






展开阅读全文
今天碰到一个有些奇怪的问题,有一套环境,在主从复制的时候有一些问题。
大体的流程设计如下:
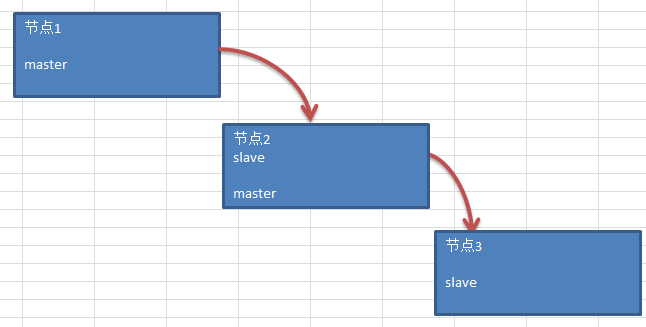
三个节点位于三个不同的区域,因为节点1和节点3之间的网络存在问题,所以走了节点2来中转,由此可见延迟是难免的,但是延迟不能太大。最终的数据还是要通过节点3来做统计分析查询。这套环境的数据量不大,但是数据变更貌似是比较频繁。早上开发的同事反馈,节点同步感觉延迟很大,想让我帮忙看看到底是哪里出了问题。
查看节点1,节点2没有延迟,问题就出在节点2到节点3的延迟。
在节点3中查看slave状态:
> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host:xxxx
Master_User: repl
Master_Port: 3307
Connect_Retry: 10
Master_Log_File: mysql-bin.000009
Read_Master_Log_Pos: 16186388
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 13599457
Relay_Master_Log_File: mysql-bin.000009
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
...
Last_Errno: 1032
Last_Error: Could not execute Delete_rows event on table test_mbi.test_dist_online; Can't find record in 'test_dist_o
Skip_Counter: 0
Exec_Master_Log_Pos: 13599294
Relay_Log_Space: 16304336
Until_Condition: None
...
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Delete_rows event on table test_mbi.test_dist_online; Can't find record in 'test_dist_o
Replicate_Ignore_Server_Ids:
Master_Server_Id: 23307
Master_UUID: 189a00c4-16a3-11e6-a678-06c76b65c01e
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
1 row in set (0.00 sec)
发现在日志应用中出现了1032的错误,即删除的数据在从库中找不到。一般来看这类问题,感觉好像说小也小,那skip一下吧,发现这个不是权宜之计,因为skip了这个问题之后接着又碰到了同样的问题,所以反反复复修改skip本身就是一件隔靴挠痒的事情,而且实际上数据已经不一致了。
因为需求紧迫,时间又比较紧张,数据的延迟较大,所以简单评估之后发现还是重建从库。
当然这个步骤就很常规了。我也简单列举一下:
因为是多实例的场景,所以使用了如下的命令来导出:
/opt/mysql/bin/mysqldump -S /data2/bmbidb/mysql.sock --single-transaction --master-data=2 -B test_ad test_mbi test_sys_mgr |gzip > test.sql.gz
然后在各种网络层面周旋,总算是把这个dump从节点2拷贝到了从库环境节点3
然后在节点3停止slave,开始导入数据:
gunzip < test.sql.gz | /opt/mysql/bin/mysql --socket=/home/bmbidb/mysql.sock --port=3307
start slave
接着开始change master,当然这个时候对于MASTER_LOG_FILE,MASTER_LOG_POS可以通过dump来得到这些信息
gunzip < tes.sql.gz | head -50
会发现下面这么一段内容:
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000008', MASTER_LOG_POS=241903809;
这就是需要我们关注的地方,然后直接使用即可。
CHANGE MASTER TO MASTER_HOST='xxxx',MASTER_USER='repl',MASTER_PASSWORD='xxxx',MASTER_PORT=3307,MASTER_LOG_FILE='mysql-bin.000008', MASTER_LOG_POS=241903809,MASTER_CONNECT_RETRY=10;
这样从库的设置就完成了。
然后在下午的晚些时间又碰到了类似的问题,这可让我很纠结了,不可能一出现这种情况我就重建从库吧。
排除了很多潜在的原因,包括sync_binlog,表结构差异,节点中的数据库权限,表的存储引擎等。貌似还是没有找到要领。
通过mysqlbinlog去解析relay日志,依旧是无功而返。
/opt/mysql/bin/mysqlbinlog -vv relaylog.05 --base64-output decode-rows > relay05.tmp
所以这个问题还是很让人纠结的。
在同事的协助下,暂时使用了一个临时方案先来过渡。对于这类的DML操作如果数据不存在,可以选择忽略,即设置slave_exec_mode为IDEMPOTENT,而默认职位STRICT
> set global slave_exec_mode='IDEMPOTENT';
Query OK, 0 rows affected (0.00 sec)
> stop slave;set global sql_slave_skip_counter=1;start slave;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
修改完成后,这类问题暂时告一段落,还需要找到根本的原因。这种情况下比对了部分的数据,没有发现其他的数据冲突,但是解决方案也需要一个合理的解释。我们下一篇来继续聊聊这个,应该会有一个答复。
本文首发在云栖社区,遵循云栖社区版权声明:本文内容由互联网用户自发贡献,版权归用户作者所有,云栖社区不为本文内容承担相关法律责任。云栖社区已在2020年6月升级到阿里云开发者社区。如果您发现有涉嫌抄袭的内容,请填写侵权投诉表单进行举报,一经查实,阿里云开发者社区将协助删除涉嫌侵权内容。
网友评论
登录后评论
0/500
评论















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









