







4.预测模型选择的标准
4.1 基本准则
基本的准则有残差平方和以及均方误差(MSE) , 残差平方和定义为:
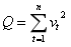
均方误差的定义为:
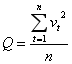
n为样本容量。
如果模型选择以MSE为标准,则容易出现过拟合。
过拟合(over-fitting)也称为过学习,它的直观表现是算法在训练集上表现好,但在测试集上表现不好,泛化性能差。过拟合是在模型参数拟合过程中由于训练数据包含抽样误差,在训练时复杂的模型将抽样误差也进行了拟合导致的。所谓抽样误差,是指抽样得到的样本集和整体数据集之间的偏差。直观来看,引起过拟合的可能原因有:
模型本身过于复杂,以至于拟合了训练样本集中的噪声。此时需要选用更简单的模型,或者对模型进行裁剪。
训练样本太少或者缺乏代表性。此时需要增加样本数,或者增加样本的多样性。
训练样本噪声的干扰,导致模型拟合了这些噪声,这时需要剔除噪声数据或者改用对噪声不敏感的模型。
4.2 对自由度施加惩罚的模型选择标准
4.2.1 自由度修正均方差
这里的自由度是待估计的参数个数, 增加自由度惩罚的均方差定义为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3313
3313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









