







 本文探讨了领域自适应中的分布对齐和目标函数优化,提出VADA和DIRT-T模型。VADA通过最小化条件熵避免决策边界穿过高密度区,而DIRT-T进一步优化决策边界,尤其适用于非保守领域自适应。实验证明,这些方法在手写数字体迁移学习上取得了state-of-the-art的性能。
本文探讨了领域自适应中的分布对齐和目标函数优化,提出VADA和DIRT-T模型。VADA通过最小化条件熵避免决策边界穿过高密度区,而DIRT-T进一步优化决策边界,尤其适用于非保守领域自适应。实验证明,这些方法在手写数字体迁移学习上取得了state-of-the-art的性能。
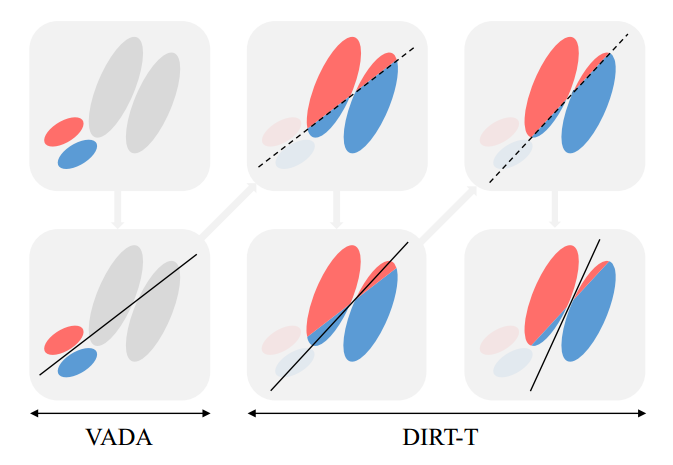
一、动机
领域自适应(domain adaptation)是迁移学习中的一种方法,旨在利用源域中标注好的数据,学习一个精确的模型,运用到无标注或只有少量标注的目标域中。本质上是一种数据增强的方法。
领域自适应最常见的方法是找一个公共特征空间,将源域和目标域数据都映射过去,在该空间进行分布对齐。最近很流行的方法是利用域对抗训练[1],也就是设置一个判别网络,判断特征数据来自于源域还是目标域,特征提取器通过与判别器的对抗实现特征空间的对齐。但是,作者认为域对抗方法有两个关键的限制:
- 特征提取函数如果能力太强的话,特征分布对齐就是一个比较弱的约束。
- 在非保守的领域自适应(也就是没有一个分类器可以同时在源域和目标域中分类的很好),训练模型在源域上执行的太好会损害在目标域上的性能。
本文考虑一个正交假设(orthogonal assumption)即簇假设(cluster assumption):输入分布包含分离的数据簇,相同label的数据会形成一个簇,不同label的数据会属于不同的簇。这样的话,决策边界就不能穿过数据高密度的区域,因为一旦穿过,就意味着将相同label的数据分成了不同类。
作者提出两个相关模型分别解决以上两个问题:
- 虚拟对抗领域自适应模型(VADA),结合领域对抗自适应和一个惩罚项,将决策边界推离数据密度高的地方。
- 拥有教师的决策边界迭代细化训练模型(DIRT-T),让分类更专注于目标域。
在保守领域自适应中,VADA就可以工作的很好;在非保守领域自适应中,DIRT-T会帮助VADA工作。
二、模型
领域对抗训练介绍
考虑一个分类函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









