







使用词嵌入
example
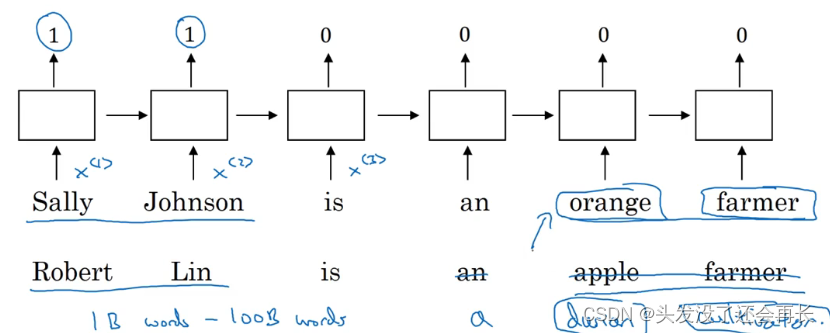
从一个例子开始,我们继续用命名实体识别的例子,如果你要找出人名,假如有一个句子:“Sally Johnson is an orange farmer.”(Sally Johnson 是一个种橙子的农民),你会发现 Sally Johnson 就是一个人名,所以这里的输出为 1。之所以能确定 Sally Johnson 是一个人名而不是一个公司名,是因为你知道种橙子的农民一定是一个人,前面我们已经讨论过用one-hot 来表示这些单词,𝑥<1> ,𝑥<2>等等。
如果你用特征化表示方法,嵌入的向量,也就是我们在上个视频中讨论的。那么用词嵌入作为输入训练好的模型,如果你看到一个新的输入:“Robert Lin is an apple farmer.” (Robert Lin 是一个种苹的农民),因为知道 orange 和 apple 很相近,那么你的算法很容易就知道 Robert Lin 也是一个人,也是一个人的名字。
要是测试集里这句话不是“Robert Lin is an apple farmer.”,而是不太常见的词怎么办?要是你看到:“Robert Lin is a durian cultivator.”(Robert Lin 是一个榴莲培育家)怎么办?如果对于一个命名实体识别任务,你只有一个很小的标记的训练集,你的训练集里甚至可能没有 durian(榴莲)或者 cultivator(培育家)这两个词。但是如果你有一个已经学好的词嵌入,它会告诉你 durian(榴莲)是水果,就像 orange(橙子)一样,并且 cultivator(培育家),做培育工作的人其实跟 farmer(农民)差不多,那么你就有可能从你的训练集里的“an orange farmer”(种橙子的农民)归纳出“a durian cultivator”(榴莲培育家)也是一个人。
为什么词嵌入能够做到这些?
词嵌入能够达到这种效果,其中一个原因就是学习词嵌入的算法会考察非常大的文本集,也许是从网上找到的,这样你可以考察很大的数据集可以是 1 亿个单词,甚至达到 100 亿也都是合理的,大量的无标签的文本的训练集。因此学习这种嵌入表达,把它们都聚集在一块,通过读取大量的互联网文本发现了 orange(橙子)和 durian(榴莲)都是水果。接下来你可以把这个词嵌入应用到你的命名实体识别任务当中,尽管你只有一个很小的训练集,也许训练集里有100,000个单词,甚至更小,这就使得你可以使用
迁移学习,把你从互联网上免费获得的大量的无标签文本中学习到的知识,能够分辨 orange(橙子)、apple(苹果)和 durian(榴莲)都是水果的知识,然后把这些知识迁移到一个任务中,比如你只有少量标记的训练数据集的命名实体识别任务中。
用词嵌入做迁移学习的步骤
第一步,先从大量的文本集中学习词嵌入。一个非常大的文本集,或者可以下载网上预训练好的词嵌入模型,网上你可以找到不少,词嵌入模型并且都有许可。
第二步,你可以用这些词嵌入模型把它迁移到你的新的只有少量标注训练集的任务中,比如说用这个 300 维的词嵌入来表示你的单词。这样做的一个好处就是你可以用更低维度的特征向量代替原来的 10000 维的 one-hot 向量,现在你可以用一个 300 维更加紧凑的向量。尽管 one-hot 向量很快计算,而学到的用于词嵌入的 300 维的向量会更加紧凑。
第三步,当你在你新的任务上训练模型时,在你的命名实体识别任务上,只有少量的标记数据集上,你可以自己选择要不要继续微调,用新的数据调整词嵌入。实际中,只有这个第二步中有很大的数据集你才会这样做,如果你标记的数据集不是很大,通常我不会在微调词嵌入上费力气。

当你的任务的训练集相对较小时,词嵌入的作用最明显,所以它广泛用于 NLP 领域。我只提到一些,不要太担心这些术语(下问列举的一些 NLP 任务),它已经用在命名实体识别,用在文本摘要,用在文本解析、指代消解,这些都是非常标准的 NLP 任务。
Relation to face encoding
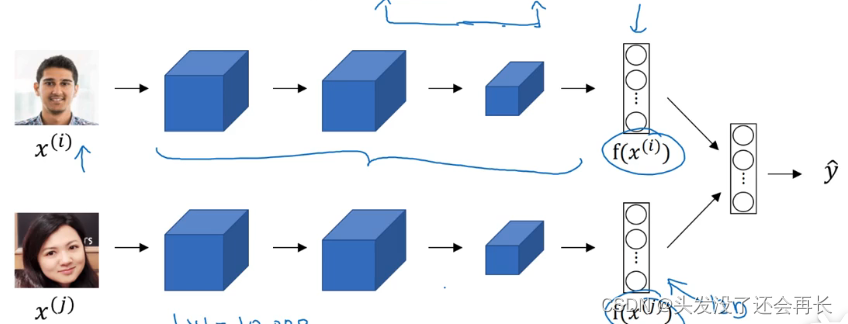
在人脸识别领域大家喜欢用编码这个词来指代这些向量𝑓(𝑥(𝑖)),𝑓(𝑥(𝑗)),人脸识别领域和这里的词嵌入有一个不同就是,在人脸识别中我们训练一个网络,任给一个人脸照片,甚至是没有见过的照片,神经网络都会计算出相应的一个编码结果。
这里的术语编码(encoding)和嵌入(embedding)可以互换,所以刚才讲的差别不是因为术语不一样,这个差别就是,人脸识别中的算法未来可能涉及到海量的人脸照片,而自然语言处理有一个固定的词汇表,而像一些没有出现过的单词我们就记为未知单词。
词嵌入特征
词嵌入还有一个迷人的特性就是它还能帮助实现类比推理,尽管类比推理可能不是自然语言处理应用中最重要的,不过它能帮助人们理解词嵌入做了什么,以及词嵌入能够做什么。
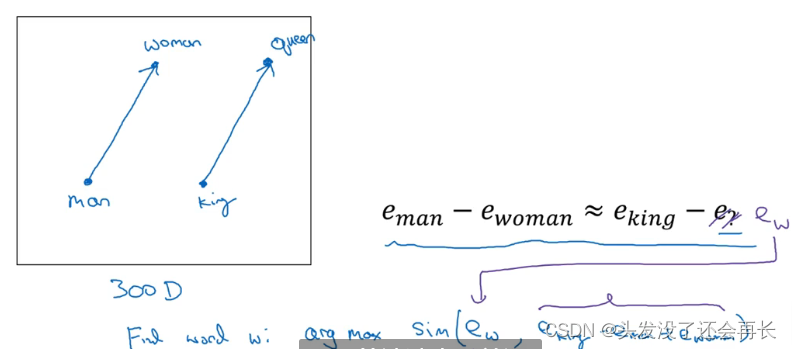
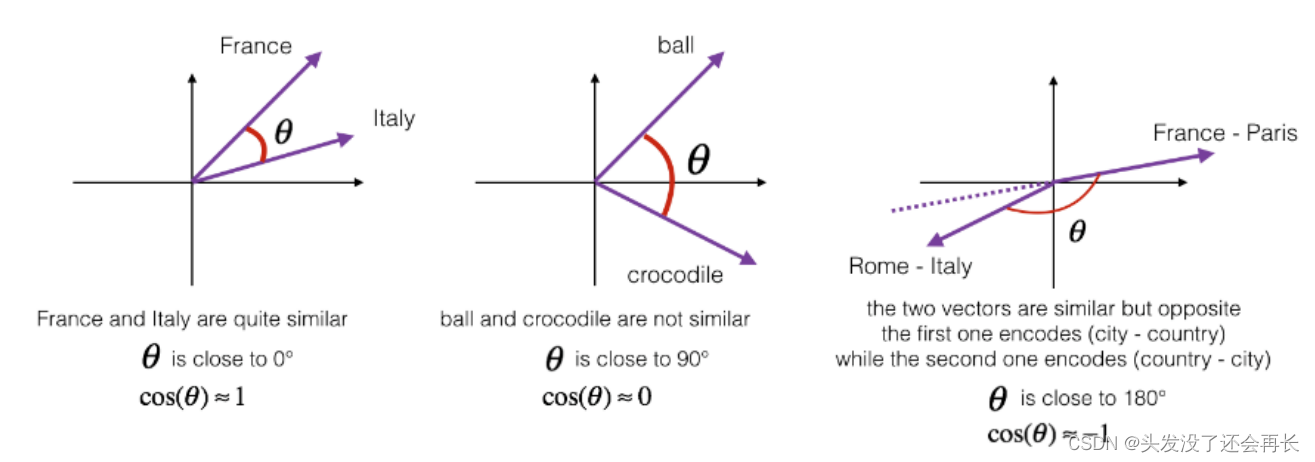
假如我提出一个问题,man 如果对应 woman,那么 king 应该对应什么?你们应该都能猜到 king 应该对应 queen。能否有一种算法来自动推导出这种关系,下面就是实现的方法。
我们用一个四维向量来表示 man,我们用𝑒5391来表示,不过在这节视频中我们先把它称为𝑒man,而旁边这个表示 woman 的嵌入向量,称它为𝑒woman,对 king 和 queen 也是用一样的表示方法。在该例中,假设你用的是四维的嵌入向量,而不是比较典型的 50 到 1000 维的向量。这些向量有一个有趣的特性,就是假如你有向量𝑒man和𝑒woman,将它们进行减法运算,即
这个结果表示,man 和 woman 主要的差异是 gender(性别)上的差异,而 king 和queen之间的主要差异,根据向量的表示,也是 gender(性别)上的差异,这就是为什么𝑒man-𝑒woman和𝑒king − 𝑒queen结果是相同的。所以得出这种类比推理的结论的方法就是,当算法被问及 man 对 woman 相当于 king 对什么时,算法所做的就是计算𝑒man − 𝑒woman,然后找出一个向量也就是找出一个词,使得𝑒man − 𝑒woman≈ 𝑒king − 𝑒?,也就是说,当这个新词是 queen时,式子的左边会近似地等于右边。


把这种思想写成算法
在图中,词嵌入向量在一个可能有 300 维的空间里,于是单词 man 代表的就是空间中的一个点,另一个单词 woman 代表空间另一个点,单词 king 也代表一个点,还有单词 queen 也在另一点上。
计算当 man 对于 woman,那么 king 对于什么,你能做的就是找到单词 w 来使得,𝑒man − 𝑒woman ≈ 𝑒king − 𝑒𝑤这个等式成立,你需要的就是找到单词 w 来最大化𝑒𝑤与 𝑒king − 𝑒man + 𝑒woman的相似度,即𝐹𝑖𝑛𝑑 𝑤𝑜𝑟𝑑 𝑤: 𝑎𝑟𝑔𝑚𝑎𝑥 𝑆𝑖𝑚(𝑒𝑤, 𝑒king − 𝑒man + 𝑒woman)所以我做的就是我把这个𝑒𝑤全部放到等式的一边,于是等式的另一边就会是𝑒king −𝑒man + 𝑒woman。我们有一些用于测算𝑒𝑤和𝑒king − 𝑒man +𝑒woman之间的相似度的函数,然后通过方程找到一个使得相似度最大的单词,如果结果理想的话会得到单词 queen。这种方法来做类比推理准确率大概只有 30%~75%。
相似度函数
列举一个最常用的相似度函数,这个最常用的相似度函数叫做余弦相似度。这是我们上个图中所得到的等式
在余弦相似度中,假如在向量𝑢和𝑣之间定义相似度:
现在我们先不看分母,分子其实就是𝑢和𝑣的内积。如果 u 和 v 非常相似,那么它们的内积将会很大,把整个式子叫做余弦相似度,其实就是因为该式是𝑢和𝑣的夹角的余弦值,所以这个角就是 Φ 角,这个公式实际就是计算两向量夹角 Φ 角的余弦。
距离用平方距离或者欧氏距离来表示:||𝑢 − 𝑣||^2
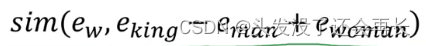
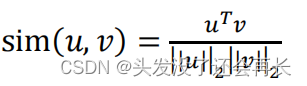
参考资料:余弦相似度 为了测量两个词的相似程度,我们需要一种方法来测量两个词的两个 嵌 入 向 量 之 间 的 相 似 程 度 。 给 定 两 个 向 量 𝑢 和 𝑣 , 余 弦 相 似 度 定 义 如 下 :
其中 𝑢. 𝑣 是两个向量的点积(或内积),||𝑢||2是向量𝑢的范数(或长度),并且 𝜃 是向量𝑢和𝑣之间的角度。这种相似性取决于角度在向量𝑢和𝑣之间。如果向量𝑢和𝑣非常相似,它 们 的 余 弦 相 似 性 将 接 近 1; 如 果 它 们 不 相 似 , 则 余 弦 相 似 性 将 取 较 小 的 值。
两个向量之间角度的余弦是衡量它们有多相似的指标,角度越小,两个向量越相似。
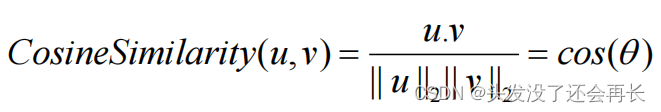















 8469
8469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









