





gpt openai
Language modeling in NLP tries to solve a number of tasks such as text summarization, speech recognition, Optical Character Recognition (OCR), machine translation, part-of-speech tagging, and many more.
NLP中的语言建模尝试解决许多任务,例如文本摘要,语音识别,光学字符识别(OCR),机器翻译,词性标记等等。
Leveraging the task of natural language understanding for language models, OpenAI proposed a GPT model in the paper “Improving Language Understanding by Generative Pre-Training (2018)” that achieves state-of-the-art results in 9 out of 12 NLP tasks.
借助自然语言理解对语言模型的任务,OpenAI在论文“通过生成式预训练改善语言理解(2018年)”中提出了GPT模型。 在12个NLP任务中有9个获得了最先进的结果。
In this series, I will introduce you to the language models GPT, GPT-2, and GPT-3 proposed by OpenAI.
在本系列中,我将向您介绍OpenAI提出的语言模型GPT,GPT-2和GPT-3。
The flow of the series will be as mentioned below.
该系列的流程如下所述。
1. OpenAI’s GPT — Part 1: Unveiling the GPT Model
1. OpenAI的GPT-第1部分:发布GPT模型
2. OpenAI’s GPT — Part 2: Unveiling the GPT-2 Model
2. OpenAI的GPT-第2部分:发布GPT-2模型
3. OpenAI’s GPT — Part 3: Introduction to GPT-3
3. OpenAI的GPT-第3部分:GPT-3简介
4. OpenAI’s GPT — Part 4: Deeper Insights into GPT-3
4. OpenAI的GPT-第4部分:对GPT-3的更深入的了解
5. OpenAI’s GPT — Part 5: Implementation of GPT-3
5. OpenAI的GPT-第5部分:GPT-3的实现
1.背景 (1. Background)
- The task of obtaining large manually labeled data is not feasible as it is expensive and there is a lack of labeled data. On the other hand, text corpora of unlabeled data are present in abundance. 获取大型手动标记数据的任务不可行,因为它很昂贵,而且缺少标记数据。 另一方面,未标记数据的文本语料库大量存在。
- Therefore, to make the models independent of the supervised learning approach it becomes crucial to extract valuable information from the unlabeled and the labeled data with the help of semi-supervised learning. 因此,要使模型独立于监督学习方法,借助半监督学习从未标记和标记的数据中提取有价值的信息就变得至关重要。
- Presently, not more than word-level or sentence-level information can be effectively obtained from the unlabeled text. To generate information from unlabeled data for more complex tasks, the following two challenges are faced. 目前,从未标记的文本中可以有效地获得不多于单词或句子的信息。 为了从未标记的数据生成信息以完成更复杂的任务,面临以下两个挑战。
1. Lack of clarity about the type of optimization objectives that will be effective in learning for the tasks requiring transfer.
1.缺乏关于在学习需要转移的任务时将有效学习的优化目标类型的信息。
2. No technique has received a common consensus as the most effective technique for transferring the learned representations to the target task.
2.没有一种技术作为将学习的表示转移到目标任务的最有效技术而获得共识。
- Moreover, some of the existing techniques require making changes to the architecture based on specific tasks. Hence, no model was developed that could provide universal representation for a varied range of tasks. 此外,某些现有技术需要根据特定任务对体系结构进行更改。 因此,没有开发出能够为各种任务提供通用表示的模型。
2.简介 (2. Introduction)
- A transformer-based architecture is chosen for the GPT model as it can provide long-range language inferences, unlike LSTM which was used in the previous similar work on text classification. 为GPT模型选择了基于变压器的体系结构,因为它可以提供远程语言推断,这与以前的类似文本分类工作中使用的LSTM不同。
- Due to its ability to model long-range dependencies, the transformer also performs significantly well on NLP tasks like document generation, machine translation, and syntactic parsing. 由于具有对远程依赖关系进行建模的能力,因此转换器在NLP任务(例如文档生成,机器翻译和语法分析)上也表现出色。

- The proposed model [1] employes a semi-supervised learning approach with the usage of unsupervised pre-training and supervised fine-tuning. 提出的模型[1]采用了半监督学习方法,并使用了无监督预训练和监督微调。
- First, to learn the parameters of a neural network, a language modeling objective is used on the unlabeled data. Second, a supervised objective is used for adapting the learned parameters to a particular target task. 首先,要学习神经网络的参数,对未标记的数据使用语言建模目标。 其次,有监督的目标用于使学习到的参数适应特定的目标任务。
The model is termed as “task agnostic” as it is not specific to a single NLP task but rather provides a generalizable architecture that can suit different NLP tasks with minimal changes for transfer.
该模型被称为“ 任务不可知的 ”,因为它不是特定于单个NLP任务的,而是提供了一种可通用的体系结构,该体系结构可以适应不同的NLP任务,而对传输的更改最少。
3.拟议框架 (3. Proposed Framework)
The training is performed in two stages — unsupervised pre-training and supervised fine-tuning.
训练分两个阶段进行: 无监督的预训练和监督 的微调 。
3.1无人监督的预训练 (3.1 Unsupervised pre-training)
- The first stage involves learning a model on a large corpus of text. 第一阶段涉及学习大量文本语料库的模型。
- Given the input corpus of tokens, U = {u1,…,un}, using the language modeling objective, the log probability of u_i with respect to the previous tokens is maximized. 给定输入的令牌语料库U = {u1,…,un},使用语言建模目标,u_i相对于先前令牌的对数概率最大化。
- In the objective function, P is the conditional probability, k refers to the size of the context window and Θ are parameters of a neural network. 在目标函数中,P是条件概率,k是上下文窗口的大小,Θ是神经网络的参数。
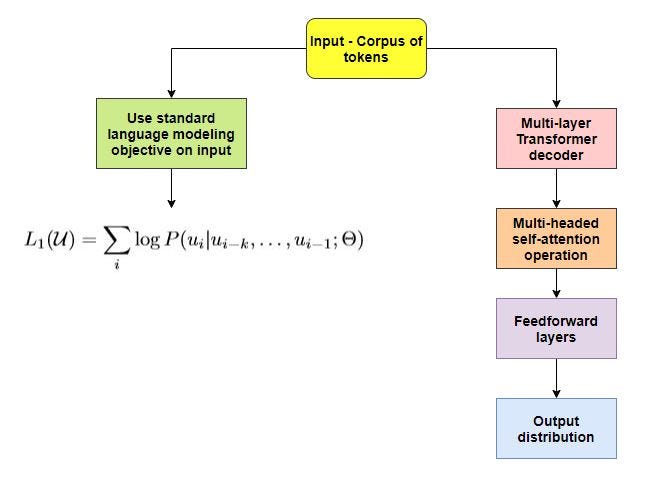
- The attention and output probability distribution is calculated as follows. 注意和输出概率分布计算如下。
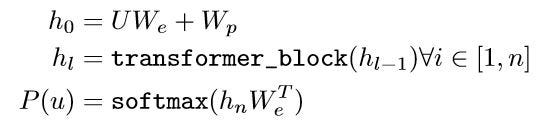
- U is input corpus of tokens, W_e refers to token embedding matrix and W_p for position embedding matrix. U是令牌的输入语料,W_e是令牌嵌入矩阵,W_p是位置嵌入矩阵。
To know more details about the different transformer components, visit here.
要了解有关不同变压器组件的更多详细信息,请访问此处 。
3.2监督微调 (3.2 Supervised fine-tuning)
- The second stage involves fine-tuning, i.e. making the model adaptable to certain tasks. 第二阶段涉及微调,即使模型适应于某些任务。
- A labeled dataset C is taken as input. Probability of label y given tokens x_1,…,x_m is obtained after passing data through the pre-trained model and further layers. 带标签的数据集C被用作输入。 给定标记x_1,…,x_m的标签y的概率是在将数据通过预训练模型和其他层传递之后获得的。
- Further, a maximizing objective is applied using the log probability. 此外,使用对数概率来应用最大化目标。
Lastly, when unsupervised pre-training was done before fine-tuning, several advantages like improved generalization and accelerated convergence were witnessed. Therefore, a combination of both the objective functions using weight λ was considered.
最后,当在微调之前进行无监督的预训练时,可以看到诸如改进泛化和加速收敛的几个优点。 因此,考虑了使用权重λ的两个目标函数的组合。

3.3特定于任务的输入转换 (3.3 Task-specific input transformations)
- To fine-tune the proposed GPT model for certain tasks like textual entailment, semantic similarity, question answering and commonsense reasoning, certain transformations need to be done to the input data structure so that the model can process. 为了针对某些任务(如文本蕴涵,语义相似度,问题回答和常识推理)微调提出的GPT模型,需要对输入数据结构进行某些转换,以便模型可以处理。
3.3.1 Textual Entailment
3.3.1文字蕴含
- Premise p and hypothesis h token sequences are concatenated with a delimiter ($) in between. 前提p和假设h令牌序列之间用定界符($)连接。

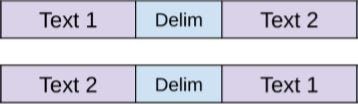
3.3.2 Semantic Similarity
3.3.2语义相似度
- Two possible sentence orderings are processed independently with both the texts containing a delimiter between them. 两种可能的句子排序都独立处理,两个文本之间都包含定界符。
3.3.3 Question Answering and Commonsense Reasoning
3.3.3问答和常识推理
- Input comprises a document, a question, and a collection of possible answers. Transformation is done by concatenating the document with the question for each possible answer in the set and placing a delimiter between them. 输入内容包括文档,问题和可能答案的集合。 转换是通过将文档与该问题针对集合中的每个可能答案并在它们之间放置定界符来完成的。

The overall proposed framework is as shown below.
总体建议框架如下所示。
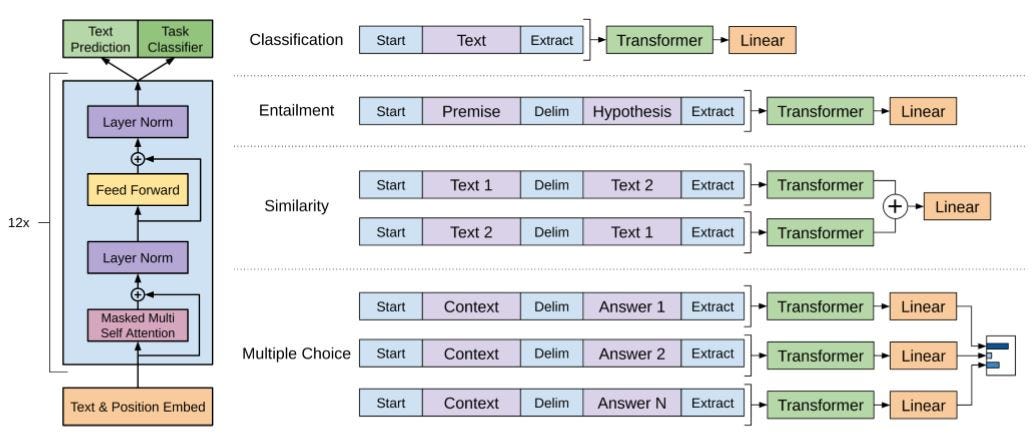
4.实验细节 (4. Experimental Details)
4.1无人监督的预训练 (4.1 Unsupervised pre-training)
- The language model is trained on the BooksCorpus dataset. It is a huge dataset that contains 7000 unique unpublished books. 语言模型在BooksCorpus数据集上训练。 它是一个巨大的数据集,其中包含7000本书未出版。
- The books are part of various genres such as adventure, fantasy, and romance. 这些书是冒险,幻想和浪漫等各种流派的一部分。
- This dataset forms a perfect fit for the language model as it provides long contiguous texts that can help the model to learn to utilize the long-range information. 该数据集提供了较长的连续文本,可以帮助模型学习利用远程信息,因此非常适合语言模型。
Specifications of some of the parameters chosen for training are as mentioned below.
选择用于训练的某些参数的规格如下所述。
— 12 layer decoder-only transformer with masked self-attention heads.
— 12层仅解码器的变压器,带屏蔽的自注意力头。
— Adam optimizer with a maximum learning rate of 2.5e-4.
-Adam 优化器 ,最大学习率为2.5e-4 。
— Training was done with 100 epochs with mini batches of size 64 on randomly sampled contiguous sequences of 512 tokens.
-在随机采样的512个令牌的连续序列上,以100个纪元和64 个小 批量的批次进行了训练。
— Gaussian Error Linear Unit (GELU) activation function was used.
—使用了高斯误差线性单位(GELU)激活函数。
For detailed information about the experimental setup, refer to section 4 of [1].
有关实验设置的详细信息,请参见[1]的第4节。
4.2监督微调 (4.2 Supervised fine-tuning)
Dropout with a rate of 0.1 is added to the classifier.
速率为0.1的 辍学添加到分类器。
The learning rate is taken as 6.25e-5 and batch size is equal to 32.
学习率取为6.25e-5 , 批处理大小等于32 。
With 3 epochs of training, the model in most cases learns quickly.
经过3个时期的训练,该模型在大多数情况下可以快速学习。
The linear learning rate decay schedule is used with a 0.2% warmup rate for training.
线性学习率衰减时间表用于训练的预热率为0.2% 。
5.结果和推论 (5. Results and Inferences)
- Results from the supervised fine-tuning and comparisons of the proposed model in different scenarios are described below. 下面描述了在不同场景下有监督的微调和所提出模型的比较结果。
Fine-tuning was performed on the following variety of four supervised tasks — natural language inference, semantic similarity, question answering, and text classification.
对以下四个受监管任务进行了微调:自然语言推论,语义相似性,问题解答和文本分类。
5.1自然语言推论 (5.1 Natural Language Inference)
Through this task, the relationship between the input texts is analyzed in terms of entailment, contradiction, or neutral.
通过这个任务,输入文本之间的关系蕴涵 , 矛盾 ,或中性的方面进行了分析。
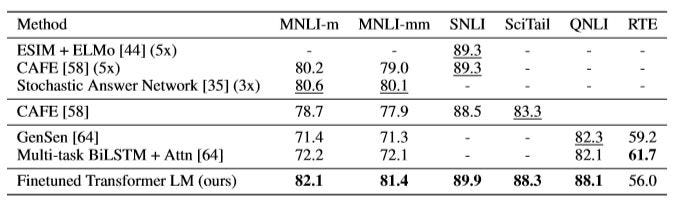
The model is evaluated on the five datasets from diverse sources — image captions (SNLI), science exams (SciTail), Wikipedia articles (QNLI), transcribed speech, popular fiction, and government reports (MNLI) and news articles (RTE).
的 该模型在来自不同来源的五个数据集上进行了评估-图像标题( SNLI ),科学考试( SciTail ),维基百科文章( QNLI ),转录语音,通俗小说,政府报告( MNLI )和新闻文章( RTE )。
The proposed model outperforms the previous state-of-the-art methods on four out of the five given datasets. An improvement of 1.5% on MNLI, 5.8% on QNLI, 5% on SciTail, and 0.6% on SNLI can be witnessed.
所提出的模型在五个给定的数据集中有四个优于传统的方法。 可以看到MNLI上升了1.5% ,QNLI上升了5.8% ,SciTail上升了5% ,SNLI上升了0.6% 。
5.2问题解答和常识推理 (5.2 Question Answering and Commonsense Reasoning)
- In this task of question answering, prediction of the answer is done on the basis of the document text provided and the question asked. 在此问题解答任务中,将根据提供的文档文本和提出的问题对答案进行预测。
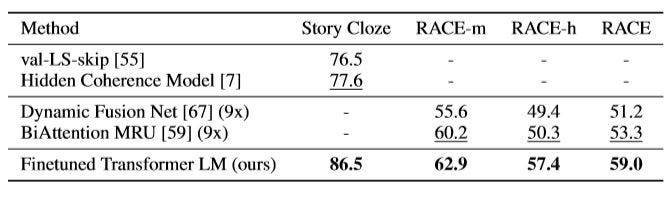
RACE dataset which comprises English passages and questions related to school exams is used for the evaluation. This dataset is particularly beneficial because it contains a large number of reasoning type questions as opposed to datasets like CNN or SQuAD.
RACE数据集包括英语段落和与学校考试有关的问题,用于评估。 该数据集特别有益,因为与CNN或SQuAD这样的数据集相比,它包含大量推理类型的问题。
The model is also evaluated on the Story Cloze Test, wherein endings to multi-sentence stories are chosen from two options.
还可以通过Story Cloze Test评估模型,其中从两个选项中选择多句故事的结尾。
Model’s success in handling long-range information effectively can be witnessed by an improvement of 8.9% on Story Cloze, and 5.7% overall on RACE over the previous best methods.
与之前的最佳方法相比,Story Cloze改进了8.9% ,RACE总体提高了5.7% ,可以证明Model在有效处理远程信息方面的成功。
5.3语义相似度和分类 (5.3 Semantic Similarity and Classification)
- Semantic similarity is a challenging task that involves checking for equivalence of two sentences based on semantics. 语义相似性是一项艰巨的任务,涉及基于语义检查两个句子的对等性。
Three datasets are used for the evaluation of this task — the Microsoft Paraphrase corpus (MRPC), the Quora Question Pairs (QQP) dataset, and the Semantic Textual Similarity benchmark (STS-B).
三个数据集用于评估此任务-Microsoft复述语料库( MRPC ),Quora问题对( QQP )数据集和语义文本相似性基准( STS-B )。
- New results surpass the previous state-of-the-art results on two of the three semantic similarity tasks. 在三个语义相似性任务中的两个上,新结果超过了以前的最新结果。
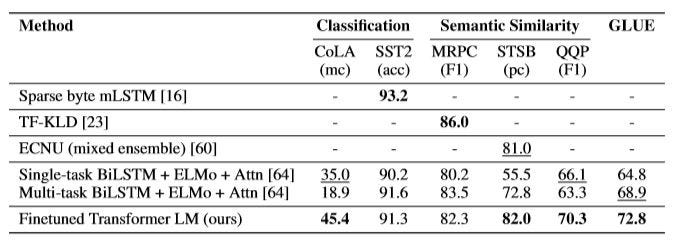
For classification, Corpus of Linguistic Acceptability (CoLA) is taken as an evaluation task that tests the grammatical correctness of a sentence.
对于分类, 将语言可接受性语料库(CoLA)用作评估任务,以测试句子的语法正确性。
Stanford Sentiment Treebank (SST-2), a standard binary classification task, is also used for evaluation.
标准二进制分类任务Stanford Sentiment Treebank(SST-2)也用于评估。
On CoLA, the model obtains a score of 45.4 whereas with SST-2 the accuracy obtained is 93.2%. [See figure 12]
在CoLA上,该模型获得45.4的得分,而在SST-2中,该模型的得分为93.2% 。 [见图12]
The model significantly improves on the GLUE benchmark with an overall score of 72.8. [See figure 12]
该模型在GLUE基准上得到了显着改进,总体得分为72.8 。 [见图12]
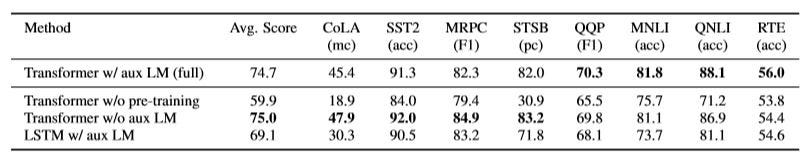
5.4消融研究 (5.4 Ablation Studies)
First, the effectiveness of the auxiliary LM objective is tested. Results indicate that it benefits larger datasets and not smaller datasets.
首先,测试辅助LM物镜的有效性。 结果表明,它有益于较大的数据集而不是较小的数据集。
Second, the effect of using a transformer over a single layer 2048 unit LSTM is observed. An average score drop of 5.6 is witnessed in the latter case.
第二,观察到在单层2048单位LSTM上使用变压器的效果。 在后一种情况下,平均得分下降了5.6。
Finally, the effectiveness of performing pre-training is evaluated. Without pre-training, the performance decreases by 14.8% across all the tasks.
最后,评估执行预训练的有效性。 如果不进行预训练,则所有任务的性能都会下降14.8%。
六,结论 (6. Conclusion)
- A framework that improves natural language understanding with the help of unsupervised pre-training and supervised fine-tuning is proposed. 提出了一种在无监督的预训练和有监督的微调的帮助下提高自然语言理解的框架。
The proposed task agnostic model generalizes well to a number of tasks such as natural language inference, semantic similarity, question answering, and text classification.
所提出的任务不可知模型很好地概括了许多任务,例如自然语言推断,语义相似性,问题回答和文本分类。
- The significant improvement in performance over 9 out of the 12 datasets shows the potential of this model in improving natural language understanding with unsupervised learning in future tasks. 在12个数据集中的9个数据集中,性能的显着提高表明,该模型具有在未来任务中无监督学习的情况下提高自然语言理解的潜力。
7.参考 (7. References)
[1] Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018): 12.
[1] Radford,Alec等。 “通过生成式预训练来提高语言理解能力。” (2018):12。
[2] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
[2] Vaswani,Ashish等人。 “注意力是您所需要的。” 神经信息处理系统的研究进展 。 2017。
翻译自: https://medium.com/visionwizard/openais-gpt-part-1-unveiling-the-gpt-model-6cc1d334bf0d
gpt openai















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









