearn.fully_connected(net,len(output[0]), activation = "softmax")
net = tflearn.regression(net)
model = tflearn.DNN(net)All we have to do now is feed the data to this model and begin training. We will set our epochs to 200 and batch size to 8. Again, you can experiment with these numbers and find the right one for your data. After training, we will be saving it on the disk so that we can use the trained model in our Flask application.
我们现在要做的就是将数据输入该模型并开始训练。 我们将纪元设置为200,批量大小设置为8。同样,您可以尝试使用这些数字并为您的数据找到合适的数字。 训练后,我们会将其保存在磁盘上,以便我们可以在Flask应用程序中使用训练后的模型。
model.fit(training, output, n_epoch = 200, batch_size = 8, show_metric = True)
model.save("model.tflearn")If everything goes right, you should have files named “model.tflearn.data”, “model.tflearn.index”, and “model.tflearn.meta” in the working directory.
如果一切正常,则在工作目录中应该有名为“ model.tflearn.data”,“ model.tflearn.index”和“ model.tflearn.meta”的文件。
Your “main.py” file should look something like this:
您的“ main.py”文件应如下所示:
#Imports
import nltk
import os
from nltk.stem.lancaster import LancasterStemmer
import numpy as np
import tflearn
import tensorflow as tf
import random
import json
import pickle
#Loading Data
with open("intents.json") as file:
data = json.load(file)
#Initializing empty lists
words = []
labels = []
docs_x = []
docs_y = []
#Looping through our data
for intent in data['intents']:
for pattern in intent['patterns']:
pattern = pattern.lower()
#Creating a list of words
wrds = nltk.word_tokenize(pattern)
words.extend(wrds)
docs_x.append(wrds)
docs_y.append(intent['tag'])
if intent['tag'] not in labels:
labels.append(intent['tag'])
stemmer = LancasterStemmer()
words = [stemmer.stem(w.lower()) for w in words if w not in "?"]
words = sorted(list(set(words)))
labels = sorted(labels)
training = []
output = []
out_empty = [0 for _ in range(len(labels))]
for x,doc in enumerate(docs_x):
bag = []
wrds = [stemmer.stem(w) for w in doc]
for w in words:
if w in wrds:
bag.append(1)
else:
bag.append(0)
output_row = out_empty[:]
output_row[labels.index(docs_y[x])] = 1
training.append(bag)
output.append(output_row)
#Converting training data into NumPy arrays
training = np.array(training)
output = np.array(output)
#Saving data to disk
with open("data.pickle","wb") as f:
pickle.dump((words, labels, training, output),f)
tf.reset_default_graph()
net = tflearn.input_data(shape = [None, len(training[0])])
net = tflearn.fully_connected(net,8)
net = tflearn.fully_connected(net,8)
net = tflearn.fully_connected(net,len(output[0]), activation = "softmax")
net = tflearn.regression(net)
model = tflearn.DNN(net)
model.fit(training, output, n_epoch = 200, batch_size = 8, show_metric = True)
model.save("model.tflearn")建筑烧瓶应用 (Building Flask Application)
Now that we’ve trained our deep learning model, it’s time to integrate it into a web application. The framework we will be using here is Flask. Now explaining how to build a Flask application requires a series of articles on its own so I won’t be doing that here. However, I’ll make sure to include all the resources I referred to while building this application in the “References” section down below.
现在我们已经训练了深度学习模型,是时候将其集成到Web应用程序中了。 我们将在这里使用的框架是Flask。 现在说明如何构建Flask应用程序需要自己撰写一系列文章,因此在这里我不再做。 但是,在下面的“参考”部分中,我将确保在构建此应用程序时包括我参考的所有资源。
Here’s a link to my GitHub repository where you can access all the files to build the Flask application. I’d recommend you to copy all the files into your working directory so that it can access the trained model and pickle files.
这是我的GitHub存储库的链接 ,您可以在其中访问所有文件以构建Flask应用程序。 我建议您将所有文件复制到工作目录中,以便它可以访问经过训练的模型和泡菜文件。
We will be using AJAX for asynchronous transfer of data i.e you won’t have to reload your webpage every time you send an input to the model. The web application will respond to your inputs seamlessly. Let’s take a look at the HTML file.
我们将使用AJAX进行数据的异步传输,即,您不必在每次向模型发送输入时都重新加载网页。 Web应用程序将无缝响应您的输入。 让我们看一下HTML文件。
<!DOCTYPE html>
<html>
<title>Restaurant Chatbot</title>
<head>
<link href='https://fonts.googleapis.com/css?family=Alegreya' rel='stylesheet'>
<link rel="icon" href="">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.2.1/jquery.min.js"></script>
<style>
body {
font-family: monospace;
background-position: center;
background-repeat: no-repeat;
background-size: cover;
background-attachment: fixed;
}
h1 {
border: 1px solid white;
border-radius: 5px;
color: #ce9e62;
display: inline-block;Alegreya
font-size: 3em;
margin: 5;
padding: 10px;
}
#chatbox {
margin-top: auto;
margin-bottom: auto;
margin-left: auto;
margin-right: auto;
width: 40%;
margin-top: 60px;
}
#userInput {
margin-left: auto;
margin-right: auto;
width: 40%;
margin-top: 60px;
}
#textInput {
width: 90%;
border: none;
border-bottom: 3px solid black;
font-family: 'Alegreya';
font-size: 17px;
}
.userText {
color: white;
background-color: #4b6777;
font-family: 'Alegreya';
font-size: 17px;
text-align: center;
line-height: 30px;
border-radius: 5px;
}
.userText span {
padding:10px;
border-radius: 5px;
}
.botText {
color: #ce9e62;
background-color: #2c2c2c;
font-family: 'Alegreya';
font-size: 17px;
text-align: center;
line-height: 30px;
border-radius: 5px;
}
.botText span {
padding: 10px;
border-radius: 5px;
}
.boxed {
margin-left: auto;
margin-right: auto;
width: 100%;
margin-top: 60px;
border-radius: 5px;
}
input[type=text] {
bottom: 0;
width: 40%;
padding: 12px 20px;
margin: 8px 0;
box-sizing: border-box;
position: fixed;
border-radius: 5px;
}
</style>
</head>
<body background="{{ url_for('static', filename='images/slider.jpg') }}">
<img />
<center>
<h1>
Restaurant Chatbot
</h1>
</center>
<div class="boxed">
<div>
<div id="chatbox">
</div>
</div>
<div id="userInput">
<input id="nameInput" type="text" name="msg" placeholder="Ask me anything..." />
</div>
<script>
function getBotResponse() {
var rawText = $("#nameInput").val();
var userHtml = '<p class="userText"><span>' + rawText + "</span></p>";
$("#nameInput").val("");
$("#chatbox").append(userHtml);
document
.getElementById("userInput")
.scrollIntoView({ block: "start", behavior: "smooth" });
$.get("/get", { msg: rawText }).done(function(data) {
var botHtml = '<p class="botText"><span>' + data + "</span></p>";
$("#chatbox").append(botHtml);
document
.getElementById("userInput")
.scrollIntoView({ block: "start", behavior: "smooth" });
});
}
$("#nameInput").keypress(function(e) {
if (e.which == 13) {
getBotResponse();
}
});
</script>
</div>
</body>
</html>Have a look at the JavaScript section where we get the input from the user, sends it to the “app.py” file where it’s fed to the trained model and then receives the output back to display it on the app.
看一下JavaScript部分,我们从用户那里获取输入,然后将其发送到“ app.py”文件,在该文件中将其输入到经过训练的模型中,然后将输出接收回去以在应用程序上显示。
The “app.py” file is where all the routes are mentioned, input data is processed (Stemming and Bag of Words), and fed to the model for output. Let’s have a look at it.
“ app.py”文件是提及所有路由的地方,处理输入数据(词干和词袋),并将其馈送到模型以进行输出。 让我们来看看它。
#Imports
from flask import Flask, render_template, request, jsonify
import nltk
import datetime
from nltk.stem.lancaster import LancasterStemmer
import numpy as np
import tflearn
import tensorflow as tf
import random
import json
import pickle
stemmer = LancasterStemmer()
seat_count = 50
with open("intents.json") as file:
data = json.load(file)
with open("data.pickle","rb") as f:
words, labels, training, output = pickle.load(f)
#Function to process input
def bag_of_words(s, words):
bag = [0 for _ in range(len(words))]
s_words = nltk.word_tokenize(s)
s_words = [stemmer.stem(word.lower()) for word in s_words]
for se in s_words:
for i,w in enumerate(words):
if w == se:
bag[i] = 1
return np.array(bag)
tf.reset_default_graph()
net = tflearn.input_data(shape = [None, len(training[0])])
net = tflearn.fully_connected(net,8)
net = tflearn.fully_connected(net,8)
net = tflearn.fully_connected(net,len(output[0]), activation = "softmax")
net = tflearn.regression(net)
#Loading existing model from disk
model = tflearn.DNN(net)
model.load("model.tflearn")
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/get')
def get_bot_response():
global seat_count
message = request.args.get('msg')
if message:
message = message.lower()
results = model.predict([bag_of_words(message,words)])[0]
result_index = np.argmax(results)
tag = labels[result_index]
if results[result_index] > 0.5:
if tag == "book_table":
seat_count -= 1
response = "Your table has been booked successfully. Remaining tables: " + str(seat_count)
elif tag == "available_tables":
response = "There are " + str(seat_count) + " tables available at the moment."
elif tag == "menu":
day = datetime.datetime.now()
day = day.strftime("%A")
if day == "Monday":
response = "Chef recommends: Steamed Tofu with Schezwan Peppercorn, Eggplant with Hot Garlic Sauce, Chicken & Chives, Schezwan Style, Diced Chicken with Dry Red Chilli, Schezwan Pepper"
elif day == "Tuesday":
response = "Chef recommends: Asparagus Fresh Shitake & King Oyster Mushroom, Stir Fried Chilli Lotus Stem, Crispy Fried Chicken with Dry Red Pepper, Osmanthus Honey, Hunan Style Chicken"
elif day == "Wednesday":
response = "Chef recommends: Baby Pokchoi Fresh Shitake Shimeji Straw & Button Mushroom, Mock Meat in Hot Sweet Bean Sauce, Diced Chicken with Bell Peppers & Onions in Hot Garlic Sauce, Chicken in Chilli Black Bean & Soy Sauce"
elif day == "Thursday":
response = "Chef recommends: Eggplant & Tofu with Chilli Oyster Sauce, Corn, Asparagus Shitake & Snow Peas in Hot Bean Sauce, Diced Chicken Plum Honey Chilli Sauce, Clay Pot Chicken with Dried Bean Curd Sheet"
elif day == "Friday":
response = "Chef recommends: Kailan in Ginger Wine Sauce, Tofu with Fresh Shitake & Shimeji, Supreme Soy Sauce, Diced Chicken in Black Pepper Sauce, Sliced Chicken in Spicy Mala Sauce"
elif day == "Saturday":
response = "Chef recommends: Kung Pao Potato, Okra in Hot Bean Sauce, Chicken in Chilli Black Bean & Soy Sauce, Hunan Style Chicken"
elif day == "Sunday":
response = "Chef recommends: Stir Fried Bean Sprouts & Tofu with Chives, Vegetable Thou Sou, Diced Chicken Plum Honey Chilli Sauce, Diced Chicken in Black Pepper Sauce"
else:
for tg in data['intents']:
if tg['tag'] == tag:
responses = tg['responses']
response = random.choice(responses)
else:
response = "I didn't quite get that, please try again."
return str(response)
return "Missing Data!"
if __name__ == "__main__":
app.run()We first import all the required libraries and then load the pickle file in which we saved the preprocessed data. This will be required to create a BoW vector for the input data. Then we define a function “bag_of_words” where we provide user input and get a BoW vector as an output.
我们首先导入所有必需的库,然后加载用于保存预处理数据的pickle文件。 创建输入数据的BoW向量将需要此操作。 然后,我们定义一个函数“ bag_of_words”,在其中提供用户输入并获得BoW向量作为输出。
Remember the tags “menu”, “book_table” and “available_tables” with empty responses? We did that so we could provide custom responses to questions in those tags.
还记得带有空响应的标签“ menu”,“ book_table”和“ available_tables”吗? 我们这样做是为了对这些标签中的问题提供自定义响应。
For the questions related to what’s on the menu, we would first check what day of the week it is and according to that, the chatbot will recommend special dishes for the day.
对于与菜单上的内容有关的问题,我们将首先检查星期几,并根据此聊天机器人将推荐当天的特殊菜肴。
When the user asks to book a table, we decrement the counter “seat_count” by one. Now, of course, this isn’t how bookings work but the whole point of demonstrating this was to show the possibilities we can have with this chatbot. You could connect this bot to a database and conduct bookings accordingly. Or you could add any other additional tasks according to your requirements. Asking for available tables just shows the current value of “seat_count”. Whenever you reset the Flask server, the counter goes back to 50. This was done to show that you don’t have to always depend on the JSON file for a response.
当用户要求预订桌子时,我们将计数器“ seat_count”减一。 现在,当然,这不是预订的工作方式,而是演示这一点的全部目的是展示我们可以使用此聊天机器人获得的可能性。 您可以将此机器人连接到数据库并进行相应的预订。 或者,您可以根据需要添加其他任何其他任务。 询问可用表仅显示“ seat_count”的当前值。 每当您重置Flask服务器时,计数器都会回到50。这样做是为了表明您不必始终依赖JSON文件来进行响应。
Once the setup is complete, just run the “app.py” file and the Flask server will be live. It should look something like this:
设置完成后,只需运行“ app.py”文件,即可启动Flask服务器。 它看起来应该像这样:
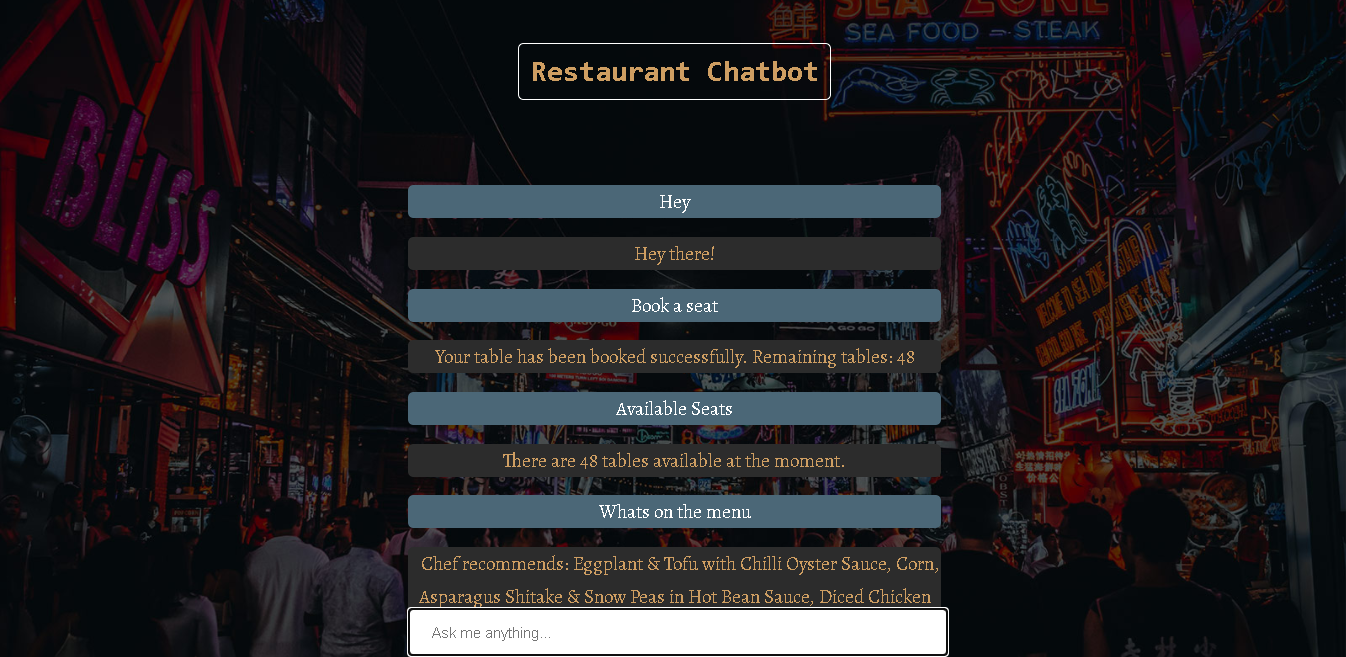
结论 (Conclusion)
The project is finally done and working like it’s supposed to. However, there are tons of stuff you can tweak and fine-tune in here. I’d love to hear what additional features you were able to add to this chatbot or any other modifications you have made to this project. You can go ahead and connect this chatbot to a database or integrate it with any website. Instead of using Bag of Words, you could also use other vectorization methods like TF-IDF, Word2Vec, etc. There is a high chance that these methods will improve the model’s accuracy in predicting the tags.
该项目终于完成并按预期工作。 但是,您可以在此处调整和微调很多东西。 我很想听听您能够添加到此聊天机器人的其他功能或对该项目进行的任何其他修改。 您可以继续将此聊天机器人连接到数据库,或将其与任何网站集成。 除了使用词袋之外,您还可以使用其他矢量化方法,例如TF-IDF,Word2Vec等。这些方法很有可能会提高模型在预测标签时的准确性。
As promised I have also listed all the blogs and videos I referred to while building this application. It’ll definitely help you get a deeper understanding of the project and its working.
如所承诺的,我还列出了在构建此应用程序时引用的所有博客和视频。 它肯定会帮助您更深入地了解该项目及其工作。
翻译自: https://towardsdatascience.com/how-to-build-a-basic-chatbot-from-scratch-f63a2ccf5262
fcn从头开始















 6005
6005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









