






 安然数据集分析处理 介绍 (Intro)Natural Language Processing (NLP) has been gaining tractions in recent years, allowing us to understand unstructured text data in a way that was never possible before. One of the ...
安然数据集分析处理 介绍 (Intro)Natural Language Processing (NLP) has been gaining tractions in recent years, allowing us to understand unstructured text data in a way that was never possible before. One of the ...
安然数据集分析处理
介绍 (Intro)
Natural Language Processing (NLP) has been gaining tractions in recent years, allowing us to understand unstructured text data in a way that was never possible before. One of the promises of NLP is to use relevant techniques to detect fraud in companies and shed light on potential violations in the early phase.
近年来,自然语言处理(NLP)受到越来越多的关注,这使我们能够以前所未有的方式理解非结构化文本数据。 NLP的承诺之一是使用相关技术来检测公司中的欺诈行为,并在早期阶段揭示潜在的违规行为。
关于数据集 (About the dataset)
I’ve only managed to find two earnings call transcripts online. And only one ofthem is readable when converted from PDF to text. You can find the originaldocument here.
我只设法在网上找到两个收入电话会议记录。 从PDF转换为文本时,只有其中之一是可读的。 您可以在此处找到原始文档 。
The earnings call transcript used in this article is from Enron’s conference call hold on November 14, 2001. Enron filed for bankruptcy on December 2, 2001.
本文使用的收入电话会议记录来自2001年11月14日举行的安然电话会议。安然于2001年12月2日申请破产。
预处理数据集 (Pre-processing the dataset)
As you can see from the original Earnings, call PDF document, the documentis not digital and contains numbers in between the conversations.
从原始收入中可以看到,调用PDF文档,该文档不是数字文档,并且在对话之间包含数字。

To pump the spoken sentences into R programming for analysis, I use Robotic Process Automation (RPA) to massage the text data into a more structured format. Below is a snapshot of the organized text data in CSV format.
为了将口语句子输入到R编程中进行分析,我使用了机器人过程自动化(RPA)来将文本数据压缩为更加结构化的格式。 以下是CSV格式的组织文本数据的快照。
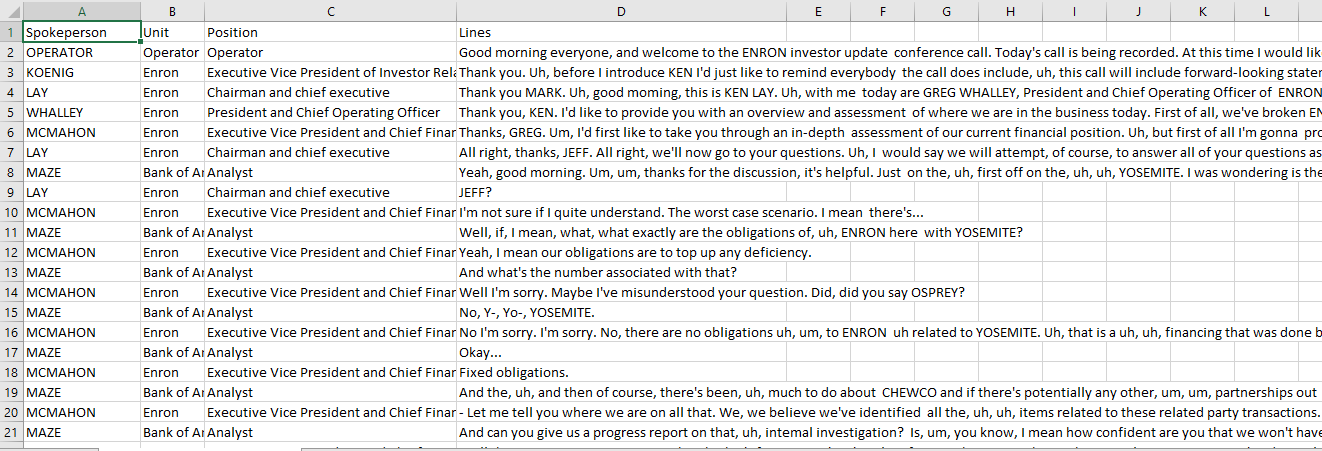
I then tokenize and remove common stop words from the dataset. To make the results more insightful, I also dropped all the numbers and a fewfiller words such as “um,” “uh,” etc. from the dataset. After cleaning the dataset, I wa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









