







1. Standalone模式
1.1 概述
使用Standalone需要构建一个完整的Master+Slaves的Spark集群,分布式部署,资源管理和任务监控都是依赖Spark自带架构实现。
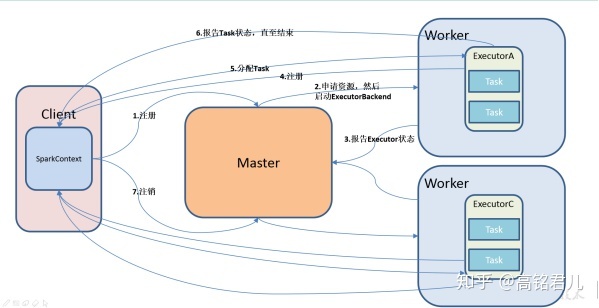
1.2 安装使用
1)进入spark安装目录下的conf文件夹
[centos@hadoop102 module]$ cd spark/conf/2)修改配置文件名称
[centos@hadoop102 conf]$ mv slaves.template slaves
[centos@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh3)修改slave文件,添加work节点
[centos@hadoop102 conf]$ vim slaves
hadoop102
hadoop103
hadoop1044)修改spark-env.sh文件,添加如下配置
[centos@hadoop102 conf]$ vim spark-env.sh
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=70775)分发spark包
[centos@hadoop102 module]$ xsync spark/6)启动
[centos@hadoop102 spark]$ sbin/start-all.sh网页查看: hadoop102:8080
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置
export JAVA_HOME=XXXX2. Yarn模式
2.1 概述
Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster)适用于生产环境。

2.1 安装使用
1)修改hadoop配置文件yarn-site.xml,添加如下内容:
[centos@hadoop102 hadoop]$ vi yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>2)修改spark-env.sh,添加如下配置
[centos@hadoop102 conf]$ vi spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop3)将以下文件分发同步到hadoop103和hadoop104上
1. /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
2. spark-env.sh4)执行一个示例程序
[centos@hadoop102 spark]$ bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master yarn
--deploy-mode client
./examples/jars/spark-examples_2.11-2.1.1.jar
100注意:在提交任务之前需启动HDFS以及YARN集群。
2.2 日志查看
1)修改配置文件spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=180802)重启spark历史服务
[centos@ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2347
2347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









