





强化学习 求解迷宫问题
This is a short maze solver game I wrote from scratch in python (in under 260 lines) using numpy and opencv. Code link included at the end.
这是一个简短的迷宫求解器游戏,我使用numpy和opencv在python中(不到260行)从头开始编写。 末尾包含代码链接。
I wrote this to understand the fundamentals of Q-Learning and apply the theoretical concepts directly in code from scratch. Follow along if you wanna get your hands dirty with reinforcement learning!
我写这篇文章是为了了解Q-Learning的基础知识,并从头开始将理论概念直接应用到代码中。 如果您想通过强化学习使自己的双手变脏,请继续学习 !
Game Objective -
游戏目标-
Find the optimal movement policy which takes an agent from any starting (shown in black-gray shades on the left) to the closest destination (blue-ish) box while avoiding danger zone (red) and wall (green) boxes.
找到最佳移动策略,该策略可以使特工从任何起点(左侧以黑灰色阴影显示)到达最近的目的地 (蓝色)方框,同时避开危险区(红色)和墙壁(绿色)方框。
A “policy” can be thought of as the set of “smart-movement” rules which the agent learns to navigate its environment. In this case, they’re visualized as arrows (shown on left). This is done through Q-Learning.
可以将“策略”视为代理可以学习在其环境中导航的“智能移动”规则集。 在这种情况下,它们显示为箭头(如左图所示)。 这是通过Q-Learning完成的 。
Significance -
意义-
You might ask if making game-playing AIs like these are relevant at all in practical applications and that’s fair. Actually these are toy-problems designed in such a way that, their solutions are broadly applicable.
您可能会问,使这样的游戏性AI在实际应用中是否完全相关,这很公平。 实际上,这些是玩具问题,其设计方式使得它们的解决方案可广泛应用。
For example, the current example of maze solving can further be extended for autonomous navigation in an occupancy grid to get to the nearest EV charging station.
例如,迷宫求解的当前示例可以进一步扩展为在乘员网格中进行自主导航以到达最近的EV充电站。
Q学习算法和Q表方法- (The Q-Learning Algorithm and the Q-Table approach -)
Q-Learning is centered around the Bellman Equation and finding the q-value for each action at the current state. Finding an optimal policy involves recursively solving this equation multiple times.
Q学习以Bellman方程为中心,并找到当前状态下每个动作的q值 。 寻找最佳策略需要多次递归求解该方程。
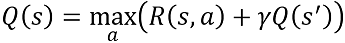
Only the main parts of the Bellman Equation relevant to this implementation will be explained in this article. For a more in-depth primer on the Bellman equation, check reference [1].
本文将只解释与该实现相关的Bellman方程的主要部分。 有关Bellman方程的更深入入门,请参阅参考文献[1]。
Q值是多少? (What is the Q-value?)
Imagine you are an unfortunate soul stuck in a simple 2D world like the following -
想象一下,您是一个不幸的灵魂,被困在一个简单的2D世界中,如下所示:
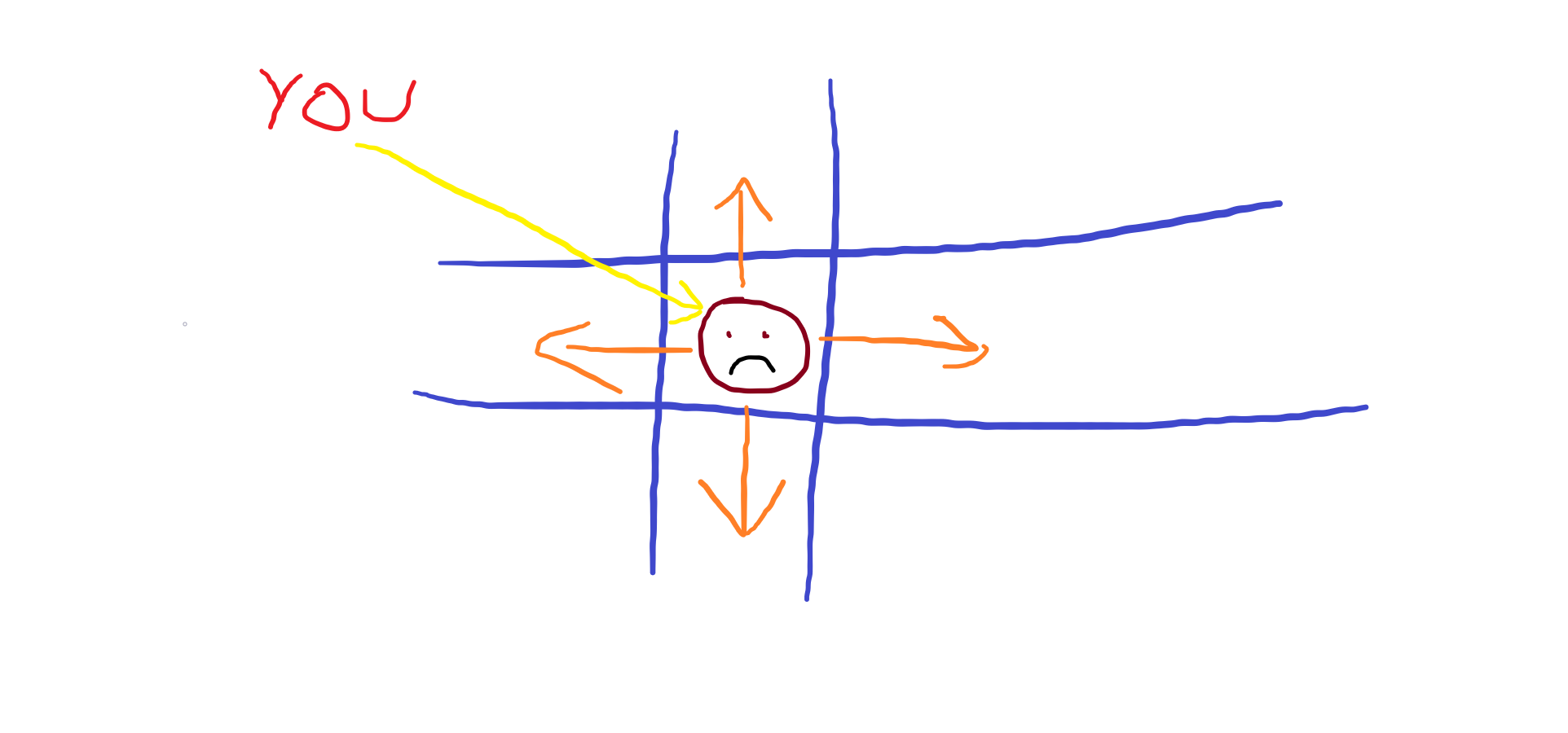
Well, you look sad. You should be. Who wants to be in a 2D world anyway?
好吧,你看起来很难过。 你应该。 谁想成为2D世界?
Well… lets put a smile on that face, shall we? 🎃
好吧……让微笑在那张脸上吧? 🎃
Given that the only movements you can make are the orange arrows shown in the image on the left (and a no-op operation), you gotta find your way to the nearest exit portal.
鉴于您只能做的动作就是左侧图像中显示的橙色箭头(以及无操作操作),因此您必须前往最近的出口门户。
Given these conditions, at any given stage, you’ll have to make a decision on one of these actions. To do that, your brain does an internal “ranking” of the actions taking many things into consideration. This might include things like -
考虑到这些条件,在任何给定阶段,您都必须对这些操作之一做出决定。 为此,您的大脑会在考虑到许多因素的情况下对这些行为进行内部“排名”。 其中可能包括-
Where is the nearest exit?
最近的出口在哪里?
Are there any danger zones?
有危险区域吗?
Where dem walls at boi?
Boi的dem墙在哪里?
Why is it getting hot in here? (We’ll get to this by discussing adding a small -ve reward for every time the agent does nothing)
为什么这里天气变热? (我们将通过讨论每次代理人什么都不做时增加一个小的-ve奖励来解决这个问题)
Now you being an advanced human, process these implicitly and assign a quality -value or a “Q-value” to each of the actions (up, down, left, right, no-op) you can take at that point.
现在您是高级人员,可以隐式处理这些内容,并为此时可以执行的每个动作(上,下,左,右,无操作)分配一个质量值或一个“ Q值” 。
But how can you make a computer do it?
但是如何使计算机做到这一点呢?
Simple, you somehow assign a numeric q-value to each action at each situation you might encounter. However, this is the naive approach; and as stated in the title, we shall stick to this here. For more advanced stuff, there are tons of other articles where you should be looking.
很简单,您可能会在每种情况下以某种方式为每个动作分配一个数字q值 。 但是,这是幼稚的方法。 如标题中所述,我们将在此处坚持这一点。 对于更高级的内容,您应该查看大量其他文章。
Pretty much like how we humans form perceptions of “good” and “bad” actions based on real-life experiences, the agent has to be trained in a similar way.
就像我们人类根据现实生活中的经验来形成对“好”和“坏”行为的看法一样,必须以类似的方式来训练代理。
Now, this brings us to the following question -
现在,这引出了以下问题-
什么是Q表? (What is the Q-table?)
Simply put, this is the memory of experiences per-say you’ll be updating and querying every time you have to make a decision and perform an action in the environment.
简而言之,这是您每次要在环境中做出决定并执行操作时都会更新和查询的经验的记忆。
An accurate visual representation of your relationship with the Q-table is shown on the left.
左侧显示了您与Q表的关系的准确视觉表示。
Now, to build the Q-table, you need to collect information about the world. It needs to know of danger zones, walls it could bump in to, and pretty much anything to help you not die soon (much like life itself).
现在,要建立Q表,您需要收集有关世界的信息。 它需要知道危险区域,可能撞到的墙以及几乎所有可以帮助您不会很快死亡的东西(就像生命本身一样)。
To do this, let’s assume you can die a thousand deaths. Yes, sacrifice is necessary for science.
为此,假设您可以杀死一千人。 是的,牺牲对于科学是必要的。
Armed with this, you will start at random locations and kind-of begin randomly roaming around until you start forming a perception of the world around you. This perception is shaped by what you encounter while roaming around.
有了这些,您将开始在随机的位置开始,并开始随机漫游,直到您开始形成对周围世界的感知。 这种感知取决于您在漫游时遇到的情况。

For example, you may hit a wall — that’s bad, cuz you’re bleeding. Now you’ll remember in that situation, whatever action you took which caused you to bleed, shouldn’t be repeated.
例如,您可能撞墙了,这很糟糕,因为您正在流血。 现在您会记得在这种情况下,无论您采取什么措施导致您流血,都不应重复。
Sometimes, you’ll even encounter danger zones raging with fire 🔥🧨 which will end your life as soon as you step on them. This is worse than bleeding, which will be quantified by assigning a more -ve reward value for such experiences.
有时,您甚至会遇到烈火肆虐的危险区域,一旦踩到这些危险区域,生命就会终止。 这比流血更糟,流血将通过为此类体验分配更高的奖励值来量化。
Now for the better things in life.
现在为了生活中更好的事情。
Similarly, you’ll also keep track of all the good things (when you receive a +ve reward) which happen during your time in the maze. Well, in this case, there’s only one good thing which can happen - E S C A P E.
同样,您还将跟踪迷宫中发生的所有美好事物(获得+ ve奖励时) 。 好吧,在这种情况下,只会发生一件好事- 亚太经社会E。
This just sounds like another way of dying, but hey let’s pretend its more fun cuz it sounds different than death.
这听起来像是另一种死亡的方式,但是,让我们假装它更有趣,因为它听起来比死亡还不同。
To do all of this, you’ll basically build a table storing the q-values of performing each and every action in every possible scenario in the environment (do remember that this is naive for a reason).
为此,您基本上将构建一个表,该表存储在环境中每种可能的场景中执行每个动作的q值(请记住,这是天真的原因)。
A higher q-value for a given action in a given state means that action will be more likely to be taken by you (the agent).
在给定状态下,给定操作的q值较高,意味着您(代理)更有可能采取该操作。
Shown below are two different states with example q-values for each action that can be performed by you (the agent) at those states.
下面显示的是两种不同的状态,您(代理)在这些状态下可以执行的每个操作的示例q值 。
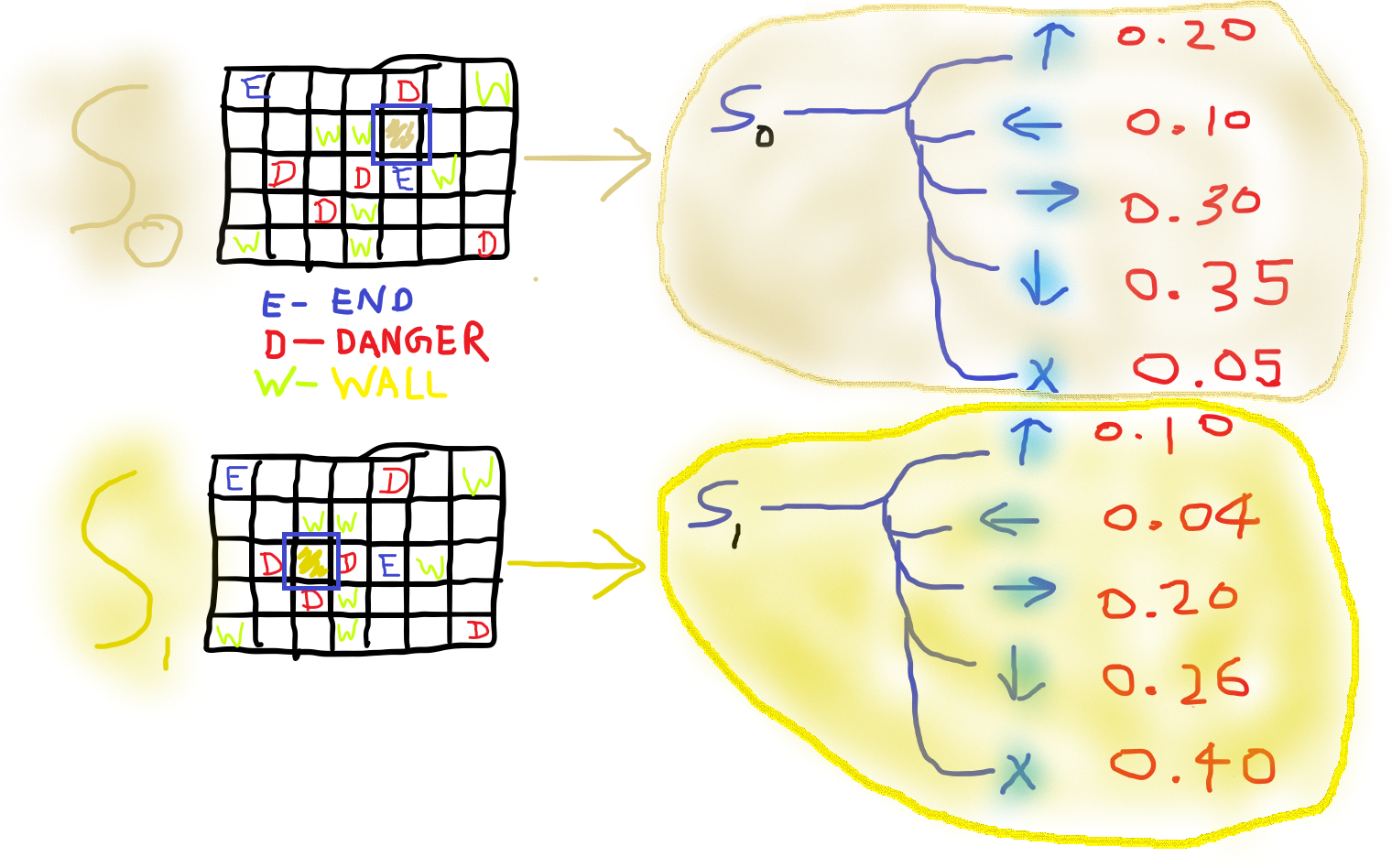
The q-values then act as a guide towards taking the next action to maximize overall reward (which means escape). At every step, the following actions will be performed sequentially in this naive scenario -
然后,q值将指导您采取下一步行动,以使总体奖励最大化(这意味着逃避)。 在此幼稚的场景中,每一步都会依次执行以下操作-
- Query Q-table for values pertaining to the different actions you can perform at your current state. 在Q表中查询与您当前状态下可以执行的不同操作有关的值。
Take action pertaining to the highest q-value.
采取与最高q值有关的动作。
Record the new state and reward received and use it to update the Q-table using the Bellman Equation. We’ll get here shortly.
记录新的状态和收到的奖励,并使用其通过Bellman公式更新Q表。 我们很快就会到这里。
- Go to step 1. 转到步骤1。
学习可视化 (Learning Visualization)
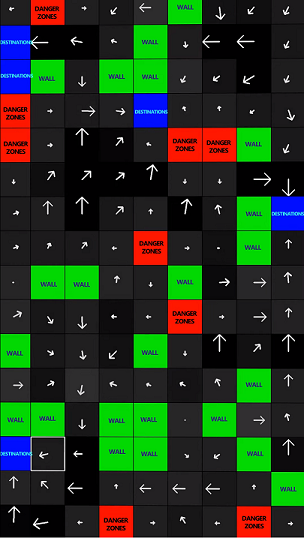
Given all state transition rules are defined (which in this case is quite simple given the basic nature of the maze world), after a sufficient number of repeating these iterations, the agent builds a “vector field map” per-say of the different actions that should be performed at each location of the maze so as to reach the nearest destination in the minimum time.
给定所有状态转换规则(在这种情况下,鉴于迷宫世界的基本性质,这非常简单),在重复了足够多次重复这些迭代之后,代理会针对每个不同的动作构建一个“ 向量场图 ”应该在迷宫的每个位置执行此操作,以便在最短的时间内到达最近的目的地。
Shown on the left is the final learned representation of the Q-table.
左侧显示的是Q表的最终学习表示。
The arrows are visualized by obtaining a vector sum of the different q-values at each location. For example, if we have the following q-values for up, left, right, down — qu, ql, qr, qd
通过在每个位置获得不同q值的矢量和,可以使箭头可视化。 例如,如果我们有以下q值分别代表上,左,右,下— qu,ql,qr,qd
Then the arrow, on a 2D plane (Horizontal is X-axis, Vertical is Y-axis) will have its x-component as qr-ql and y-component as qd-qu
然后,在2D平面上(水平轴为X轴,垂直轴为Y轴)的箭头的x分量为qr-ql , y分量为qd-qu
The length of the arrow is the norm of this vector obtained using the following formula -
箭头的长度是使用以下公式获得的该向量的范数-
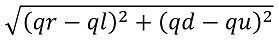
Therefore, if you start at any location in the maze, you can follow the arrows and reach the nearest destination by avoiding walls and danger zones.
因此,如果您从迷宫中的任何位置开始,您可以遵循箭头,避开墙壁和危险区域,到达最近的目的地。
在探索迷宫的同时更新Q表- (Updating the Q-Table while exploring the maze -)
This is one of the more challenging parts of the problem which greatly affects how soon you’ll be getting your sweet release (it’s not death, let’s remember that haha).
这是问题中更具挑战性的部分之一,极大地影响了您获得甜蜜释放的时间(这不是死亡,请记住那哈哈)。
基本上,这是一个问题- (Basically, here is the question —)
You take the highest q-value action at your given state following which, you end up in a new state (let’s hope for simplicity you don’t die for now).
您在给定状态下执行最高的q值操作,然后您进入新状态(希望简单起见,您现在不会死亡)。
Next, you’d like to record whether your action has brought you closer to the nearest destination in the Q-table. How could you do this?
接下来,您想记录您的操作是否使您更接近Q表中的最近目的地。 你怎么能这样
All you have here to work with are the following -
您在这里可以使用的所有功能如下-
Existing q-values at the new and old states defined for each action. They might have been randomly initialized or obtained from a previous iteration.
为每个动作定义的新旧状态下的现有q值。 它们可能已经被随机初始化或从先前的迭代中获得。
The reward you gained for the action you performed to get to the new state from the old state.
您为执行从旧状态到新状态所执行的操作而获得的奖励。
The action you performed to get to the new state from the old state.
您为从旧状态进入新状态而执行的操作。
How would you change the existing Q-table values you obtained for the old state to make a better decision if you come across it in the future?
...你流会改变你所获得的现有Q-表值老态做出更好的决定,如果你将来遇到呢?
This is the very basic question which is answered by the Bellman equation in this case -
在这种情况下,这是一个非常基本的问题 ,由Bellman方程式回答-
Following are the variable definitions -
以下是变量定义-
a is the action.
一个是动作。
s and s’ are the old and new states respectively.
s和s'分别是旧状态和新状态。
𝛾 is the discount factor, a constant between 0 and 1. You need this to prioritize current reward over expected future reward.
𝛾是折现因子 ,介于0和1之间的常数。 您需要使用此功能将当前奖励优先于预期的未来奖励。
Q(s) is the q-value of the action a you just took to reach the new state from the old state s.
Q(S) 是你只是把到达从旧的状态s新状态的动作的Q值。
Q(s’) is the maximum q-value at the new state s’.
Q(s')是新状态s'下的最大q值。
R(s, a) is the reward you immediately receive for performing a to transition from s to s’.
R(S,a)是你立即收到用于执行从s到S'过渡的报酬。
Tmax term is the secret sauce here. This causes the equation to iterate through every a until the maximum value of the expression inside the max term is obtained. It finally returns that value q and the corresponding action a.
T max术语是这里的秘密调味料。 这会使方程式每隔一个迭代一次,直到获得max项内的表达式的最大值 。 最后,它返回该值q和相应的动作a 。
Every action a performed from state s might lead to new states s’ for each iteration. Therefore each time, the maximum of the q-values defined at s’ is chosen to compute the expression inside max.
从状态s执行的每个动作a可能会导致每次迭代的新状态s' 。 因此,每次选择在s'定义的q值的最大值来计算max内的表达式。
Once the values q and a are obtained, the Q-table value defined for action a at state s is then overwritten by q.
一旦获得值q和a ,则在状态s下为动作a定义的Q表值将被q覆盖。
In our case, this representation is the value function (don’t worry if you don’t get this; well, I just pulled an Andrew Ng on you 😈).
在我们的例子中,该表示形式是值函数(不要担心,如果您不明白这一点,那么,我只是对您😈了Andrew Ng😈) 。
在迷宫中运行代理- (Running the agent in the maze -)
˚Finally,你在这里做到了,恭喜! 这是来自我的模因页面@ ml.exe的独家RL模因。 您应得的芽。 (Finally, you’ve made it here, congrats! Here is an exclusive RL meme for you from my meme page @ml.exe. You deserve it bud.)
After a sufficient number of iterations of the Bellman equation, you’ll converge to optimum q-values for each action at each state.
在进行了足够多的Bellman方程式迭代之后,您将收敛到每个状态下每个动作的最佳q值。
When you want to run the agent, simply start from any spawn point and blindly do the action with the highest q-value. You’ll reach the nearest destination.
当您要运行代理程序时,只需从任何生成点开始,然后盲目执行具有最高q值的操作。 您将到达最近的目的地。
However, there are a few caveats to getting this right -
但是,有一些注意事项可以解决此问题-
Reward policies should be carefully designed. This means correct reward values should be assigned for performing each action at each state. Since this case is so simple, a simple scheme like the following works well -
奖励政策应精心设计。 这意味着应该为在每个状态下执行每个动作分配正确的奖励值。 由于这种情况非常简单,因此,如下所示的简单方案非常有效-
discount_factor = 0.5
折扣系数= 0.5
default_reward = -0.5
default_reward = -0.5
wall_penalty = -0.6
wall_penalty = -0.6
win_reward = 5.0
win_reward = 5.0
lose_reward = -10.0
lost_reward = -10.0
default_reward is the reward obtained for doing nothing at all. Remember a basic question we asked ourselves in the beginning of this article “Why is it getting hot in here?”; well, here it is. Assigning a small negative reward encourages the agent to seek actions to end its misery rather than sitting around like an obese piece of lard.
default_reward是一无所获的奖励。 记住我们在本文开头问自己的一个基本问题:“ 为什么这里的温度越来越高? ”; 好吧,这是。 分配少量的负面奖励会鼓励行动者采取行动来结束其痛苦,而不是像肥胖的猪油一样围坐在一起。
wall_penalty is the reward received if you bump into a wall while doing the action from your present state. Whenever you bump into a wall, you remain at your original location while receiving this “reward” 🤣.
wall_penalty是当您从当前状态执行操作时撞到墙上时获得的奖励。 每当碰到墙时,您都会在收到此“奖励”🤣的同时留在原来的位置。
win_reward and lose_reward speak for themselves.
win_reward和Lose_reward为自己说话。
You lose a game if you end up on any of the danger zones. Upon dying, you respawn at a randomly chosen location on the grid.
如果最终进入任何危险区域,您都会输掉一场比赛。 死亡后,您会在网格上随机选择的位置重生。
In the codebase, you can play around with rewards to see how this affects solution convergence.
在代码库中,您可以尝试一些奖励,以了解它如何影响解决方案的融合。
结论 (Conclusion)
If you correctly understand the steps cited in this article, you’ll be able to fully understand the codebase I wrote from scratch to implement all of this. You can find it here -
如果您正确理解了本文引用的步骤,则将能够完全理解我为实现所有这些而从头开始编写的代码库。 你可以在这里找到它 -
The code writes out a video of the agent training and learning as shown in the YouTube video below. You can generate random worlds with varying complexities.
该代码编写了有关代理培训和学习的视频,如下面的YouTube视频所示。 您可以生成具有不同复杂度的随机世界。
If you found this helpful, feel free to follow me for more upcoming articles :)
如果您认为这有帮助,请随时关注我以获取更多即将发表的文章:)
I’m the editor of the following publication which publishes Tech articles related to the usage of AI & ML in digital mapping of the Earth. Feel free to follow to stay updated :)
我是以下出版物的编辑,该出版物发表有关在地球数字地图中使用AI和ML的技术文章。 随时关注以保持更新:)
强化学习 求解迷宫问题














 2555
2555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









