





数据模型最佳实践
重点 (Top highlight)
If you’re into data science you’re probably familiar with this workflow: you start a project by firing up a jupyter notebook, then begin writing your python code, running complex analyses, or even training a model. As the notebook file grows in size with all the functions, the classes, the plots, and the logs, you find yourself with an enormous blob of monolithic code sitting up in one place in front of you. If you’re lucky, things can go well. Good for you then!
如果您对数据科学感兴趣,那么您可能熟悉此工作流程:通过启动jupyter笔记本启动项目,然后开始编写python代码,运行复杂的分析甚至训练模型。 随着笔记本文件的功能,类,图和日志的大小不断增长,您会发现自己面前堆满了巨大的一堆整体代码。 如果幸运的话,一切都会顺利进行。 那对你有好处!
However, jupyter notebooks hide some serious pitfalls that may turn your coding into a living hell. Let’s see how this happens and then discuss coding best practices to prevent it.
但是,jupyter笔记本电脑隐藏着一些严重的陷阱,可能会使您的编码变成活生生的地狱。 让我们看看这是如何发生的,然后讨论编码最佳实践以防止这种情况的发生。
Jupyter Notebook⛔️的问题 (The problems with Jupyter Notebook ⛔️)

Quite often, things may not go the way you intend if you want to take your jupyter prototyping to the next level. Here are some situations I myself encountered while using this tool and that should sound familiar to you:
通常,如果您想使Jupyter原型开发更上一层楼,事情可能会不符合您的预期。 这是我本人在使用此工具时遇到的一些情况,对您来说应该听起来很熟悉:
With all the objects (functions or classes) defined and instantiated in one place, maintainability becomes really hard: even if you want to make a small change to a function, you have to locate it somewhere in the notebook, fix it and rerun the code all over again. You don’t want that, believe me. Wouldn’t be simple to have your logic and processing functions separated in external scripts?
将所有对象(函数或类)定义并实例化后, 可维护性就变得非常困难 :即使您想对函数做些小改动,也必须将其放在笔记本中的某个位置,进行修复并重新运行代码。一遍又一遍。 你不要那个,相信我。 将逻辑和处理功能分离在外部脚本中会不会很简单?
Because of its interactivity and instant feedback, jupyter notebooks push data scientists to declare variables in the global namespace instead of using functions. This is considered bad practice in python development because it limits effective code reuse. It also harms reproducibility because your notebook turns into a large state machine holding all your variables. In this configuration, you’ll have to remember which result is cached and which is not and you’ll also have to expect other users to follow your cell execution order.
由于其交互性和即时反馈,Jupyter笔记本促使数据科学家在全局名称空间中声明变量,而不是使用函数。 在python开发中,这被认为是不好的做法 ,因为它限制了有效的代码重用。 由于笔记本电脑变成容纳所有变量的大型状态机,因此也会损害可重复性。 在此配置中,您必须记住要缓存哪个结果,而没有缓存,还必须期望其他用户遵循您的单元执行顺序。
The way notebooks are formatted behind the scenes (JSON objects) makes code versioning difficult. This is why I rarely see data scientists using GIT to commit different versions of a notebook or merging branches for specific features. Consequently, team collaboration becomes inefficient and clunky: team members start exchanging code snippets and notebooks via e-mail or Slack, rolling back to a previous version of the code is a nightmare, and the file organization starts to be messy. Here’s what I commonly see in projects after two or three weeks of using a jupyter notebook without proper versioning:
笔记本在后台格式化的方式(JSON对象)使代码版本控制变得困难。 这就是为什么我很少看到数据科学家使用GIT提交不同版本的笔记本或合并分支以实现特定功能的原因。 因此,团队协作变得效率低下和笨拙:团队成员开始通过电子邮件或Slack交换代码段和笔记本,回滚到以前的代码版本是一场噩梦,文件组织也开始变得混乱。 在不使用正确版本的情况下使用Jupyter笔记本两三周后,我通常会在项目中看到以下内容:
The way notebooks are formatted behind the scenes (JSON objects) makes code versioning difficult. This is why I rarely see data scientists using GIT to commit different versions of a notebook or merging branches for specific features. Consequently, team collaboration becomes inefficient and clunky: team members start exchanging code snippets and notebooks via e-mail or Slack, rolling back to a previous version of the code is a nightmare, and the file organization starts to be messy. Here’s what I commonly see in projects after two or three weeks of using a jupyter notebook without proper versioning: analysis.ipynbanalysis_COPY(1).ipynbanalysis_COPY(2).ipynbanalysis_FINAL.ipynbanalysis_FINAL_2.ipynb
笔记本在后台格式化的方式(JSON对象)使代码版本控制变得困难。 这就是为什么我很少看到数据科学家使用GIT提交不同版本的笔记本或合并分支以实现特定功能的原因。 因此,团队协作变得效率低下和笨拙:团队成员开始通过电子邮件或Slack交换代码段和笔记本,回滚到以前的代码版本是一场噩梦,文件组织也开始变得混乱。 这是在使用没有适当版本控制的Jupyter笔记本两三周后在项目中通常看到的内容: analysis.ipynbanalysis_COPY(1).ipynbanalysis_COPY(2).ipynbanalysis_FINAL.ipynbanalysis_FINAL_2.ipynb
Jupyter notebooks are good for exploration and quick prototyping. They’re certainly not designed for reusability or production-use. If you developed a data processing pipeline using a jupyter notebook, the best you can state is that your code is only working on your laptop or your VM in a linear synchronous fashion following the execution order of the cells. This doesn’t say anything about the way your code would behave in a more complex environment with, for instance, larger input datasets, other asynchronous parallel tasks, or less allocated resources.
Jupyter笔记本非常适合探索和快速制作原型。 他们肯定是 非专为可重用性或生产用途而设计 。 如果您使用jupyter笔记本电脑开发了数据处理管道,那么您可以说的最好是,代码仅按照单元执行顺序以线性同步方式在笔记本电脑或VM上运行。 这没有说明您的代码在更复杂的环境中的行为方式,例如,较大的输入数据集,其他异步并行任务或分配的资源较少。
Jupyter notebooks are good for exploration and quick prototyping. They’re certainly not designed for reusability or production-use. If you developed a data processing pipeline using a jupyter notebook, the best you can state is that your code is only working on your laptop or your VM in a linear synchronous fashion following the execution order of the cells. This doesn’t say anything about the way your code would behave in a more complex environment with, for instance, larger input datasets, other asynchronous parallel tasks, or less allocated resources.Notebooks are in fact hard to test since their behavior is sometimes unpredictable.
Jupyter笔记本非常适合探索和快速制作原型。 他们肯定是 非专为可重用性或生产用途而设计 。 如果您使用jupyter笔记本电脑开发了数据处理管道,那么您可以说的最好是,代码仅按照单元执行顺序以线性同步方式在笔记本电脑或VM上运行。 这没有说明您的代码在更复杂的环境中的行为方式,例如,较大的输入数据集,其他异步并行任务或分配的资源较少。 实际上,笔记本电脑很难测试,因为它们的行为有时是无法预测的。
As someone who spends most of his time on VSCode taking advantage of powerful extensions for code linting, style formatting, code structuring, autocompletion, and codebase search, I can’t help but feel a bit powerless when switching back to jupyter.
正如有人谁花了他的大部分时间VSCode代码以强大的扩展优势掉毛 ,风格格式化 ,代码结构,自动完成,并且代码库搜索,我不禁切换回jupyter时感到有点力不从心。
As someone who spends most of his time on VSCode taking advantage of powerful extensions for code linting, style formatting, code structuring, autocompletion, and codebase search, I can’t help but feel a bit powerless when switching back to jupyter. Compared to VSCode, jupyter notebook lacks extensions that enforce coding best practices.
正如有人谁花了他的大部分时间VSCode代码以强大的扩展优势掉毛 ,风格格式化 ,代码结构,自动完成,并且代码库搜索,我不禁切换回jupyter时感到有点力不从心。 与VSCode相比,jupyter笔记本电脑缺少一些扩展,可以实施最佳编码实践。
Ok folks, enough bashing for now. I honestly love jupyter and I think it’s great for what’s designed to do. You can definitely use it to bootstrap small projects or quickly prototype ideas.
好的,伙计们,现在已经足够扑朔迷离了。 我真的很喜欢jupyter,我认为这对设计工作非常有用。 您绝对可以使用它来引导小型项目或快速创建想法原型。
But in order to ship these ideas in an industrial fashion, you have to follow software engineering principles that happen to get lost when data scientists use notebooks. So let’s review some of them together and see why they’re important.
但是,为了以工业方式传播这些想法,您必须遵循软件工程师的原理,而数据科学家在使用笔记本时会迷路。 因此,让我们一起回顾其中的一些内容,看看它们为何如此重要。
使您的代码再次出色的技巧 (Tips to make your code great again 🚀)
*These tips have been compiled from different projects, meetups I attended, and discussions with software engineers and architects I’ve worked with by the past. If you have other suggestions and ideas to share, feel free to bring your contributions in the comment section and I’ll credit your answer in the post.
*这些技巧是从不同的项目,我参加的聚会以及与我过去合作过的软件工程师和架构师的讨论中汇编而来的。 如果您有其他建议和想法要分享,请随时在评论部分中发表您的意见,我会在帖子中感谢您的回答。
*The following sections assume that we’re writing python scripts. Not notebooks.
* 以下各节假定我们正在编写python脚本。 不是笔记本。
1 —清洁代码🧼️ (1 —Clean your code 🧼️)
One of the most important aspects of code quality is clarity. Clear and readable code is crucial for collaboration and maintainability.
代码质量最重要的方面之一就是清晰度。 清晰易读的代码对于协作和可维护性至关重要。
Here’s what may help you have a cleaner code:
这可以帮助您获得更简洁的代码:
Use meaningful variable names that are descriptive and imply type. For example, if you’re declaring a boolean variable about an attribute (age for example) to check whether a person is old, you can make it both descriptive and type-informative by using is_old.The same goes for the way you declare your data: make it explanatory.
使用描述性和隐含类型的有意义的变量名 。 例如,如果要声明一个有关属性(例如年龄)的布尔变量以检查某人是否老,则可以使用is_old使其具有描述性和类型信息性。 声明数据的方式也一样:使其具有解释性。
# not good ... import pandas as pd
df = pd.read_csv(path)# better!transactions = pd.read_csv(path)Avoid abbreviations that no one but you can understand and long variable names that no one can bear.
避免缩写 ,除非有人可以理解,否则请避免使用 冗长的变量名 ,没人可以接受。
Don’t hard code “magic numbers” directly in code. Define them in a variable so that everyone can understand what they refer to.
不要在代码中直接硬编码“魔术数字” 。 在变量中定义它们,以便每个人都可以理解它们所指的内容。
# not good ...
optimizer = SGD(0.0045, momentum=True)# better !
learning_rate = 0.0045
optimizer = SGD(learning_rate, momentum=True)Follow PEP8 conventions when naming your objects: for example, functions and methods names are in lowercase and words are separated by an underscore, class names follow the UpperCaseCamelCase convention, constants are fully capitalized, etc.
命名对象时,请遵循PEP8约定 :例如,函数和方法名称为小写字母,单词之间用下划线分隔,类名称遵循UpperCaseCamelCase约定,常量完全大写,等等。
Learn more about these conventions
了解有关这些约定的更多信息
here.
在这里 。
Use indentation and whitespaces to let your code breathe. There are standard conventions such as “using 4 space for each indent”, “separate sections should have additional blank lines”… Since I never remember those, I use a very nice VSCode extension called prettier that automatically reformat my code when pressing ctrl+s.
使用缩进和空格使代码充满活力。 有标准的公约,如“使用4个空间,每个缩进”,“独立的部分应该有更多的空行” ......因为我从来不记得那些,我用一个非常漂亮的VSCode扩展名为 漂亮 是按下Ctrl + S时自动重新格式化我的代码 。

2 —使代码模块化 (2 — Make your code modular 📁)
When you start building something that you feel can be reused in the same or other projects, you’ll have to organize your code into logical functions and modules. This helps for better organization and maintainability.
当您开始构建可以在相同或其他项目中重用的东西时,您必须将代码组织成逻辑功能和模块。 这有助于更好的组织和可维护性。
For example, you’re working on an NLP project and you may have different processing functions to handle text data (tokenizing, stripping URLs, lemmatizing, etc.). You can put all these units in a python module called text_processing.py and import them from it. Your main program will be way lighter!
例如,您正在开发一个NLP项目,并且您可能具有不同的处理功能来处理文本数据(标记化,剥离URL,词形化等)。 您可以将所有这些单元放入名为text_processing.py的python模块中,然后从中导入它们。 您的主程序将更轻巧!
These are some good tips I learned about writing modular code:
这些是我学习的有关编写模块化代码的一些好技巧:
DRY: Don’t Repeat Yourself. Generalize and consolidate your code whenever possible.
干:不要重复自己。 尽可能泛化和合并您的代码。
Functions should do one thing. If a function does multiple operations, it becomes more difficult to generalize.
函数应该做一件事 。 如果一个函数执行多项操作,则将很难概括。
Abstract your logic in functions but without over-engineering it: there’s the slight possibility that you’ll end up with too many modules. Use your judgment, and if you’re inexperienced, have a look at popular GitHub repositories such as scikit-learn and check out their coding style.
在函数中抽象逻辑,但又 不要过度设计:最终会有太多的模块。 使用您的判断力,如果您没有经验,请查看scikit-learn等流行的GitHub存储库,并查看其编码风格。
3 —重构代码📦 (3 — Refactor your code 📦)
Refactoring aims at reorganizing the internal structure of the code without altering its functionalities. It’s usually done on a working (but still not fully organized) version of the code. It helps de-duplicate functions, reorganize the file structure, and add more abstraction.
重构旨在重新组织代码的内部结构,而不改变其功能。 通常是在有效(但仍未完全组织)的代码版本上完成的。 它有助于消除重复功能,重组文件结构,并添加更多抽象。
To learn more about python refactoring, this article is a great resource.
要了解有关python重构的更多信息,本文是一个很好的参考资料 。
4-提高代码效率⏱ (4 — Make your code efficient ⏱)
Writing efficient code that executes fast and consumes less memory and storage is another important skill in software development.
编写高效的代码以快速执行并消耗更少的内存和存储空间是软件开发中的另一项重要技能。
Writing efficient code takes years of experience, but here are some quick tips that may help your find out if your code is running slow and how to boost it:
编写高效的代码需要多年的经验,但是以下一些快速提示可以帮助您确定代码运行缓慢以及如何提高代码运行速度:
- Before running anything, check the complexity of your algorithm to evaluate its execution time 在运行任何内容之前,请检查算法的复杂性以评估其执行时间
- Check the possible bottlenecks of your script by inspecting the running time of every operation 通过检查每个操作的运行时间来检查脚本的可能瓶颈
Avoid for-loops as much as possible and vectorize your operations, especially if you’re using libraries such as NumPy or pandas
- Leverage the CPU cores of your machine by using multiprocessing 通过使用多处理来利用计算机的CPU内核
5 —使用GIT或任何其他版本控制系统🔨 (5 — Use GIT or any other version control system 🔨)
In my personal experience, using GIT + Github helped me improve my coding skills and better organize my projects. Since I used it while collaborating with friends and/or colleagues, it made me stick to standards I didn’t obey to in the past.
以我的个人经验,使用GIT + Github帮助我提高了编码技能并更好地组织了项目。 由于我是在与朋友和/或同事合作时使用它的,所以它使我遵守了过去不遵守的标准。

There are lots of benefits to using a version control system, be it in data science or software development.
使用版本控制系统有很多好处,无论是在数据科学还是软件开发中。
- Keeping track of your changes 跟踪您的更改
- Rolling back to any previous version of the code 回滚到任何以前的代码版本
- Efficient collaboration between team members via merge and pull requests 团队成员之间通过合并和请求请求进行有效的协作
- Increase of code quality 提高代码质量
- Code review 代码审查
- Assigning tasks to team members and monitoring their progress over time 向团队成员分配任务并监控他们的进度
Platforms such as Github or Gitlab go even further and provide, among other things, Continuous Integration and Continuous Delivery hooks to automatically build and deploy your projects.
诸如Github或Gitlab之类的平台甚至走得更远,并提供“持续集成”和“持续交付”挂钩,以自动构建和部署项目。
If you’re new to Git I recommend having a look at this tutorial. Or you can have a look at this cheat sheet:
如果您不熟悉Git,建议您看一下本教程 。 或者,您可以查看以下备忘单:

If you want to specifically learn about how to version machine learning models, have a look at this article.
如果您想专门学习如何对机器学习模型进行版本控制,请参阅本文 。
6 —测试您的代码📐 (6 — Test your code 📐)
If you’re building a data pipeline that executes a series of operations, one way to make sure it performs according to what it’s designed to do, is to write tests that check an expected behavior.
如果您要构建执行一系列操作的数据管道,则要确保它按照设计目标执行,一种方法是编写检查预期行为的测试 。
Tests can be as simple as checking an output shape or an expected value returned by a function.
测试可以像检查函数的输出形状或期望值一样简单。
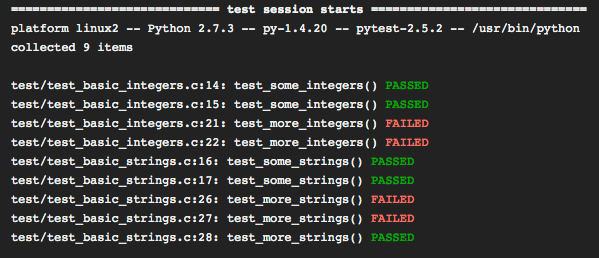
Writing tests for your functions and modules brings many benefits:
为您的功能和模块编写测试会带来很多好处:
- It improves the stability of the code and makes mistakes easier to spot 它提高了代码的稳定性,并使错误更容易发现
- It prevents unexpected outputs 它可以防止意外的输出
- It helps to detect edge cases 它有助于检测边缘情况
- It prevents from pushing broken code to production 它防止将破坏的代码推向生产环境
7 —使用日志记录🗞 (7 —Use logging 🗞)
Once the first version of your code is running, you definitely want to monitor it at every step to understand what happens, track the progress, or spot faulty behavior. Here’s where you can use logging.
一旦您的代码的第一个版本运行了,您肯定要在每个步骤进行监视,以了解发生了什么,跟踪进度或发现错误的行为。 在这里可以使用日志记录。
Here are some tips on efficiently using logging:
以下是有效使用日志记录的一些技巧:
- Use different levels (debug, info, warning) depending on the nature of the message you want to log 根据您要记录的消息的性质,使用不同的级别(调试,信息,警告)
- Provide useful information in the logs to help solve the related issues. 在日志中提供有用的信息,以帮助解决相关问题。
import logging
logging.basicConfig(filename='example.log',level=logging.DEBUG)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
https://github.com/A2Amir/Software-Engineering-Practices-in-Data-Science.
https://github.com/A2Amir/Software-Engineering-Practices-in-Data-Science。
https://towardsdatascience.com/5-reasons-why-jupyter-notebooks-suck-4dc201e27086
https://towardsdatascience.com/5-reasons-why-jupyter-notebooks-suck-4dc201e27086
https://medium.com/@_orcaman/jupyter-notebook-is-the-cancer-of-ml-engineering-70b98685ee71
https://medium.com/@_orcaman/jupyter-notebook-is-the-cancer-of-ml-engineering-70b98685ee71
https://datapastry.com/blog/why-i-dont-use-jupyter-notebooks-and-you-shouldnt-either/
https://datapastry.com/blog/why-i-dont-use-jupyter-notebooks-and-you-shouldnt-two/
https://visualgit.readthedocs.io/en/latest/pages/naming_convention.html
https://visualgit.readthedocs.io/zh_CN/latest/pages/naming_convention.html
https://towardsdatascience.com/unit-testing-for-data-scientists-dc5e0cd397fb
https://towardsdatascience.com/unit-testing-for-data-scientists-dc5e0cd397fb
结论 (Conclusion)
Long gone the days when data scientists found their way around by producing reports and jupyter notebooks that didn’t communicate in any way with the company systems and infrastructure. Nowadays, data scientists start producing testable and runnable code that seamlessly integrates with the IT systems. Following software engineering best practices becomes therefore a must. I hope this article gave you an overview of what these best practices are.
数据科学家通过制作报告和没有与公司系统和基础架构进行任何通信的jupyter笔记本找到自己的方式的日子已经过去了。 如今,数据科学家开始生产可测试且可运行的代码,这些代码可与IT系统无缝集成。 因此,必须遵循软件工程最佳实践。 我希望本文能为您概述这些最佳实践。
Thanks for reading!
谢谢阅读!
翻译自: https://medium.com/swlh/software-engineering-tips-and-best-practices-for-data-science-5d85dbcf87fd
数据模型最佳实践















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









