





词嵌入应用
A fundamental issue with LegalTech is that words — the basic currency of all legal documentation — are a form of unstructured data that cannot be intuitively understood by machines. Therefore, in order to process textual documents, words have to be represented by vectors of real numbers.
LegalTech的一个基本问题是,单词(所有法律文档的基本货币)是一种非结构化数据的形式,机器无法直观地理解。 因此,为了处理文本文档,单词必须用实数向量表示。
Traditionally, methods like bag-of-words (BoW) map word tokens/n-grams to term frequency vectors, which represent the number of times a word has appeared in the document. Using one-hot encoding, each word token/n-gram is represented by a vector element and marked 0, 1, 2 etc depending on whether or the number of times that a word is present in the document. This means that if a word is absent in the corpus vocabulary, the element will be marked 0, and if it is present once, the element will be marked 1 etc.
传统上,诸如单词袋(BoW)的方法将单词标记/ n-gram映射到术语频率向量,该频率向量表示单词在文档中出现的次数。 使用一键编码,每个单词标记/ n-gram由一个矢量元素表示,并根据单词在文档中出现的次数或次数标记为0、1、2等。 这意味着,如果语料库词汇中不存在某个单词,则该元素将被标记为0,如果该单词出现一次,则该元素将被标记为1等。
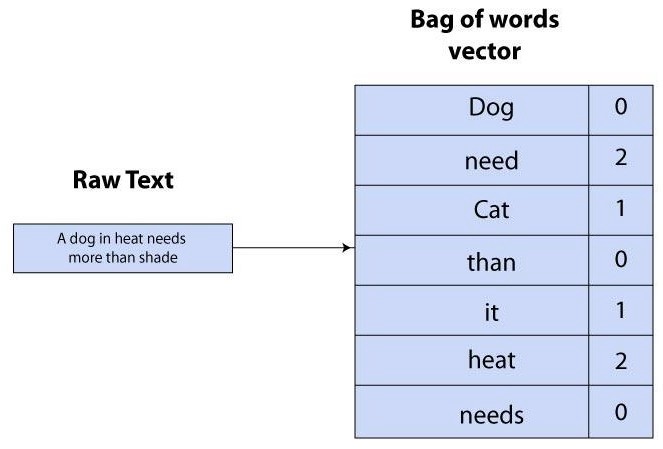
The problem was that this produced very sparse matrices (i.e. mostly comprising zeros) in extremely high dimensions. For instance, a corpus with 30,000 unique word tokens would require a matrix with 30,000 rows, which is extremely computationally taxing. Furthermore, this method fails to capture semantic meaning, context, and word relations, as it can only show how frequently a word exists in a document. This inability to represent semantic meaning persisted even as BoW was complemented by the TF-IDF measure, as while the latter was able to represent a measure of how important a word was to a corpus (i.e. an improvement from the plain BoW representations), it was still computed based on the frequency of a word token/n-gram appearing in the corpus.
问题在于,这会以非常高的尺寸生成非常稀疏的矩阵(即主要包含零)。 例如,具有30,000个唯一单词标记的语料库将需要具有30,000行的矩阵,这在计算上非常费力。 此外,该方法无法捕获语义含义,上下文和单词关系,因为它只能显示单词在文档中的出现频率。 即使在BoW补充了TF-IDF度量之后,这种无法表示语义的现象仍然存在,而TF-IDF度量可以用来度量单词对语料库的重要性(即对普通BoW表示的改进),仍然是根据语料中出现的单词记号/ n-gram的频率来计算的。
In contrast, modern word embeddings (word2vec, GloVE, fasttext etc) rely on neural networks to map the semantic properties of words into dense vector representations with significantly less dimensions.
相反,现代单词嵌入(word2vec,GloVE,fasttext等)依赖于神经网络将单词的语义特性映射为尺寸明显较小的密集矢量表示形式。
As a preliminary note, it should be said that word embeddings are premised off distributional semantics assumptions, i.e. words that are used and occur in the same contexts tend to have similar meanings. This means that the neural network learns the vector representations of the words through the contexts that the words are found in.
作为初步说明,应该说词嵌入是基于分布语义假设的前提,即,在相同上下文中使用和出现的词往往具有相似的含义。 这意味着神经网络通过发现单词的上下文来学习单词的向量表示。
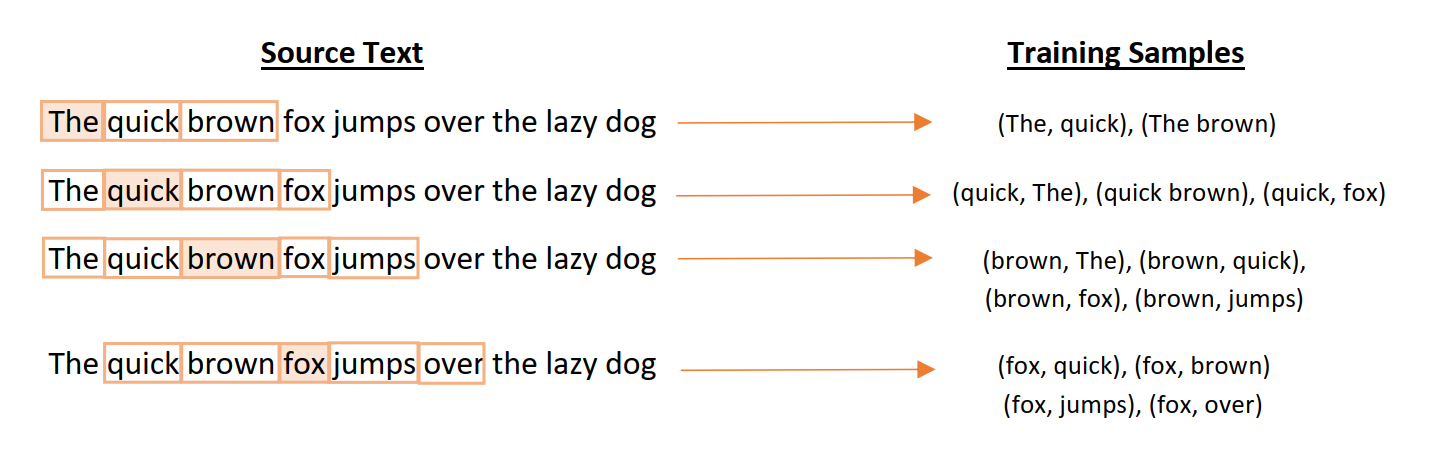
“Context” here is represented by a sliding context window of size n, where n words before the target word and n words after the target word will fall within the context window (e.g. n=2 in the example). The model will then train by using one-hot encoded context vectors to predict one-hot encoded target vectors as the context window moves down the sentence.
“上下文”在这里是由大小的滑动上下文窗口n,其中目标字之前n个字与目标字后n个字将落入上下文窗口内表示(例如n = 2的示例中)。 然后,当上下文窗口沿句子向下移动时,该模型将通过使用一热编码的上下文向量进行训练,以预测一热编码的目标向量。
In doing so, word embeddings can capture semantic associations and linguistic contexts not captured by BoW. This article will explore the impact of neural word embeddings in legal AI technologies.
这样,单词嵌入可以捕获BoW无法捕获的语义关联和语言环境。 本文将探讨神经词嵌入在法律AI技术中的影响。
捕获法律条款之间的关系 (Capturing Relationships between Legal Terms)
An important implication of word embeddings is that it captures the semantic relationship between words.
词嵌入的一个重要含义是它捕获了词之间的语义关系。
- Words that have similar meanings and contexts will occupy closer spatial positions in the vector space, as measured by cosine similarity. These word vectors can also be summed or multiplied without losing their inherent semantic characteristics and relationships. 具有相似含义和上下文的单词将在向量空间中占据更近的空间位置(按余弦相似度衡量)。 这些单词向量也可以求和或相乘而不会丢失其固有的语义特征和关系。
- The vector differences between the encoded words can also represent relationships between words. For instance, the word relations in “man is to king as woman is to queen” can be mathematically captured by vec(king) — vec(man) + vec(woman) = vec(queen). In the legal sphere, Ash (2016) has similarly shown that the relationship between corporate and income tax can be captured by vec(corporate income tax) — vec(corporation) + vec(person) = vec(personal income tax). 编码词之间的向量差也可以表示词之间的关系。 例如,可以从数学上用“ vec(king)— vec(man)+ vec(woman)= vec(queen)来捕捉“男人是国王,女人是女王”中的“关系”一词。 在法律领域,Ash(2016)同样表明,公司税与所得税之间的关系可以通过vec(企业所得税)-vec(公司)+ vec(人)= vec(个人所得税)来体现。
The ability to map out the relationship between legal terms and objects has exciting implications in its capacity to improve our understanding of legal reasoning. An interesting direction is the potential vectorisation of judicial opinions with doc2vec to identify/cluster judges with similar belief patterns (based on conservativeness of legal opinions, precedents-cited etc).
绘制法律术语与客体之间关系的能力对提高我们对法律推理的理解能力具有令人兴奋的意义。 一个有趣的方向是使用doc2vec进行司法舆论的潜在矢量化,以识别/聚集具有相似信念模式的法官(基于法律意见的保守性,被引用的先例等)。
Another function is that word embeddings can capture implicit racial and gender biases in judicial opinions, as measured by the Word Embedding Association Test (WEAT). Word embeddings are powerful because they can represent societal biases in mathematical or diagrammatical form. For instance, Bolukbasi (2016) showed that word embeddings trained on Google News articles exhibited significant gender bias, which can be geometrically captured by a direction in the word embedding (i.e. gender-neutral words are linearly separable from gender-neutral words).
另一个功能是,单词嵌入可以捕获司法观点中隐含的种族和性别偏见,这是通过单词嵌入关联测试(WEAT)测得的。 词嵌入功能强大,因为它们可以以数学或图表形式表示社会偏见。 例如,Bolukbasi(2016)表明,在Google新闻文章上训练的词嵌入表现出明显的性别偏见,可以通过词嵌入的方向以几何方式捕获(即,与性别无关的词与与性别无关的词可线性分离)。
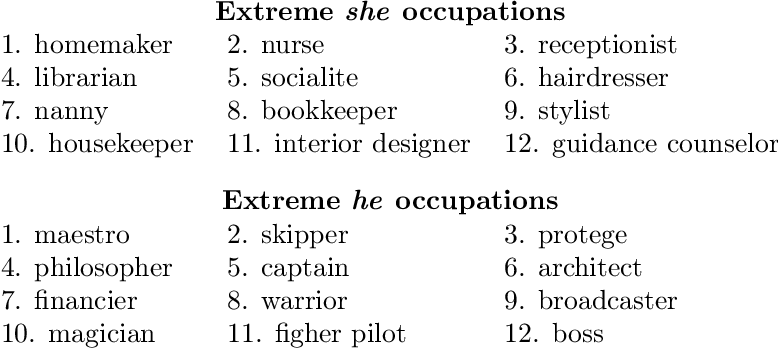
As such, word embeddings may reflect vector relationships like “man is to programmer as woman is to home-maker”, as the word “man” in the Google News corpora co-occurs more frequently alongside words like “programmer” or “engineer”, while the word “woman” will appear more frequently beside “homemaker” or “nurse”.
因此,词嵌入可能反映矢量关系,例如“男人是程序员,女人是家庭主妇”,因为Google新闻语料库中的“男人”一词与“程序员”或“工程师”等词同时出现,而“女人”一词会在“家庭主妇”或“护士”旁边更频繁地出现。
Applied to the legal domain, we can tabulate WEAT scores across judicial opinions, and preliminary research in this field has shown interesting trends, such as (i) male judges showing higher gender bias (i.e. higher WEAT scores) than female judges and (ii) white judges showing lower race bias than black judges. More remains to be explored in this domain.
应用于法律领域,我们可以将WEAT分数汇总到各个司法意见中,并且该领域的初步研究显示出有趣的趋势,例如(i)男法官表现出比女性法官更高的性别偏见(即WEAT得分更高),以及(ii)白人法官的种族偏见低于黑人法官。 在这个领域还有更多的探索。
加强法律研究 (Improving Legal Research)
Word embeddings also has fundamental implications for improving the technology behind legal research platforms (known in machine learning parlance as Legal Information Retrieval (LIR) systems).
单词嵌入对于改善法律研究平台(在机器学习中称为法律信息检索(LIR)系统)背后的技术也具有根本意义。
Currently, most LIR systems (e.g. Westlaw and LexisNexis) are still boolean-indexed systems primarily utilising keyword search functionality.
当前,大多数LIR系统(例如Westlaw和LexisNexis)仍然是主要使用关键字搜索功能的布尔索引系统。
This means that the system looks for literal matches or variants of the query keywords, usually by using string-based algorithms to measure the similarity between two text strings. However, these types of searches fail to understand the intent behind the solicitor’s query, meaning that search results are often under-inclusive (i.e. missing relevant information that does not contain the keyword, but perhaps variants of it) or over-inclusive (i.e. returning irrelevant information that comprises the keyword).
这意味着系统通常通过使用基于字符串的算法来测量两个文本字符串之间的相似性,来查找查询关键字的字面匹配或变体。 但是,这些类型的搜索无法理解律师查询的意图,这意味着搜索结果通常包含范围不足(即缺少不包含关键字但可能包含其变体的相关信息)或包含范围过大(即返回包含关键字的无关信息)。
Word embeddings, however, enhance the potential of commercially available semantic search LIR . As it allows practitioners to mathematically capture semantic similarity, word embeddings can help LIR systems find results that are not only exact matches of the query string, but also results that might be relevant or semantically close, but differ in certain words.
然而,词嵌入增强了商业上可用的语义搜索LIR的潜力。 由于它使从业人员可以在数学上捕获语义相似性,因此单词嵌入可以帮助LIR系统查找结果,这些结果不仅是查询字符串的精确匹配项,还可以是可能相关或在语义上接近但在某些单词上有所不同的结果。

For instance, Landthaler shows that effective results can be produced by first summing up the word vectors in each search phrase into a search phrase vector. The document is then sequentially parsed by a window of size n (where n = the number of words in the search phrase) and the cosine similarity of the search phrase vector and accumulated vectors is calculated. This will not only be able to return exact keyword-matching results, but also semantically-related search results, which provides more intuitive results.
例如,Landthaler表示,可以通过首先将每个搜索短语中的单词向量求和为搜索短语向量来产生有效结果。 然后,通过大小为n (其中n =搜索短语中的单词数)的窗口顺序解析文档,并计算搜索短语向量和累积向量的余弦相似度。 这样不仅可以返回准确的关键字匹配结果,还可以返回语义相关的搜索结果,从而提供更直观的结果。

This is especially important since research shows that participants using boolean-indexed search LIR systems which search for the exact matches of query terms on full-text legal documents can have recall rates as low as 20% (i.e. only 20% of relevant documents are retrieved by the LIR). However, on average, these participants estimate their retrieval rates to be up to 75%, which is significantly higher. This means that solicitors can often overlook relevant precedents or case law that may bolster their case, just because the LIR system prioritises string similarity over semantic similarity. Word embeddings hence have the potential to significantly address this shortfall.
这一点尤其重要,因为研究表明,使用布尔索引搜索LIR系统的参与者在全文法律文件中搜索查询词的精确匹配项时,召回率可低至20%(即,仅检索到20%的相关文件)由LIR)。 但是,平均而言,这些参与者估计他们的检索率高达75%,这要高得多。 这意味着律师通常会忽略可能会增强其案例的相关先例或判例法,仅因为LIR系统将字符串相似度放在语义相似度之上。 因此,单词嵌入有可能显着解决这一不足。
结论和未来方向 (Conclusion and Future Directions)
Overall, the field of neural word embeddings is fascinating. Not only is the ability to mathematically capture semantic context and word relations academically intriguing, word embeddings have also been a hugely important driver behind many LegalTech products in the market.
总体而言,神经词嵌入领域令人着迷。 数学上不仅能够以数学方式捕获语义上下文和单词关系的能力,而且单词嵌入也已成为市场上许多LegalTech产品背后的重要推动力。
However, word embeddings are not without limitations, and ML practitioners sometimes turn to newer pre-trained language modelling techniques (e.g. ULMFit, ELMo, OpenAI transformer, and BERT) to overcome some of the inherent problems with word embeddings (e.g. presuming monosemy). Nevertheless, word embeddings remain one of the most fascinating NLP topics today, and the move from sparse, frequency-based vector representations to denser semantically-representative vectors is a crucial step in advancing the NLP subdomain and the field of legal AI.
但是,单词嵌入并非没有局限性,并且ML从业人员有时会转向较新的经过预先训练的语言建模技术(例如ULMFit,ELMo,OpenAI转换器和BERT)来克服单词嵌入的一些固有问题(例如,假定为单义)。 尽管如此,词嵌入仍然是当今最引人入胜的NLP主题之一,从稀疏的基于频率的向量表示向密集的语义表示向量的转变是推进NLP子域和合法AI领域的关键一步。
翻译自: https://towardsdatascience.com/legal-applications-of-neural-word-embeddings-556b7515012f
词嵌入应用















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









