





梯度下降法
介绍 (Introduction)
Gradient Descent is a first order iterative optimization algorithm where optimization, often in Machine Learning refers to minimizing a cost function J(w) parameterized by the predictive model's parameters. Additionally, by first-order we mean that Gradient Descent only takes into account the first derivative when performing updates of the parameters.
梯度下降是一阶迭代优化算法,其中优化(通常在机器学习中)是指最小化由预测模型的参数参数化的成本函数J(w)。 另外,一阶是指梯度下降在执行参数更新时仅考虑一阶导数。
No matter what happens, at some point in your Machine Learning or Deep Learning journey, you will hear about something called Gradient Descent. A vital piece to the puzzle for many Machine Learning algorithms, I highly recommend that it’s not treated as a black box by practitioners.
无论发生什么情况,在您的机器学习或深度学习过程中的某个时刻,您都会听到有关梯度下降的信息。 对于许多机器学习算法来说,这是一个难题的重要组成部分,我强烈建议从业者不要将其视为黑匣子。
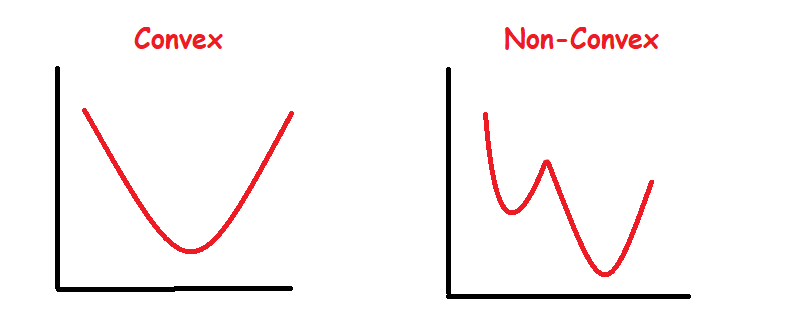
In order to minimize the cost function, we aim to either find the global minimum which is quite feasible if the objective function is convex. Nonetheless, in many scenarios such as deep learning task our objective function tends to be non-convex, thereby finding the lowest possible value of the objective function has been highly regarded as a suitable solution.
为了最小化成本函数,我们的目标是找到一个全局最小值,如果目标函数是凸的 ,则这是非常可行的。 尽管如此,在诸如深度学习任务之类的许多情况下,我们的目标函数往往是非凸的,因此,将目标函数的尽可能低的值视为高度合适的解决方案。
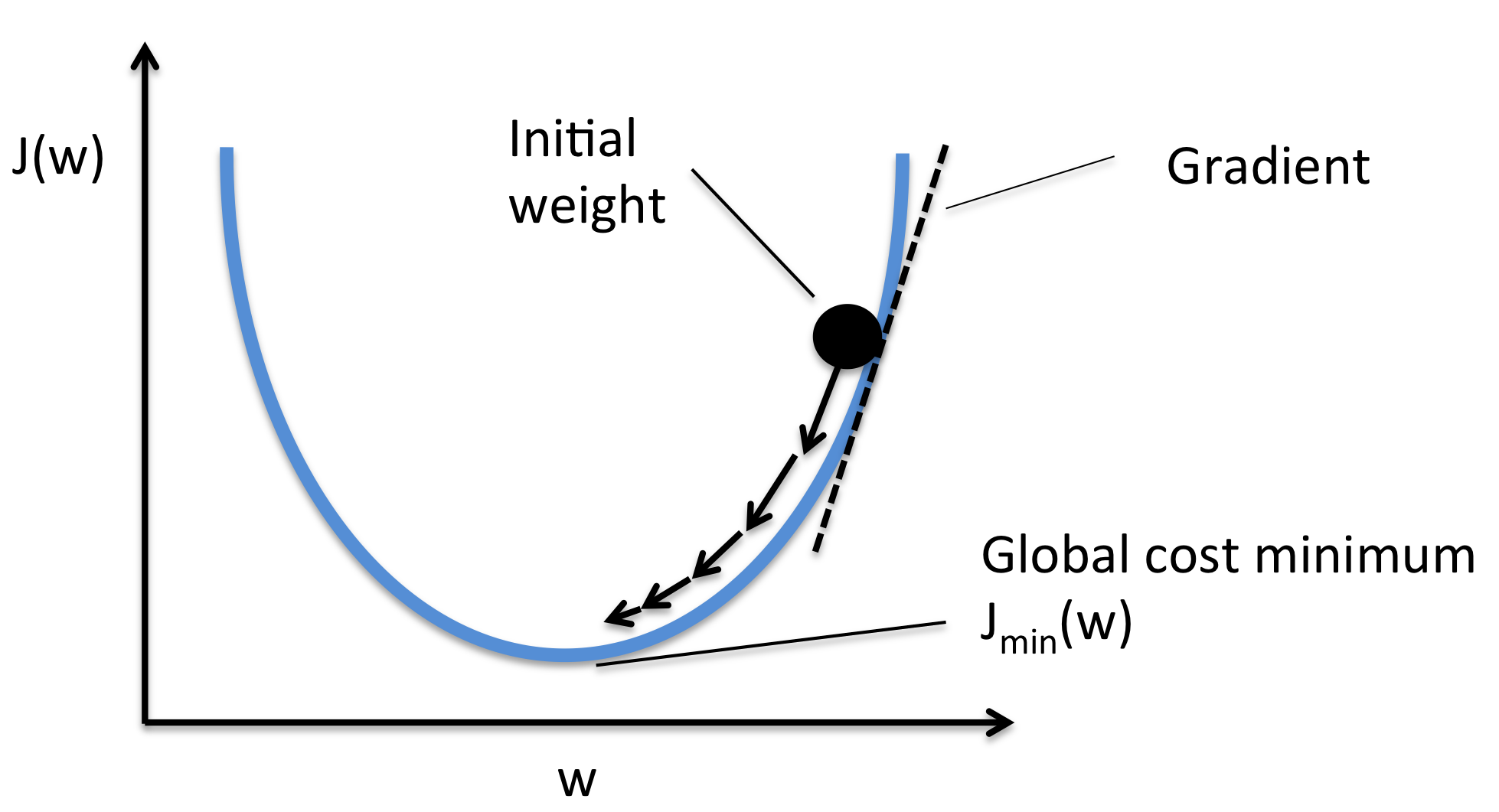
To find the local minimum of the function we take steps proportional to the negative of the gradient of the function at the current point (Source: Wikipedia). Frankly, we start with a random point on the objective function and move in the negative direction towards the global/local minimum.
为了找到该函数的局部最小值,我们采取与该函数在当前点处的梯度的负值成比例的步骤(来源: Wikipedia )。 坦白说,我们从目标函数上的随机点开始,然后朝整个全局/局部最小值的负方向移动。
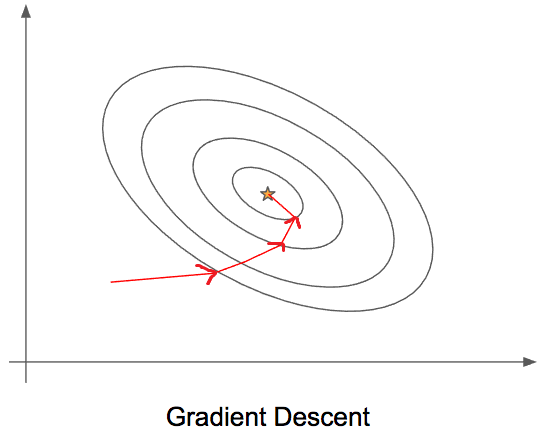
There are many different adaptations that could be made to Gradient Descent to make it run more efficiently for different scenarios; Each adaptation to Gradient Descent has its own pros and cons as we will share below:
可以对Gradient Descent进行多种调整,以使其在不同情况下更有效地运行。 每种适应Gradient Descent的方法都有其优缺点,我们将在下面分享:
批次梯度下降 (Batch Gradient Descent)
Batch Gradient Descent refers to the sum of all observations on each iteration. In other words, Batch Gradient Descent calculates the error for each observation in the batch (remember this is the full training data) and updates the predictive model only after all observations have been evaluated — A more technical way to say this is “Batch Gradient Descent performs parameter updates at the end of each epoch” (one epoch refers to one iteration through the entire training data).
批梯度下降是指每次迭代中所有观测值的总和。 换句话说,批次梯度下降计算批次中每个观测值的误差(请记住,这是完整的训练数据)并仅在评估所有观测值之后才更新预测模型-一种更技术性的说法是“ 批次梯度下降”在每个时期的末尾执行参数更新 (一个时期是指整个训练数据的一次迭代)。
Pros
优点
- More stable convergence and error gradient than Stochastic Gradient descent 比随机梯度下降法更稳定的收敛和误差梯度
- Embraces the benefits of vectorization 拥抱矢量化的好处
- A more direct path is taken towards the minimum 朝着最小方向走更直接的路径
- Computationally efficient since updates are required after the run of an epoch 计算效率高,因为在运行纪元后需要更新
Cons
缺点
- Can converge at local minima and saddle points 可以收敛于局部最小值和鞍点
- Slower learning since an update is performed only after we go through all observations 学习更新后才进行学习,因此学习速度较慢
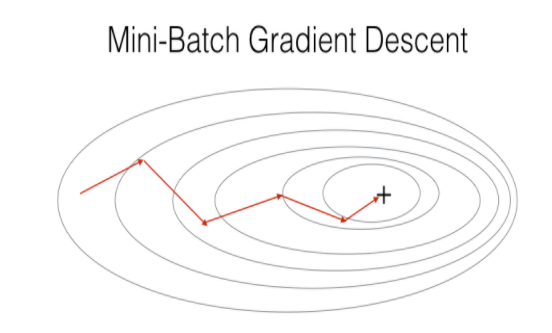
小批量梯度下降 (Mini-Batch Gradient Descent)
If Batch Gradient Descent sums over all observation on each iteration, Mini Batch Gradient Descent sums over a lower number of samples (a mini-batch of the samples) on each iteration — this variant reduces the variance of the gradient since we sum over a designated number of samples (depending on the mini-batch size) on each update.
如果每次迭代的所有观察结果都具有“批次梯度下降”的总和,则“每次迭代”中的较小数量的样本(样本的小批量)的“最小批次梯度下降”总和-由于我们在指定的点求和,因此该变体减小了梯度的方差每次更新的样本数(取决于最小批量)。
Note: This variation of Gradient Descent is often the recommended technique among Deep Learning practitioners, but we must consider there is an extra hyperparameter which is the “batch sizes”
注意 :这种梯度下降的变化通常是深度学习从业人员推荐的技术,但是我们必须考虑还有一个额外的超参数,即“批量大小”
Pros
优点
- Convergence is more stable than Stochastic Gradient Descent 收敛比随机梯度下降更稳定
- Computationally efficient 计算效率高
- Fast Learning since we perform more updates 快速学习,因为我们执行更多更新
Cons
缺点
- We have to configure the Mini-Batch size hyperparameter 我们必须配置Mini-Batch大小超参数
随机梯度下降 (Stochastic Gradient Descent)
Stochastic Gradient Descent sums the error of an individual observation and performs an update to the model on each observation — This is the same as setting the number of Mini Batches to be equal to m, where m is the number of observations.
随机梯度下降可将单个观测值的误差相加,并对每个观测值执行模型更新-这与将“迷你批次”的数量设置为等于m相同 ,其中m是观测值的数量。
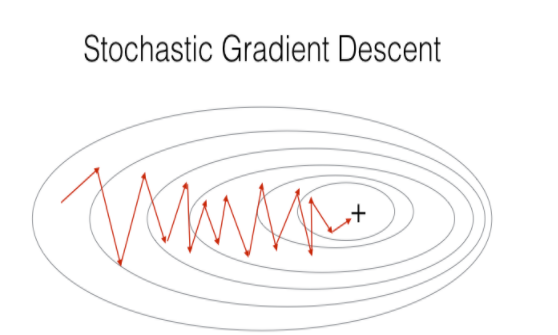
Pros
优点
- Only a single observation is being processed by the network so it is easier to fit into memory 网络仅处理一个观测值,因此更容易放入内存
- May (likely) to reach near the minimum (and begin to oscillate) faster than Batch Gradient Descent on a large dataset 在大型数据集上,可能(可能)达到接近最小值(并开始振荡)的速度比批次梯度下降快
- The frequent updates create plenty of oscillations which can be helpful for getting out of local minimums. 频繁的更新会产生大量的振荡,这有助于摆脱局部最小值。
Cons
缺点
- Can veer off in the wrong direction due to frequent updates 由于频繁更新,可能会朝错误的方向偏离
- Lose the benefits of vectorization since we process one observation per time 由于我们每次处理一个观测值,因此失去了矢量化的好处
- Frequent updates are computationally expensive due to using all resources for processing one training sample at a time 由于一次使用所有资源来一次处理一个训练样本,因此频繁更新的计算量很大
结语 (Wrap Up)
Optimization is a major part of Machine Learning and Deep Learning. A simple and very popular optimization procedure that is employed with many Machine Learning algorithms is called Gradient descent, and there are 3 ways we can adapt Gradient Descent to perform in a specific way that suits our needs.
优化是机器学习和深度学习的主要部分。 许多机器学习算法采用的一种简单且非常流行的优化程序称为梯度下降,我们可以通过3种方法使梯度下降以适合我们需求的特定方式执行。
Let’s continue the Conversation on LinkedIn!
让我们继续在LinkedIn上进行对话!
翻译自: https://towardsdatascience.com/gradient-descent-811efcc9f1d5
梯度下降法















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









