






1、Java的三大特性及简介
封装(信息隐藏):属性来描述同一类事物的特征,方法描述操作,将之归到一个类中,称为封装。
好处:①实现了专业的分工。②信息隐藏。
继承:实现了代码的复用。其中的子类与父类是一般化和特殊化的关系。
多态:子类以父类的身份出现需要向上转型(upcast),其中向上转型是由JVM自动实现的。但向下转型(downcast)是不安全的,需要强制转换。
向上转型实例(指向子类对象,但会遗失父类中没有的方法)
public class Person {
int age;
int height;
int sex;
void doThing(){
System.out.println("method is doThing");
}
void walk(){
System.out.println("method is walk");
}
void say(){
System.out.println("method is say");
}
}public class Teacher extends Person{
void walk(){
System.out.println("person is walking");
}
void teach(){}
}
Person p = new Teacher();
p.walk();输出结果为:person is walking
因为p实际上指向的是一个子类对象,此时,Java虚拟机会自动识别出调用哪个具体的方法。不过,由于向上转型,p对象会遗失和父类不同的方法。例如teach()。
备注:
①一个接口可以继承多个接口。
interface C extends A,B{}
②一个类可以实现多个接口
class D implements A,B,C{}
③一个类只能继承一个类,不能继承多个类
class B extends A{}
④在继承类的同时,也可以继承接口
class E extends D implements A,B,C{}
3.synchronized关键字
Java支持多线程,为解决线程并发的问题,引入了synchronized同步块和volatile关键字。
3.1 修饰一个代码块或修饰方法(类似,见4中volatile关键字中实例)
参考:http://blog..net/luoweifu/article/details/46613015
一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞。
例1:
package sync;
public class SyncThread implements Runnable{
private static int count;
public SyncThread() {
count = 0;
}
@Override
public void run() {
synchronized (this) {
for(int i=0;i<3;i++){
try{
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
}
}package sync;
public class Main_sync {
public static void main(String[] args) {
SyncThread syncThread = new SyncThread();
Thread thread1 = new Thread(syncThread, "SyncThread1");
Thread thread2 = new Thread(syncThread, "SyncThread2");
thread1.start();
thread2.start();
}
}输出为:
SyncThread1:0
SyncThread1:1
SyncThread1:2
SyncThread2:3
SyncThread2:4
SyncThread2:5
两个并发线程(thread1和thread2)访问同一个对象(syncThread)中的synchronized代码块时,在同一时刻只能有一个线程得到执行,另一个线程受阻塞,必须等待当前线程执行完这个代码块后才能执行该代码块。
3.2 一个线程访问一个对象的synchronized代码块时,别的线程可以访问该对象的非synchronized代码块而不受阻塞。
总结如下:
A.无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;如果synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类所有的对象是同一把锁。
B.每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的这段代码。
C.实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
参考:http://www..com/aigongsi/archive/2012/04/01/2429166.html
例:
100个线程访问一个共享变量,每次加1,访问结束后,变量值为100;
例2:
package thread_sync_demo;
public class Money {
int i;
public Money(){}
public Money(int i){
this.i = i;
}
public void addMoney(){
i++;
}
public int getMoney(){
return i;
}
}package thread_sync_demo;
public class MoneyOperator implements Runnable{
private Money money;
public MoneyOperator(Money money) {
this.money = money;
}
@Override
public void run() {
// TODO Auto-generated method stub
synchronized (money) {
try {
Thread.sleep(10);
} catch (Exception e) {
// TODO: handle exception
}
money.addMoney();
System.out.println(Thread.currentThread().getName()+":"+money.getMoney());
}
}
}Money money = new Money(0);
for (int i = 0; i < 100; i++) {
new Thread(new MoneyOperator(money),"thread"+i).start();
}最终实例money中变量i变为100.
例3:
public class Counter {
public volatile static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++;
}
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}运行结果为:Counter.count = 992,可能每次运行结果都会变。
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图描述这写交互
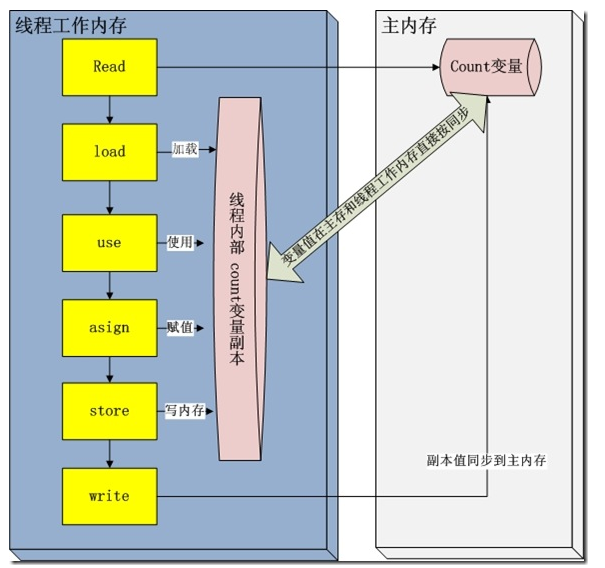
read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
例4:两个线程的交替执行,也涉及到了对象锁,两个线程的等待与执行均由该对象操作,所以应使用synchronized。
写两个线程,一个线程打印1-52,另一个线程打印A-Z,打印顺序为12A34B56C……5152Z。
注:分别给两个对象构造一个对象O,数字每打印两个或字母每打印一个就执行O.wait();
package thread_sync_demo;
public class NumberThread extends Thread{
private Object obj;
public NumberThread(Object obj){
this.obj = obj;
}
@Override
public void run() {
synchronized (obj) {
for(int i=1;i<53;i++){
System.out.print(i);
if(i%2==0){
obj.notifyAll();
try {
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}package thread_sync_demo;
public class LetterThread extends Thread{
private Object obj;
public LetterThread(Object obj){
this.obj = obj;
}
@Override
public void run() {
synchronized (obj) {
for(int i=0;i<26;i++){
System.out.print((char)('A'+i)+"");
obj.notifyAll();//打印一个字母就会唤醒其他线程,并当前对象处于等待状态
//notifyAll();唤醒在此对象监视器上等待的所有线程。
if(i!=25){
try {
obj.wait();//当前线程等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}public static void main(String[] args) {
Object obj = new Object();
LetterThread letterThread = new LetterThread(lock);
NumberThread numberThread = new NumberThread(lock);
numberThread.start();
letterThread.start();
}补充如下:
public void method(SomeObject so){
synchronized(so){
//..
}
}
这时,锁就是so这个对象,每个对象对应一个唯一的锁,所以哪个线程拿到这个对象锁谁就能够运行他控制的那段代码。当有一个明确的对象作为锁时,就能够这样写程式,但当没有明确的对象作为锁,只是想让一段代码同步时,能够创建一个特别的Instance变量来充当锁:
private byte[] lock = new byte[0];
Public void method(){
synchronized(lock)
{
//
}
}零长度的byte数组对象创建起来将比任何对象都经济--查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
4.关键字volatile
参考:http://www..com/dolphin0520/p/3920373.html
4.1 内存模型的相关概念
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i+1;
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
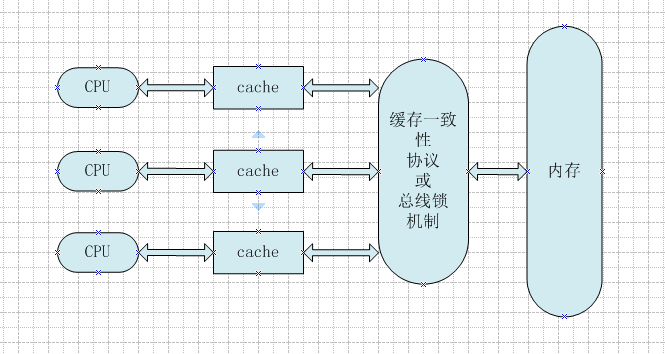
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。如下图所示:
4.2 并发编程中的三个概念
原子性、可见性、有序性
原子性:一个操作或多个操作,要么全部执行并且执行执行的过程不会被任何因素打算,要么就都不执行。经典的银行转账问题。
可见性:多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
例如:
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。有序性:即程序执行的顺序按照代码的先后顺序执行。举个简单的例子,看下面这段代码:
int i = 0;
boolean flag = false;
i = 1;//语句1
flag = true;//语句2
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:int a = 10;//语句1
int r = 2;//语句2
a = a + 3;//语句3
r = a*a;//语句4这段代码有4个语句,那么可能的一个执行顺序是:
2->1->3->4
那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
4.3 深入剖析volatile关键字
①volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行://线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。②volatile保证原子性吗?
看下面这段代码
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。修改如下:
public class Test {
public int inc = 0;
public synchronized void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}为方法添加synchronized关键字,将a++操作原子化即可。
5.关键字final
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象,但引用值可变。
例1:
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
System.out.println((a == c));
System.out.println((a == e));输出结果为:true,false
当final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译器常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个变量,不需要在运行时确定。
6.Java中修饰符
private:该类;
default:同包访问,且为默认值;
protected:同包及继承子类可访问;
public:均可访问
7.Java的八种数据类型
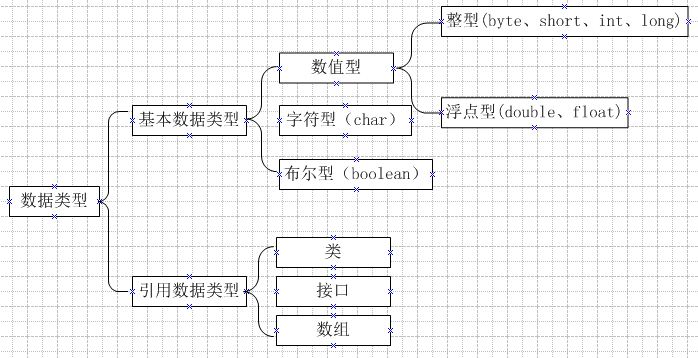
类型占用存储空间
byte1字节
short2字节
int4字节
long8字节
float4字节
double8字节注:String不属于八种的一种,String是一个对象。
例:
String str1 = null;
String str2 = "hello";
System.out.println(str1+str2);输出结果为:nullhello
7.1 字符串比较,使用“==”还是equals()?
简单来说, "==" 判断两个引用的是不是同一个内存地址(同一个物理对象).而 equals 判断两个字符串的值是否相等.除非你想判断两个string引用是否同一个对象,否则应该总是使用 equals()方法.
7.2 如何通过空白字符拆分字符串?
String 的 split()方法接收的字符串会被当做正则表达式解析,"\s"代表空白字符,如空格" ",tab制表符"\t", 换行"\n",回车"\r",而编译器在对源代码解析时,也会进行一次字面量转码,所以需要"\\s".代码如下:
String sArray[] = s.split("\\s+");
7.3 String VS StringBuilder VS StringBufferString是不可变对象,一旦创建,那么整个对象就不可改变,设计之初将其定义为final类型,主要从效率和安全性两方面考虑?即使新手觉得String引用变了,实际上只是(指针)引用指向了另一个(新的)对象。
StringBuilder 是可变的,因此可以在创建以后修改内部的值.
StringBuffer 是同步的,因此是线程安全的,但效率相对更低.
7.4 String与new String的区别(注意对象与对象引用的区别)
实例分析
String hello = "hello";
String hello1 = "he" + new String("llo");
String str1="abx";
String str2="abx";
String str3=new String("abx");
String str4=new String("abx");
System.out.println(str1==str2);
System.out.println(str2==str3);
System.out.println(str3==str4);
System.out.println(hello == hello1);输出结果为:true,false,false,false
当String str1="abx" ,"abx"是一个对象,String str2="abx"明显是又声明了一个到“abx”的一个引用str2,所以测试str1==str2时打印true
但String str3=new String("abx");这是显式的创建了一个String对象。判断==时,显然两个对象不是同一个对象。所以判断字符相等的时候我们都用equals方法。也是这个道理。
8.Java异常
参考:http://blog..net/hguisu/article/details/6155636
8.1 Java的异常结构图
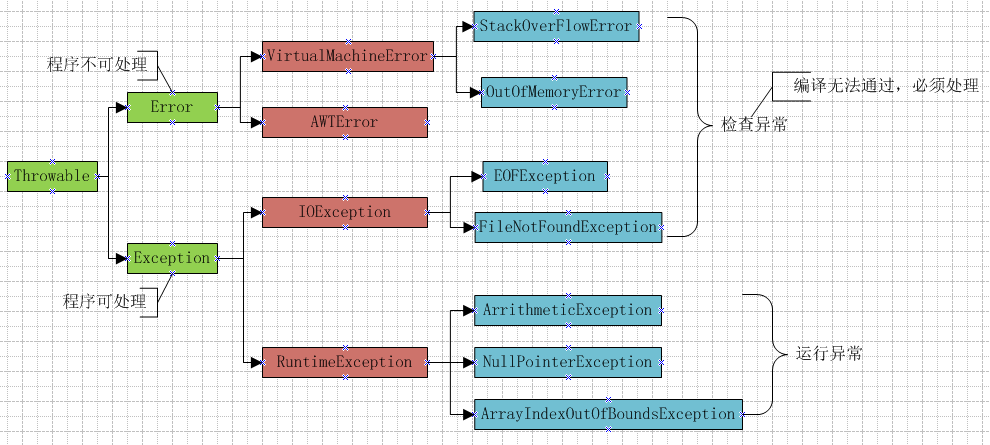
Throwable是所有异常的根,Error是错误,Exception是异常。
运行异常由运行时系统自动抛出,不需要使用throw语句。
Exception
一般分为checked异常和Runtime异常。
①java认为checked异常都是可以被处理的异常。我们比较熟悉的Checked异常有:文件、类、方法未找到,IO异常
Java.lang.ClassNotFoundException
Java.lang.NoSuchMetodException
java.io.IOException
②RuntimeException
Runtime如除数是0和数组下标越界等,其产生频繁,处理麻烦,若显示申明或者捕获将会对程序的可读性和运行效率影响很大。所以由系统自动检测并将它们交给缺省的异常处理程序。我们比较熟悉的RumtimeException类的子类有:算术、数组越界、空指针等
Java.lang.ArithmeticException
Java.lang.ArrayStoreExcetpion
Java.lang.ClassCastException
Java.lang.IndexOutOfBoundsException
Java.lang.NullPointerException
8.2 处理异常的机制
抛出异常和捕获异常;总是先抛出,后捕获。
抛出异常:当一个方法出现错误引发异常时,方法创建异常对象并交付运行时系统,异常对象中包含了异常类型和异常出现时的程序状态等异常信息。运行时系统负责寻找处置异常的代码并执行。
捕获异常:在方法抛出异常之后,运行时系统将转为寻找合适的异常处理器(exception handler)。潜在的异常处理器是异常发生时依次存留在调用栈中的方法的集合。当异常处理器所能处理的异常类型与方法抛出的异常类型相符时,即为合适 的异常处理器。运行时系统从发生异常的方法开始,依次回查调用栈中的方法,直至找到含有合适异常处理器的方法并执行。当运行时系统遍历调用栈而未找到合适 的异常处理器,则运行时系统终止。同时,意味着Java程序的终止。
try/catch/finally
①基本语法
try {
// 可能会发生异常的程序代码
} catch (Type1 id1) {
// 捕获并处理try抛出的异常类型Type1
} catch (Type2 id2) {
// 捕获并处理try抛出的异常类型Type2
} finally {
// 无论是否发生异常,都将执行的语句块
}
例1:
public static void main(String[] args) {
try {
System.out.println("in the try block");
return;
} catch (Exception e) {
e.printStackTrace();
}
finally {
System.out.println("in the finally block");
}
}输出结果:
in the try block
in the finally block
解释:在try中的return真正返回之前会执行finally中的语句。
②catch中捕获异常时,异常类型应自底层写起。例如:发生数组越界,第一个catch中应写ArrayIndexOutOfBoundsException,最后的catch写RuntimeException。否则,会出现屏蔽。
小结:
try 块:用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
catch 块:用于处理try捕获到的异常。
finally 块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。在以下4种特殊情况下,finally块不会被执行:
1)在finally语句块中发生了异常。
2)在前面的代码中用了System.exit()退出程序。
3)程序所在的线程死亡。
4)关闭CPU。
throws抛出异常的规则:
1) 如果是不可查异常(unchecked exception),即Error、RuntimeException或它们的子类,那么可以不使用throws关键字来声明要抛出的异常,编译仍能顺利通过,但在运行时会被系统抛出。
2)必须声明方法可抛出的任何可查异常(checked exception)。即如果一个方法可能出现受可查异常,要么用try-catch语句捕获,要么用throws子句声明将它抛出,否则会导致编译错误
3)仅当抛出了异常,该方法的调用者才必须处理或者重新抛出该异常。当方法的调用者无力处理该异常的时候,应该继续抛出,而不是囫囵吞枣。
4)调用方法必须遵循任何可查异常的处理和声明规则。若覆盖一个方法,则不能声明与覆盖方法不同的异常。声明的任何异常必须是被覆盖方法所声明异常的同类或子类。例:
void method1() throws IOException{} //合法
//编译错误,必须捕获或声明抛出IOException
void method2(){
method1();
}
//合法,声明抛出IOException
void method3()throws IOException {
method1();
}
//合法,声明抛出Exception,IOException是Exception的子类
void method4()throws Exception {
method1();
}
//合法,捕获IOException
void method5(){
try{
method1();
}catch(IOException e){…}
}
//编译错误,必须捕获或声明抛出Exception
void method6(){
try{
method1();
}catch(IOException e){throw new Exception();}
}
//合法,声明抛出Exception
void method7()throws Exception{
try{
method1();
}catch(IOException e){throw new Exception();}
}判断一个方法可能会出现异常的依据如下:
1)方法中有throw语句。例如,以上method7()方法的catch代码块有throw语句。
2)调用了其他方法,其他方法用throws子句声明抛出某种异常。例如,method3()方法调用了method1()方法,method1()方法声明抛出IOException,因此,在method3()方法中可能会出现IOException。
throw与throws的区别
①throw:针对对象的做法
②throws:针对方法的做法
参考:http://blog..net/u012050416/article/details/50781426#t9
例:
public class Test3 {
public static void main(String[] args) {
System.out.println("main..." + getValue());
}
public static int getValue() {
try {
System.out.println("try...");
return 0;
} finally {
System.out.println("finally...");
return 1;
}
}
}输出结果:
try...
finally...
main...1
解释:此处finally中返回1,所以不再执行try中的return 0;
例:
public class Test3 {
public static void main(String[] args) {
System.out.println("main..." + getValue());
}
public static int getValue() {
int i = 0;
try {
System.out.println("try...");
return i;
} finally {
System.out.println("finally...");
i++;
}
}
}输出结果:
try...
finally...
main...0
解释:
这个很多人都不知道为什么了,按道理说,在try的return执行之前,在finally之中已经更改了i的值,为什么return的值任然是0而不是1呢?
实际上,Java 虚拟机会把 finally 语句块作为 subroutine。直接插入到 try 语句块或者 catch 语句块的控制转移语句之前。但是,还有另外一个不可忽视的因素,那就是在执行 subroutine(也就是 finally 语句块)之前,try 或者 catch 语句块会保留其返回值到本地变量表(Local Variable Table)中。待 subroutine 执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。
所以,上例中try中返回的不是finally中的i,而是在执行finally之前放在本地变量表中的i。所以返回的仍然是0。
例:
public class Test3 {
public static void main(String[] args) {
System.out.println("main..." + getValue());
}
public static int getValue() {
int i = 0;
try {
System.out.println("try...");
} finally {
System.out.println("finally...");
i++;
return i;
}
}
}输出结果:
try...
finally...
main...1由于try中没有返回语句,所以不会将try中的i放到本地变量表,执行完finally之后也不会再返回try,而是使用finally中的i直接返回。
例:
public class Test3 {
public static void main(String[] args) {
System.out.println("main..." + getValue());
}
public static int getValue() {
int i = 0;
try {
System.out.println("try...");
return test();
} finally {
System.out.println("finally...");
i++;
}
}
public static int test() {
System.out.println("test...");
return 10;
}
}输出结果:
try...
test...
finally...
main...10此处try中的return test()就等同于int r = test();return r;,另外,catch和finally的关系和上面是一样的,这里省略了。
最佳实践:
1)不要在catch和finally块中有return语句;
2)建议在finally中只进行资源的清理操作;
补充:Java栈
所谓Java栈,描述的是一种Java中方法执行的内存模型,Java栈为线程私有,线程中每一次的方法调用(或执行),JVM都会为该方法分配栈内存,即:栈帧(stack frame),分配的栈帧用于存放该方法的局部变量表、操作栈、方法编译后的字节码指令信息和异常处理信息等,JVM制定了一个线程可以请求的栈深度的最大值,如果线程请求的栈深度超过这个最大值,JVM将会抛出stackoverflowerror,
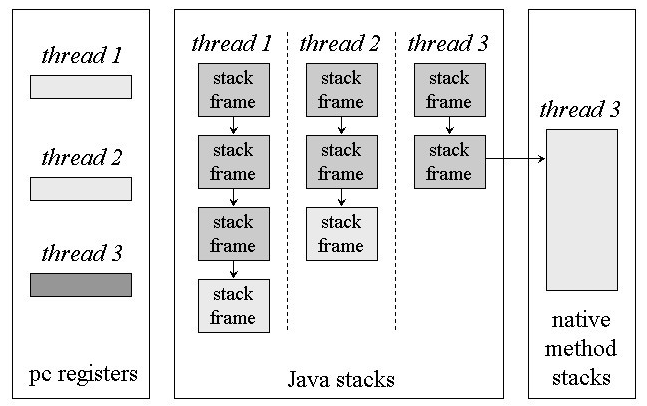
由图可知:在一个JVM实例中(即我们运行的一个Java程序)可以同时运行多个线程,而每个线程都拥有自己的Java栈,此栈为线程私有,随着线程内方法的不断调用,线程内的栈深度不断增加,直到溢出。而当一个方法执行完毕(return或throw),该方法所对应的线程内的栈帧被JVM回收,线程内的栈深度会相应的变小,直到线程的终结。
9.switch语句

该方法返回值为10;因为每个case中均无break;所以当输入2后,会从case 2一直执行下去。
switch标准语句格式如下:
switch(整型或字符型变量)
{
case 变量可能值1:
分支一;
break;
case 变量可能值2:
分支二;
break;
……
default:
最后分支;
}
10.java8的接口新特性:可以有方法体的接口
11.重载(overloading)和重写(overriding)
重载:函数名同,参数个数/类型不同,返回值可以相同也可以不同。重载是一个类中多态性的一种表现。
重写:又叫方法覆盖,父类与子类间的多态性
注:super关键字必须位于子类方法中的第一句。
12.GC是否为守护线程?
是,线程分为守护线程和非守护线程(即用户线程)。只要当前JVM实例中尚存在任何一个非守护线程没有结束,守护线程就全部工作;只有当最后一个非守护线程结束时,守护线程随着JVM一同结束工作。守护线程最典型的应用就是GC(垃圾回收器)。
13.字符和ASC码的转换
字符->ASC码:(int)'a'
ASC码->字符:(char)97
例1:统计字符串中不同字符的个数
package exercise;
public class Main {
public static void main(String[] args) {
String s = "123asdASD123";
int j = 0,p = 0;
byte []bytes = s.getBytes();
for(int i=0;i
if(bytes[i]>=0&&bytes[i]<=127){
p = 0;
for(int k=0;k
if(bytes[i]==bytes[k]){
p = 1;
break;
}
}
if(p==0)
j++;
}
}
System.out.println(j);
}
}例2:统计字符串中不同字符的个数
package exercise;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public class Main_exer {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();
int nums = 0;
byte []bytes = s.getBytes();
Map map = new HashMap();
for(int i=0;i
boolean flag = map.containsValue((char)bytes[i]+"");
if(flag==false){
System.out.println((char)bytes[i]);
map.put((int)bytes[i], (char)bytes[i]+"");
nums++;
}
}
System.out.println("不同的字符数是:" + nums);
}
}
14.HashMap
特点:collection、key-value、
如何实现快速存储数据?
①hashmap数据结构:链表散列
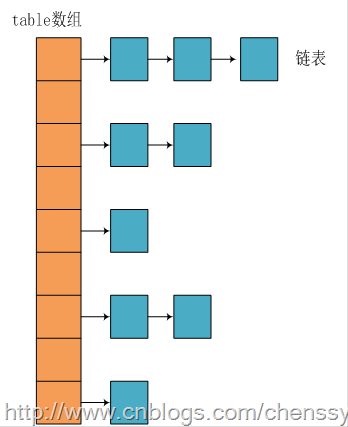
②主要在于:链的产生、扩容问题。















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









