






一般线性模型和混合线性模型
生命科学的数学统计和机器学习 (Mathematical Statistics and Machine Learning for Life Sciences)
This is the seventeenth article from my column Mathematical Statistics and Machine Learning for Life Sciences where I try to explain some mysterious analytical techniques used in Bioinformatics and Computational Biology in a simple way. Linear Mixed Model (LMM) also known as Linear Mixed Effects Model is one of key techniques in traditional Frequentist statistics. Here I will attempt to derive LMM solution from scratch from the Maximum Likelihood principal by optimizing mean and variance parameters of Fixed and Random Effects. However, before diving into derivations, I will start slowly in this post with an introduction of when and how to technically run LMM. I will cover examples of linear modeling from both Frequentist and Bayesian frameworks.
这是我的《生命科学的数学统计和机器学习》专栏中的第十七篇文章,我试图以一种简单的方式来解释生物信息学和计算生物学中使用的一些神秘的分析技术。 线性混合模型(LMM)也称为线性混合效应模型,是传统频率统计中的关键技术之一。 在这里,我将尝试通过优化固定效应和随机效应的均值和方差参数,从最大似然原理从头开始 获得LMM解决方案。 但是,在深入探讨衍生工具之前,我将在本文中慢慢介绍何时以及如何在技术上运行LMM 。 我将介绍来自频繁框架和贝叶斯框架的线性建模示例。
数据非独立性问题 (Problem of Non-Independence in Data)
Traditional Mathematical Statistics is based to a large extent on assumptions of the Maximum Likelihood principal and Normal distribution. In case of e.g. multiple linear regression these assumptions might be violated if there is non-independence in the data. Provided that data is expressed as a p by n matrix, where p is the number of variables and n is the number of observations, there can be two types of non-independence in the data:
传统的数学统计在很大程度上是基于最大似然原理和正态分布的假设 。 在例如多重线性回归的情况下,如果数据中存在非独立性 ,则可能会违反这些假设。 假设数据用ap x n矩阵表示,其中p是变量数,n是观察数,则数据中可以有两种类型的非独立性:
non-independent variables / features (multicollinearity)
非独立变量/特征( 多重共线性 )
- non-independent statistical observations (grouping of samples) 非独立统计观察(样本分组)
In both cases, the inverse data matrix needed for the solution of Linear Model is singular, because its determinant is close to zero due to correlated variables or observations. This problem is particularly manifested when working with a high-dimensional data (p >> n) where variables can become redundant and correlated, this is known as the Curse of Dimensionality.
在这两种情况下,线性模型求解所需的逆数据矩阵都是奇异的 ,因为由于相关变量或观测值,其行列式接近于零。 当使用高维数据(p >> n)时,此问题尤其明显,其中变量可能变得多余且相关,这称为维数诅咒 。
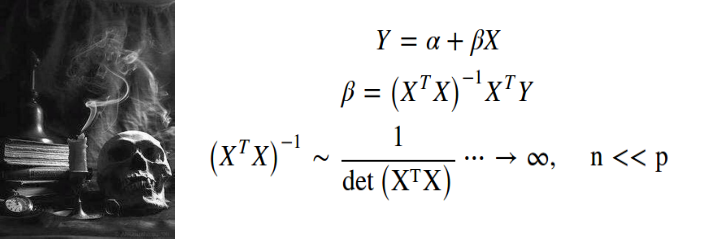
To overcome the problem of non-independent variables, one can for example select most informative variables with LASSO, Ridge or Elastic Net regression, while the non-independence among statistical observations can be taking into account via Random Effects modelling within the Linear Mixed Model.
为了克服非独立变量的问题,例如可以使用LASSO ,Ridge或Elastic Net回归选择最具信息量的变量,而统计观测值之间的非独立性可以通过线性混合模型中的 随机效应建模加以考虑。
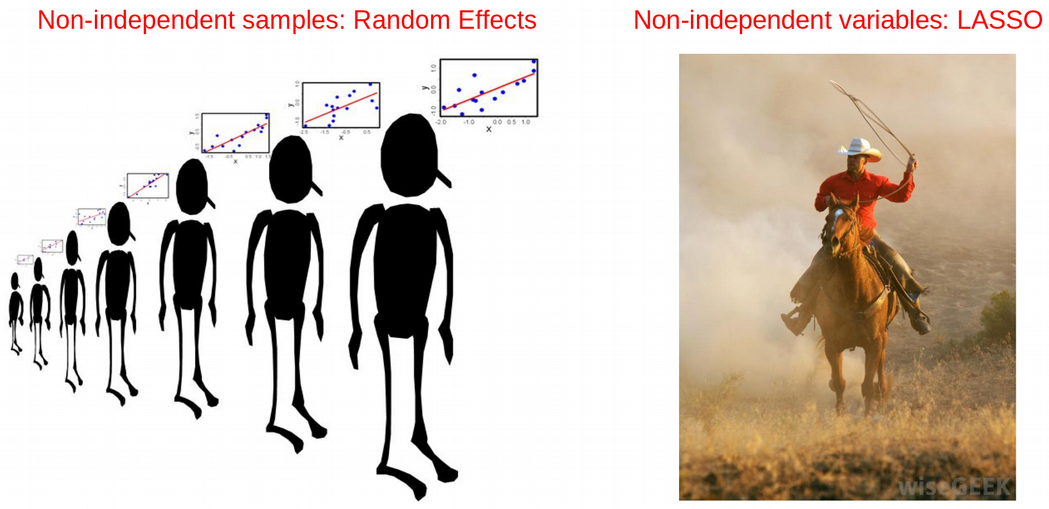
I covered a few variable selection methods including LASSO in my post Select Features for OMICs Integration. In the next section, we will see an example of longitudinal data where grouping of data points should be addressed through the Random Effects modelling.
在我的文章《 用于OMIC集成的选择功能》中,我介绍了一些变量选择方法,包括LASSO。 在下一部分中,我们将看到一个纵向数据的示例,其中应通过随机效应建模解决数据点分组的问题。
LMM and Random Effects modeling are widely used in various types of data analysis in Life Sciences. One example is the GCTA tool that contributed a lot to the research of long-standing problem of Missing Heritability. The idea of GCTA is to fit genetic variants with small effects all together as Random Effect withing LMM framework. Thanks to the GCTA model the problem of Missing Heritability seems to be solved at least for Human Height.
LMM和随机效应建模广泛用于生命科学中的各种类型的数据分析。 GCTA工具就是一个例子,它为长期遗留 遗传力问题的研究做出了很大贡献。 GCTA的想法是将具有较小影响的遗传变异体与具有LMM框架的随机效应结合在一起。 多亏了GCTA模型,遗传力缺失的问题似乎至少对于人类身高可以解决 。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7145
7145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









