






缓存简介
众所皆知,缓存在计算机技术中应用地十分广泛。如CPU->L1/L2/L3->内存->磁盘就是个典型例子。那些频繁访问的数据、热点数据、IO耗时长的数据都可以放在缓存中,应用程序先从缓存中读取,如果没有名字,再从真实数据源读取,并放置在缓存中。缓存对于支撑高并发系统,起到了非常关键的作用。
缓存命中率
缓存命中率 = 从缓存中成功读取的次数/总读取次数(从缓存读次数 + 从真实数据源读次数)。这是一个非常重要的监控指标,它可以帮助我们查看缓存是否工作合理且良好,如果缓存命中率很低,那么我们应该重新审视,是否哪里出了问题?这类数据是否应该放在缓存中?
缓存回收策略
1.基于空间
基于空间指的是缓存设置了存储空间大小,如20MB,当缓存数据达到设置的空间上限时,则按照策略淘汰数据。
2.基于容量
基于容量指的是缓存设置了数量条目限制。当缓存的条目超过数量上限时,则按照策略淘汰数据。
3.基于时间
基于时间分为两类:
TTL(Time To Live):缓存的存活时间,当缓存数据被放入存活到一定时间段时,会自动到期移除。
TTI(Time To Idle):缓存的空闲期,即缓存经过一定时间没有被访问,就会自动被移除。
4.基于Java引用
这里主要指的是软引用和弱引用。
软引用:当JVM在垃圾回收时,如果内存不足,则会回收软引用指向的对象内存空间。
弱引用:当JVM在垃圾回收时,发现了弱引用,则会回收弱引用指向的对象内存空间。相比软引用,它不会判断内存是否够用,都会回收空间。
5.基于算法
常见的缓存淘汰算法有如下:
FIFO:先进先出算法。即最先放入的数据最先被淘汰。
LRU:最近最少被使用算法。上次使用时间距离现在最久的那个数据被淘汰。
LFU:最不常用算法。即一定时间段内使用次数(频率)最少的那个被淘汰。
Java缓存类型
堆内缓存:主要指软引用和弱引用缓存的对象,开源的Guava Cache有相关实现。
堆外缓存:顾名思议,不依赖Java堆空间,只受限本机内存大小。EhCache有相关实现。
磁盘缓存:缓存数据存放在磁盘上,相比放在内存中,磁盘缓存即使断电数据也可恢复。EhCache有相关实现。
分布式缓存:上面的缓存一般指的是进程内缓存,但分布式系统中,往往需要共享缓存数据,如使用高性能的Redis分布式缓存。
缓存使用模式
Cache-Aside
业务代码围绕着Cache写,由业务代码来维护缓存数据。工作原理就是常见的先从缓存读取,命中则返回;未命中回源到SoR读取,并写入缓存。
Cache-as-SoR
SoR(system-of-record):即真正存储数据的数据源,如mysql数据库等。
Cache-as-SoR是把Cache当做SoR,所有操作都是针对Cache进行,如果缓存未命中,则交给Cache组件去回源,而不是业务代码做回源的操作。有三种相关的实现:Read-Through、Write-Through、Write-Behind。
Read-Through
即业务代码调用Cache,如果命中则返回,未命中则由Cache组件去从数据源加载数据,通常配置一个CacheLoader去做这个回源的操作。
Write-Through
也称为穿透写/直写模式,业务代码首先调用Cache写操作的API,然后由Cache负责写数据库和写缓存,而不是业务代码。通常需要配置一个CacheLoaderWriter来做这个操作。
Write-Behind
也称为Write-Back,即回写模式。与Write-Through不同的是,这里的写SoR和写Cache是异步的,而不是同步。此外,Write-Behind还支持批量写。
Copy Pattern
有两种模式:Copy-On-Read和Write-On-Read。与CopyOnWriteArrayList思想类似,写操作时先复制一份源数据,然后在复制的数据上做写操作,避免多线程环境下的并发修改问题。
多级缓存
所谓多级缓存,是指在整个系统架构的不同层级都可以进行数据缓存,以提升系统的高并发需求。整体架构图如下:
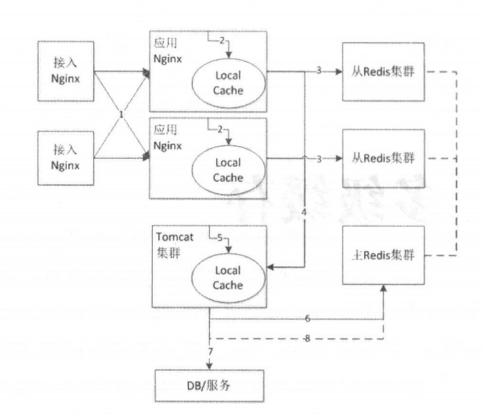
1.接入nginx将请求负载均衡到应用nginx;
2.应用nginx先从local cache读取数据,未命中则从分布式缓存redis读取;
3.分布式集群未命中则从后端Tomcat集群读取;
4.Tomcat集群先从local cache读取,未命中可再尝试从分布式缓存redis读取;这步从redis再次尝试读取是可选的。
5.以上缓存皆未命中,则回源到DB读取,并将数据异步写入到redis集群。
缓存数据一致性
1.如果可以订阅数据库的binlog,那么就订阅变更消息然后进行缓存更新。
2.如果无法订阅消息或者订阅的成本过高,并且业务场景对数据一致性的要求不是很严格,如商品详情页看到的库存,可以短暂的不一致,只要保证下单时一致即可。那么这种场景可以设置合理的过期时间,过期后再查询新的数据。
3.如果是秒杀之类的,可以订阅活动开启消息,提前将数据推送到前端应用,并将负载均衡机制降级为轮询。
更新缓存的原子性
1.更新数据时可采用乐观锁思想,即更新时比对版本号,如果版本号与预期的一致,则成功更新,否则失败或重试。如果使用的Redis,则可以利用Redis的单线程机制进行原子化更新。
2.悲观锁,在更新之前获取相关的分布式锁。
3.使用数据订阅同步中间件,如canal去订阅数据库的binlog,并同步缓存数据。
缓存崩溃与数据恢复
1.取模

2.一致性哈希

3.快速恢复

如果整个缓存集群坏了,并且没有备份,那么只能慢慢重建缓存数据。为了让部分用户还是可用的,可以根据系统承受能力,通过降级方案让一部分用户先用起来,将这些用户相关的缓存数据重建。另外,通过后台Worker进行缓存数据的预热。
参考资料:
《亿级流量网站架构核心技术》















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









