







一、为什么要用C语言
我曾经的理想是一直用汇编语言来编写操作系统,因为只有用汇编语言才能感觉到自己是下沉到计算机的最底层来控制它,一旦动用了其它的更高级的语言(如C语言),会让自己觉得自己的工作再也不那么“纯粹”了。因为高级语言是建立在已有操作系统和别的编译器基础之上的。我们的目标本来就是从0开始造一个操作系统,可是还没写出来之前就先用了别人的操作系统和工具了,这样的感觉让人感到气馁。
但是,换个角度想就完全有不同的感受了。难道用汇编语言来写操作系统就没有建立在别人的工作基础之上吗?一样的需要汇编语言汇编器啊,别人同样为你做了很多的工作。我们在前面写汇编语言编写操作系统的过程中,用了无数的工具、软件和API(如BIOS中断)等,这些全都是建立在别人的工作基础上的。哪怕是你用纯粹的机器代码来写操作系统,最后把机器代码写进启动设备的时候,还得借用别人做好的工具呢。就算你有办法把机器代码弄进设备里面,计算机识别机器代码并正确执行还需要硬件电路支持呢;硬件电路需要数字电路,数字电路需要电子设备,电子设备需要半导体,半导体需要物理材料......因此,你究竟觉得应该从哪里做起才叫从0开始呢?这显然是没有止境的。
但是,这个世界确实有只用汇编语言来编写的操作系统。大名鼎鼎的MenuetOS就是:
MenuetOSwww.menuetos.net而且这个操作系统的优秀让人吃惊:像WINDOWS一样的一个包含各种功能的视窗操作系统,它的安装镜像全部加起来只有一张软盘(1.44MB)大小,所以汇编语言的优势是十分明显的。虽然仅用汇编语言编写且容量如此渺小,但是这个操作系统可以打游戏、办公、上网、看电影等,是两个国外的牛人坚持了数10年之久完成的杰作。惊叹于他们的这份毅力和坚持,是我一直崇拜的偶像。从某种程度上讲,此专栏的诞生就是受到他们的启发而作。
但是,我在自制操作系统进入到32位之后,坚持用汇编语言的想法却一下就改变了。在16位的实模式下,操作系统主要涉及MBR启动、磁盘读写、BIOS中断、内核装载LOADER、进入保护模式等流程,这些都是汇编语言的强项,因此操作系统在进入32位保护模式前,用汇编语言是最好的选择。但是在进入32位之后,重点的工作就是开发操作系统内核了,开发内核涉及的工作就太多了。保护模式下,BIOS中断再也不能使用了,一切计算机硬件设备的控制都需要自己来编程,硬件涉及显卡、键盘、鼠标、硬盘......软件涉及进程、任务、调度。这些工作的完成如果再用汇编语言的话,工程量就太大了。
这是因为汇编语言最大的劣势是缺乏足够的封装,一切的运算和操作都需要自己来设计,这就要求开发人员必须要非常的熟悉处理器的指令手册(比如INTEL系列CPU指令手册),一份指令手册动辄就是几百个指令集。说实话,要不是长期做CPU底层方面的特殊开发工作,普通的计算机学习和应用者又会有几人能很专业的掌握呢。
比如现在我们需要一个计算:a=x/y;b=x%y的过程,用汇编语言实现,步骤的步骤如下:
1.查询INTEL系列CPU指令手册,手册上写的指令格式是:DIV r/m32。
2.放操作数:
2.1 x必须要放进EAX:mov eax,x
2.2 y可以有一些选择(如EBX、EDX),我们可以把它放进EBX:mov ebx, y
3.指令执行:DIV EBX。
4.取操作结果:
4.1 商必须要从EAX 中取: mov a,eax
4.2 余数必须要从EDX 中取: mov b,edx
就这简单的一个除法,就必须动用以上复杂的过程。其实倒不是说汇编语言有多么的烧脑和复杂,主要是它非常的繁琐,繁琐得你今天学会了这个除法写法,但后天就会忘记了,所以下次遇到还必须得重新重复以上过程。这样一来,用汇编语言编程,大量的时间和精力都会花在这些细枝末节上面,主体的工作反而会进展得非常的缓慢,这样就会逐渐消除编程者的信心和成就感,偏离我们的学习目标。
我们是在开发操作系统,编码量得多大啊。所以这个时候,C语言的优势体现就毫无疑问:上面的问题,只需两句语句a=x/y;b=x%y就解决,根本不需要开发者关心和掌握哪些寄存器参与了,然后从哪些寄存器取结果。这些过程,C语言编译器都替你完成了。
结论:以后的工作就必须要使用C语言了。
但我要再一次向坚持使用纯汇编语言的大神们致敬!
二、怎么使用C语言
先来回顾一下,到目前为止,我们的操作系统进展到什么程度:
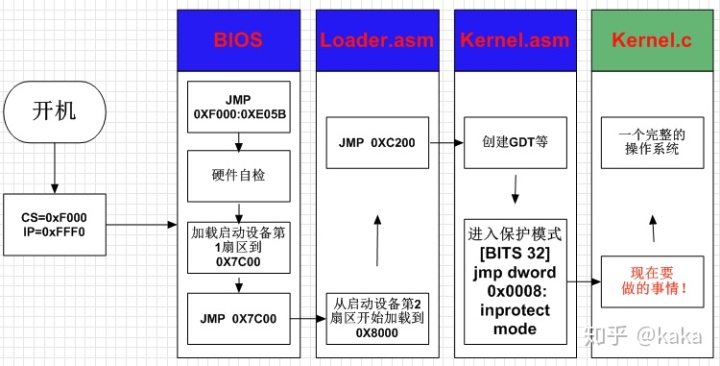
其中,Loader.asm和Kernel.asm的完整程序代码在前面的章节中已经贴出。目前由于开发工作遇到了效率瓶颈,现在我们就需要用C语言来继续进行我们的工作---操作系统内核的编写。其实,从上图中可以看到我们进入保护模式的时候,程序都不应该叫做内核,顶多叫做装载而已,名字明显起早了。但是,当时一步步的学习,不是有很多不懂的地方嘛,也没关系,就姑且这样吧。那我们以后的工作就是集中精力编写Kernel.c这个程序,终极目标就是让它变成一个完整的操作系统。
图中可以看出,操作系统完整的程序执行过程:Loader.asm--->Kernel.asm--->Kernel.c。那我们现在就只需要把Kernel.c在内存上顺序的布置在Kernel.asm的后面即可。那怎么才能把Kernel.c贴在Kernel.asm的屁股后面呢,方法就是把Kernel.asm编译成的二进制文件(Kernela.bin)和Kernel.c编译成的二进制文件(Kernelc.bin)连接在一起嘛:
copy /b Kernela.bin+Kernelc.bin Kernel.bin
这样得到新的Kernel.bin文件就可以利用Loader.asm进行装载了。Kernela.bin倒是非常的简单,直接一条NASM编译命令就可,前面都已经完成该项工作了,本章我们就来研究怎么才能得到Kernel.c编译之后的二进制文件。
- 传统的C编译器不适合
假设我们现在的任务是要在屏幕上显示一个红色的字母"C",汇编程序应该是这样写:
;保护模式下,此程序正常运行的前提是DS要先映射到物理地址:0Xb8000.
mov byte [00],'C' ;显示字符
mov byte [01],0x0c;红色将这段代码编译之后,机器码如下,我们需要记住这段机器码。

现在我们换成用C语言来编写,最小格式如下:
/* file:zh.c */
int main()
{
*(char *)(00) = 'C';
*(char *)(01)= 0x0c;
stop:goto stop;
return 0;
}程序中,我们必须定义main函数,否则无法通过C编译器编译。最有名的C编译器无疑是GCC,某种意义上讲GCC是UNIX的代表,但是由于我这次一直是在WINDOWS的环境下开发的,没有借助于任何的UNIX系统,因此还需安装WINDOWS版本的GCC编译器---MinGW。用GCC编译上面程序:

就可以得到C语言编译之后的二进制目标程序:zh.o,我们打开该文件看看:
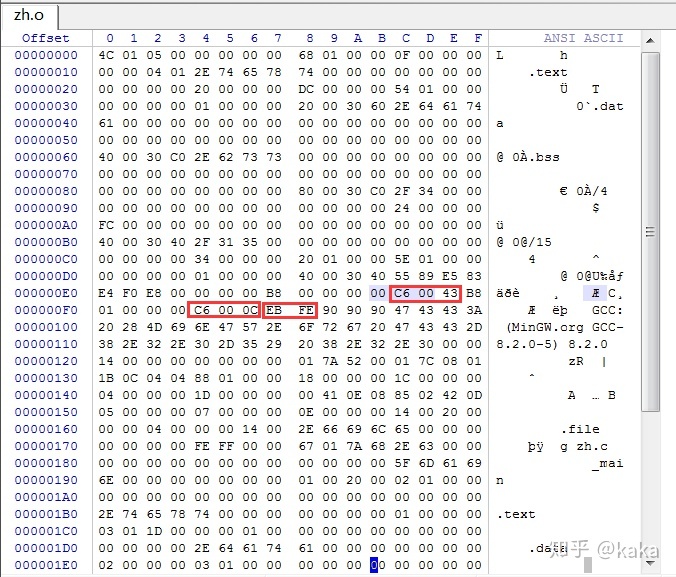
可以看出,这个和汇编语言NASM编译出来的机器代码并不一样,我们只找到了JMP $这条指令对应的机器代码,但是我们能隐约地感觉到前面两句应该就是我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









