







为什么使用seq2seq:
1、seq2seq的架构相对于常规的cnn或者rnn处理序列问题的效果在实际的应用中效果更好;
2、seq2seq的框架非常灵活可以支持不定长的输入和输出;
3、seq2seq中的很多技巧可以进一步提升模型的效果,例如attention机制、teacher forcing等;
4、seq2seq考虑了输出的标签之间的序列依赖性,这是常规的RNN或cnn无法做到的,常规的RNN和CNN只能以输出向量的形式解决多步预测问题,这意味着它们无法考虑到输出标签之间的序列依赖性;
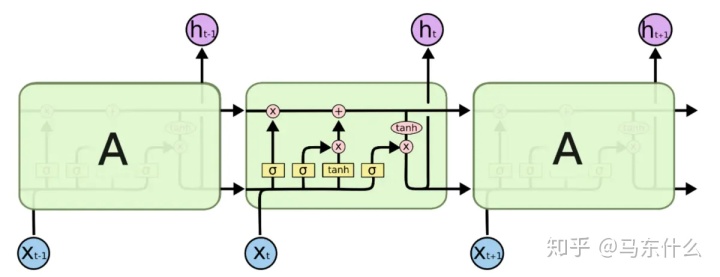
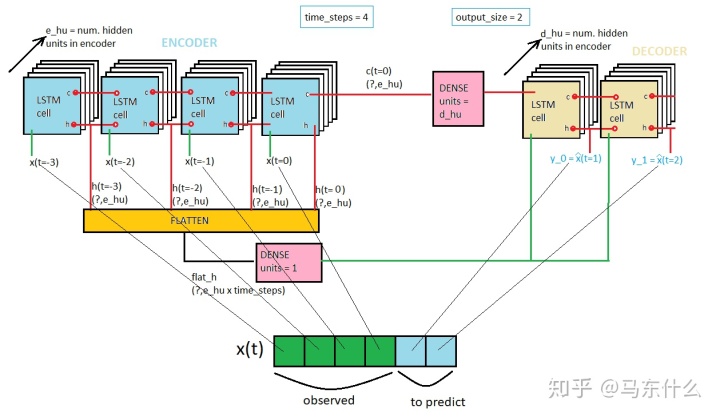
例如常规的LSTM我们要解决n步预测问题,则输出ht一般会接 Dense层,这个dense层的units的数量设置为n,此时实际上就是一个简单的全连接层将hidden state映射为一个n维的向量,从而满足问题的数据的形式,这个时候n维向量输出(即n个待预测的时间步)之间是完全独立,不互相影响的;
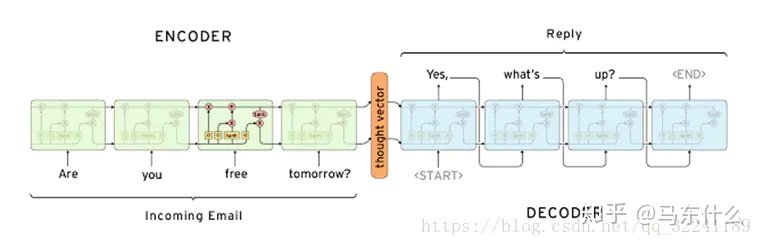
而seq2seq的结构则可以考虑到输出序列之间的序列依赖性;
那么seq2seq为什么可以支持不定长的输入和输出呢?
这一点看似复杂,其实在实现上非常的简单:
from keras.layers import Input, LSTM, Dense
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









