






问题是酱紫的:我之前从中国空气质量在线监测分析平台爬取了全国368个城市和地区的日度空气质量数据,每个城市和地区的数据都是单独放在一个csv文件中,这么做有一个很大的弊端就是,想要把空气质量数据和其他数据进行横向合并就比较困难,这很不利于我们后续的数据分析。所以,我们首先可能就需要将这368个csv文件纵向合并为一个文件。
import os all_file_list=os.listdir(r'D:\爬虫下载\日空气质量') all_file_list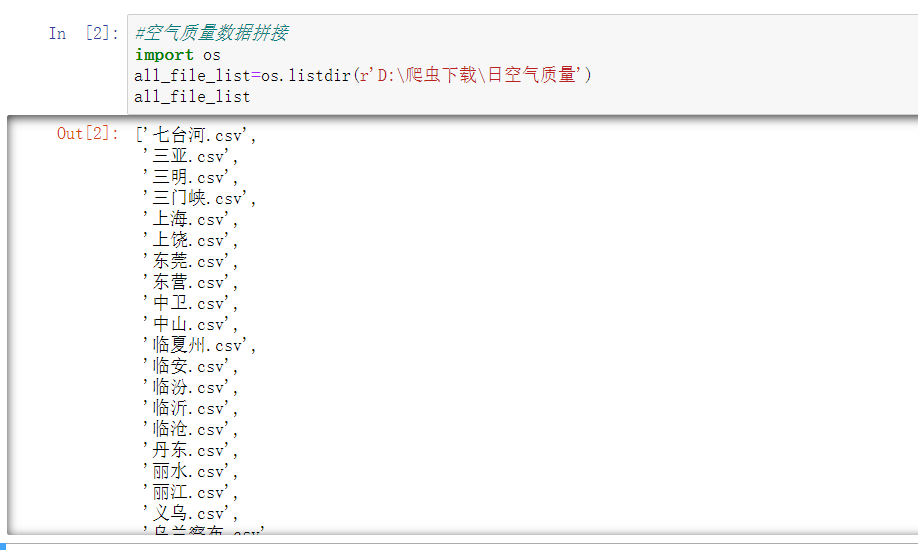 这样,我们就获取到了D盘日空气质量文件夹下所有文件名,接下来,我们就可以对这个文件名列表进行循环遍历,依次读取每一个csv文件,然后进行表格纵向合并。
这样,我们就获取到了D盘日空气质量文件夹下所有文件名,接下来,我们就可以对这个文件名列表进行循环遍历,依次读取每一个csv文件,然后进行表格纵向合并。
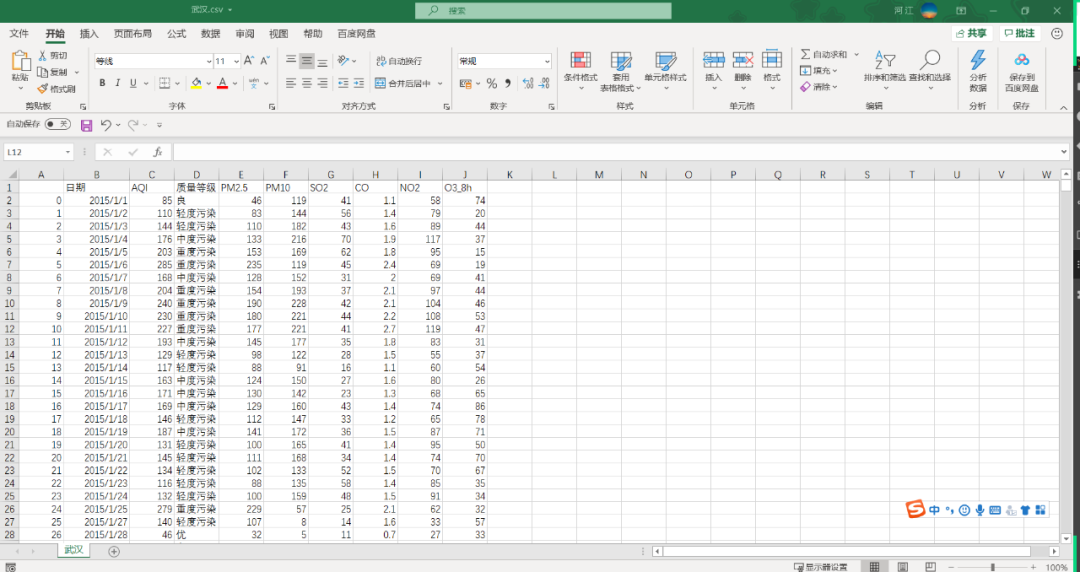
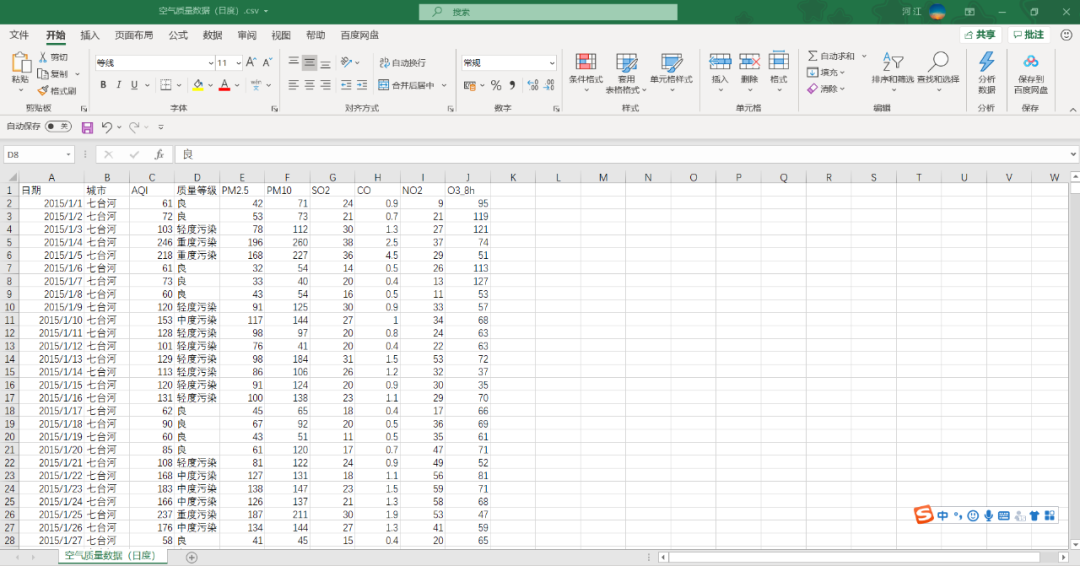
for file in all_file_list: df = pd.read_csv(r'D:\爬虫下载\日空气质量\{}'.format(file),index_col='日期') df.drop(labels='Unnamed: 0',axis=1,inplace=True) city = file.split('.')[0] df.insert(0,'城市',city)#在第零列插入一列,值为城市名称 df.drop(labels='日期',axis=0,inplace=True)#删除索引为日期的行 df.to_csv(r'D:\爬虫下载\日空气质量\空气质量数据(日度).csv', mode='a',encoding='utf_8_sig')df.drop(labels='Unnamed: 0',axis=1,inplace=True)表示删除序号那一列;
city = file.split('.')[0]表示进行字符串分割,这样我们就可以拿到城市名称;
df.insert(0,'城市',city)表示在第1列左边插入一列,值为城市名称;
df.drop(labels='日期',axis=0,inplace=True)表示删除索引为日期的行(没用的行);
df.to_csv是将df写入到一个新的csv文件,mode='a'表示是追加方式。














 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









