



 本文通过创建Aurora实例与RDS MySQL实例进行对比实验,包括数据导入与查询性能测试。结果显示在小规模数据下两者性能相近,但在大规模数据和压力测试下,Aurora与RDS MySQL的性能差距将显现。
本文通过创建Aurora实例与RDS MySQL实例进行对比实验,包括数据导入与查询性能测试。结果显示在小规模数据下两者性能相近,但在大规模数据和压力测试下,Aurora与RDS MySQL的性能差距将显现。
创建一个Aurora实例
使用MySQL Workbench连接Aurora和RDS MySQL
通过dump file 加载数据到Aurora和RDS MySQL
使用查询语句验证Aurora和RDS MySQL性能
Task1:创建Aurora数据库:
创建一个Aurora数据库,跟创建RDS一样,登录AWS管理控制台,搜索Aurora,创建数据库。

数据库类型选择,Aurora with MySQL compatibility,其他默认就好。


Templates选择 Dev/Test

DB instance size 选择db.t3.small就好,因为是测试环境,如果是生产环境选择Memory Optimized的类型R系列。土豪在测试时选择高配实例也可以。
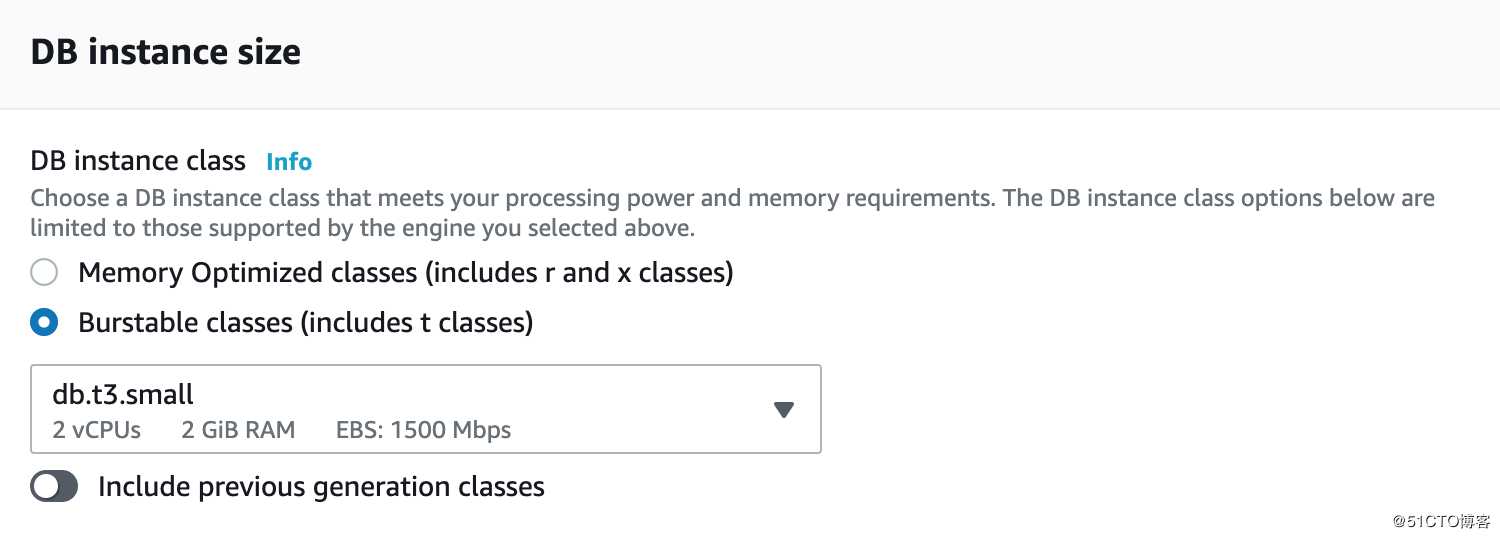
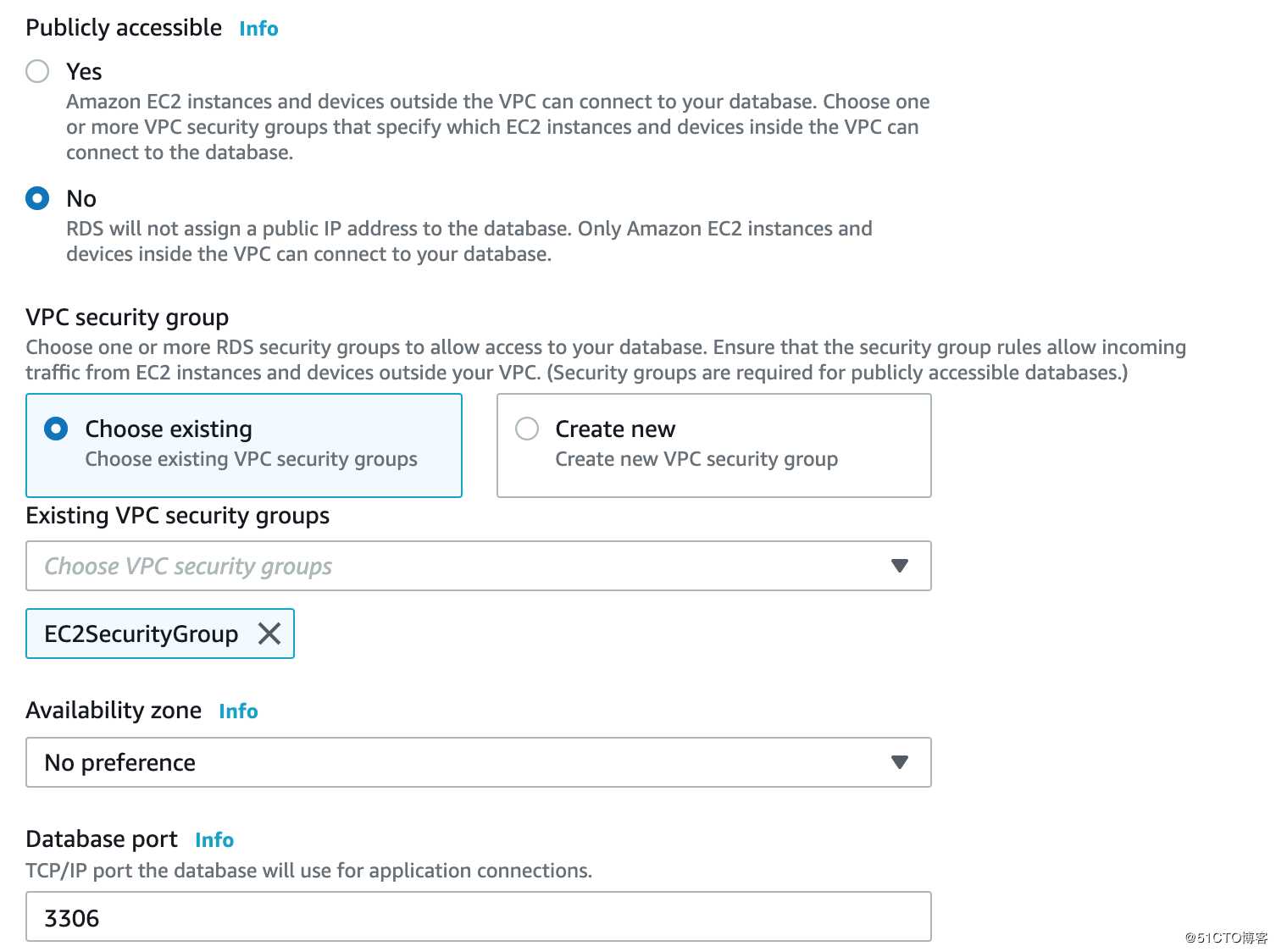
注意在security group放行的端口,由于测试环境,我们可以都放行。

其他配置保持默认即可,创建数据库。
然后创建一个同类型的(db.t3.smal)RDS mysql数据库。
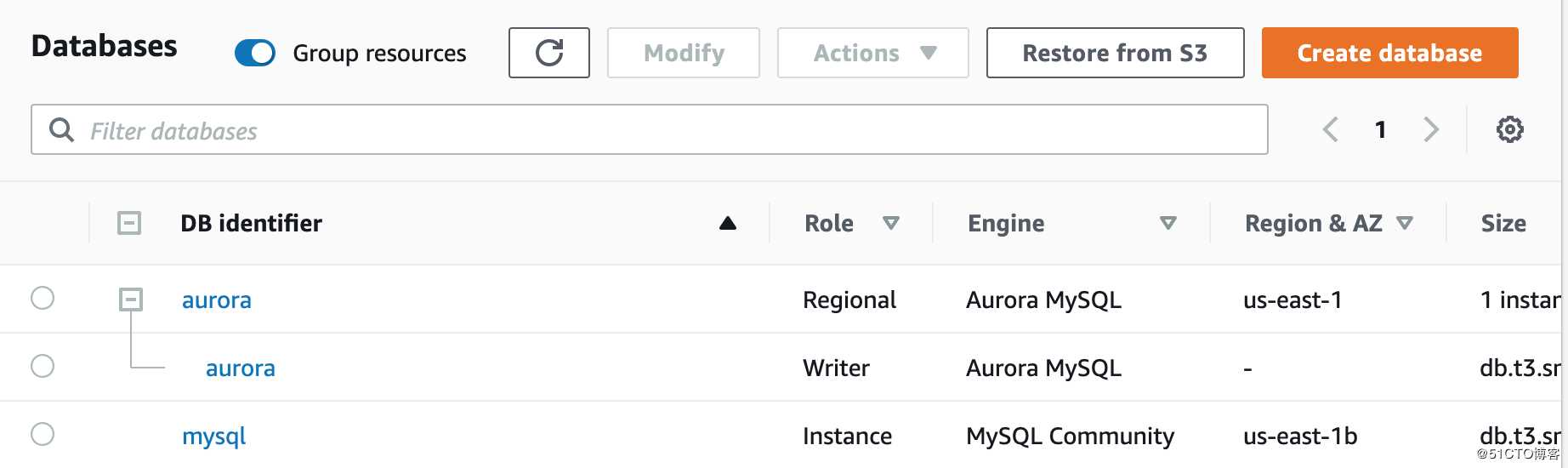
创建成功后如下:
Task2:连接跳板机并安装MySQL workbench:
跳板机为windows 或 Linux 都可以,我这里以windows 举例:
Task3:通过跳板机连接Aurora和RDS MySQL
Aurora endpoint:
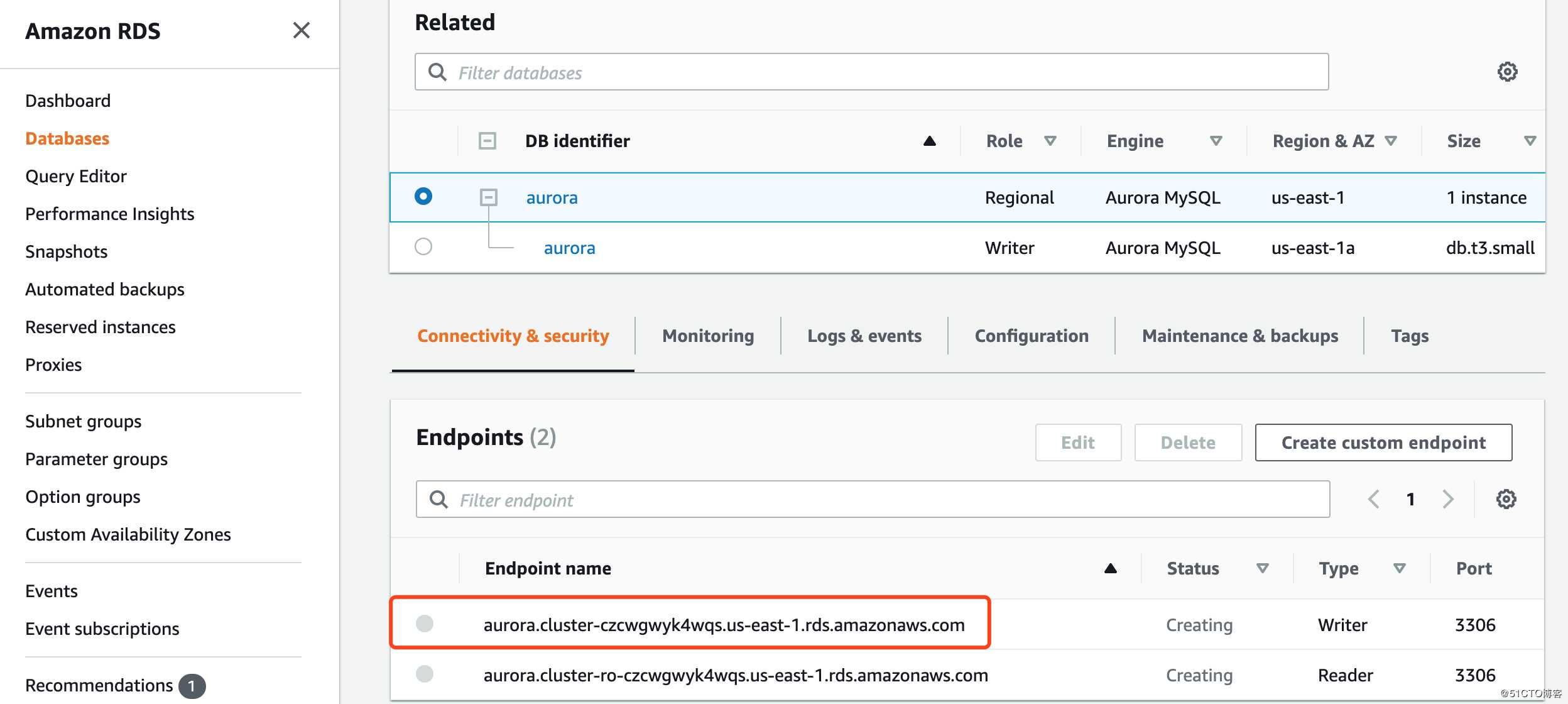
Mysql endpoint:
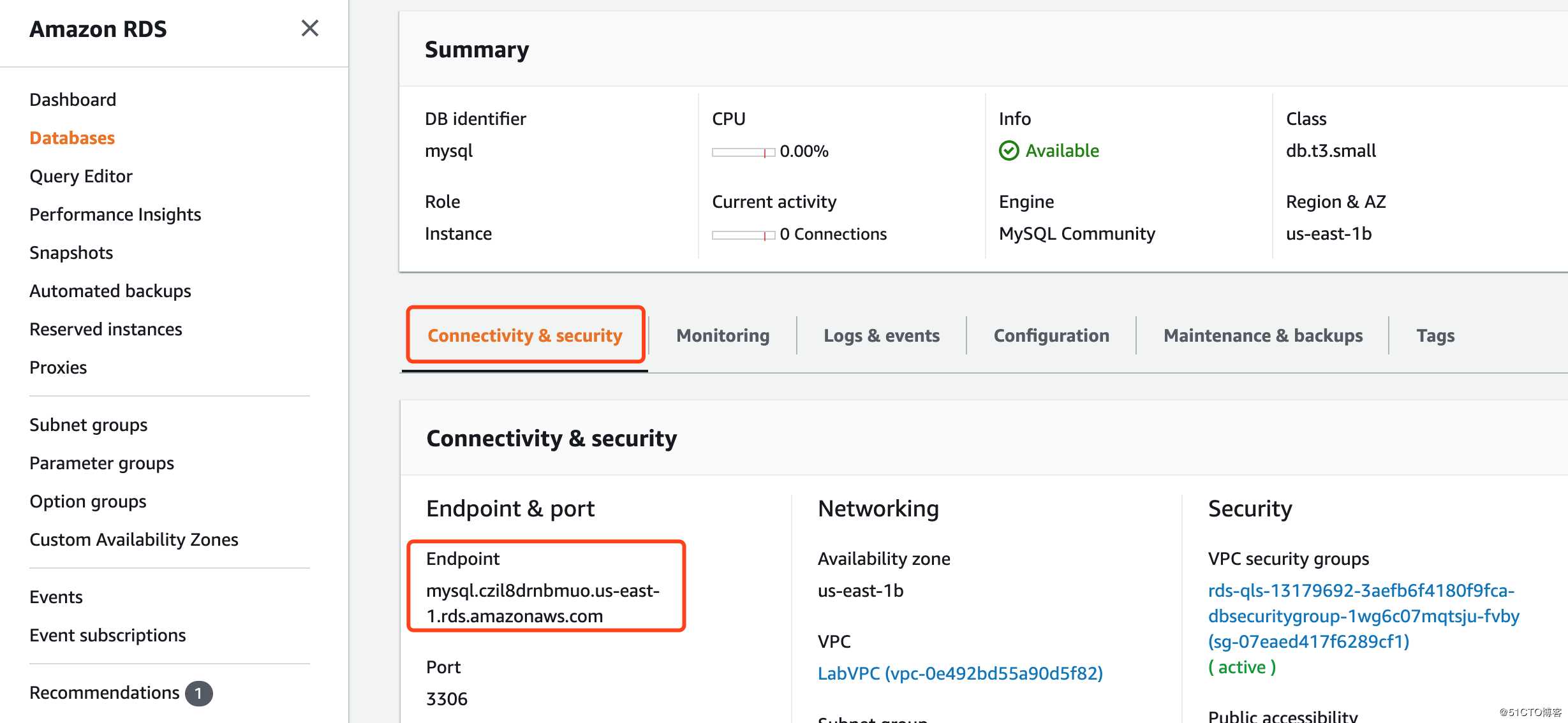
登录跳板机,连接Aurora
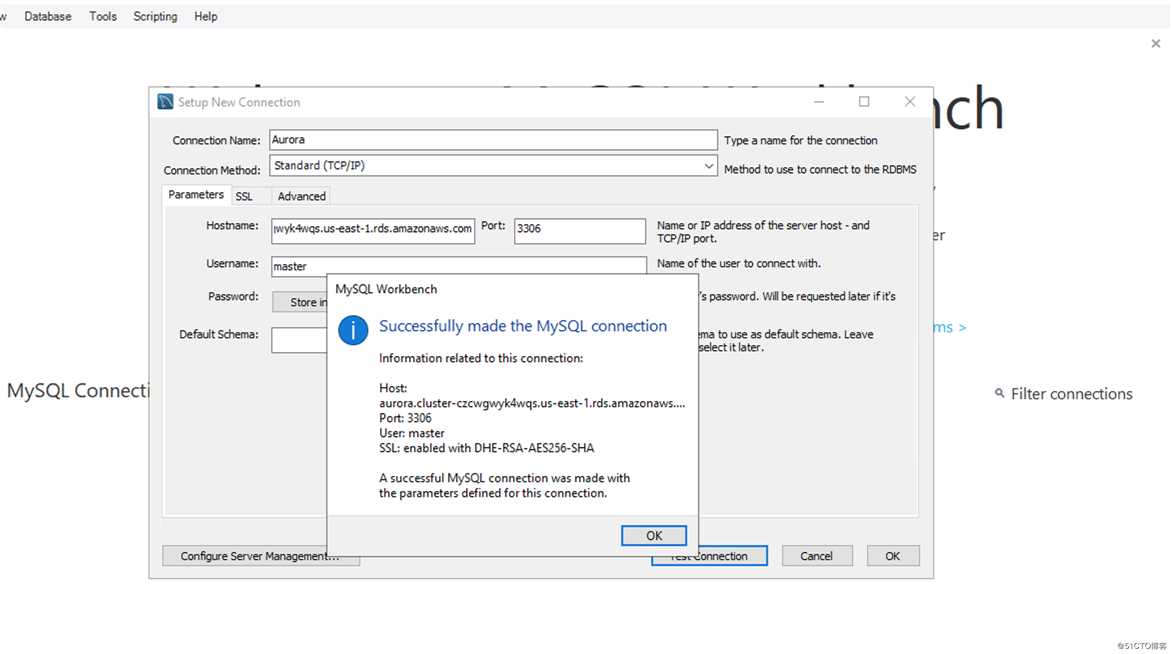
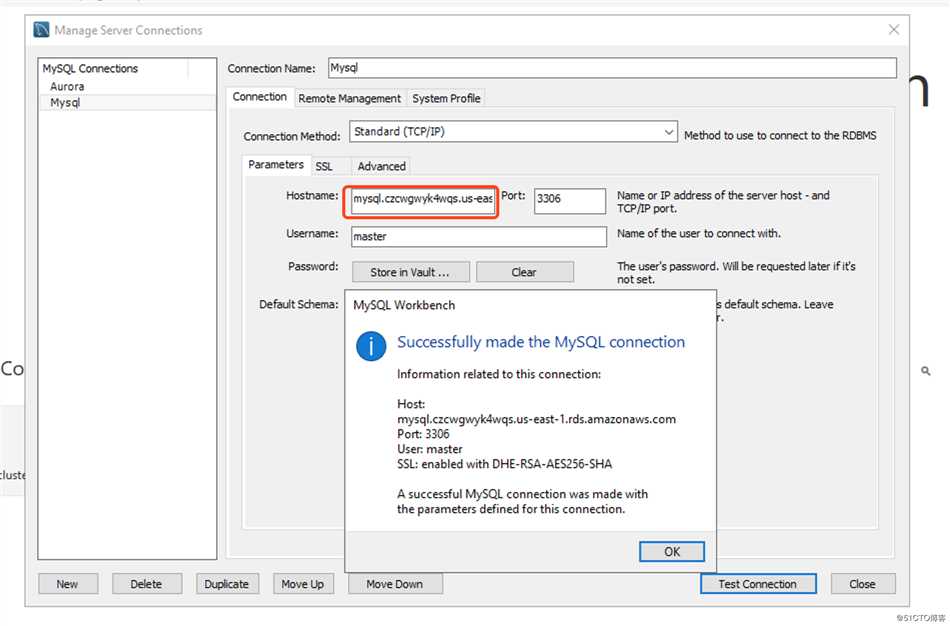
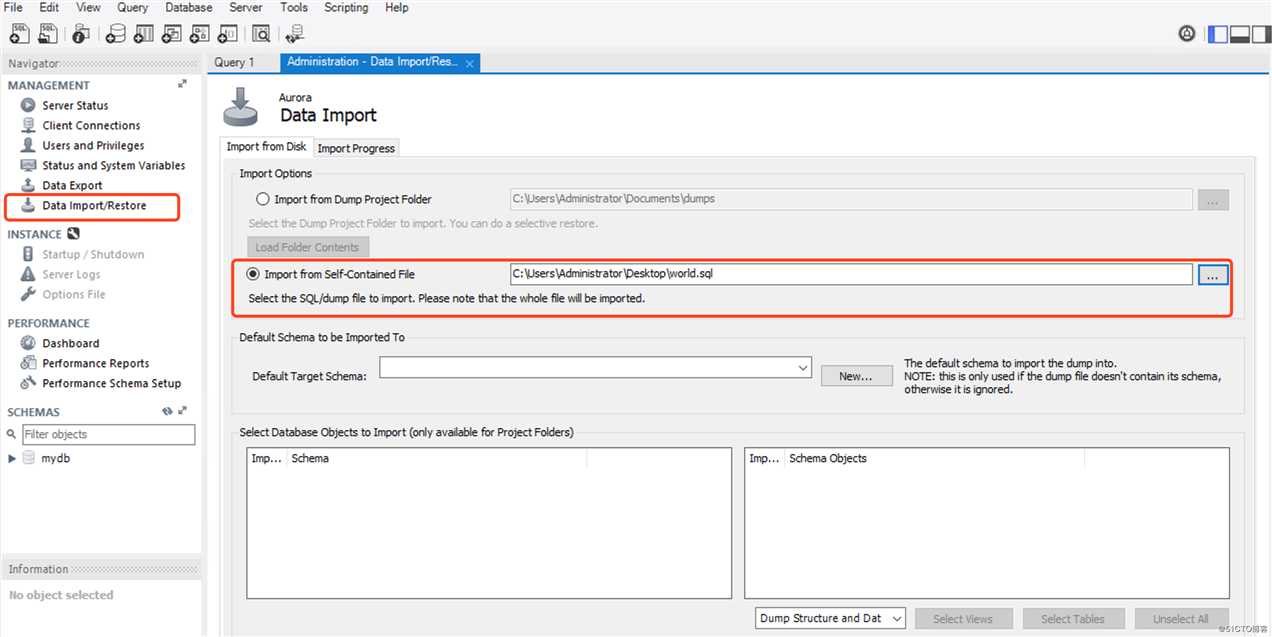
Task4:导入SQL Dump文件到数据库中。
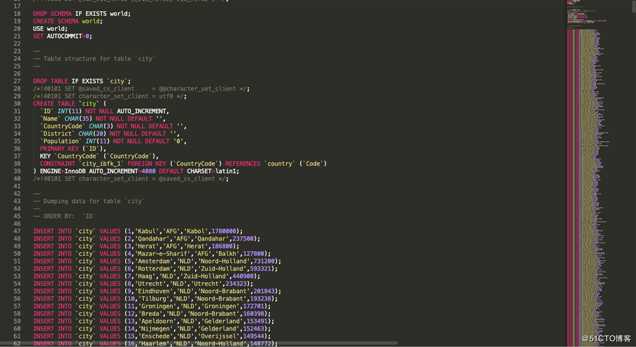
不熟悉SQL dump的同学,这个文件大概就是下图的样子,很好理解,定义Schema,然后插入数据。
运行Powershell,下载dump file到桌面
导入数据:
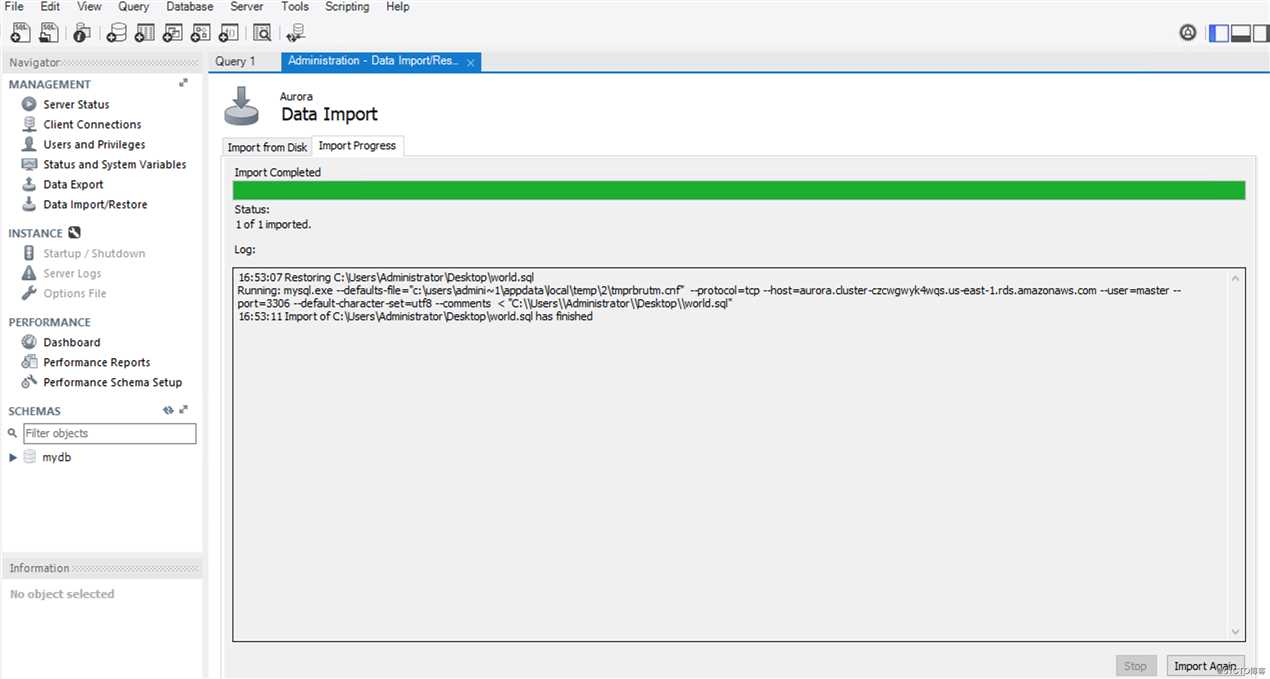
同样,Mysql再做一遍。不赘述了。
Task5:执行查询:
Aurora执行结果:
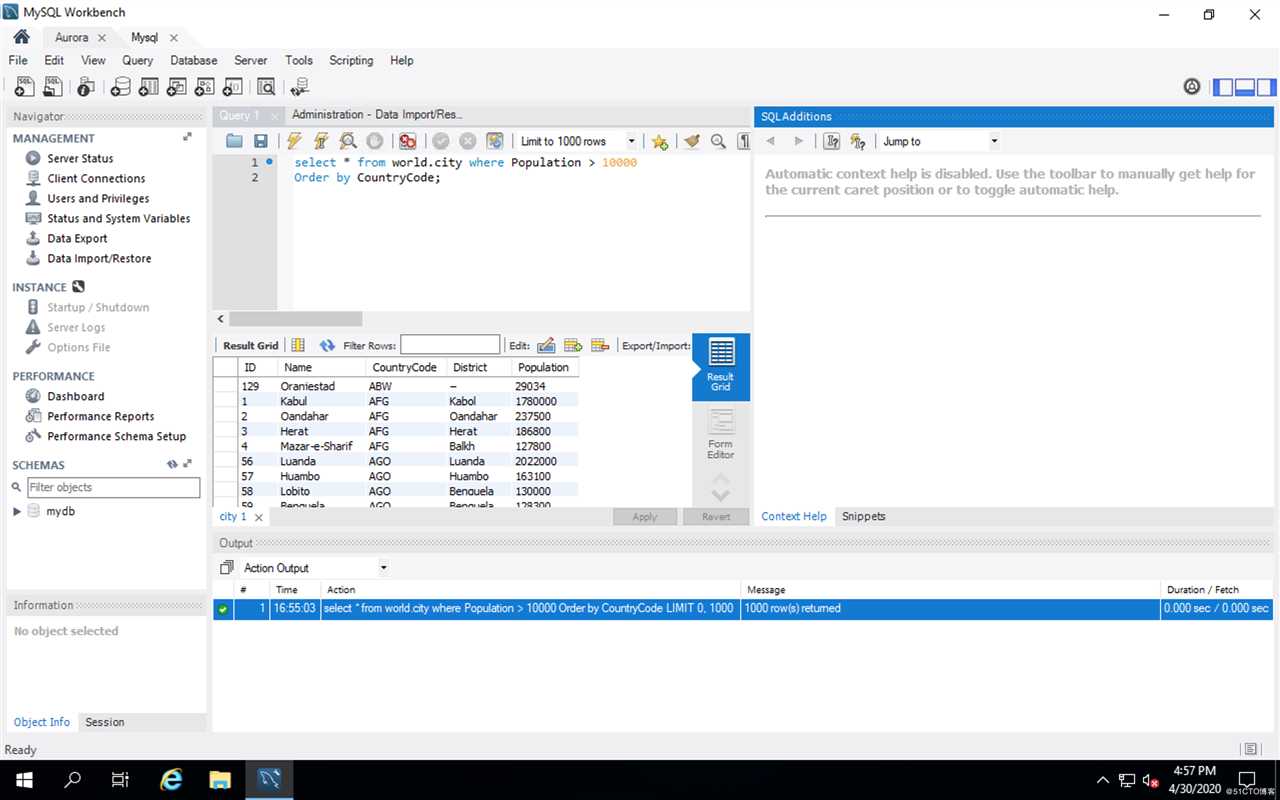
MySQL执行结果:
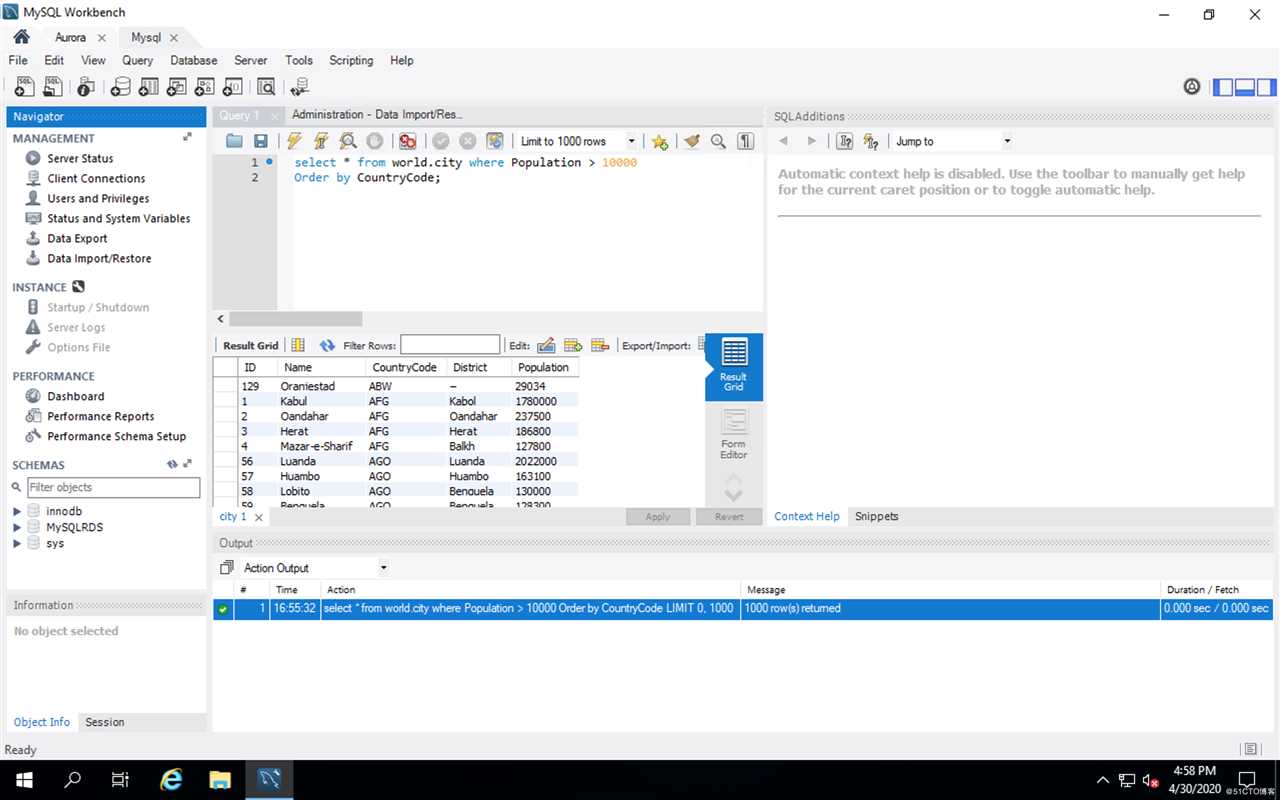
大家看出什么区别了吗?
对,没什么区别,执行速度都很快。为什么?
因为只有1000条数据,在少量数据的情况下,很难比较Aurora和MySQL的执行效率。但百万或千万条数据使用压力测试工具的情况下,它们的TPS和QPS的会有很大差距。
最后附上用压测工具Sysbench的对比结果。(我想起来再补充吧)

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









