





etl dag 图构建
I admit it, as a data engineer I have been full of envy and jealousy towards my colleagues — application engineers — in countless times.When they were automating their production release and deployment generation processes, we had to waste hours drawing arrows and copying boxes from one ETL environment to another or manually resolving conflicts between different branches (if code versions on my colleagues’ laptops can be even called that) of a semantic model of a BI tool.
我承认,作为一名数据工程师,我充满了嫉妒和嫉妒。 对我的同事–应用程序工程师–进行了无数次的尝试。当他们使生产发布和部署生成流程自动化时,我们不得不浪费时间绘制箭头并将框从一个ETL环境复制到另一个ETL环境,或者手动解决不同分支之间的冲突( 如果使用代码版本,在我同事的笔记本电脑上甚至可以称为 BI工具语义模型。
And is that any ETL or BI tool that comes to mind still has that 90s flavor — Why this obsession to invest in a development GUI, which is end up using by programmers and not by business users? Why these little boxes connected with arrows with predefined data transformations that are never used? Why do we always end up building a component that ends up calling an external mega script (osCommand) filled with spaghetti code? Is SQL not worthy enough to have proper version control?
而且,是否想到的任何ETL或BI工具仍然具有90年代的风味 -为什么这种对开发GUI进行投资的痴迷,最终会被程序员而不是业务用户使用? 为什么这些小框与箭头相连,并带有从未使用过的预定义数据转换? 为什么我们总是最终构建一个组件,该组件最终调用填充有意大利面条代码的外部巨型脚本(osCommand)? SQL是否不值得拥有适当的版本控制?
Anyway, many questions, but few answers … until now
无论如何,有很多问题,但没有几个答案……直到现在
The data revolution that we have experienced in recent years i is undeniable. In virtually any industry you can think of, a data-centric transformation is no longer optional, but rather a necessity for business survival
我近年来经历的数据革命是不可否认的。 在几乎您可以想到的任何行业中,以数据为中心的转换不再是可选的,而是业务生存的必要条件
The hypothesis that the introduction of a competitive vector based on data analysis would add value has been widely validated. As is to be expected, the demand for more complete informational systems (descriptive and predictive) has grown exponentially, not being, by any means, restricted to business intelligence departments or reporting areas.
基于数据分析 引入 竞争向量 会增加价值的假设已得到广泛验证 。 可以预见的是,对更完整的信息系统(描述性和预测性)的需求呈指数级增长,而绝不局限于商业智能部门或报告区域。
My previous litanies of complaints, therefore, have done nothing but multiply, evidencing the lack of control and discipline that has always existed in the development of informational platforms, which, ultimately, cause quality problems or a very high time-to-market
因此,我以前的抱怨之争无非是多了,证明了信息平台开发中一直存在的缺乏控制和纪律,最终导致质量问题或上市时间过长
This increase in use has caused information platforms to reveal its flaws
使用量的增加已导致信息平台揭示其缺陷
But good news: You don’t have to reinvent the wheel. The list of problems associated with informational systems is exactly the same as those suffered by operational systems, more than a decade ago
但是,好消息是:您不必重新发明轮子。 与信息系统相关的问题列表与十多年前操作系统遭受的问题完全相同
So why don’t we apply the same formula for building modern applications to the world of data?
那么,为什么我们不采用相同的公式来构建现代应用程序到数据世界呢?
>enter DataOps
>输入数据操作
Of the principles defined in the DataOps manifest, without a doubt, my favorite is “9: Analytics is code”, I cannot agree more. You have to program more, not less!
毫无疑问,在DataOps清单中定义的原则中,我最喜欢的是“ 9:分析就是代码”,我对此表示同意。 您必须编写更多而不是更少的程序!
Will we finally be able to enjoy the benefits of continuous data integration? Can we finally make automatic deployments between environments? Are you telling me that we are going to be able to generate “Data Products” in the same way that we generate, for example, a mobile app?
我们最终能否享受到持续数据集成的好处? 我们最终可以在环境之间进行自动部署吗? 您是否告诉我,我们将能够以与生成移动应用程序相同的方式来生成“数据产品”?
新一代分析工具应运而生 (A new generation of analytical tools makes its way)
Taking the principles of the manifesto as references, probably, data warehouses have been the most advanced technological pieces in this new wave. Over the past few years, we have seen them embrace the cloud paradigm by providing extreme performance and on-demand environments. BigQuery, the market leading DWH Cloud, is a good example.
以宣言的原则为参考,数据仓库可能已成为新潮流中最先进的技术。 在过去的几年中,我们已经看到它们通过提供出色的性能和按需环境来拥抱云范式。 市场领先的DWH云BigQuery是一个很好的例子。
Unfortunately, these SQL execution platforms are “just” this — which is not small — execution platforms, but how do we manage the code to be deployed on these platforms? How do we integrate it? How do we run the tests automatically?
不幸的是,这些SQL执行平台只是“很小”的执行平台,但是我们如何管理要在这些平台上部署的代码? 我们如何整合它? 我们如何自动运行测试?
>enter dbt
>输入dbt
I must admit that I am deeply in love with data build tool, dbt, it is as if my data dreams had come true. dbt is an open source tool that consists of a SQL compiler and an executor, so that it allows us to programmatically define a sequence of data transformation integrating with, for example with BigQuery, dbt will take care of the materialization of the tables or views, of the table dependencies etc etc
我必须承认,我深爱数据构建工具 dbt,好像我的数据梦想已经实现。 dbt是一个开放源代码工具,由SQL编译器和执行器组成,因此它使我们能够以编程方式定义一系列数据转换序列,例如与BigQuery集成,dbt将负责表或视图的实现,表的依赖等

But how do we give expressiveness and logic to our data transformation sequence? Again, there is no need to reinvent the wheel, dbt incorporates integration with the jinja templating language so that we can annotate our code for example like this
但是,如何为数据转换序列赋予表现力和逻辑性呢? 再次,不需要重新发明轮子,dbt将与jinja模板语言的集成结合在一起,以便我们可以像这样注释我们的代码
Where we can, for example, depending on the current environment and the type of load (full, incremental load ..) , edit the SELECT projection or customized the WHERE predicate.
例如,根据当前环境和负载类型(完全,增量负载..),可以在其中编辑SELECT投影或自定义WHERE谓词。
How simple and how powerful!
多么简单,多么强大!
I bet you’re thinking now: “This is great, now I could make an ETL CI/CD pipeline, which, for example, executes dbt code on BigQuery when there is code push on the master branch”
我敢打赌,您现在在想: “这太好了,现在我可以建立一个ETL CI / CD管道,例如,当master分支上有代码推送时,它会在BigQuery上执行dbt代码”
What a coincidence, that is exactly what I thought!
真是巧合,那正是我的想法!
So, reusing a few repos here and there I have built this demo in Google Cloud where using GitHubActions as CICD software, every time I push code to the master, it generates and executes a dbt container in a kubernetes cluster that performs the transformations in BigQuery.
因此,重用一些回购在这里和那里我建立这在谷歌云在那里使用GitHubActions作为CICD软件演示,每一次我把代码给主人,它生成并执行DBT容器中kubernetes集群执行BigQuery中的转化。
That is, a 100% serverless ETL pipeline is possible, let’s see that in detail
也就是说,可以使用100%无服务器ETL管道,让我们详细了解一下
使用GKE和GitHubActions的BigQuery + dbt的无服务器管道… (A serverless pipeline with BigQuery + dbt using GKE and GitHubActions …)
… without any boxes and arrows
……没有任何方框和箭头


Let’s start with the dbt code itself. The most relevant concept within dbt is the definition of the so-called “models” that are nothing other than SQL statements that dbt will compile and execute, this is a example of an extremely simple model
让我们从dbt代码本身开始。 dbt中最相关的概念是所谓的“模型”的定义,除了dbt将要编译和执行SQL语句外,这就是一个非常简单的模型的示例
In this example I have used the BigQuery Public DataSet of the mobile coverage data of Catalonia (I have copied it into this other dataset called warehouse as seen in the example code).
在此示例中,我使用了加泰罗尼亚移动覆盖率数据的BigQuery Public DataSet (已将其复制到另一个数据集中,称为仓库,如示例代码所示)。
When this code is executed, the table is materialized in a physical table, and then we can reference it in later steps of the pipeline using {{ref (“avg_signal_contaminant”)}}, where avg_signal_contaminant is the name of the .sql file where we have defined the SQL statement.
执行此代码后,该表将在物理表中具体化,然后我们可以在管道的后续步骤中使用{{ref(“ avg_signal_contaminant”)}}引用该表,其中avg_signal_contaminant是.sql文件的名称,其中我们已经定义了SQL语句。
Once the entire pipeline has been defined, dbt will be in charge of analyzing the dependencies and building the dependency graph, for this little example, as said I have used the mobile coverage table for Catalonia in the years 2015–2017, additionally I have loaded data from Catalonia OpenData on meteorology and air pollutants in Catalonia, the ultimate objective of the small project being to generate a final table with the aggregated data on mobile coverage and pollutants in the Barcelona area.
一旦定义了整个管道,dbt将负责分析依赖关系并构建依赖关系图,对于这个小例子,正如我所说的,我在2015-2017年间使用加泰罗尼亚的移动覆盖率表,此外,我已经加载了来自Catalonia OpenData的有关加泰罗尼亚的气象和空气污染物的数据,这个小项目的最终目标是生成一张最终表格,其中包含巴塞罗那地区的移动覆盖范围和污染物的汇总数据。
Finally, it is also interesting to note that with the dbt docs command, we can easily generate the documentation of the process including a nice lineage graph
最后,还有趣的是,使用dbt docs命令,我们可以轻松生成流程的文档,包括漂亮的血统图

In addition to this, we have to generate some additional configuration files, for instance the BigQuery connection configuration file that has the following structure
除此之外,我们还必须生成一些其他配置文件,例如具有以下结构的BigQuery连接配置文件
The interesting thing about this profile file is that we can define various environments, such as development or production datasets and later reference them in our dbt models using macros.
关于此配置文件的有趣之处在于, 我们可以定义各种环境 ,例如开发或生产数据集,然后使用宏在dbt模型中引用它们。
Once we have finished the transformation in our development environment (in my case my local environment), simply by running the dbt run command from the command line we can execute the entire pipeline (not including tests)
在开发环境(在我的情况下为本地环境)中完成转换之后,只需从命令行运行dbt run命令,我们就可以执行整个管道(不包括测试)

We can check that the results back in BigQuery
我们可以在BigQuery中检查结果

For more details on the entire setup process, you can have a look at the documentation
有关整个设置过程的更多详细信息,请查看文档
Once we have a functional data transformation pipeline fully described in code, we will generate a CI/CD workflow!
一旦有了用代码完整描述的功能数据转换管道,我们将生成CI / CD工作流程!
What do you think about the idea that this ETL is executed in the development environment every time a commit is made in the dbt code? Obviously we can complicate things as desired: execution of automatic tests, merge of branches, pushes to production, sending notifications to our slack channel …There are multiple tools such as Google Cloud Build, CircleCI or the one we are going to use in this example: GitHub Actions.
您认为每次在dbt代码中进行提交时都会在开发环境中执行此ETL的想法是什么? 显然,我们可以根据需要使事情复杂化:自动测试的执行,分支的合并,推送到生产,将通知发送到我们的闲暇渠道……有多种工具,例如Google Cloud Build,CircleCI或本示例中将使用的工具: GitHub动作 。
This is the code for the GitHub Actions workflow
这是GitHub Actions工作流程的代码
Basically, for each push to the master we will generate and execute an container with the dbt code in a Google Kubernetes Engine cluster.
基本上,每次向master推送时,我们将在Google Kubernetes Engine集群中生成并执行带有dbt代码的容器。
A couple of things to keep in mind: the need to previously define the secrets of the pipeline with, for example, the key of the GKE Service Account ${{secrets.GKE_SA_KEY}}.
需要牢记的两件事:需要预先定义管道的机密,例如,使用GKE服务帐户$ {{secrets.GKE_SA_KEY}}的密钥。
And it is also important to generate the keyfile.json file from the GitHub Actions secret with the SA key defined in the dbt profile file, to be able to attach it to the dbt image and connect to BigQuery.
同样重要的是,使用dbt概要文件中定义的SA密钥从GitHub Actions机密生成keyfile.json文件,以便能够将其附加到dbt映像并连接到BigQuery。
This would be the Docker configuration file that I have prepared
这将是我准备的Docker配置文件
I have used the official dbt Docker image, which has been on the DockerHub for a relatively short time
我使用了官方的dbt Docker镜像,该镜像在DockerHub上的发布时间相对较短
Well, once the configuration is finished we can git commit to GitHub and we can see the execution of our GitHub Actions workflow
好了,一旦配置完成,我们可以将git提交到GitHub,然后可以看到GitHub Actions工作流程的执行情况

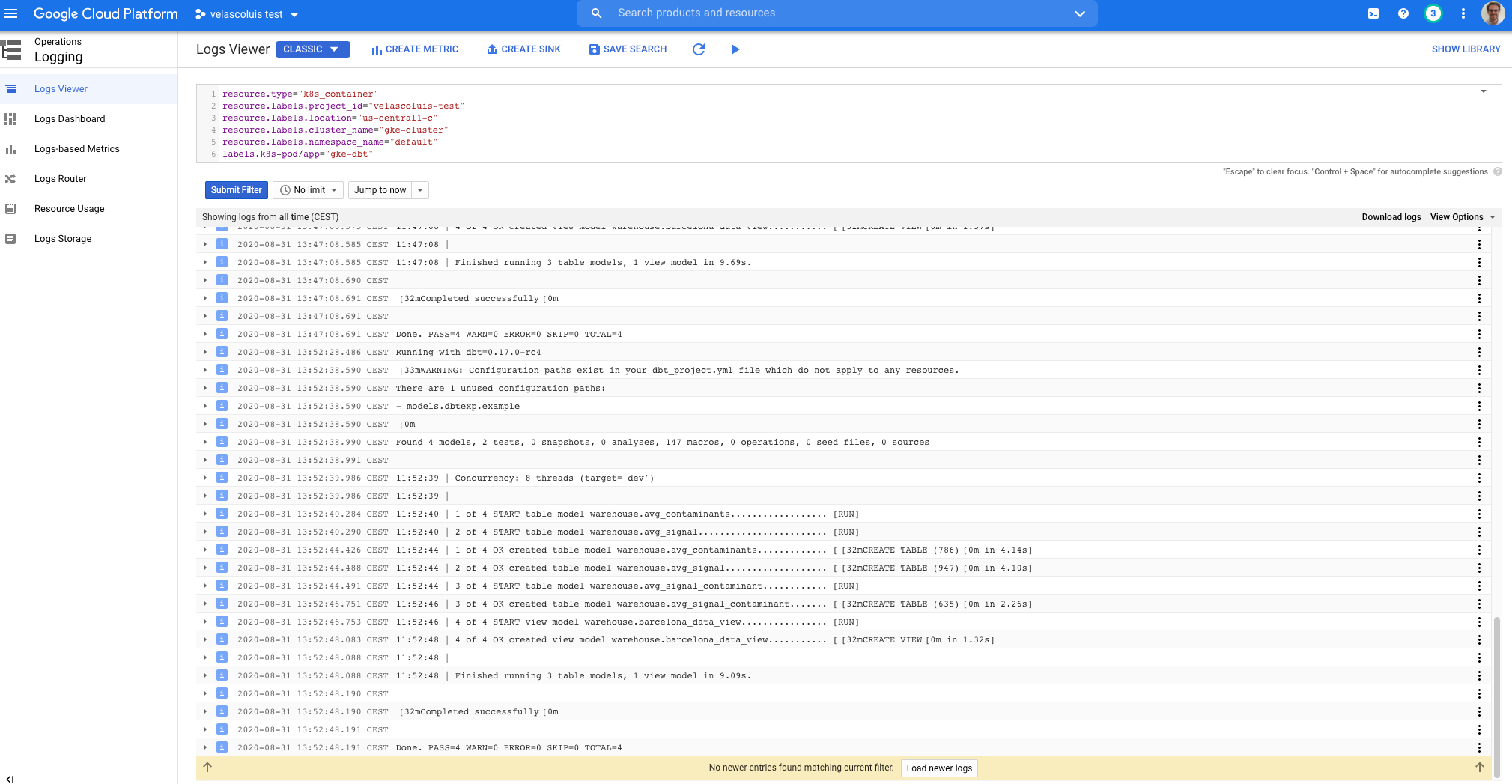
We can check the execution logs of the pod in the kubernetes cluster and everything has worked perfectly!
我们可以检查kubernetes集群中Pod的执行日志,一切运行正常!
摘要 (Summary)
Can we finally treat a complete information system from a DataOps perspective? The promise of a modern approach to building information systems is closer than ever.
我们最终可以从DataOps角度对待完整的信息系统吗? 建立信息系统的现代方法的承诺比以往任何时候都更加紧密。
In this article we have focused on perhaps the most important and heaviest part, data integration, but what about semantic models, reports and the exploitation layer in general? Can we have a similar programmatic approach? Will there be a semantic layering model language? (SPOILER = Yes, it’s called lookML)
在本文中,我们重点讨论了可能最重要和最繁重的部分,即数据集成,但是语义模型,报告和利用层通常如何? 我们可以采用类似的编程方法吗? 会有语义分层模型语言吗? (SPOILER =是,它称为lookML )
What a time to be a Data Engineer!
什么时候成为一名数据工程师!
Yours truly,
敬上,
etl dag 图构建















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









