





查询数据 抓取 网站数据
I had a shameful secret. It is one that affects a surprising number of people in the data science community. And I was too lazy to face the problem and tackle it head-on.
我有一个可耻的秘密。 它影响了数据科学界中数量惊人的人们。 而且我懒得面对这个问题并直接解决它。
I didn’t know how to scrape data.
我不知道如何抓取数据。
For the majority of the time, it didn’t impact my life — I had access to datasets, or other people had developed custom scrapers / APIs for what I needed.
在大多数时间里,这并没有影响我的生活-我可以访问数据集,或者其他人已经为我需要的开发了自定义的scraper / API。
But every so often I would look at a website and wish that I could grab some of that sweet, original data to do some serious analysis.
但是,我经常会浏览一个网站,希望我可以从其中一些甜美的原始数据中进行认真的分析。
Well, no more.
好吧,没有更多了。
Relatively recently, I taught myself how to scrape websites with Python using a combination of BeautifulSoup, requests and regular expressions.
相对最近,我自学了如何结合使用BeautifulSoup , 请求和正则表达式来使用Python抓取网站。
I had a shameful secret… I didn’t know how to scrape data.
我有一个可耻的秘密……我不知道如何抓取数据。
The whole process was far easier than I thought it was going to be, and as a result I am able to make my own data sets.
整个过程比我想象的要容易得多,因此,我能够制作自己的数据集。
So here, I wanted to share my experience so you can do it yourself as well. As with my other articles, I include the entire code in my git repo here so you can follow along or adapt the code for your own purposes.
因此,在这里,我想分享我的经验,以便您也可以自己做。 与其他文章一样,我将完整的代码包含在我的git repo中,以便您可以按照自己的目的进行修改或修改代码。
在开始之前 (Before we get started)
配套 (Packages)
I assume you’re familiar with python. Even if you’re relatively new, this tutorial shouldn’t be too tricky, though.
我认为您熟悉python。 即使您是相对较新的人,本教程也不应该太棘手。
You’ll need BeautifulSoup, requests, and pandas. Install each (in your virtual environment) with a pip install [PACKAGE_NAME].
您将需要BeautifulSoup , requests和pandas 。 通过pip install [PACKAGE_NAME]安装每个组件(在您的虚拟环境中)。
You can find my code here: https://github.com/databyjp/beginner_scraping
您可以在这里找到我的代码: https : //github.com/databyjp/beginner_scraping
让我们做一个数据集 (Let’s make a dataset)
Once we learn how to scrape data, the skill can be applied to almost any site. But it is important to get the fundamentals right; so let’s start somewhere that is easy, while being reflective of the real world.
一旦我们了解了如何抓取数据,该技能便可以应用于几乎所有站点。 但是重要的是要正确地掌握基本原理。 因此,让我们从一个容易的地方开始,同时反思现实世界。
Many of you know that I’m a sports fan — so let’s get started by scraping our numerical data, which we will get from ScrapeThisSite.com.
你们中的许多人都知道我是体育迷-因此,让我们开始抓取我们将从ScrapeThisSite.com获得的数值数据。
As the creative name suggests, this site is designed to practice scraping. Given that the data is in tables, it is also easy to check that the data has been scraped correctly.
顾名思义,此网站旨在进行抓取。 鉴于数据在表中,因此也很容易检查数据是否已正确刮取。
获取原始数据 (Get the raw data)
Before we do anything, we need the raw data. This is where the requests library comes in. Getting the data is straightforward, just taking a line of code as follows:
在做任何事情之前,我们需要原始数据。 这就是requests库的所在。获取数据非常简单,只需执行以下代码即可:
import requests
page = requests.get("https://scrapethissite.com/pages/forms/")It’s that easy to get a copy of the web page. To check that the page has been loaded correctly, try:
轻松获得网页副本。 要检查页面是否已正确加载,请尝试:
assert page.status_code == 200If you don’t get an error, it should mean that the page has been downloaded correctly. How good is that? Now to the meat of the problem; getting data from our page.
如果没有错误,则表明该页面已正确下载。 那有多好? 现在要解决问题了; 从我们的页面获取数据。
进入你的元素 (Getting into your element)
To scrape a site, we need to identify which part of the website holds the information that we are after. Although this is easy visually, it’s annoyingly difficult to do in code.
要抓取网站,我们需要确定网站的哪个部分包含我们所关注的信息。 尽管从视觉上看这很容易,但是在代码中却很难完成。
Your best friend in this task is the “inspect element” button on your browser. There are different ways to actually address the elements to be scraped, but that’s secondary. First you need to identify the data being scraped.
您最好的朋友是浏览器中的“检查元素”按钮。 有多种方法可以实际解决要剪贴的元素,但这是次要的。 首先,您需要确定要抓取的数据。
For instance, let’s say that I would like to scrape this page.
例如,假设我要抓取此页面。

Before we go any further, take a look at the underlying code. Here’s a small sample of it.
在继续之前,请看一下基础代码。 这是其中的一小部分。

Given that it’s designed to be used by folks learning scraping, it’s not all that difficult to read. Still, it’s a pain correlating what you see here with what you see rendered.
鉴于它是为学习拼写的人们设计的,因此阅读起来并不难。 但是,将您在此处看到的内容与渲染的内容相关联仍然是一件痛苦的事情。
What you should be doing is to highlight the relevant element on the page, right-click and choose “inspect element”. This will bring up a layout similar to the below, although it will vary by browser.
您应该做的是突出显示页面上的相关元素,右键单击并选择“检查元素”。 这将显示类似于以下内容的布局,尽管它会因浏览器而异。

The code that will be brought up is the DOM (Document Object Model). Without getting too technical, this allows the code to be matched with the rendered end result.
将要显示的代码是DOM(文档对象模型) 。 无需太过技术,这可以使代码与渲染的最终结果匹配。
I highly recommend scrolling through the various elements here, selecting them, and generally observing the DOM’s structure.
我强烈建议在此处滚动浏览各种元素,选择它们,并通常观察DOM的结构。
More concretely, let’s see what we would do to scrape the table showing the conference standings as below.
更具体地说,让我们来看看如何抓取显示会议状态的表格,如下所示。
宝贝步骤—抓取一条数据 (Baby steps — Scrape one piece of data)

An inspection of the elements reveal that we would like to obtain the contents of this table. Although it doesn’t have a unique id, it does reside in a section with id value hockey.
对元素的检查表明,我们希望获得此表的内容。 尽管它没有唯一的ID,但它确实驻留在id值为hockey的section 。
BeautifulSoup finds all of this easy, where parameter id can be passed on (id values in html are unique), or just a default parameter of tags.
BeautifulSoup很容易找到所有这些,可以传递参数id (html中的id值是唯一的),也可以只是标签的默认参数。
We can find all of this by:
我们可以通过以下方式找到所有这些:
div = soup.find(id="hockey") # Find the right div
table = div.find("table")You can verify that there is only one table in that div, by running:
您可以通过运行以下命令来验证该div中只有一个表:
assert len(soup.find_all("table")) == 1We notice that the table includes header rows <th> as well as data rows <tr>. Let’s scrape just the rows — and we also notice that each data row here has the class attribute with value team, so let’s also filter by that attribute. This can be done by passing these through as a dictionary, allowing us to filter by whatever custom attributes people define!
我们注意到该表包括标题行<th>和数据行<tr> 。 让我们只刮擦行-并且我们还注意到这里的每个数据行都具有带有value team的class属性,因此我们也按该属性进行过滤。 这可以通过将它们作为字典传递来完成,从而允许我们根据人们定义的任何自定义属性进行过滤!
team_elm = table.find("tr", attrs={"class": "team"})The element collected looks like this:
收集的元素如下所示:
What if we want to extract the team name from all this mess?
如果我们想从所有这些混乱中提取球队名称怎么办?
I see that the name column is marked by its class attribute, so I can find the column by its tag (td) and the attribute.
我看到name列由其class属性标记,因此我可以通过其标签( td )和该属性找到该列。
team_name = team_elm.find("td", attrs={"class": "name"}).textBut since the results include a ton of whitespace:
但是由于结果包含大量空白,因此:
>>> team_name
'\n Boston Bruins\n 'This is a job for regular expressions!
这是正则表达式的工作!
team_name = re.sub(r"^\s+|\s+$", "", team_name)If you’re not sure what is going on there — the regex is substituting either the start of string ^ whitespace(s) \s+ or | end of string $ whitespace(s), with nothing. You can throw in a re.M flag if it might go over multiple lines also.
如果您不确定发生了什么, 则正则表达式将替换字符串^空格的开头\s+或| 字符串$空格的末尾,不包含任何内容。 如果re.M标志也可能跨越多行,则可以抛出该标志。
Fabulous. Now, how would we extend this to collect the entire table?
极好。 现在,我们将如何扩展它以收集整个表?
轻松自如-抓取整个数据表 (Getting comfortable — scraping an entire table of data)
To do this, we are going to identify the table, as we have done before, isolate each row of data, and then iterate through the row to collect the data elements.
为此,我们将像以前一样确定表,隔离数据的每一行,然后遍历该行以收集数据元素。
Upon review of the elements (see below screenshow), I notice that each column has a <td> tag with varying data-stat attributes, such as “wins”, “losses”, “win_loss_pct”, etc.
在查看了这些元素之后(请参见下面的屏幕显示),我注意到每列都有一个<td>标记,该标记带有变化的data-stat属性,例如“胜利”,“损失”,“ win_loss_pct”等。

We could hard-code these and loop through them manually. But, a more fun way is to actually grab a row, and generate a list of these column attributes, like below.
我们可以对它们进行硬编码并手动遍历它们。 但是,一种更有趣的方法是实际获取一行并生成这些列属性的列表,如下所示。
stat_keys = [col.attrs["class"][0] for col in data_rows[0].find_all("td")]This gets us a list of values:
这为我们提供了一个值列表:
['name', 'year', 'wins', 'losses', 'ot-losses', 'pct', 'gf', 'ga', 'diff']Using this snippet, we can just write a few lines of code to perform this task of grabbing the data. At a high level, the code loops through the rows, makes sure that the row is not a header row, loops through the columns to gather the data into a dictionary, and collates it all into a list.
使用此代码片段,我们只需编写几行代码即可完成抓取数据的任务。 在较高级别,代码循环遍历各行,确保该行不是标题行,遍历各列以将数据收集到字典中,然后将所有数据整理到一个列表中。
The entire resulting data is then put into a pandas DataFrame.
然后将整个结果数据放入pandas DataFrame中。
That should be relatedly clear, but if that didn’t make a lot of sense that’s okay. Instead, take a look at the code below. The actual code is quite succinct and almost shorter than the my description!
这应该是相对明确的,但是如果没有任何意义,那就没关系。 相反,请看下面的代码。 实际的代码非常简洁,几乎比我的描述要短!
重复任务-刮取多页 (Repeating the task — scraping multiple pages)
Let’s wrap this up by scraping data from multiple pages. You might have noticed the links to various pages at the bottom.
让我们通过从多个页面抓取数据来结束这一过程。 您可能已经注意到底部各个页面的链接。
Once again, take a look at the element — and from what we find, we can decide on our strategy.
再次查看元素-从发现的内容中,我们可以决定策略。

We can deal with this in one of a number of ways, but this time, we will grab each of the links here and then scrape each resulting page.
我们可以通过多种方式之一来解决这个问题,但是这次,我们将在这里获取每个链接,然后抓取每个结果页面。
The way I chose to do this is to fine the ul tagged element, with class attribute value of pagination. Then I find each li element, grab the href targets (i.e. the links), and then convert it through a set to remove any duplicates.
我选择执行此操作的方法是使用带有pagination类属性值的ul标记元素进行细化。 然后,我找到每个li元素,获取href目标(即链接),然后将其转换为一组以删除所有重复项。
pagination = soup.find("ul", attrs={"class": "pagination"})
link_elms = pagination.find_all("li")
links = [link_elm.find("a").attrs["href"] for link_elm in link_elms]
links = list(set(links))Straightforward, isn’t it?
直截了当,不是吗?
And all we need to do now is to create a function to generalise our task of scraping the page above, and concatenate the returned result from each page.
现在,我们需要做的就是创建一个函数,以概括我们抓取上面页面的任务,并连接每个页面的返回结果。
temp_dfs = list()
for link in links:
tmp_df = scrape_this(uri=link)
temp_dfs.append(tmp_df)
hockey_team_df = pd.concat(temp_dfs, axis=0).reset_index(drop=True)Just for good measure, we can sort the results and save them as a file:
出于良好的考虑,我们可以对结果进行排序并将其保存为文件:
hockey_team_df.sort_values(["year", "name"], inplace=True)
hockey_team_df.to_csv("hockey_team_df.csv")Putting it all together, we get:
放在一起,我们得到:
And that’s it! In just a few lines of code, we can scrape decades of data from this website to generate our own dataset.
就是这样! 仅需几行代码,我们就可以从该网站抓取数十年的数据来生成我们自己的数据集。
Just as a sanity check, let’s plot some of this data with plotly to see the correlation between win percentage and a few different metrics. One really key thing to note is that before manipulating downloaded pages, we need to convert data types in our dataframes!
正如一个全面的检查,我们绘制了一些这个数据与plotly看到的胜率和几个不同指标之间的相关性。 需要特别注意的一件事是,在处理下载的页面之前,我们需要转换数据框中的数据类型!
Why? Well, as you might know already — more or less all website data is presented as text. And text, even if it is of numbers, cannot be manipulated. So, wins for example need to be manipulated to:
为什么? 好了,您可能已经知道了-几乎所有网站数据都以文本形式显示。 即使文本是数字,也无法对其进行操作。 因此,例如需要将胜利操纵为:
hockey_team_df.wins = hockey_team_df.wins.astype(int)Some visualisation libraries will make this conversion internally, but if you are manipulating the data in pandas you will certainly need to do this.
一些可视化库将在内部进行此转换,但是如果您要处理熊猫中的数据,则肯定需要这样做。
(I won’t show full the code here, but it is in my GitHub repo — in the scraper_mult_pages.py file.)
(我不会在此处显示完整的代码,但它在我的GitHub存储库中 -在scraper_mult_pages.py文件中。)
So here’s a graph comparing win percentages vs goals scored for the season:
所以这是一个图表,比较了本赛季的胜率和进球数:

That’s not terrible but doesn’t look like that great a correlation. What about goals allowed (scored by opponent)?
这并不可怕,但看起来并没有那么大的相关性。 允许的进球数(对手得分)呢?
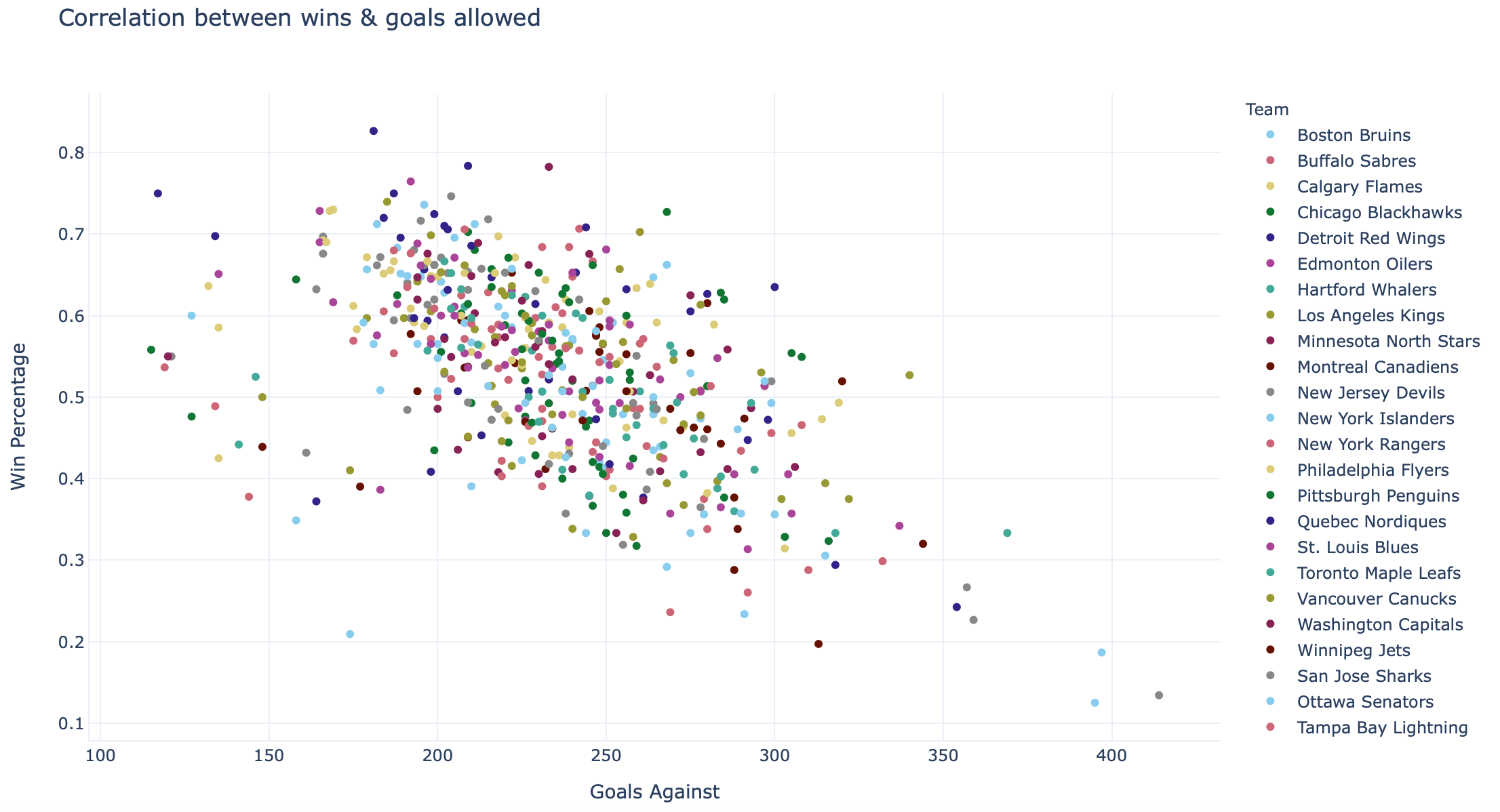
That’s better! Maybe defence does win championships / games. We can combine these two to look at goal differentials:
那更好! 也许防守确实赢得了冠军/比赛。 我们可以将两者结合起来看一下目标差异:

Woah! What’s a great correlation if I do say so myself.
哇! 如果我自己这么说的话,那有很大的相关性。
Isn’t that fantastic? Well, I think it is. You might not be that interested in this particular data, but the point is — you too now have all the tools you’ll need to get data on whatever it is that holds your interest.
那不是很棒吗? 好吧,我认为是。 您可能对特定的数据不那么感兴趣,但重点是-您现在也拥有获取所需数据的所有工具。
I hope that was useful. I for one am glad that I bothered to learn how to do this.
我希望这是有用的。 我很高兴能够去学习如何做到这一点。
There’s a lot more to scraping when you get down to it — using packages like selenium might become necessary for certain websites, and a more fully featured frameworks like scrapy might save you time on big projects. But there’s a lot that we can already do by adapting these techniques.
当您开始使用它时,抓取还有更多内容–对于某些网站,可能需要使用诸如Selenium之类的软件包,而像scrapy这样功能更全的框架可能会节省您进行大型项目的时间。 但是,通过采用这些技术,我们已经可以做很多事情。
Go ahead — try it out!
继续-试试吧!
With one note: This site that I have used explicitly allows scraping, but not everybody does. Web scraping has been a somewhat controversial topic, one recent case even going to court. As always, be sensible and respectful of other people’s sites and potential intellectual property.
有一个注释:我明确使用的此站点允许抓取,但并非所有人都可以。 网页抓取一直是一个颇有争议的话题,最近有一个案件甚至要提起诉讼 。 与往常一样,对他人的网站和潜在的知识产权要明智和尊重。
You can read more about it here: https://www.scraperapi.com/blog/is-web-scraping-legal/
您可以在这里了解更多信息: https : //www.scraperapi.com/blog/is-web-scraping-legal/
But just before you go — if you liked this, say hi / follow on twitter, or follow here for updates. ICYMI: I also wrote this article on visualising hidden information, using NBA assists data as an example:
但是在您出发之前-如果您愿意,请打个招呼/在twitte r上关注 ,或在此处关注更新。 ICYMI:我还写了这篇文章,以可视化隐藏信息为例,以NBA辅助数据为例:
and more recently, this one showcasing some amazing data science portfolios that I’ve found across the Internet.
最近,这本书展示了我在Internet上发现的一些惊人的数据科学产品组合。
查询数据 抓取 网站数据















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









