






 本文介绍了如何在Python3中进行情感分类,翻译自一篇关于数据科学的文章,探讨了使用Python进行情感分析的基本方法。
本文介绍了如何在Python3中进行情感分类,翻译自一篇关于数据科学的文章,探讨了使用Python进行情感分析的基本方法。
python3中情感分类
This post is the last of the three sequential posts on steps to build a sentiment classifier. Having done some exploratory text analysis and preprocessed the text, it’s time to classify reviews to sentiments. In this post, we will first look at 2 ways to get sentiments without building a model then build a custom model.
这篇文章是关于建立情感分类器的三个连续文章中的最后一篇。 经过一些探索性的文本分析并预处理了文本 ,是时候对评论进行分类了。 在本文中,我们将首先探讨两种无需构建模型即可获得情感的方法,然后构建自定义模型。
Before we dive in, let’s take a step back and look at the bigger picture really quickly. CRISP-DM methodology outlines the process flow for a successful data science project. In this post, we will do some of the tasks that a data scientist would go through during the modelling stage.
在我们深入之前,让我们退后一步,真正快速地了解大局。 CRISP-DM方法论概述了成功的数据科学项目的流程。 在本文中,我们将完成数据科学家在建模阶段要完成的一些任务。
0. Python设置 (0. Python setup)
This post assumes that the reader (👀 yes, you!) has access to and is familiar with Python including installing packages, defining functions and other basic tasks. If you are new to Python, this is a good place to get started.
这篇文章假定读者(👀,是的,您!)可以访问并熟悉Python,包括安装软件包,定义函数和其他基本任务。 如果您不熟悉Python,那么这是一个入门的好地方。
I have tested the scripts in Python 3.7.1 in Jupyter Notebook.
我已经在Jupyter Notebook中的Python 3.7.1中测试了脚本。
Let’s make sure you have the following libraries installed before we start:◼️ Data manipulation/analysis: numpy, pandas◼️ Data partitioning: sklearn◼️ Text preprocessing/analysis: nltk, textblob◼️ Visualisation: matplotlib, seaborn
让我们确保你已经在我们开始之前安装以下库:◼️ 数据处理/分析:numpy 的,熊猫 ◼️ 数据分区:sklearn◼️ 文本预处理/分析:NLTK,textblob◼️ 可视化:matplotlib,seaborn
Once you have nltk installed, please make sure you have downloaded ‘stopwords’ and ‘wordnet’ corpora from nltk with the script below:
安装nltk之后 ,请确保使用以下脚本从nltk下载了' stopwords '和'wordnet'语料库:
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('vader_lexicon')If you have already downloaded, running this will notify you so.
如果您已经下载了,运行它会通知您。
Now, we are ready to import all the packages:
现在,我们准备导入所有软件包:
# Set random seed
seed = 123# Data manipulation/analysis
import numpy as np
import pandas as pd# Text preprocessing/analysis
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import RegexpTokenizer
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from textblob import TextBlob
from scipy.sparse import hstack, csr_matrix
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler# Modelling
from sklearn.model_selection import train_test_split, cross_validate, GridSearchCV, RandomizedSearchCV
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.pipeline import Pipeline# Visualisation
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set(style="whitegrid", context='talk')1.数据📦 (1. Data 📦)
We will use IMDB movie reviews dataset. You can download the dataset here and save it in your working directory. Once saved, let’s import it to Python:
我们将使用IMDB电影评论数据集。 您可以在此处下载数据集并将其保存在您的工作目录中。 保存后,让我们将其导入Python:
sample = pd.read_csv('IMDB Dataset.csv')
print(f"{sample.shape[0]} rows and {sample.shape[1]} columns")
sample.head()
Let’s look at the split between sentiments:
让我们看一下情感之间的分歧:
sample['sentiment'].value_counts()
Sentiment is evenly split in the sample data. Let’s encode the target into numeric values where positive is 1 and negative is 0:
情感在样本数据中平均分配。 让我们将目标编码为数值,其中正数为1,负数为0:
sample['target'] = np.where(sample['sentiment']=='positive', 1, 0)# Check values
sample.groupby(['sentiment', 'target']).count().unstack()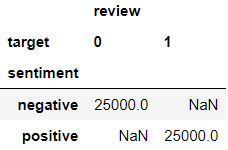
Let’s set aside 5000 cases for testing:
让我们预留5000个案例进行测试:
# Split data into train & test
X_train, X_test, y_train, y_test = train_test_split(sample['review'], sample['sentiment'], test_size=5000, random_state=seed,
stratify=sample['sentiment'])# Append sentiment back using indices
train = pd.concat([X_train, y_train], axis=1)
test = pd.concat([X_test, y_test], axis=1)# Check dimensions
print(f"Train: {train.shape[0]} rows and {train.shape[1]} columns")
print(f"{train['sentiment'].value_counts()}\n")print(f"Test: {test.shape[0]} rows and {test.shape[1]} columns")
print(test['sentiment'].value_counts())
We will quickly inspect the head of the training dataset:
我们将快速检查训练数据集的头部:
train.head()
Alright, let’s dive in! 🐳
好吧,让我们潜入吧! 🐳
1.情感分析💛 (1. Sentiment analysis 💛)
In this section, I want to show you two very simple methods to get sentiments without building a custom model. We will extract polarity intensity scores with VADER and TextBlob.
在本节中,我想向您展示两种非常简单的方法,无需构建自定义模型即可获得情感。 我们将提取与VADER和TextBlob极性强度分数。
1.1。 使用VADER进行情感分析 (1.1. Sentiment analysis with VADER)
Let’s start with a simple example and see how we extract sentiment intensity scores using VADER sentiment analyser:
让我们从一个简单的示例开始,看看如何使用VADER情感分析器提取情感强度得分:
example = 'The movie was awesome.'
sid = SentimentIntensityAnalyzer()
sid.polarity_scores(example)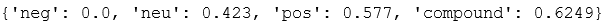
neg,neu,pos: 这三个分数总计为1。这些分数显示了每个类别中的文字所占的比例。 复合: 此分数的范围是-1(最负)至1(最正)。
Although not all reviews would be as simple as our example at hand, it’s good to
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









