







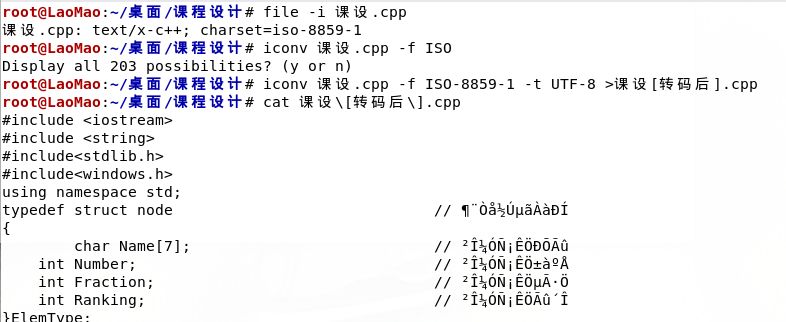
汉字乱码真是一个悲催的事情,JAVA讨厌汉字,PHP也不喜欢汉字;
4)因果图方法:前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等. 考虑输入条件之间的相互组合,可能会产生一些新的情况. 但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多. 因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例. 这就需要利用因果图(逻辑模型). 因果图方法最终生成的就是判定表. 它适合于检查程序输入条件的各种组合情况.。前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等-考虑输入条件之间的相互组合,可能会产生一些新的情况-但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多-因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例-这就需要利用因果图(逻辑模型)-因果图方法最终生成的就是判定表-它适合于检查程序输入条件的各种组合情况.。前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等. 考虑输入条件之间的相互组合,可能会产生一些新的情况. 但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多. 因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例. 这就需要利用因果图(逻辑模型). 因果图方法最终生成的就是判定表. 它适合于检查程序输入条件的各种组合情况.。
gbk(扩展的gb2312):全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 gb2312,加入更多的汉字,它的编码范围是 8140~fefe(去掉 xx7f)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 gb2312 兼容的,也就是说用 gb2312 编码的汉字可以用 gbk 来解码,并且不会有乱码。刚开始使用的时候,出现基站站名是乱码,之所以会显示乱码,是因为mapinfo是gb编码,google earth是utf-8编码,所以中文显示有问题。其实他显示的是日文编码的汉字,要想控上看到汉字,需要现在电脑里用南极星软件进行歌曲名的日文编码重命名iconv 乱码,电脑里显示乱码,输入到md里就可以显示汉字了,比较复杂。
哎,转换吧;
1,PHP自带的转换函数ICONV,一个高大上的函数;
复制代码 代码如下:
string iconv ( string $in_charset , string $out_charset , string $str )
使用DEMO:
复制代码 代码如下:
$text = "This is the Euro symbol '?'.";
echo 'Original : ', $text, PHP_EOL;
echo 'TRANSLIT : ', iconv("UTF-8", "ISO-8859-1//TRANSLIT", $text), PHP_EOL;
iconv.internal_encoding iso-8859-1 iso-8859-1。iconv.input_encoding iso-8859-1 iso-8859-1。iconv.output_encoding iso-8859-1 iso-8859-1。
echo 'Plain : ', iconv("UTF-8", "ISO-8859-1", $text), PHP_EOL;
?>
大家都推荐的函数,不过使用之后无法转换,没有错误,字符也没有转换,NO!
2,另辟蹊径iconv 乱码,还有一个大家质疑效率不高的函数,不过无论如何,先实现再考虑其他三
复制代码 代码如下:
//检查该函数是否可用
echo function_exists('mb_convert_encoding');
//检测当前编码
echo $str2=implode("",array_map(function($val){return ucwords($val)。 //echo "val = $val\n"。echo $val['name'].$val['age'].$val['sex']."
"。
//转换编码,把CP936(就是GBK)转换成UTF-8
$v=mb_convert_encoding ($val, "UTF-8", "CP936");
结果成功了;
好吧,先用着吧,为了转换查询的结果集,制作一个转换函数:
1,函数“乱码克星”:
复制代码 代码如下:
// $fContents 字符串
// $from 字符串的编码
// $to 要转换的编码
function auto_charset($fContents,$from='gbk',$to='utf-8'){
$from = strtoupper($from)=='UTF8'? 'utf-8':$from;
$to = strtoupper($to)=='UTF8'? 'utf-8':$to;
if( strtoupper($from) === strtoupper($to) || empty($fContents) || (is_scalar($fContents) && !is_string($fContents)) ){
//如果编码相同或者非字符串标量则不转换
return $fContents;
}
if(is_string($fContents) ) {
if(function_exists('mb_convert_encoding')){
return mb_convert_encoding ($fContents, $to, $from);

}else{
return $fContents;
}
}
elseif(is_array($fContents)){
foreach ( $fContents as $key => $val ) {
$_key = auto_charset($key,$from,$to);
$fContents[$_key] = auto_charset($val,$from,$to);
if($key != $_key )
unset($fContents[$key]);
}
return $fContents;
}
else{
return $fContents;
}
}
2,使用:
复制代码 代码如下:
//打印输出查询结果(假设你的结果)
$arr=array();
while($list=mssql_fetch_row($row))
{
$arr[]=$list;
}
$s=auto_charset($arr,'gbk','utf-8');
//打印试试,在浏览器设置编码为UFT-8,看没有乱码
print_r($s);die();
以上所述就是本文关于php中文乱码的介绍了,希望大家能够喜欢。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-106590-1.html















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









