





 本文介绍了如何利用Simple Transformers库进行文本分类任务,该库基于transformer模型如BERT和RoBERTa,适用于Python和Java开发者,是人工智能和机器学习领域的实践工具。
本文介绍了如何利用Simple Transformers库进行文本分类任务,该库基于transformer模型如BERT和RoBERTa,适用于Python和Java开发者,是人工智能和机器学习领域的实践工具。
变形金刚图纸
自然语言处理 (Natural Language Processing)
Using Transformer models has never been simpler! Yes that’s what Simple Transformers author Thilina Rajapakse says and I agree with him so should you. You might have seen lengthy code with hundreds of lines to implement transformers models such as BERT, RoBERTa, etc. Once you understand how to use Simple Transformers you will know how easy and simple it is to use transformer models.
使用Transformer模型从未如此简单! 是的,这就是《 Simple Transformers作者Thilina Rajapakse所说的,我也同意他的看法,你也应该同意。 您可能已经看到了数百行的冗长代码,以实现诸如BERT,RoBERTa等的变压器模型。一旦了解了如何使用Simple Transformers您就会知道使用变压器模型是多么容易和简单。
TheSimple Transformers library is built on top of Hugging Face Transformers library. Hugging Face Transformers provides state-of-the-art general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, T5, etc.) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) and provides more than thousand pre-trained models and covers around 100+ languages.
Simple Transformers库建立在Hugging Face Transformers库的顶部。 拥抱脸变形金刚 提供用于自然语言理解(NLU)和自然语言生成(NLG)的最新通用架构(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet,T5等),并提供千种预先训练的模型,涵盖了约100多种语言。
Simple Transformers can be used for Text Classification, Named Entity Recognition, Question Answering, Language Modelling, etc. In the article, we will solve the binary classification problem with Simple Transformers on NLP with Disaster Tweets dataset from Kaggle. Let’s get started.
Simple Transformers可用于文本分类,命名实体识别,问题回答,语言建模等。在本文中,我们将使用 Kaggle的Disaster Tweets数据集在NLP上使用Simple Transformers解决二进制分类问题。 让我们开始吧。
导入库和数据集 (Import libraries & datasets)
Download dataset from Kaggle to Colab. From your Kaggle profile navigate to My Account > API and then click on Create New API Token. This will download the kaggle.json file. Once you have this file, run the below code. During the execution, it will prompt you to upload a JSON file so you can upload the kaggle.json file.
将数据集从Kaggle下载到Colab。 在您的Kaggle个人资料中,导航至“ My Account > API ,然后单击“ Create New API Token. 这将下载kaggle.json文件。 拥有此文件后,运行以下代码。 执行期间,它将提示您上传JSON文件,以便您可以上传kaggle.json文件。
from google.colab import files
files.upload()
!pip install -q kaggle
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions download -c nlp-getting-startedGoogle Colab comes with transformers pre-installed. Here we are upgrading the transformers library so we will have the latest version of it and then install Simple Transformers:
Google Colab预先安装了变压器。 在这里,我们正在升级转换器库,因此我们将拥有它的最新版本,然后安装简单转换器:
!pip install --upgrade transformers
!pip install simpletransformersNow, import all the necessary libraries:
现在,导入所有必需的库:
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from simpletransformers.classification import ClassificationModel, ClassificationArgs前处理 (Preprocessing)
We will now load train and test datasets into pandas data frames namely train & test. There are 7613 records in the train set and 3263 records in the test set.
现在,我们将训练和测试数据集加载到熊猫数据框中,即训练和测试。 火车集中有7613条记录,测试集中有3263条记录。
train = pd.read_csv(‘/content/train.csv’)
test = pd.read_csv(‘/content/test.csv’)print(‘Shape of train set {}’.format(train.shape))
print(‘Shape of test set {}’.format(test.shape))
>>> Shape of train set (7613, 5)
>>> Shape of test set (3263, 4)
Since we don’t need ‘id’, ‘keyword’ & ‘location’ columns we will remove these columns from both train & test data.
由于我们不需要'id' , 'keyword'和'location'列,因此我们将从训练和测试数据中删除这些列。
train.drop([‘id’, ‘keyword’, ‘location’], axis=1, inplace=True)
test.drop([‘id’, ‘keyword’, ‘location’], axis=1, inplace=True)There are no null values in both the datasets. So we don’t have to worry about handling missing values.
两个数据集中都没有空值。 因此,我们不必担心处理缺失值。
train.isnull().sum().sum()
>> 0test.isnull().sum().sum()
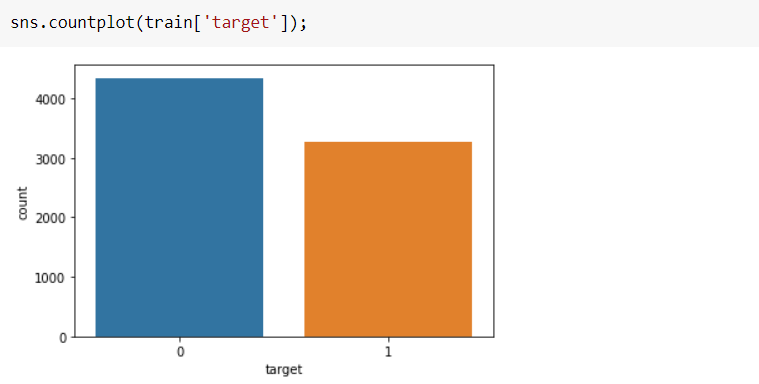
>> 0Let’s look at the target distribution.
让我们看一下目标分布。
We will use train test split and use 80% of the data for building the classification model.
我们将使用训练测试拆分,并使用80%的数据来构建分类模型。
train.columns = ['text', 'labels']train_df, valid_df = train_test_split(train, test_size=0.2, stratify=train[‘labels’], random_state=42) 初始化 ClassificationModel (Initialize a ClassificationModel)
Since we are trying to solve binary text classification, we will have to use ClassificationModel as per this table.
由于我们正在尝试解决二进制文本分类,因此我们将必须根据此表使用ClassificationModel 。
For the ClassificationModel we need to pass model_type and model_name. We will use roberta and roberta_base. However, you are free to select any model from this list and experiment.
对于ClassificationModel model_name我们需要传递model_type和model_type 。 我们将使用roberta和roberta_base 。 不过,你可以自由选择任何模型这个名单和实验。
Deep Learning models such as transformers run on CUDA enabled GPU. By default, CUDA is enabled. Before using Simple Transformers make sure GPU is on in your system. Since we are dealing with binary classification num_labels should be set to 2.
诸如变压器之类的深度学习模型在启用CUDA的GPU上运行。 默认情况下,CUDA是启用的。 使用Simple Transformers之前,请确保系统中的GPU已打开。 由于我们正在处理二进制分类, num_labels应将num_labels设置为2。
There are several parameters we can configure for the classification model which can be found here. Here we are using only three parameters: num_train_epochs, overwrite_output_dir & manual_seed. Some of the other important and most commonly used parameters are — learning_rate, train_batch_size, etc.
我们可以为分类模型配置几个参数,可以在这里找到。 在这里,我们仅使用三个参数: num_train_epochs , overwrite_output_dir和manual_seed 。 其他一些重要和最常用的参数是- learning_rate , train_batch_size等。
model_args = ClassificationArgs(num_train_epochs=1, overwrite_output_dir=True, manual_seed=42)model = ClassificationModel(model_type='roberta', model_name='roberta-base', use_cuda=True, num_labels=2, args=model_args)训练模型 (Train the model)
The train_model() method trains the model using thetrain_df dataframe. This will run for one epoch as we have set num_train_epoch to 1.
train_model()方法使用train_df数据帧训练模型。 我们将num_train_epoch设置为1,这将运行一个纪元。
model.train_model(train_df)评估模型 (Evaluate the model)
The eval_model() method will evaluate the model using the valid_df dataframe and returns 3 outputs.
eval_model()方法将使用valid_df数据帧评估模型,并返回3个输出。
result, model_outputs, wrong_preds = model.eval_model(valid_df)Since the evaluation metric for this Competition is f1_score, let us calculate the f1_score using sklearn.
由于本次比赛的评价指标是f1_score ,让我们计算f1_score使用sklearn。
predictions = []
for x in model_outputs:
predictions.append(np.argmax(x))
print(‘f1 score:’, f1_score(valid_df[‘labels’], predictions))>>> f1 score: 0.8134044173648134对测试集的预测 (Prediction on the test set)
The predict() method will be used to make predictions on unseen data. After making a prediction on the test and submitting to Kaggle gave f1_score of 0.81949 on the leaderboard.
predict()方法将用于对看不见的数据进行预测。 对测试做出预测并提交给Kaggle后,在排行榜上的f1_score为0.81949 。
test_predictions, raw_outputs = model.predict(test[‘text’])
sample_sub[‘target’] = test_predictions
sample_sub.to_csv(‘submission.csv’,index=False)
files.download(‘submission.csv’)This is really good score considering we have experimented with only one transformer model on 80% of train data and also we haven’t explored hyper-parameter optimizations, early stopping & k-fold cross validation. If we can try all these we can further improve the score.
考虑到我们仅对80%的火车数据进行了一个变压器模型实验,而且还没有探索超参数优化,提早停止和k折交叉验证,因此这确实是一个不错的成绩。 如果我们可以尝试所有这些,我们可以进一步提高分数。
Full code can be found here on Colab. You can also view the same code below:
完整的代码可以发现这里的Colab。 您还可以在下面查看相同的代码:
结论 (Conclusion)
Hope you enjoyed reading this tutorial and understood how to use Simple Transformers for Classification tasks.
希望您喜欢阅读本教程并了解如何将简单变压器用于分类任务。
Thank you so much for taking out time to read this article. You can reach me at https://www.linkedin.com/in/chetanambi/
非常感谢您抽出宝贵的时间阅读本文。 您可以通过https://www.linkedin.com/in/chetanambi/与我联系
变形金刚图纸















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









