





gpt 语言模型
Natural language processing (NLP) is everywhere lately, with OpenAI’s GPT-3 generating as much hype as we’ve ever seen from a single model.
最近,自然语言处理(NLP)随处可见,OpenAI的GPT-3产生了我们从单一模型中看到的尽可能多的炒作。
As I’ve written about before, the flood of projects being built on GPT-3 is not down to just its computational power, but its accessibility. The fact that it was released as a simple API has made it so that anyone who can query an endpoint can use state of the art machine learning.
正如我之前所写 ,在GPT-3上构建的大量项目不仅取决于其计算能力,还取决于其可访问性。 它以简单的API发行的事实使之成为现实,因此任何可以查询端点的人都可以使用最新的机器学习技术。
Experiencing machine learning as “just another web service” has opened the eyes of many engineers, who previously experienced machine learning as an arcane, unapproachable field.
将机器学习体验为“仅仅是另一个Web服务”已经打开了许多工程师的视野,他们以前曾将机器学习视为一个不可思议的,不可接近的领域。
Suddenly, machine learning is something you can build things with.
突然之间,机器学习就是您可以构建的东西 。
And while GPT-3 is an incredible accomplishment, it’s far from the only impressive language model in the world. If you’re interested in machine learning engineering, my goal in this article is to introduce you to a number of open source language models you can use today to build software, using some of the most popular ML applications in the world as examples.
尽管GPT-3是令人难以置信的成就,但它与世界上唯一令人印象深刻的语言模型相距甚远。 如果您对机器学习工程感兴趣,本文的目的是向您介绍当今可以用于构建软件的许多开源语言模型,并以世界上一些最受欢迎的ML应用程序为例。
Before we start, I need to give a little context to our approach.
在开始之前,我需要对我们的方法进行一些介绍。
将模型作为API进行实时推理 (Deploying a model as an API for realtime inference)
What made GPT-3 so accessible to engineers was that to use it, you just queried an endpoint with some text, and it sent back a response. This on-demand, web service interface is called realtime inference.
使GPT-3易于工程师使用的原因是要使用它,您只是向端点查询了一些文本,然后它发回了响应。 这种按需的Web服务接口称为实时推理 。
In the case of GPT-3, the API was deployed for us by the team at OpenAI. However, deploying a model as an API on our own is fairly trivial, with the right tools.
对于GPT-3,OpenAI团队已为我们部署了API。 但是,使用合适的工具将模型本身作为API部署是相当琐碎的。
We’re going to use two main tools in these examples. First is Hugging Face’s Transformers, a library that provides a very easy-to-use interface for working with popular language models. Second is Cortex, an open source machine learning engineering platform I maintain, designed to be make it as easy as possible to put models into production.
在这些示例中,我们将使用两个主要工具。 首先是Hugging Face的Transformers,该库提供了一个非常易于使用的界面来处理流行的语言模型。 其次是Cortex ,我维护着一个开放源代码的机器学习工程平台,旨在使其尽可能轻松地将模型投入生产。
To deploy a model as an API for realtime inference, we need to do three things.
要将模型部署为用于实时推理的API,我们需要做三件事。
First, we need to write the API. With Cortex’s Predictor interface, our API is just a Python class with an __init__() function, which initializes our model, and a predict() function, which does the predicting. It looks something like this:
首先,我们需要编写API。 通过Cortex的Predictor接口,我们的API只是一个带有__init__()函数(用于初始化我们的模型)和predict()函数predict()用于进行predict()的Python类。 看起来像这样:
Cortex will then use this to create and deploy a web service. Under the hood, it’s doing a bunch of things with Docker, FastAPI, Kubernetes, and various AWS Services, but you don’t have to worry about the underlying infrastructure (unless you want to).
然后,Cortex将使用它来创建和部署Web服务。 在后台,它正在使用Docker,FastAPI,Kubernetes和各种AWS服务来做很多事情,但是您不必担心基础架构(除非您愿意)。
One thing Cortex needs to turn this Python API into a web service, however, is a configuration file, which we write in YAML:
但是,Cortex需要将该Python API转换为Web服务的一件事是一个配置文件,我们使用YAML编写该文件:
Nothing too crazy. We give our API a name, tell Cortex where to find the Python API, and allocate some compute resources, in this case, one CPU. You can configure in much more depth if you’d like, but this will suffice.
没什么太疯狂的。 我们给我们的API起个名字,告诉Cortex在哪里可以找到Python API,并分配一些计算资源,在这种情况下,是一个CPU。 如果愿意,您可以进行更深入的配置,但这足够了。
Then, we run $ cortex deploy using the Cortex CLI, and that’s it. Our model is now a functioning web service, a la GPT-3:
然后,我们使用Cortex CLI运行$ cortex deploy ,仅此而已。 我们的模型现在是运行正常的Web服务,例如GPT-3:

This is the general approach we will take to deployment throughout this list, though the emphasis will be on the models themselves, the tasks they’re suited to, and the projects you can build with them.
这是我们将在整个列表中进行部署的一般方法,尽管重点将放在模型本身,模型适合的任务以及可以使用它们构建的项目上。
1. Gmail智能撰写 (1. Gmail Smart Compose)
Smart Compose is responsible for those eerily-accurate email suggestions Gmail throws out while you type:
Smart Compose负责在您键入时Gmail抛出的那些错误准确的电子邮件建议:
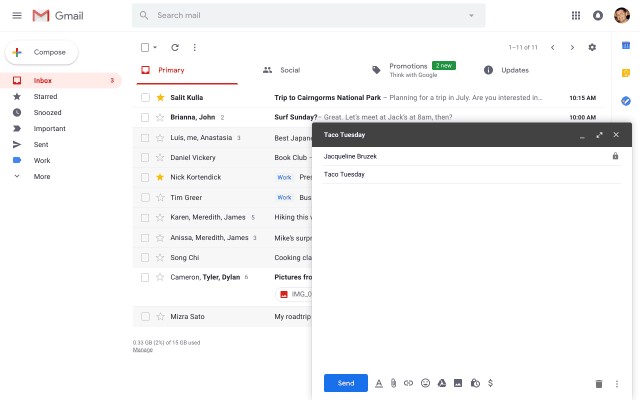
Even though Smart Compose is the result of huge budgets and engineering teams, you can build your own version in a couple of hours.
即使Smart Compose是庞大预算和工程团队的结果,您也可以在几个小时内构建自己的版本。
架构智能撰写 (Architecting Smart Compose)
Architecturally, Smart Compose is a straightforward example of realtime inference:
从结构上讲,Smart Compose是实时推断的简单示例:
- As you type, Gmail pings a web service with the text of your email chain. 键入时,Gmail会使用电子邮件链中的文本对网络服务执行ping操作。
- The web service feeds the text to a model, predicting the next sequence. Web服务将文本输入模型,以预测下一个序列。
- The web service delivers the predicted text back to the Gmail client. 该网络服务将预测的文本发送回Gmail客户端。
The biggest technical challenge to Smart Compose is actually latency. Predicting a probable sequence of text is a fairly routine task in ML, but delivering a prediction as fast as someone types is much harder.
Smart Compose的最大技术挑战实际上是延迟。 在ML中,预测可能的文本序列是一项相当常规的任务,但要提供与输入者一样快的预测则要困难得多。
To build our own Smart Compose, we’ll need to select a model, deploy it as an API, and build some kind of text editor frontend to query the API, but I’ll leave that last part to you.
要构建自己的Smart Compose,我们需要选择一个模型,将其部署为API,并构建某种文本编辑器前端来查询API,但我将把最后一部分留给您。
构建文本预测API (Building a text prediction API)
Let’s start by picking a model. We need one that is accurate enough to generate good suggestions on potentially not a lot of input. We also, however, need one that can serve predictions quickly.
让我们从选择一个模型开始。 我们需要一个足够准确的建议,以针对可能不多的输入产生好的建议。 但是,我们还需要一种可以快速提供预测的服务。
Now, latency isn’t all about the model—the resources you allocate to your API (GPU vs. CPU, for example) play a major role—but the model itself is still important.
现在,延迟不仅仅与模型有关—您分配给API的资源(例如,GPU与CPU)起着主要作用,但是模型本身仍然很重要。
There are a bunch of models capable of doing text generation, but for this task, we’re going to use DistilGPT-2, via Hugging Face’s Transformers library.
有许多模型可以执行文本生成,但是对于此任务,我们将通过Hugging Face的Transformers库使用DistilGPT-2。
GPT-2 is, shockingly, the predecessor to GPT-3. Until GPT-3’s release, it was widely regarded as the best model for text generation. The tradeoff with GPT-2, however, is performance. It’s really big—like 6 GB—and even with GPUs, can be slow in generating predictions. DistilGPT-2, as the name suggests, is a distilled version of GPT-2. It retains most of GPT-2 accuracy, while running roughly twice as fast (according to Hugging Face, it can run on a iPhone 7).
令人震惊的是,GPT-2是GPT-3的前身。 在GPT-3发布之前,它一直被广泛认为是文本生成的最佳模型。 但是,与GPT-2的权衡是性能。 它确实很大(例如6 GB),即使使用GPU,生成预测也会很慢。 顾名思义,DistilGPT-2是GPT-2的简化版本。 它保留了大多数GPT-2精度,同时运行速度大约是后者的两倍(根据“拥抱脸”,它可以在iPhone 7上运行)。
We can write a prediction API for DistilGPT-2 in barely 15 lines of Python:
我们可以用不到15行的Python编写针对DistilGPT-2的预测API:
Most of that should be intuitive.
其中大多数应该是直观的。
We initialize our predictor in __init__(), wherein we declare our device (in this case a CPU, but you can change that to GPU), load our model into memory, and load our tokenizer. A tokenizer encodes text into tokens the model can understand, and decodes predictions into text we can understand.
我们在__init__()初始化我们的预测变量,在其中声明我们的设备(在本例中为CPU,但您可以将其更改为GPU),将模型加载到内存中,并加载令牌生成器。 分词器将文本编码为模型可以理解的令牌,并将预测解码为我们可以理解的文本。
Then, our predict() function handles requests. It tokenizes our request, feeds it to the model, and returns a decoded prediction.
然后,我们的predict()函数处理请求。 它标记化我们的请求,将其提供给模型,并返回解码后的预测。
Once you deploy that API with Cortex, all you need to do is connect it to your frontend. Under the hood, that’s all Smart Compose is. A single text generator, deployed as an API. The rest is just normal web development.
使用Cortex部署该API之后,您要做的就是将其连接到您的前端。 在后台,这就是Smart Compose的全部功能。 单个文本生成器,部署为API。 其余只是普通的Web开发。
2. Siri式问题解答 (2. Siri-esque question answering)
Virtual assistants, from Siri to Alexa to Google Assistant, are ubiquitous. And while many actually rely on machine learning for multiple tasks—speech-to-text, voice recognition, text-to-speech, and more—they all have one core task in common:
从Siri到Alexa再到Google Assistant的虚拟助手无处不在。 尽管许多人实际上依靠机器学习来完成多个任务(语音到文本,语音识别,文本到语音等),但它们都有一个共同的核心任务:
Question answering.
问题解答 。
For many, question answering is one of the more scifi seeming ML tasks, because it fits our pop culture image of a robot that knows more about the world than we do. As it turns out, however, setting up a question answering model is relatively straightforward.
对于许多人来说,问题解答是看起来更科学的ML任务之一,因为它符合我们的流行文化形象,即机器人比我们更了解世界。 然而,事实证明,建立问题回答模型相对简单。
设计提取性问题解答 (Architecting extractive question answering)
There are a few different approaches to this task, but we’re going to focus on extractive question answering, in which a model answers questions by extracting relevant summarizations from a body of reference material (documentation, wikipedia, etc.)
有几种不同的方法可以完成此任务,但我们将专注于提取式问题解答,其中模型通过从参考资料(文档,维基百科等)中提取相关摘要来回答问题。
Our API will be a model trained for extractive question answering, initialized with a body of reference material. We’ll then send it inputs via the API, and return predictions.
我们的API将是经过训练的提取性问题回答模型,并使用大量参考资料进行初始化。 然后,我们将通过API向其发送输入,并返回预测。
For this example, I’ll use the Wikipedia article on machine learning.
对于此示例,我将使用有关机器学习的Wikipedia文章。
构建提取性问答API: (Building an extractive question answering API:)
We aren’t going to be selecting a model at all this time. Instead, we’ll be using Hugging Face’s Pipeline, which allows us to download a pretrained model by specifying the task we want to accomplish, not the specific model.
我们不会一直在选择模型。 相反,我们将使用Hugging Face的管道,该管道允许我们通过指定要完成的任务而不是特定模型来下载预训练的模型。
That’s roughly 7 lines of Python to implement machine learning that, just a few years ago, you would have needed a team of researchers to develop.
大约几年前,大约需要7行Python来实现机器学习,因此您将需要一个研究人员团队来进行开发。
Testing out the API, when I ping it with “What is machine learning,” it responds:
当我用“什么是机器学习”对它进行测试时,对API进行测试,它将响应:
"the study of computer algorithms that improve automatically through experience."3. Google翻译 (3. Google Translate)
Translation is an incredibly complicated task, and the fact that Google Translate is so reliable is a testament to how powerful production machine learning has become over the last decade.
翻译是一项非常复杂的任务,而Google Translate如此可靠的事实证明了过去十年来强大的生产机器学习已变得如此强大。

And while Google Translate represents the pinnacle of machine translation in production, you can still build your own Google Translate without becoming an expert in the field.
尽管Google Translate代表了生产中机器翻译的巅峰之作,但您仍然可以在不成为该领域专家的情况下构建自己的Google Translate。
架构语言翻译 (Architecting language translation)
To understand why translation is such a difficult task to model computationally, think about what constitutes a correct translation.
要了解为什么翻译是一项难以计算的建模任务,请考虑什么构成正确的翻译。
A phrase can be translated into any number of equivalent sentences in another language, all of which could be “correct,” but some of which would sound better to a native speaker.
可以将一个短语翻译成另一种语言的任意数量的对等句子,所有这些句子都可能是“正确的”,但其中某些对母语为母语的人听起来会更好 。
These phrases wouldn’t sound better because they were more grammatically correct, they would sound better because they agreed with a wide variety of implicit rules, patterns, and trends in the language, all of which are fluid and change constantly.
这些短语听起来不会更好,因为它们在语法上更正确,它们听起来更好,因为它们与语言中的各种隐式规则,模式和趋势相一致,所有这些规则,模式和趋势都在不断变化并不断变化。
The best approach to modeling this complexity is called sequence-to-sequence learning. Writing a primer on sequence-to-sequence learning is beyond the scope of this article, but if you’re interested, I’ve written an article about how it used in both Google Translate and, oddly enough, drug development.
对这种复杂性进行建模的最佳方法称为序列到序列学习。 撰写有关序列到序列学习的入门知识超出了本文的范围,但是,如果您有兴趣,我已经写了一篇文章,介绍了它如何在Google Translate和药物开发中使用。
We need to find a sequence-to-sequence model pretrained for translations between two languages, and deploy it as an API.
我们需要找到一种针对两种语言之间的翻译进行预训练的序列到序列模型,并将其部署为API。
构建语言翻译API: (Building a language translation API:)
For this task, we can again use Hugging Face’s Transfomers pipeline to initialize a model fine-tuned for the exact language translation we need. I’ll be using an English-to-German model here.
对于此任务,我们可以再次使用Hugging Face的Transfomers管道来初始化针对我们所需的精确语言翻译进行微调的模型。 我将在这里使用英语到德语的模型。
The code is very similar to before, just import the model from the pipeline, and serve the request:
该代码与之前非常相似,只是从管道中导入模型并满足请求:
Now, you can ping that API with any English text, and it will respond with a German translation. For other languages, you can simply load a different model (there are many available through Hugging Face’s library).
现在,您可以使用任何英文文本ping该API,它将以德语翻译作为响应。 对于其他语言,您可以简单地加载不同的模型(Hugging Face的库中有很多可用的模型)。
机器学习工程不仅限于FAANG公司 (Machine learning engineering isn’t just for FAANG companies)
All of these products are developed by tech giants, because for years, they’ve been the only ones able to build them. This is no longer the case.
所有这些产品都是由技术巨头开发的,因为多年来,它们一直是唯一能够制造它们的产品。 这已不再是这种情况。
Every one of these examples has implemented state of the art machine learning in less than 20 lines of Python. Any engineer can build them.
这些示例中的每一个都在不到20行的Python中实现了最先进的机器学习。 任何工程师都可以构建它们。
A natural objection here would be that we only used pretrained models, and that to build a “real” product, you’d need to develop a new model from scratch. This is a common line of thinking, but doesn’t square with the reality of the field.
这里的自然反对意见是,我们仅使用预先训练的模型,并且要构建“真实的”产品,您需要从头开始开发新模型。 这是一条常见的思路,但与该领域的实际情况不符。
For example, AI Dungeon is a dungeon explorer built on machine learning. The game went viral last year, quickly racking up over 1,000,000 players, and it is still one of the most popular examples of ML text generation.
例如,AI Dungeon是基于机器学习构建的地牢浏览器。 去年,该游戏开始风靡一时,Swift吸引了超过1,000,000名玩家,它仍然是ML文本生成中最受欢迎的示例之一。
While the game has recently transitioned to using GPT-3, it was originally “just” a fine-tuned GPT-2 model. The creator scraped text from a choose-your-own-adventure site, used the gpt-2-simple library to fine-tune GPT-2 with the text, and then deployed it as an API with Cortex.
尽管游戏最近已过渡到使用GPT-3,但它最初只是“微调”的GPT-2模型。 创建者从一个自己选择的冒险网站上抓取了文本,使用gpt-2-simple库对GPT-2进行了微调,然后将其作为API与Cortex一起部署 。
You don’t need Google’s budget. You don’t need early access to the GPT-3 API. You don’t need a PhD in computer science. If you know how to write code, you can build state-of-the-art machine learning applications right now.
您不需要Google的预算。 您不需要及早访问GPT-3 API。 您不需要计算机科学博士学位。 如果您知道如何编写代码,则可以立即构建最新的机器学习应用程序。
gpt 语言模型















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









