









本博客主要是积攒日常所编写的一些关于txt的脚本文件,以便于以后遇到相关数据,可以加快事件处理。
目录
2.python提取批量txt文件中的一列保存到一个新的txt文件
4.python读取文件夹下的批量txt文件的所有内容并保存为一个新的txt文件
5.按照选定内容,读取csv/txt文件里的内容,写入新的txt文件
1.python删除txt文件中重复的值
def remove_duplicates():
f_read=open('./newFile.txt','r',encoding='utf-8') #将需要去除重复值的txt文本重命名text.txt
f_write=open('./test.txt','w',encoding='utf-8') #去除重复值之后,生成新的txt文本 后的文本.txt”
data=set()
for a in [a.strip('\n') for a in list(f_read)]:
if a not in data:
f_write.write(a+'\n')
data.add(a)
f_read.close()
f_write.close()
remove_duplicates()
print('Done')示例:
原文件如图:有相同内容,且txt文件只有一列
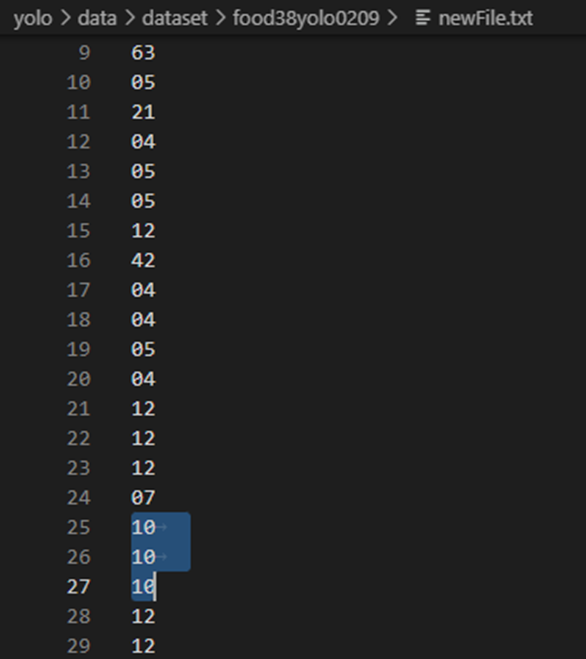
删除后,这列没有重复一样的数字

2.python提取批量txt文件中的一列保存到一个新的txt文件
代码解释:展平文件夹内的所有txt文件,读取文件想要的部分并写入新文件
import glob
files = glob.glob("/workspace/yolo/data/dataset/labels0208/*.txt") #dir表示文件所在的目录,代码意思为获取该目录下所有以txt作为后缀的文件
newFile = open("newFile.txt",'w') #新建文件,默认在你运行的目录下生成
for file in files:
with open(file,'r') as FA:
for line in FA:
line = line.strip().split(" ") #默认你文件里的分割符为\t,其他的话可以替换。
newFile.write(line[0]+'\t' +'\n') #填写文件的第1列信息
#newFile.write(line[0]+'\t'+ file +'\n') #填写文件的第1列信息,和文件名称
newFile.close()示例:
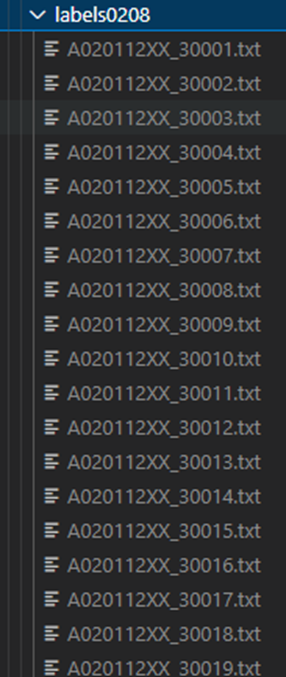
运行后的生成文件内容

3.python对文件夹下的批量txt文件进行重命名
只改变文件名称,txt后缀名不变
文件格式
方法一:
#批量修改文件名
#批量修改图片文件名
import os
import re
import sys
def renameall():
fileList = os.listdir(r"C:\Users\Administrator\Desktop\stars") #待修改文件夹
print("修改前:"+str(fileList)) #输出文件夹中包含的文件
currentpath = os.getcwd() #得到进程当前工作目录
os.chdir(r"C:\Users\Administrator\Desktop\stars") #将当前工作目录修改为待修改文件夹的位置
num=1 #名称变量
for fileName in fileList: #遍历文件夹中所有文件
pat=".+\.(jpg|png|gif)" #匹配文件名正则表达式
pattern = re.findall(pat,fileName) #进行匹配
os.rename(fileName,(str(num)+'.'+pattern[0])) #文件重新命名
num = num+1 #改变编号,继续下一项
print("---------------------------------------------------")
os.chdir(currentpath) #改回程序运行前的工作目录
sys.stdin.flush() #刷新
print("修改后:"+str(os.listdir(r"C:\Users\Administrator\Desktop\stars"))) #输出修改后文件夹中包含的文件
renameall()方法二
import os
path_in = "/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs" # 待批量重命名的文件夹
class_name = ".wav" # 重命名后的文件名后缀
file_in = os.listdir(path_in) # 返回文件夹包含的所有文件名
num_file_in = len(file_in) # 获取文件数目
for i in range(0, num_file_in):
t = str(i + 1)
new_name = os.rename(path_in + "/" + file_in[i], path_in + "/" +t+ class_name) # 重命名文件名
file_out = os.listdir(path_in)
print(file_out) # 输出修改后的结果`
结果

4.python读取文件夹下的批量txt文件的所有内容并保存为一个新的txt文件
数据如下
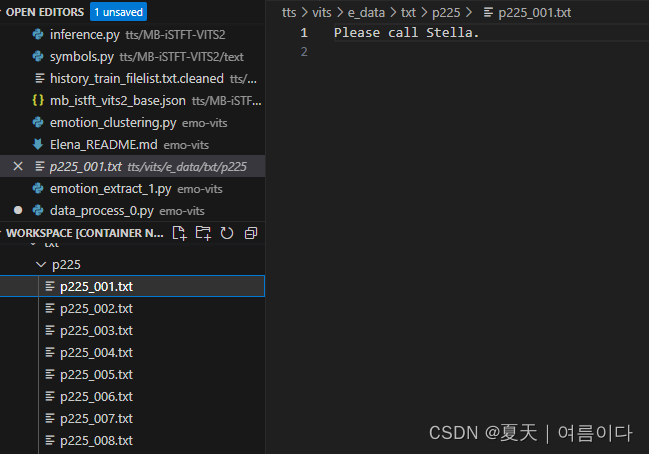
代码
#
import glob
files = glob.glob("/workspace/tts/vits/e_data/txt/p225/*.txt") #dir表示文件所在的目录,代码意思为获取该目录下所有以txt作为后缀的文件
newFile = open("p225.txt",'w') #新建文件,默认在你运行的目录下生成
for file in files:
with open(file,'r') as f:
data = f.read()
#print("data:",data)
newFile.write(file+'|'+ data)
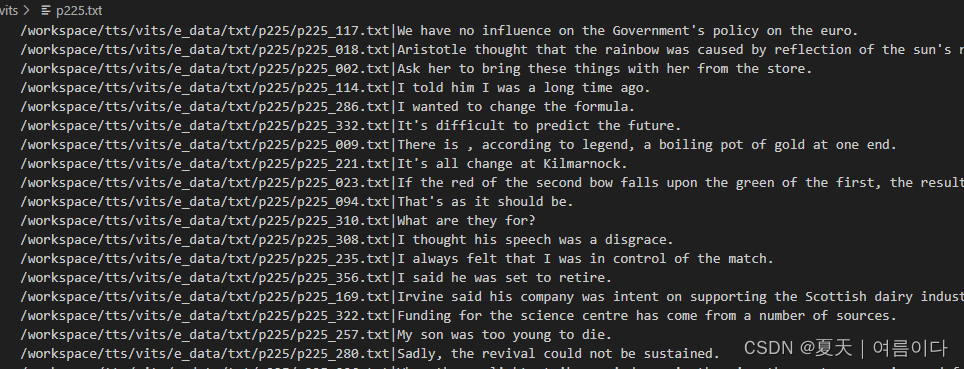
newFile.close()结果
5.按照选定内容,读取csv/txt文件里的内容,写入新的txt文件
原数据类型多列
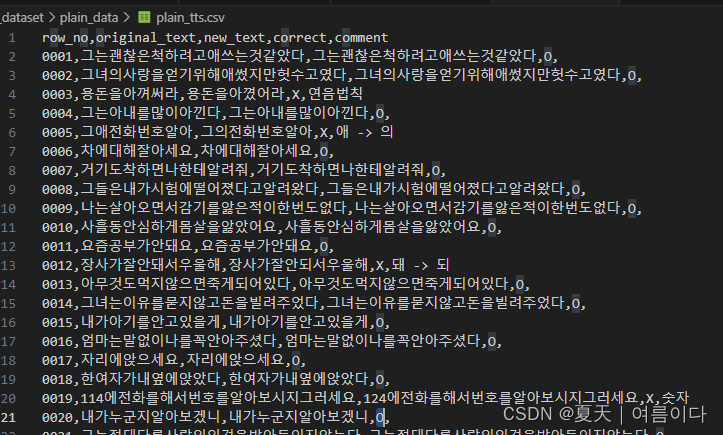
有错误的语句,对于错误的进行筛选:本文是correct等于O是正确的,错误是×的不需要。
代码如下
import pandas as pd
import csv
wav_dir="/workspace/tts_dataset/bae_data/wav/"
new_text_file=open("/workspace/tts_dataset/data-process/new_out.txt",'w')
filename = '/workspace/tts_dataset/bae_data/transcript.csv'
with open(filename, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row)
if row['correct']=='O':
new_text_file.write(wav_dir+ row['row_no']+".wav"+'|'+row["new_text"]+'\n')
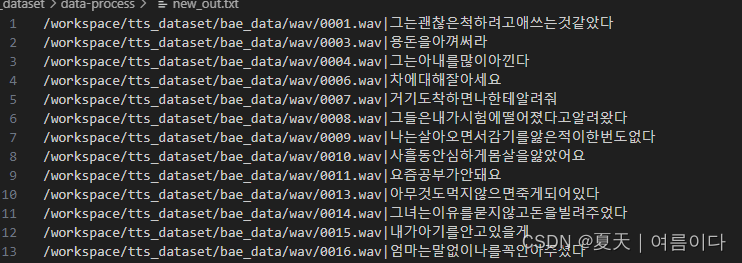
结果:按照自己想要的格式保存文件

















 3630
3630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











