







原文|https://zhuanlan.zhihu.com/p/104917833
提醒|本文已获得作者授权发布,如需转载请与作者联系。
编辑|猩算法
导读
人体姿势估计是过去几十年来一直受到计算机视觉社区关注的重要问题,这是了解图像和视频中人物的关键步骤。为了能够帮助大家更好的了解人体姿态估计领域,我们精选知乎文章。作者Poeroz对人体姿态估计方法进行整理,文章全面梳理关键技术,并对相关技术进行总结分析。本文总结全面,分析清晰,是一篇值得阅读的干货文章。
本文作者为Poeroz,目前就读于北京邮电大学计算机科学与技术系。
01
前言
上学期搬砖期间做了一些pose estimation相关的工作,但一直没有系统的整理过相关方法。近日疫情当头封闭在家,闲暇之余重温了一下之前看过的论文,对pose estimation的部分经典方法做了一个整理。内容大多为个人对这些方法的理解,所以本文也算是一个论文笔记合集吧。
本文涉及到的工作仅包含个人读过的部分论文,按时间顺序进行了整理,并不能代表pose estimation这一领域完整的发展历程。比如bottom-up中的PersonLab、PifPaf,以及传统top-down/bottom-up方法之外的一些single-stage方法等,都是近年来出现的一些值得研究的工作,由于个人还没有仔细了解过暂时没写,之后可能会继续更新。
本文目录如下:
·top-down
·CPM
·Hourglass
·CPN
·Simple Baselines
·HRNet
·MSPN
·bottom-up
·openpose
·Hourglass+Associative Embedding
·HigherHRNet
在整理过程中,我参照了以下几篇文章的思路,也添加了一些个人的理解。这几篇文章整理的思路都非常清晰,作者的水平也都比我高得多,推荐大家阅读。
https://zhuanlan.zhihu.com/p/85506259
https://zhuanlan.zhihu.com/p/72561165
https://nanonets.com/blog/human-pose-estimation-2d-guide/
正文开始之前还是希望各位带着批判的眼光阅读,毕竟本人目前水平有限,可能有理解不到位或不正确的地方,希望大家批评指正,欢迎大家评论区或私信随时交流。
02
正文
Review of 2D Human Pose Estimation with Deep Learning
人体姿态估计(Human Pose Estimation)是计算机视觉中的一个重要任务,也是计算机理解人类动作、行为必不可少的一步。近年来,使用深度学习进行人体姿态估计的方法陆续被提出,且达到了远超传统方法的表现。在实际求解时,对人体姿态的估计常常转化为对人体关键点的预测问题,即首先预测出人体各个关键点的位置坐标,然后根据先验知识确定关键点之间的空间位置关系,从而得到预测的人体骨架。
姿态估计问题可以分为两大类:2D姿态估计和3D姿态估计。顾名思义,前者是为每个关键点预测一个二维坐(x,y);后者是为每个关键点预测一个三维坐标(x,y,z),增加了一维深度信息。本文主要介绍2D姿态估计。
对于2D姿态估计,当下研究的多为多人姿态估计,即每张图片可能包含多个人。解决该类问题的思路通常有两种:top-down和bottom-up:
·top-down的思路是首先对图片进行目标检测,找出所有的人;然后将人从原图中crop出来,resize后输入到网络中进行姿态估计。换言之,top-down是将多人姿态估计的问题转化为多个单人姿态估计的问题。
·bottom-up的思路是首先找出图片中所有关键点,然后对关键点进行分组,从而得到一个个人。
通常来说,top-down具有更高的精度,而bottom-up具有更快的速度。下面分别对这两种思路的经典算法展开介绍。
Top-down
由上文我们知道,top-down的方法将多人姿态估计转换为单人姿态估计,那么网络的输入就是包含一个人的bounding box,网络预测的是人的 个关键点坐标。对于关键点的ground truth(对应网络的输出)如何表示有两种思路:
· 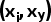 ,
, ,即直接对坐标进行回归,网络的输出是经过fc层输出的2k个数字
,即直接对坐标进行回归,网络的输出是经过fc层输出的2k个数字
·k个heatmap,即为每个关键点预测一个heatmap作为关键点的中间表示,heatmap上的最大值处即对应关键点的坐标。对于改种方法,heatmap的ground truth是以关键点为中心的二维高斯分布(高斯核大小为超参)
早期的工作如DeepPose多为直接回归坐标,当下的工作多数以heatmap作为网络的输出,这种中间表示形式使得回归结果更加精确。接下来我们介绍top-down发展过程中的一些landmark。
需要说明的是,CPM和Hourglass提出时主要面向的是单人姿态估计,因为当时还没有COCO数据集,多使用MPII数据集进行evaluation。但top-down的方法本质上也是在解决单人姿态估计问题,所以将这两个模型放在此处介绍。
CPM
CPM,Convolutional Pose Machines,是2015年CMU的一个工作。这个工作提出了很重要的一点:使用神经网络同时学习图片特征(image features)和空间信息(spatial context),这是处理姿态估计问题必不可少的两样信息。在此之前,我们多使用CNN来提取图片特征,使用graphical model或其他模型来表达各个身体部位在空间上的联系。使用神经网络同时学习这两种信息,不仅效果更好,而且使端到端(end-to-end)学习成为可能。
CPM是一个multi-stage的结构,如下图所示。每个stage的输入是原始图片特征和上一个阶段输出的belief map,这个belief map可以认为是之前的stage学到的spatial context的一个encoding。这样当前stage根据这两种信息继续通过卷积层提取信息,并产生新的belief map,这样经过不断的refinement,最后产生一个较为准确的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









