






我曾经工作过的公司所生产的产品对于小的颗粒物(业界称为FM,foreign material)具有高度敏感性,因此消灭生产环境中的FM成了公司的一个重要的活动。五个关键部门都成立了专门的小组来定期检查并统计相关发现,并推动相关部门改善。
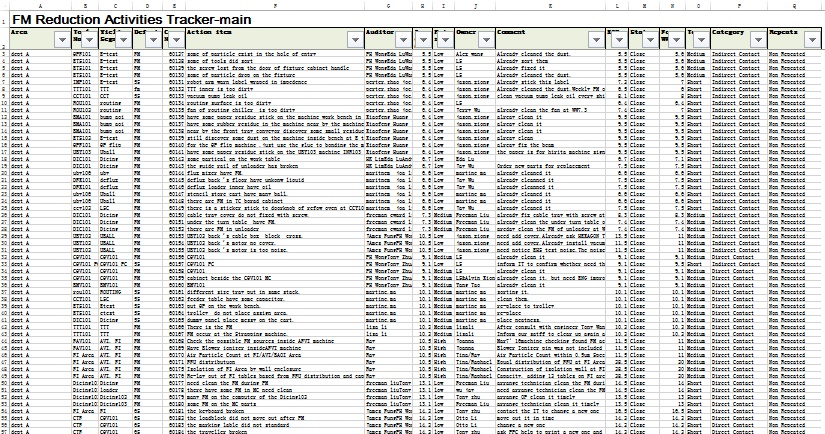
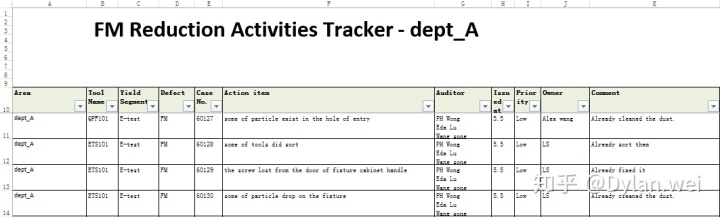
我负责搜集每个部门的数据及改善情况,每周向管理层汇报。为了我汇总数据方便(内心想法是:我可以偷一把懒),我最初是将一个表放在公共盘,让五个部门去里面填写。很快就乱成了一锅粥。首先,不同部门可能同时去填写,则会有冲突,需要“排队”;其次,常出现这个部门把另一个部门的数据覆盖了。为了让每个部门专注于填写自己的数据,我只得妥协,为每个部门单独建立了搜集这些数据的文件夹,并放置了统一格式的Excel文件,以便他们填写。每周五,我会去到他们的文件夹去复制这些数据粘贴到我的汇总表。每次粘贴加上校对,至少要花费1个小时时间,又繁重又无聊。文件夹及文件内的大致信息如下。

为了将自己从这种重复的工作中解放出来,我去网络搜索Excel自动化办公,认识了Python,从此走上了自动化办公的不归路(没有谁想回头啦☺)。下面就祭出Python这一神器,分分钟且精准地完成数据汇总。然后刷新Excel中的数据,事先设定好的数据透视图就可以自动更新到最新,然后贴到PPT上就可以发出报告了。
代码走起......
import os #用于获取文件路径
import xlrd #用于一次读取Excel中的整行数据
from openpyxl import load_workbook #用于写入数据
file_path="data" # 文件所在文件夹
#1.获取路径下所有文件,并存入列表
pathss=[] # 存储文件夹内所有文件的路径(包括子目录内的文件)
for root, dirs, files in os.walk(file_path):
path = [os.path.join(root, name) for name in files]
pathss.extend(path)
#2.只提取出需要的Excel文件的路径
files_for_merge=[]
for i in pathss:
if 'Tracker-sub' in i: #因文件夹内还有存储图片的Excel文件,需排除
files_for_merge.append(i)
#3.读取各个Excel中的数据,并存入列表
data=[]
for i in files_for_merge:
wb=xlrd.open_workbook(i) #按相应路径读取工作簿
ws=wb.sheet_by_index(0) #选取工作表
for j in range(10,ws.nrows):
data.append(ws.row_values(j)) #读取整行数据,并存入列表
#4.汇总数据到主Excel文件
wb_main=load_workbook(file_path+"/FM Reduction Activities Tracker-main.xlsx") #打开需要写入数据的文件
ws_main=wb_main['Raw Findings'] #选取需要写入数据的工作表
for row in range(3,len(data)+3):
for col in range(1,18):
ws_main.cell(row=row,column=col,value=data[row-3][col-1]) #写入数据
wb_main.save(file_path+"/FM Reduction Activities Tracker-main.xlsx") #保存数据
print("程序执行完成!") 这里用到3个第三方库,os、xlrd和openpyxl。有人造好了轮子,就不用自己死命折腾了, 先用为敬!其实学一门编程语言最重要的作用就是能用,能解决问题。至于那些库的内部构造就无需深入了解了,如同你在用智能手机的时候不需要去了解它内部构造及每一个技术细节,如果是那样,终其一生估计都难以掌握透彻。
因为我们的5个子文件是放在5个不同的文件夹下的,因此需要使用os库去获取这些文件的路径,以便后续逐个读取其中的数据。xlrd库带有读取Excel整行的函数,使用起来很方便。openpyxl虽然也可以读取数据,但需要去遍历每个单元格,相对来说不如xlrd的整行读取方便。
在获取文件路径之前,需要先告诉程序我们应该获取哪个文件夹下的数据。我们这里是将文件存在"data"路径下的,因此file_path="data"。其实其绝对路径是'C:Usersdyweipythonpython_excelExp2.merge_excelsdata',可通过os.getcwd()获得当前工作路径。由于程序会默认路径为当前工作路径,它会自动去找当前路径下是否有"data"文件夹,因此file_path="data"与file_path="C:Usersdyweipythonpython_excelExp2.merge_excelsdata"是一样的。为了简洁,直接file_path="data"即可。
In [16]:
os.getcwd()
Out[16]:
'C:Usersdyweipythonpython_excelExp2.merge_excels'然后我们要获取"data"文件夹下的所有子文件夹里的Excel文件名及路径,通过os.walk可实现。os.walk可遍历一个目录内各个子目录和子文件。它先遍历当前目录,返回三个值,分别是目录的路径,目录下子目录的名字,文件的名字。再遍历子目录,同样返回子目录的路径,子目录下的子目录的名字,子目录内的文件的名字。若还有子目录,则继续遍历,直到所有目录被遍历。因此需要三个变量root, dirs, files去接收它的返回值。由于path本身是一个列表,需要将每次采集到的文件汇总到一个列表中去,我们使用extend来完成。extend的功能可通过如下示例理解。
a=[1,2]
b=[3,4]
a.extend(b)
a
>>[1, 2, 3, 4]
In [17]:
path
Out[17]:
['datadept_EFM Reduction Activities image- E.xlsx',
'datadept_EFM Reduction Activities Tracker-sub E.xlsx']
In [18]:
pathss
Out[18]:
['dataFM Reduction Activities Tracker-main.xlsx',
'datadept_AFM Reduction Activities image- A.xlsx',
'datadept_AFM Reduction Activities Tracker-sub A.xlsx',
'datadept_BFM Reduction Activities image- B.xlsx',
'datadept_BFM Reduction Activities Tracker-sub B.xlsx',
'datadept_CFM Reduction Activities image- C.xlsx',
'datadept_CFM Reduction Activities Tracker-sub C.xlsx',
'datadept_DFM Reduction Activities image- D.xlsx',
'datadept_DFM Reduction Activities Tracker-sub D.xlsx',
'datadept_EFM Reduction Activities image- E.xlsx',
'datadept_EFM Reduction Activities Tracker-sub E.xlsx']pathss列表里面包含"data"文件夹下的所有Excel文件,但我们只需要读取文件名为“FM Reduction Activities Tracker-sub”里的数据,因此需要进行一次筛选。我们定义一个空列表files_for_merge用于装筛选后的文件名,设定条件为文件名需要包含“Tracker-sub”字符串。files_for_merge列表的结果如下,正是我们需要的文件。
In [19]:
files_for_merge
Out[19]:
['datadept_AFM Reduction Activities Tracker-sub A.xlsx',
'datadept_BFM Reduction Activities Tracker-sub B.xlsx',
'datadept_CFM Reduction Activities Tracker-sub C.xlsx',
'datadept_DFM Reduction Activities Tracker-sub D.xlsx',
'datadept_EFM Reduction Activities Tracker-sub E.xlsx'] 文件锁定之后,我们就可以开始读取其中的数据了。我们建立了一个data列表来储存这些数据。然后逐个向xlrd.open_workbook()中传入文件名及路径,打开并获取其中第一个工作表wb.sheet_by_index(0),然后使用ws.row_values()函数按行读取其中的数据。因为工作表里的数据是从第11行开始的,所以此处range(10,ws.nrows)以10开头(由于行是以0开始的,0代表真实的第一行,所以此处10代表第11行)。我们可以看到ws.row_values(9)是工作表里的第10行,即标题行。忍不住顺便提一句,Jupyter notebook的好处就在这里,有任何疑问,可以马上运行检查,而使用集成开发环境(IED如pycharm)或者写程序到py文件再执行,就远远没有这么方便。ws.nrows函数可以自动获得excel表中的最大行。
ws.row_values(9)
>>
['Area',
'Tool Name',
'Yield Segment',
'Defect',
'Case No.',
'Action item',
'Auditor',
'Issued at',
'Priority',
'Owner',
'Comment',
'ECD',
'Status',
'Focus WW',
'Term',
'Category',
'Repeats'] 然后我们可以看看我们获取到的数据data。通过len(data)可看到其中有多少条数据,此处有4532条,正是5个工作表里的数据之和。我们也可以看一下data里的第一个数据长什么样子,通过data[0]可以看到。请注意列表的索引是从0开始的,data[0]是指data列表里的第一条数据。
len(data)
>>
4532
data[0]
>>
['dept_A',
'QPF101',
'E-test',
'FM',
60127.0,
'some of particle exist in the hole of entry',
'PH WongnEda LunWang song',
5.5,
'Low',
'Alex wang',
'Already cleaned the dust.',
5.5,
'Close',
5.6,
'Medium',
'Indirect Contact',
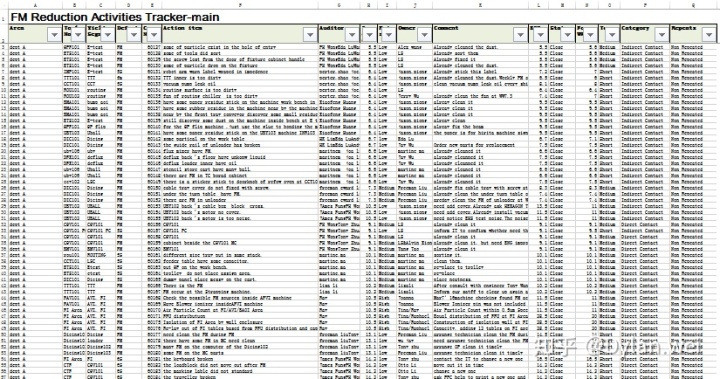
'Non Repeated'] 数据拿到手之后,就可以汇总数据到主文件“FM Reduction Activities Tracker-main.xlsx”了。我们希望每次都将数据写入到固定的一个Excel文件里,因为这个文件里会事先建立好透视表和透视图,等数据写入后,只需要刷新数据,就可以马上看到更新后的图表,实现自动化,以节省我们的宝贵时间,且提升工作效率。所以我们传入文件的路径和文件名到函数load_workbook(),打开工作簿,然后选取需要写入的工作表wb_main['Raw Findings'],然后就可以通过两个for循环分别控制表中的“行”和“列”,将列表data中的数据逐个写入。因为主文件中的数据是从第3行开始的,所以range(3,len(data)+3)里面起止都要加3。最后保存数据wb_main.save(),因不用另存数据,所以文件名还是“FM Reduction Activities Tracker-main.xlsx”。最后得到的总表就是这样:
所有源代码和说明都在Jupyter notebook上完成,所用到的Excel 资料已上传GitHub, 欢迎Fork或下载到本地随意玩。。。转载请注明出处,谢谢。GitHub链接:https://github.com/weidylan/Office_Automation_by_Using_Python微信公众号:Python操作EXCEL高效率工作
















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









