





snowflake 使用
Often, we are faced with the scenarios (and myself recently), where the model which was deployed by the data scientist runs on a schedule and whether that’s once an hour, once a day, or once a week…you get the point. However, there are times when out-of-schedule results are required to make decisions for a meeting or analysis.
通常,我们面临着场景(以及我最近遇到的场景),其中数据科学家部署的模型按计划运行,而无论是每小时,每天还是每周一次……您都明白了。 但是,有时需要超出计划范围的结果才能为会议或分析做出决策。
With that being said, there are a few ways to get out-of-schedule predictions…
话虽这么说,但是有几种方法可以进行超出预期的预测…
超出计划外的预测 (Getting Out-of-schedule Predictions)
- Users can use a notebook instance, connect to the datastore, unload the data onto to S3, reference the data for prediction, and copy the result back onto the datastore. 用户可以使用笔记本实例,连接到数据存储,将数据卸载到S3上,引用数据进行预测,然后将结果复制回数据存储。
- The developer can build a model hosting API in which users can use the datastore to extract the data, and POST onto the hosting API for prediction. 开发人员可以构建一个模型托管API,在该模型中,用户可以使用数据存储区提取数据,然后发布到托管API上进行预测。
- Build a pipeline to allow users to unloaded data directly using SQL to invoke a batch prediction. 建立管道以允许用户直接使用SQL调用批处理预测来卸载数据。
Consequent, even though the Data Scientist & Co could implement a batch prediction application for others to use for out-of-schedule case, it would be intuitive to bring non-technical users closer to the model themselves and give them the power to run predictions from SQL.
因此,即使Data Scientist&Co可以实施批处理预测应用程序以供其他人在计划外的情况下使用,也可以很直观地使非技术用户更接近模型本身,并赋予他们进行预测的能力从SQL。
缩小Snowflake上运行预测与SQL之间的差距 (Bridging the gap between running prediction and SQL on Snowflake)
Inspired by Amazon Aurora Machine Learning, I spent a couple of days thinking about how to bridge this gap, and put together an architecture and build that will allow non-technical users to perform batch prediction from the comfort of SQL. This is all within Snowflake using Stored Procedure, Snowpipe, Streams and Tasks, and SageMaker’s batch prediction job (Batch Transform), to create a batch inference data pipeline.
受Amazon Aurora机器学习的启发,我花了几天的时间思考如何弥合这一差距,并构建了一个架构和构建,它将允许非技术用户从SQL的舒适性中执行批量预测。 这一切都在Snowflake中完成,使用存储过程,Snowpipe,流和任务以及SageMaker的批处理预测作业(批处理转换)来创建批处理推理数据管道。
雪花机器学习-建筑设计 (Snowflake Machine Learning - Architectural Design)
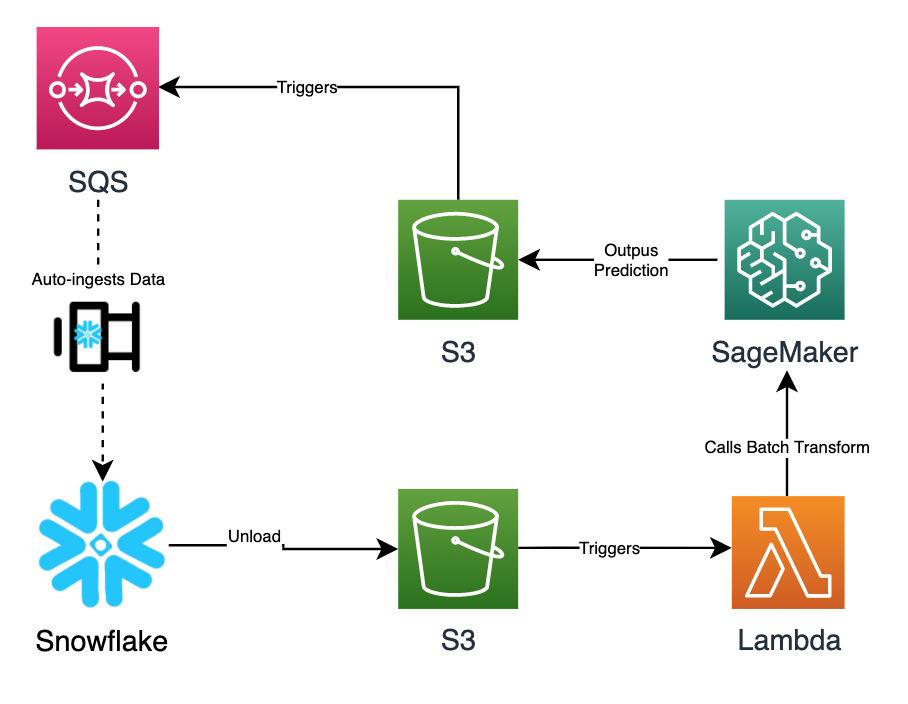
- The user unloads the data into S3 in the required format which will trigger a Lambda. 用户以所需格式将数据卸载到S3中,这将触发Lambda。
- SageMaker Batch Transform job is called to make batch predictions on the data using a trained model. 调用SageMaker Batch Transform作业以使用训练有素的模型对数据进行批量预测。
- The result from the prediction is written back onto the S3 bucket 预测结果将写回到S3存储桶
- SQS is set up on that S3 bucket to auto-ingest the predicted result onto Snowflake 在该S3存储桶上设置SQS,以将预测结果自动添加到Snowflake
- Once the data lands onto Snowflake, Streams and Tasks are called. 数据降落到Snowflake后,将调用Streams和Tasks。
卸载到S3上-使用存储过程 (Unloading onto S3 — Use of Stored Procedure)
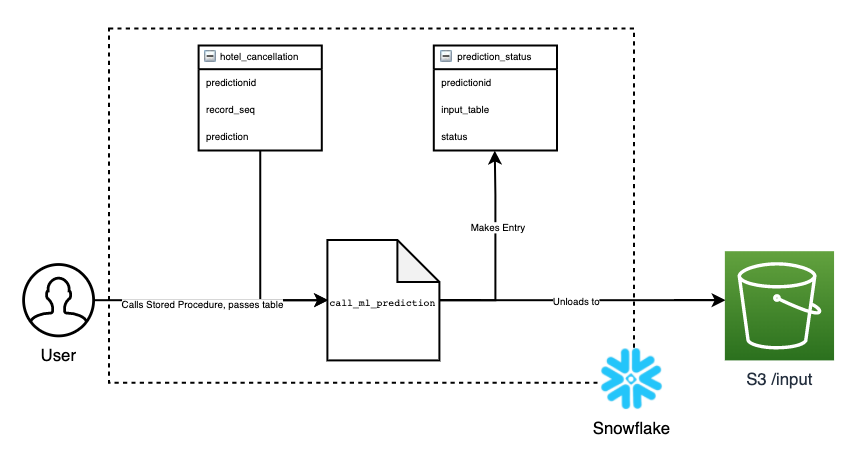
创建输入表 (Creating the input table)
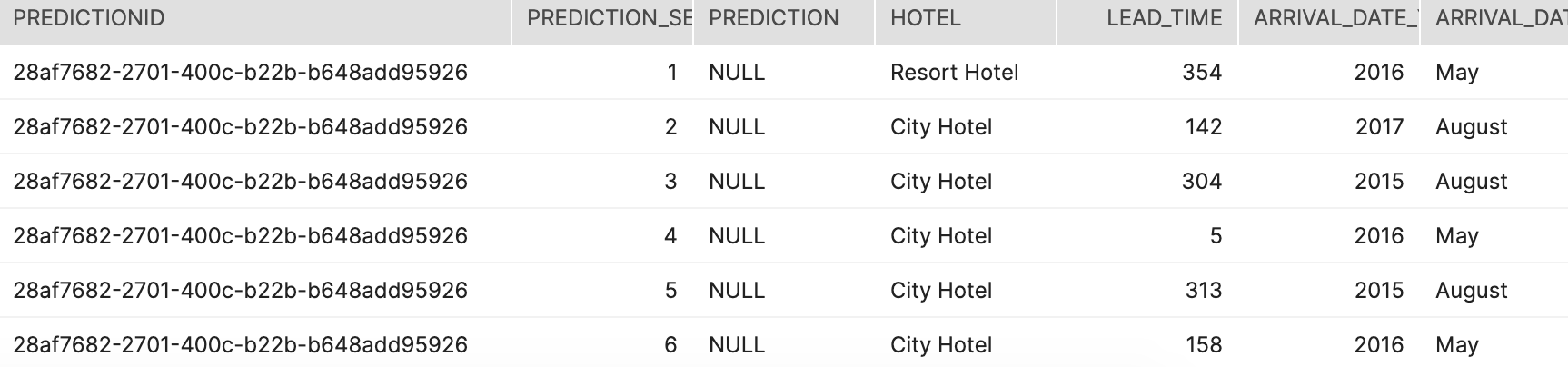
In order for the user to make a call to Batch Transform, the user will need to create an input table that contains the data for the model, and mandatory fields, the predictionid which is a uuid for the job, record_seq which is a unique identifier for reach input rows, a NULL prediction column which is the target of interest.
为了使用户能够调用Batch Transform,用户将需要创建一个输入表,其中包含模型的数据和必填字段, predictionid是作业的uuid, record_seq是唯一标识符。对于覆盖率输入行,则为目标目标NULL prediction列。
卸载到S3 (Unloading onto S3)
The call_ml_prediction Stored Procedure takes in a user-defined job name and input table name. Calling it will unload the file (using predictionid as the name) onto S3 bucket in the /input path and create an entry in the prediction_status table. From there, Batch Transform will be called to predict on the inputted data.
call_ml_prediction存储过程采用用户定义的作业名称和输入表名称。 调用它将把文件(使用predictionid作为名称)卸载到/input路径中的S3存储桶上,并在prediction_status表中创建一个条目。 从那里,将调用Batch Transform来预测输入的数据。
To ensure there aren’t multiple requests being submitted, only one job is able to run at a time. For simplicity, I also ensured only a single file is unloaded onto S3, but Batch Transform can handle multiple input files.
为了确保不会提交多个请求,一次只能运行一个作业。 为简单起见,我还确保仅将单个文件卸载到S3上,但是Batch Transform可以处理多个输入文件。

预测—使用SageMaker批量转换 (Prediction — Use of SageMaker Batch Transform)
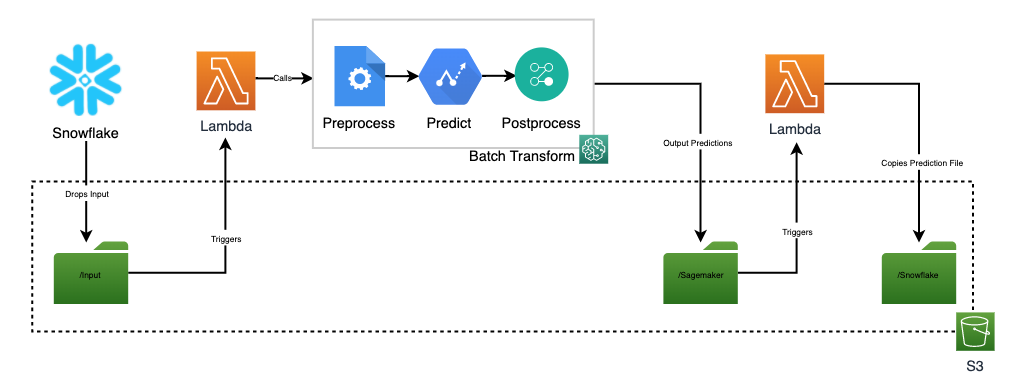
触发SageMaker批量转换 (Triggering SageMaker Batch Transform)
Once the data is unloaded onto the S3 bucket /input, a Lambda gets fired which makes a call SageMaker Batch Transform to read in the input data and output inferences to the /sagemaker path.
将数据卸载到S3存储桶/input ,将触发Lambda,该Lambda调用SageMaker Batch Transform读取输入数据,并将推断输出到/sagemaker路径。
If you’re familiar with Batch Transform, you can set the input_filter, join and output_filter to your likings for the output prediction file.
如果您熟悉Batch Transform,则可以根据自己的喜好设置output_filter,join和output_filter,以适应输出预测文件。
批量转换输出 (Batch Transform Output)
Once Batch Transform completes, it outputs the result as a .csv.out in the /sagemaker path. Another Lambda gets fired which will copy and rename the file as .csv to the /snowflake path where SQS is setup for Snowpipe auto-ingest.
一旦批量变换完成时,它输出该结果作为一个.csv.out在/sagemaker路径。 触发另一个Lambda,它将把文件复制为.csv并将其重命名为/snowflake路径,在该路径中为Snowpipe自动摄取设置了SQS。
结果-使用Snowpipe,流和任务 (The Result — Use of Snowpipe, Stream and Task)
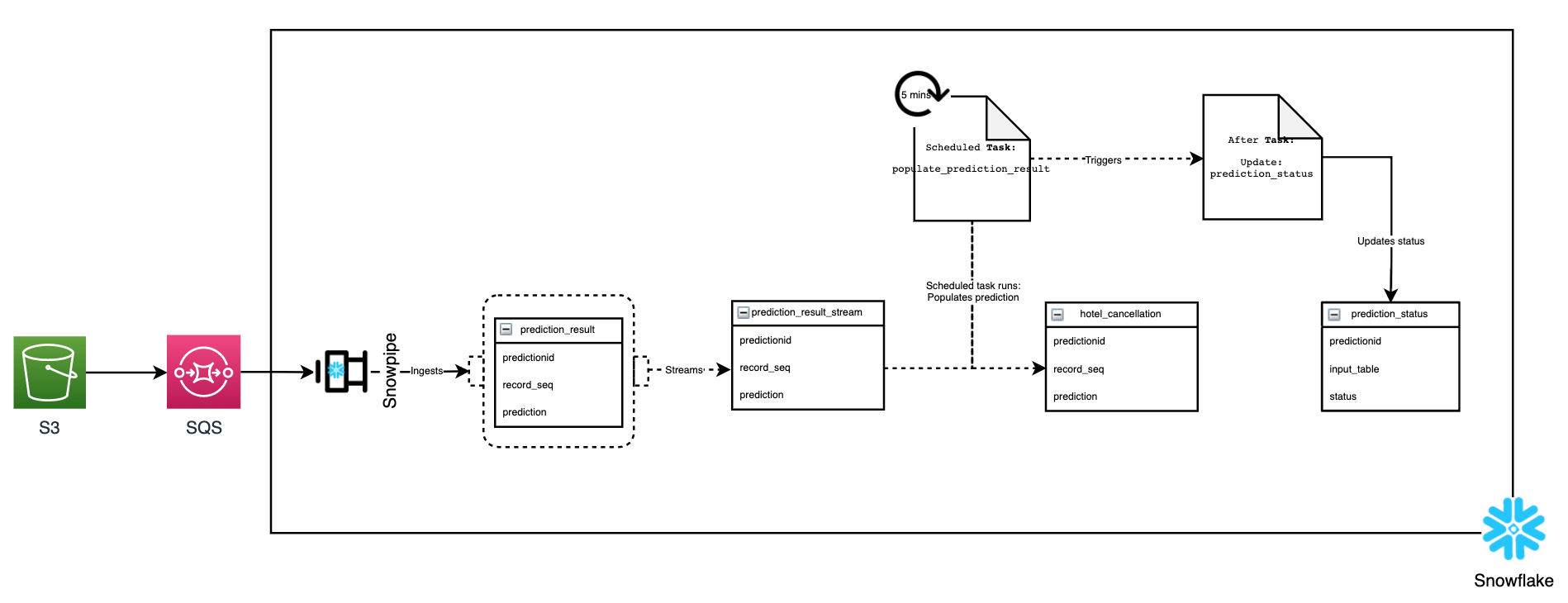
通过雪管摄取 (Ingestion through Snowpipe)
Once the data is dropped onto the /snowflake path, it is inserted into the prediction_result table via Snowpipe. For simplicity, since SageMaker Batch Transform maintains the order of the prediction, the row number was used as the identifier to join to the input table. You can do the postprocessing step within Batch Transform itself.
数据放到/snowflake路径后,便会通过Snowpipe将其插入prediction_result表。 为简单起见,由于SageMaker Batch Transform保持了预测的顺序,因此将行号用作连接到输入表的标识符。 您可以在Batch Transform本身中执行后处理步骤。
流数据并触发任务 (Streaming the data and triggering Tasks)
A stream is created is on the prediction_result table which will populate prediction_result_stream after Snowpipe delivers the data. This stream, specifically the system$stream_has_data('prediction_result_stream, will be used by the scheduled task populate_prediction_result to call the stored procedure populate_prediction_result to populate the prediction data on the hotel_cancellation table, only if there is a stream. The unique identifier, predictionid, is also set as a task session variable.
创建一个流是在prediction_result表,该表将填充prediction_result_stream Snowpipe开出数据之后。 调度的任务populate_prediction_result将使用此流,特别是system$stream_has_data('prediction_result_stream调用存储过程populate_prediction_result以在hotel_cancellation表上填充预测数据,唯一的hotel_cancellation是唯一流标识符predictionid ID为。还设置为任务会话变量。
完成工作 (Completing the job)
At the end of the job, and after populate_prediction_result completes, using the system task session variable, the next task update_prediction_status updates the prediction status from Submitted to Completed. This concludes the entire “Using SQL to run Batch Prediction” pipeline.
在作业结束时,并在populate_prediction_result完成之后,使用系统任务会话变量,下一个任务update_prediction_status将预测状态从Submitted更改为Completed 。 这样就构成了整个“使用SQL运行批处理预测”管道的整个过程。

做得更好 (Doing it better)
Snowflake provides a lot of power through Snowpipe, Streams, Stored Procedure and Task to create a data pipeline which can be used for different applications. When combined with SageMaker, Users will be able to send inputs directly from Snowflake and interact with the prediction results.
Snowflake通过Snowpipe,流,存储过程和任务提供了大量功能,以创建可用于不同应用程序的数据管道。 与SageMaker结合使用时,用户将能够直接从Snowflake发送输入并与预测结果进行交互。
Nonetheless, there are some wishlist items which will improve the whole experience and that is:
尽管如此,仍有一些愿望清单项可以改善整体体验,即:
- For Snowflake: The ability to manually trigger, or trigger a Task after Snowpipe ingestion finishes. This would guarantee the Task up completed Streams. 对于Snowflake:能够在Snowpipe提取完成后手动触发或触发任务。 这将保证任务完成流。
- For the pipeline: Being able to update the status of Snowflake from AWS side to let users know the progress of Batch Transform 对于管道:能够从AWS端更新Snowflake的状态,以使用户知道Batch Transform的进度
I hope you find this article useful and enjoyed the read.
希望您觉得这篇文章对您有帮助,并喜欢阅读。
关于我 (About Me)
I love writing medium articles, and sharing my ideas and learnings with everyone. My day-to-day job involves helping businesses build scalable cloud and data solutions, and trying new food recipes. Feel free to connect with me for a casual chat, just let me know you’re from Medium
我喜欢写中篇文章,并与所有人分享我的想法和经验。 我的日常工作涉及帮助企业构建可扩展的云和数据解决方案,并尝试新的食品食谱。 随时与我联系以进行休闲聊天,只需让我知道您来自中
— 杰诺·雅玛 ( Jeno Yamma)
snowflake 使用














 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









