 迁移学习在金融风控中的应用
迁移学习在金融风控中的应用




 本文探讨了迁移学习在金融风控领域的应用,主要任务是缩小源域和目标域之间的分布差异。介绍了几种常见的迁移学习方法,如模型再优化、层迁移、域对抗迁移和零样本学习。特别关注了基于实例的迁移学习方法——TrAdaBoost,它通过调整样本权重来提高分类效果。此外,还讨论了独立同分布的概念和在实际建模中如何减小边缘分布和条件分布的差异。
本文探讨了迁移学习在金融风控领域的应用,主要任务是缩小源域和目标域之间的分布差异。介绍了几种常见的迁移学习方法,如模型再优化、层迁移、域对抗迁移和零样本学习。特别关注了基于实例的迁移学习方法——TrAdaBoost,它通过调整样本权重来提高分类效果。此外,还讨论了独立同分布的概念和在实际建模中如何减小边缘分布和条件分布的差异。

为什么做迁移?
一句话概括:源域样本和目标域样本分布有区别,目标域样本量又不够。
场景
思考我们平时建模会使用到迁移学习的一些场景:
1)新开了某个消费分期的场景只有少量样本,需要用其他场景的数据进行建模;
2)业务被迫停止3个月后项目重启,大部分训练样本比较老旧,新的训练样本又不够;
3)在某个新的国家开展了类似国内的业务,因为国情不同,显然部分特征分布是不同的;
主要任务
缩小边缘分布之间的距离 和 jia条件分布下的差异。
首先我们来看一下迁移学习领域的进展

介绍几个基本概念:
- Domain(域):包括两部分:feature space(特征空间)和probability(概率)。所以当domain不同的时候,分两种情况。可能是feature space不同,也可能是feature space一样但probability不同;
- Task(任务):包括两部分:label space(标记空间)和objective predictive function(目标预测函数)。同理,当task不同的时候,也分两种情况。可能是label space不同,也可能是label space一样但function不同;
- Source(源)是用于训练模型的域/任务;
- Targe(任务)是要用前者的模型对自己的数据进行预测/分类/聚类等机器学习任务的域/任务
通常我们说的迁移学习就是指将知识从源域迁移到目标域的过程。
比如我们有大量英短银渐层的图片,和少量美短起司的照片,想训练一个判别当前的猫是不是美短起司的学习器。如果我们用英短银渐层图片来作为样本,显然训练的模型是不能用来判别美短起司的,用美短起司的样本来训练,样本量又太小。

这时候我们可能会使用英短银渐层来训练一个卷积神经网络,然后将这个网络的中间结构取出来作为目标模型的前半部分,然后在少量的美短起司的样本上再继续学习后面的几层网络。

熟悉卷积神经网络的同学可能知道,CNN的前几层主要学习的是轮廓和局部形状等共性特征。这样通过前面的学习,我们就知道了猫咪的共性,再通过对起司的学习得到细节上的差异。
深度学习常见的迁移方法
- 模型再优化
- 层迁移
- 域对抗迁移
- 零样本学习
目前有突破的迁移学习算法基本上可以概括这几类:
基于实例的迁移学习方法 (可以保留模型的解释性,本门课的重点)
- 代表有Dai等人提出的基于实例的 TrAdaBoost 迁移学习算法。当目标域中的样本被错误地分类之后,可以认为这个样本是很难分类的,因此增大这个样本的权重,在下一次的训练中这个样本所占的比重变大。如果源域中的一个样本被错误地分类了,可以认为这个样本对于目标数据是不同的,因此降低这个样本的权重,降低这个样本在分类器中所占的比重。
基于特征的迁移学习方法
可以分为基于特征选择的迁移学习方法和基于特征映射的迁移学习方法。
- 基于特征选择的迁移学习方法是识别出源领域与目标领域中共有的特征表示,然后利用这些特征进行知识迁移。
- 基于特征映射的迁移学习方法是把各个领域的数据从原始高维特征空间映射到低维特征空间,在该低维空间下,源领域数据与目标领域数据拥有相同的分布。这样就可以利用低维空间表示的有标签的源领域样本数据训练分类器,对目标测试数据进行预测。
基于模型的迁移学习方法
- 由源域学习到的模型应用到目标域上,再根据目标域学习新的模型。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类等方法寻找最优化的标定参数。比如 TRCNN等
独立同分布
我们建模的时候一直在强调独立同分布,那么什么叫 独立同分布?
独立同分布即指变量均服从同一种分布,并且变量之间是相互独立的(在多数情况下其实是不满足的,但往往选择忽略并不紧密的联系)。例如随机变量X1和X2,两个变量独立即指X1的出现并不影响X2,同理X2的出现并不影响X1,并且X1和X2所在的样本集具有相同的分布形状和分布参数。
对离散随机变量具有相同的分布律,对连续随机变量则有相同的概率密度函数,有着相同的分布函数,相同的期望和方差。
再回想一下我们的主要任务:
缩小边缘分布之间和条件分布下的差异。
实现方法
刚刚说了我们的主要任务是 缩小边缘分布和条件分布下的差异。
那么如何实现这两个目标呢?
1)缩小训练集与测试集的边缘分布的距离,通常的做法是 清洗训练样本,去除一些异常点或者减少他们的权重。这样可以将训练样本的分布与测试样本的分布保持一致。
2)如果想减少条件分布的差异呢?用决策树举例子,我们还需要在决策树划分的每一层的样本中,重复上述过程,才可以保证条件概率分布也是相近的。
TrAdaboost
简述
它是Adaboost学习方法发展而来,作者是第四范式的创始人老戴。TrAdaboost算法是用来解决训练集和测试集分布不同的问题。在迁移学习的某些情况下,一个训练集中会包含大量的辅助训练样本和少量的源训练样本,我们会将两个不同分布的训练集放在一起训练,这种方法也称为基于实例的迁移学习方法。
原理
1)Tradaboost是由Adaboost算法演变而来的,我们先来看Adaboost算法的基本思想:当一个训练样本被错误分类,算法就会认为这个样本是难分类的,就相应地给此样本增加样本权重,下次训练时这个样本被分错的概率就会降低。
2)类似地,在一个包含源训练数据和辅助训练数据的训练集中,TrAdaboost算法也会对训练样本进行权重调整,对于源数据样本,权重调整策略跟Adaboost差不多:如果一个源训练样本被错误分类,根据这一次源样本训练时的错误率进行调整,增加权重,降低下次训练时的分类误差;对于辅助训练样本:当它们被误分类后,算法则认为它们是与目标数据很不同的,于是降低它们的权重,权重调整的依据是Hedge(b);
3)Tradaboost通过提升多个弱分类器,对后半(N/2~N)个弱分类器进行综合投票,得出最后的决策。

TrAdaBoost 和 AdaBoost 主要区别在于:
1)TrAdaBoost 的输入是 Ds 和 Dt 对应的两个数据集,并从 Ds 中只选取对学习任务 Tt 最有用的知识;2)TrAdaBoost 在计算模型误差时,仅考虑在 Dt 上的误差;3)TrAdaBoost 在 Ds 和 Dt 中使用不同的样本调权方式;4)TrAdaBoost 仅使用学习到的所有基学习器中,后训练的半数基学习器来预测模型效果。
样本的初始权重设置和基分类器选取比较关键。初始权重设置是较强的先验信息,而且,如果初始权重设置不当,也会影响计算稳定性。
我们可以通过不同领域的样本比例,或根据不同类别样本对应的比例,或综合考虑前二者来设置初始权重。另外,基分类器的选取也会影响迭代轮数、计算稳定性和模型最终效果。
域对抗迁移(domain adaption)
target domain的误差的bound是部分由source domain的误差决定的。当目标域完全没有标签的时候,我们可以使用一种叫做域对抗或者域适应(domain adaption)的方法。
现存的对抗迁移方法使用一个判别器,单纯的将源域数据和目标域数据整体地进行对齐,没有利用复杂的多模结构。
这样做的后果就是,不仅源域数据和目标域数据会混在一起,判别结构也会混在一起,导致不同域的判别结构进行了错误的对齐。
例如下图所示,源域数据猫和目标域数据狗错误的混合在了一起。
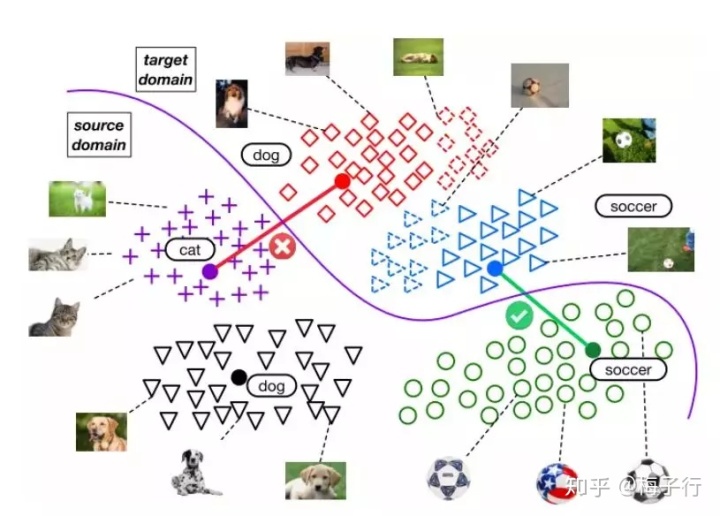
大家可能都知道,域对抗的迁移方法在深度学习中比较常用。
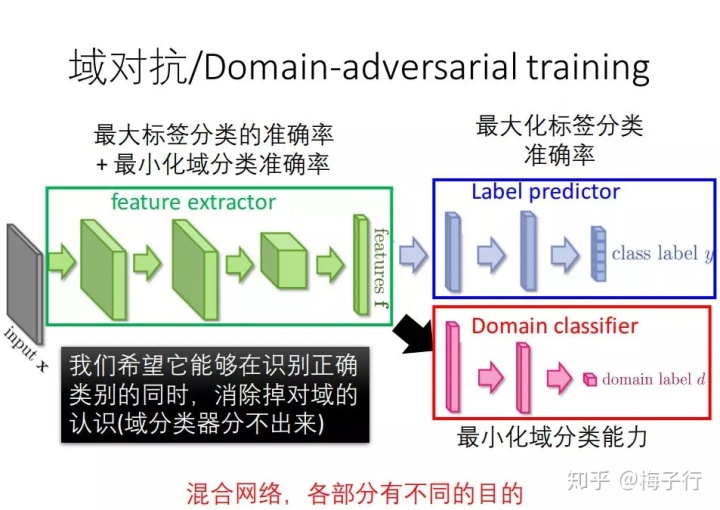
域对抗的思路其实非常的简单,就是在每一步迭代的时候,不止要能对目标域的任务能够最大化的区分,还要保证在源域和目标域上无法进行区分。
在深度学习中这件事情发生在反向传播,换成别的算法其实也可以实现。比如梯度下降中,我们每一次迭代的时候加入一个相反方向的任务,通过反复的迭代一样可以收敛到某一个值。很像是GAN。
基本思想
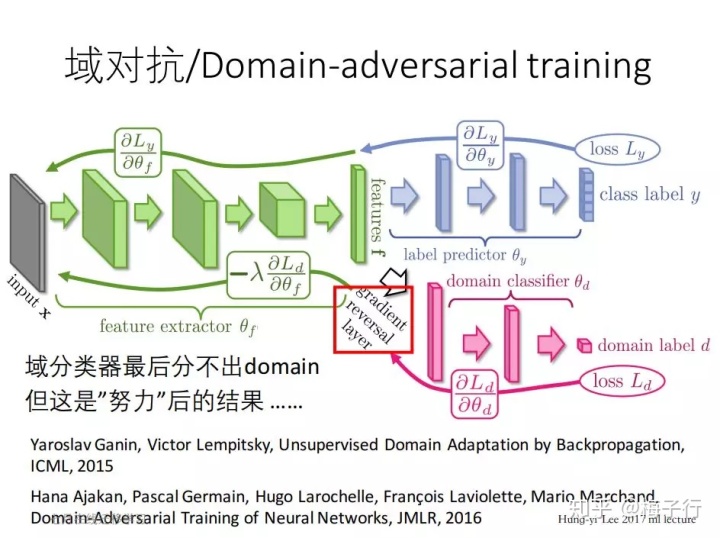
1、需求
- 有标签的训练数据量较小;
- 训练集与测试集数据分布的偏移;
2、关键点:构建源域与目标域之间的映射关系;
3、previous domain adaption:worked with fixed feature representations。
4、特点:同时进行域适应学习与特征学习
同时训练两个分类器:
label predictor:预测标签的分类器;
domain classifier:在训练时区分出训练集与测试集之间的特征的易于区分性;
迭代时的目标函数:
最小化label predictor分类器的loss函数
最大化domain classifier分类器的loss函数
5、目标:选出的特征具有一下属性:
- 特征具有易于区分的特性(discriminative)
- 特征对域的变化不敏感(domain invariant
6、一般用于衡量特征分布相似度的准则:
- match the distribution means in the kernel reproducing Hilbert space;
- map the principal axes associated with each of the distributions;
- match feature space distributions。
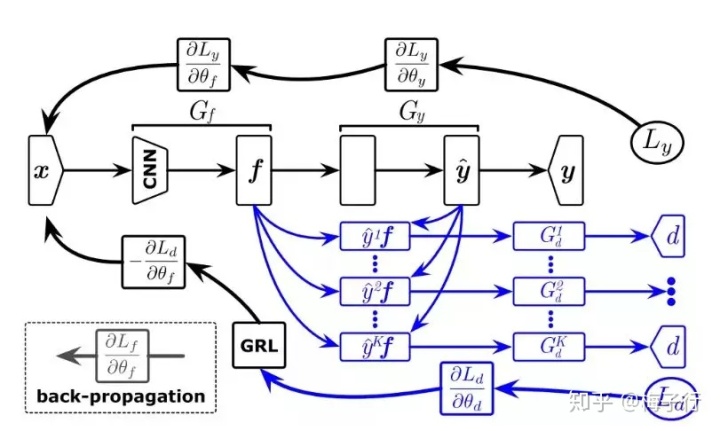
下面用风控领域大家最熟悉的逻辑回归来举例子,我们只需要在梯度下降的过程中,再引入一个任务,就是尝试去区分目标域与源域的样本。但是我们不朝着梯度的负方向走,而是朝着梯度的正方向走,以此来削弱边缘分布差异较大的特征。
import numpy as np
import pandas as pd
def sigmoid(z):
sigmoid = 1 / (1 + np.exp(-z))
return sigmoid
def domain_logistic(dt1,dt2,lb1,lb2,maxCycles): #数据集1,数据集2,标签1,标签2,最大迭代次数
dt1=mat(dt1) #(m,n)
lb1=mat(lb1).transpose() #转置后(m,1)
dt2=mat(dt2) #(m,n)
lb2=mat(lb2).transpose() #转置后(m,1)
m,n=shape(dt1)
weights=ones((n,1)) #初始化回归系数,(n,1)
alpha1=0.001 #定义第一个任务的步长
alpha2=0.00005 #定义第二个任务的步长 根据想要减弱两个domain的差距的程度,来适当改变该步长。
for i in range(maxCycles):
#区分第一个label
h=sigmoid(dt1 * weights) #sigmoid 函数
error=lb1 - h #即y-h,(m,1)
weights=weights + alpha1 * dt1.transpose() * error #梯度上升法
#不能区分第二个label
h=sigmoid(dt2 * weights) #sigmoid 函数
error=lb2 - h #即y-h,(m,1)
weights=weights - alpha2 * dt2.transpose() * error #梯度上升法
return weights
def logistic_fit(weights,dataMat):
final = []
for i in range(len(dataMat)):
temp = dataMat[i:i+1]
final.append(float(1-sigmoid(sum(weights*temp.transpose()))))
final = array(final)
return final 
















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









