







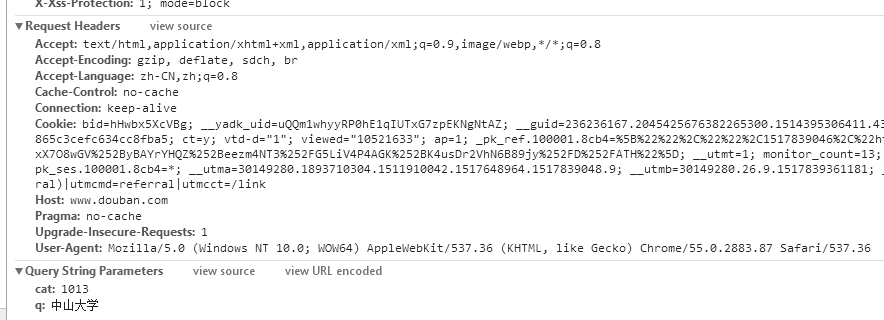
获取到以上信息后就可以开始写爬虫了
首先创建一个py文件,然后引入必要的包
import re,urllibfrombs4 import BeautifulSoup
import datetime, time
然后创建一个类:
class DouBanCrawler(object):
在这个类下写所有逻辑代码
1:初始化数据方法:
def __init__(self):'''Constructor''' self.session = SessionCrawler(sleepRange=[3, 8])
self.headers={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.8','Cache-Control': 'max-age=0','Connection': 'keep-alive','Host': 'www.douban.com','Upgrade-Insecure-Requests': '1'}
这段代码我将headers参数全局话调用,内容是刚刚用f12查看到的
然后我用的是session工具来进行http请求,其中
self.session = SessionCrawler(sleepRange=[3, 8])
SessionCrawler是我封装的外部类
内容如下:
import requests
import time
import random
import tracebackclas
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2924
2924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









