







 这篇博客总结了除贝叶斯统计和判别模型外的分类方法,包括近邻法(1近邻和k近邻),决策树(信息熵、信息增益)及其组成的随机森林,以及Boosting方法,强调了这些方法在分类中的应用和重要性。
这篇博客总结了除贝叶斯统计和判别模型外的分类方法,包括近邻法(1近邻和k近邻),决策树(信息熵、信息增益)及其组成的随机森林,以及Boosting方法,强调了这些方法在分类中的应用和重要性。
介绍除了贝叶斯统计和判别模型的两类方法外的其他分类方法:
• 1、近邻法
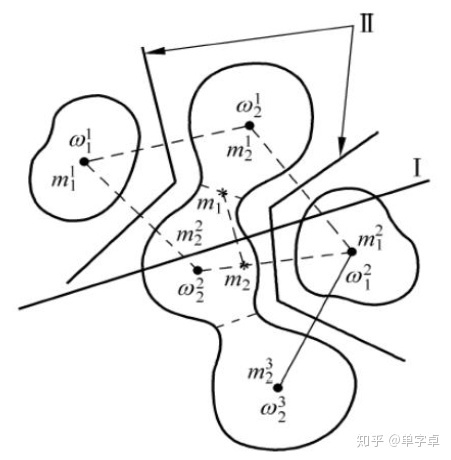
直接根据训练样本对新样本进行分类,是一种最简单的分段线性分类器:把各类划分为若干子类,以子类中心作为类别代表点, 考查新样本到各代表点的距离并将它分到最近的代表点所代表的类。
决策规则:
已知样本集S = { , , = 1, ⋯ , } ,设有 个类别即 ∈{1, 2, ⋯ , } 。 定义样本之间的距离 , =∥ - ∥。 对未知样本 , 其与 的距离为
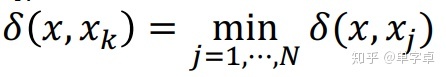
则 ∈ 或 类,针对不同的应用, 距离 (⋅,⋅)有不同的定义。
k近邻法作为最近邻法(1近邻法) 的推广: 找出 的 个近邻, 看其中多数属于哪一类, 则把 分到哪一类。 近邻分类器中的 是一个重要参数, 当 取不同值时, 分类结果会有显著不同。 另一方面, 若采用不同的距离计算方式, 则找出的“近邻” 可能有显著差别, 从而也会导致分类结果有显著不同,k近邻(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2061
2061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









